Автор: Денис Аветисян
Новый подход, основанный на больших языковых моделях и обучении с подкреплением, позволяет значительно повысить точность и интерпретируемость определения географического положения изображений.
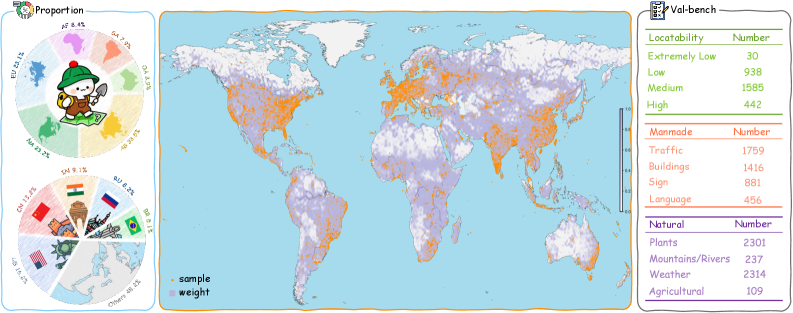
В статье представлен GeoAgent — система, использующая обучение с подкреплением и награду за гео-подобие для улучшения определения местоположения изображений с помощью больших языковых моделей.
Несмотря на успехи в области обучения моделей рассуждения, точное определение местоположения по изображениям остается сложной задачей, требующей учета специфики географических данных. В данной работе, озаглавленной ‘GeoAgent: Learning to Geolocate Everywhere with Reinforced Geographic Characteristics’, представлен новый подход, использующий большие языковые модели и обучение с подкреплением для улучшения точности и интерпретируемости определения местоположения. Ключевым нововведением является использование награды за географическую схожесть и механизма обеспечения согласованности рассуждений, основанного на новом наборе данных GeoSeek, аннотированном экспертами. Способен ли GeoAgent обеспечить качественно новый уровень понимания и анализа географической информации, приближая нас к созданию действительно «умных» систем геолокации?
Пределы Традиционной Геолокации
Современные модели геолокации часто испытывают трудности при интерпретации неоднозначных описаний местоположений, требующих сложного логического анализа. Вместо точного определения координат, они полагаются на поверхностное сопоставление ключевых слов, что приводит к ошибкам при обработке нечетких или метафоричных запросов. Например, фраза «рядом со старым дубом» может быть интерпретирована по-разному в зависимости от контекста и региональных особенностей, что подчеркивает необходимость разработки алгоритмов, способных к более глубокому семантическому пониманию и учету нюансов языка. Ограничения в способности к логическому выводу и контекстуализации существенно снижают точность геолокации в реальных условиях, особенно при работе с историческими данными или неформальными описаниями.
Существующие наборы данных для геолокации зачастую отражают выраженные региональные предубеждения, что серьезно ограничивает возможности обобщения моделей и может усугублять существующее неравенство. Например, большая часть информации может быть сосредоточена вокруг крупных городов Северной Америки и Европы, в то время как данные о менее развитых регионах или странах глобального Юга остаются недостаточными или вовсе отсутствуют. Это приводит к тому, что модели геолокации демонстрируют существенно худшую точность при определении местоположения в этих недостаточно представленных областях, создавая цифровой разрыв и затрудняя доступ к геопространственным сервисам для населения этих регионов. Устранение этих дисбалансов требует целенаправленных усилий по сбору и аннотированию данных, охватывающих весь земной шар, и разработке алгоритмов, устойчивых к региональным смещениям.
Существенная сложность точной геолокации по текстовым описаниям заключается в необходимости преобразования естественного языка в конкретные географические координаты. Это требует гораздо большего, чем простого сопоставления шаблонов или поиска ключевых слов. Современные модели часто сталкиваются с неоднозначностью формулировок, метафорами и контекстуальными зависимостями, которые требуют глубокого семантического анализа. Например, фраза «рядом с рекой» не предоставляет достаточной информации для однозначного определения местоположения без учета других факторов, таких как название реки, ее протяженность и окружающий ландшафт. Успешная геолокация по текстовым данным предполагает разработку алгоритмов, способных понимать смысл, учитывать контекст и разрешать неоднозначности, что значительно превосходит возможности простого статистического сопоставления.
GeoSeek: Набор Данных для Геолокации, Основанной на Рассуждениях
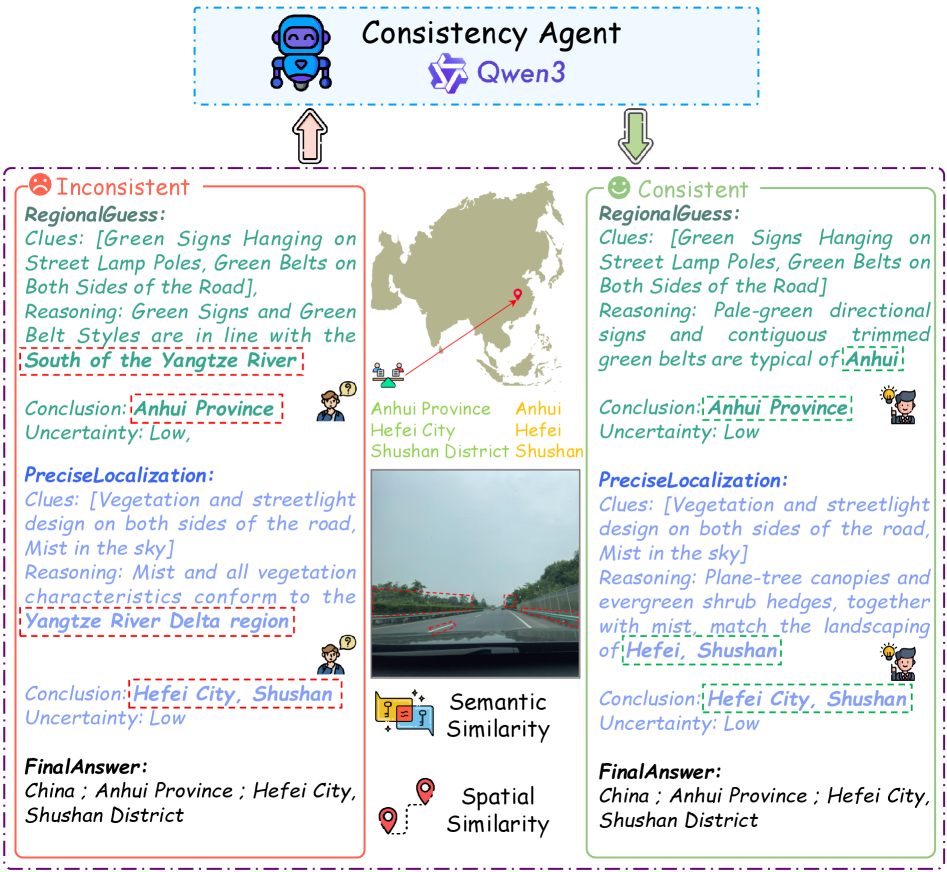
Набор данных GeoSeek был разработан для решения проблемы недостатка высококачественных данных, содержащих обоснования, в задачах геолокации. Существующие наборы данных часто предоставляют только координаты или названия мест, не содержа информацию о процессе рассуждений, который привел к определению местоположения. GeoSeek направлен на устранение этого ограничения, предоставляя данные, которые позволяют моделям не просто идентифицировать местоположение, но и понимать логику, лежащую в основе этого определения. Это особенно важно для сложных задач геолокации, требующих анализа контекста, знаний о мире и умения делать выводы.
Набор данных GeoSeek содержит аннотации в виде цепочки рассуждений (Chain-of-Thought, GeoSeek-CoT), представляющие собой явные, пошаговые объяснения, используемые людьми для определения местоположения. Эти аннотации демонстрируют процесс логического вывода, который приводит к идентификации конкретного географического объекта, а не просто указывают конечное местоположение. Такой подход позволяет моделям машинного обучения не только предсказывать местоположение, но и понимать как было принято решение, что способствует повышению надежности и интерпретируемости результатов.
Для снижения региональных смещений при создании набора данных GeoSeek была применена стратегия многоуровневой иерархической выборки. Данная стратегия предполагает последовательное разбиение географических регионов на уровни (например, страна, область, город) и выбор образцов на каждом уровне пропорционально населению и плотности населения. Это позволило обеспечить более равномерное представление различных регионов в наборе данных, избежав перепредставленности густонаселенных областей и недостаточного охвата малонаселенных территорий. Применение иерархического подхода позволило контролировать распределение данных на различных уровнях детализации, обеспечивая статистическую значимость представленных регионов.
GeoAgent: Моделирование Человеческого Рассуждения для Геолокации
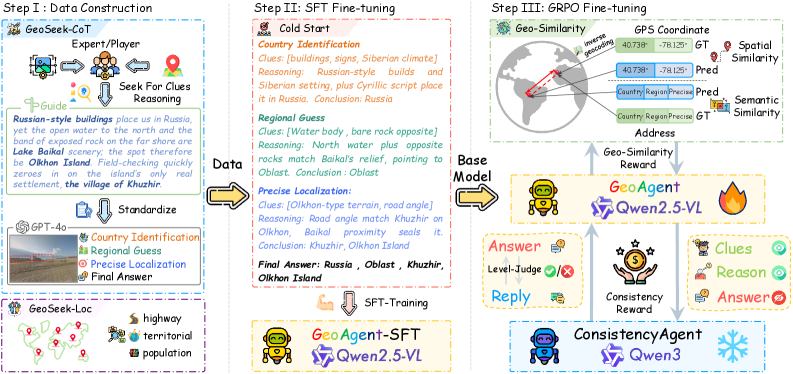
GeoAgent — это модель геолокации, разработанная для имитации человеческого рассуждения. Обучение модели происходит в два этапа: Supervised Fine-Tuning (SFT) и Gradient-based Reward Policy Optimization (GRPO). На этапе SFT модель обучается на размеченных данных для выполнения базовой задачи геолокации. Затем, на этапе GRPO, используется обучение с подкреплением для оптимизации политики модели на основе функции вознаграждения, что позволяет улучшить качество предсказаний и приблизить их к человеческому уровню рассуждений при определении местоположения.
Для оценки качества предсказаний в GeoAgent используется специализированная функция вознаграждения Geo-Similarity, комбинирующая два ключевых параметра: пространственную близость (Spatial Similarity) и семантическое соответствие (Semantic Similarity). Пространственная близость оценивается на основе географических координат предсказанного и целевого местоположений, учитывая расстояние между ними. Семантическое соответствие определяет, насколько предсказанное местоположение соответствует описанию или контексту, заданному в запросе. Комбинирование этих двух факторов позволяет модели более точно оценивать релевантность предсказаний и оптимизировать процесс обучения, обеспечивая высокую точность определения местоположения.
Модель GeoAgent использует в качестве основы языковую модель Qwen2.5-VL-7B, что обеспечивает надежную базу для понимания сложных запросов и анализа контекста. Данная модель, состоящая из 7 миллиардов параметров, демонстрирует передовые результаты в задачах геолокации, достигая точности 60.37% на бенчмарке GeoSeek-Val. Это позволяет GeoAgent эффективно решать задачи определения местоположения, опираясь на развитые возможности Qwen2.5-VL-7B в обработке и интерпретации языковой информации.

Расширение Возможностей GeoAgent с Помощью Внешних Инструментов
В основе GeoAgent лежит использование модели GPT-4o для приведения текстовых запросов к стандартизированному виду и структурированию информации. Этот процесс нормализации позволяет системе эффективно обрабатывать разнообразные формулировки и синтаксические конструкции, встречающиеся в пользовательском вводе. Благодаря применению GPT-4o, GeoAgent способен вычленять ключевые географические данные из неструктурированного текста, приводя их к единообразному формату, необходимому для последующей обработки и геокодирования. Такая предварительная обработка существенно повышает точность определения местоположения и снижает влияние неоднозначности и ошибок в исходных данных, обеспечивая более надежные результаты.
Для обеспечения высокой точности определения местоположения, система GeoAgent использует сервис геокодирования OpenCage. Данный сервис позволяет преобразовывать географические координаты в понятные адреса и наоборот, что критически важно для верификации полученных данных. Преобразование координат в адреса и адресов в координаты осуществляется посредством запросов к API OpenCage, обеспечивая не только точное определение местоположения, но и возможность проверки достоверности исходной информации. Такой подход позволяет GeoAgent эффективно работать с неполными или неточными входными данными, повышая надежность и применимость системы в различных геоинформационных задачах.
В ходе тестирования на наборе данных IM2GPS3K, разработанная система GeoAgent продемонстрировала впечатляющую точность определения страны местоположения — 76.21%. Этот результат существенно превосходит показатели существующих передовых методов и представляет собой значительный прогресс по сравнению с базовым уровнем в 72.40%. Примечательно, что повышение эффективности достигается при минимальном увеличении количества параметров модели — всего на 1.91% благодаря применению метода LoRA. Такая оптимизация позволяет добиться существенного улучшения производительности без значительного увеличения вычислительных затрат и требований к ресурсам.

В представленной работе акцент делается на достижение не просто работоспособности модели GeoAgent, но и на обеспечение её логической непротиворечивости при определении местоположения изображений. Авторы стремятся к созданию алгоритма, который не просто выдаёт правильный ответ для тестового набора данных, но и демонстрирует доказуемость своих рассуждений. Как однажды заметил Дональд Дэвис: «Простота — это высшая форма элегантности». Это особенно актуально в контексте использования обучения с подкреплением и reward-функции гео-сходства, поскольку модель должна не просто находить похожее местоположение, но и обосновывать свой выбор, опираясь на чёткие и понятные критерии, что соответствует стремлению к математической чистоте алгоритма.
Что Дальше?
Представленная работа, безусловно, демонстрирует потенциал использования обучения с подкреплением и больших языковых моделей для задачи геолокации. Однако, если решение кажется магией — значит, не раскрыт инвариант. В данном случае, вопрос о надежности и обобщающей способности полученного агента остаётся открытым. Успех, измеренный на созданном датасете, не гарантирует устойчивости к “естественному” шуму и неоднозначности реальных изображений. Необходимо критически оценить, насколько эффективно агент использует географические особенности, или же просто “запоминает” паттерны из обучающей выборки.
Будущие исследования должны быть направлены на формализацию понятия “географической согласованности”. Недостаточно просто определить “близость” двух локаций; необходимо учитывать контекст, исторические данные и даже культурные особенности. Попытки обойтись эвристическими функциями вознаграждения рискуют привести к локальным оптимумам и непредсказуемому поведению. Более того, важно исследовать возможности использования формальных методов верификации для доказательства корректности алгоритма геолокации, а не полагаться исключительно на эмпирические результаты.
В конечном счёте, истинная элегантность решения заключается не в достижении высокой точности на текущем датасете, а в создании алгоритма, способного к адаптации и самообучению в меняющихся условиях. Если же агент остаётся “черным ящиком”, выдающим правильные ответы без объяснения причин, то его ценность как научного инструмента остаётся под вопросом.
Оригинал статьи: https://arxiv.org/pdf/2602.12617.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект и закон: гармония неизбежна
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
- Польский язык обретает свой интеллект
- Индустриальные аномалии: обнаружение и сегментация без обучения
2026-02-16 10:11