Автор: Денис Аветисян
Исследователи представили Self-EvolveRec — систему, способную самостоятельно оптимизировать алгоритмы рекомендаций, используя мощь больших языковых моделей и симулируя поведение пользователей.
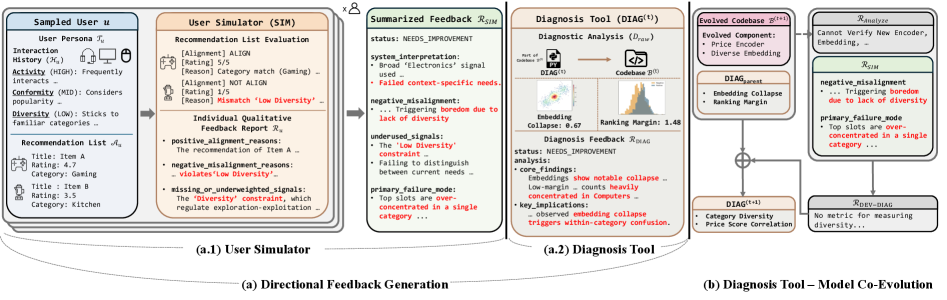
Предлагается фреймворк Self-EvolveRec для автоматической эволюции рекомендательных систем на основе направленного отклика, включающего симулятор пользователя и инструмент диагностики модели.
Традиционные подходы к автоматизации проектирования рекомендательных систем, такие как поиск нейронной архитектуры (NAS), часто ограничиваются фиксированным пространством поиска, заданным априорными знаниями экспертов. В данной работе представлена система ‘Self-EvolveRec: Self-Evolving Recommender Systems with LLM-based Directional Feedback’, которая предлагает новый подход к самообучению рекомендательных систем, используя направленную обратную связь на основе больших языковых моделей. В основе Self-EvolveRec лежит интеграция симулятора пользователя для качественной оценки и инструмента диагностики модели для количественной верификации, обеспечивающая динамическую адаптацию критериев оценки в процессе эволюции архитектуры. Способна ли предложенная архитектура преодолеть ограничения существующих AutoML-подходов и значительно улучшить как производительность рекомендаций, так и удовлетворенность пользователей?
Эволюция Рекомендаций: От Статики к Динамике
Долгое время основой систем рекомендаций являлись традиционные методы, такие как матричная факторизация. Эти алгоритмы, эффективно работающие с данными о предпочтениях пользователей и свойствах объектов, сталкиваются с серьезными трудностями при анализе сложных взаимосвязей между пользователями и предметами. В частности, они плохо учитывают контекстуальные факторы, временные зависимости и неявные сигналы, возникающие при взаимодействии пользователей с платформой. В результате, рекомендации, основанные исключительно на матричной факторизации, зачастую оказываются недостаточно точными и персонализированными, не отражая всей глубины и динамики предпочтений пользователя, что снижает эффективность всей системы и требует поиска более продвинутых подходов.
Более современные методы, такие как графовые нейронные сети, действительно демонстрируют улучшения в работе рекомендательных систем по сравнению с традиционными подходами. Однако, несмотря на свою потенциальную мощь, эти технологии часто требуют значительных усилий по ручной настройке параметров для достижения оптимальной производительности в конкретной задаче. Более того, существующие модели зачастую плохо адаптируются к изменениям в поведении пользователей или в структуре данных, что приводит к необходимости повторной настройки и переобучения. Отсутствие автоматической адаптации снижает эффективность этих систем в динамично меняющейся среде и требует постоянного вмешательства специалистов для поддержания актуальности и точности рекомендаций.
Современные пользователи демонстрируют все более сложное и динамичное поведение, что создает серьезные вызовы для традиционных систем рекомендаций. Постоянно меняющиеся предпочтения, влияние контекста и социальных факторов, а также растущий объем доступной информации требуют принципиально нового подхода к построению рекомендаций. Вместо ручной настройки и статических моделей, все большую актуальность приобретают автоматизированные конвейеры, способные к самообучению и адаптации в реальном времени. Такие системы используют алгоритмы машинного обучения для непрерывного анализа поведения пользователей, выявления скрытых закономерностей и прогнозирования будущих предпочтений, что позволяет предлагать более релевантные и персонализированные рекомендации, значительно повышая удовлетворенность и вовлеченность пользователей.
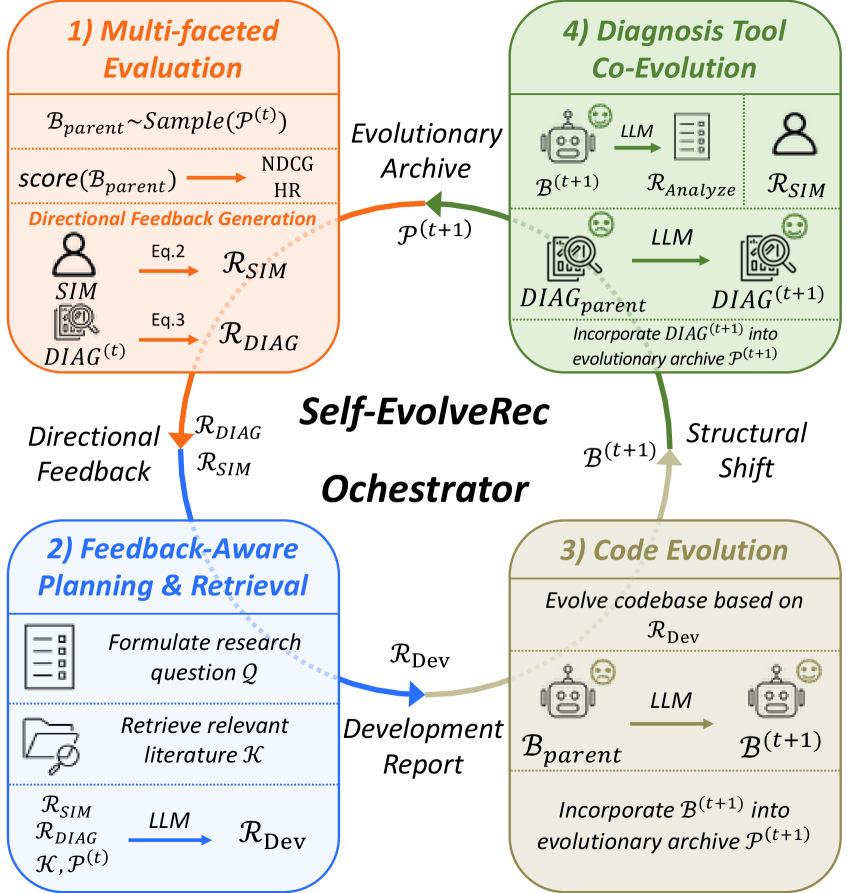
Языковые Модели как Двигатели Эволюции Кода
В последние годы наблюдается значительный прогресс в области больших языковых моделей (LLM), которые демонстрируют способность понимать и генерировать программный код. Это открывает новые возможности для автоматизации разработки программного обеспечения, включая автоматическое исправление ошибок, рефакторинг кода и даже создание новых программных решений. LLM, обученные на огромных объемах кода, способны анализировать синтаксис и семантику различных языков программирования, что позволяет им выполнять задачи, традиционно требующие участия человека. Способность генерировать код на основе текстовых описаний и примеров делает LLM ценным инструментом для повышения производительности разработчиков и снижения затрат на разработку.
Существующие фреймворки, такие как AlphaEvolve и DeepEvolve, используют большие языковые модели (LLM) для эволюции кодовой базы, однако демонстрируют ограниченную эффективность при оптимизации сложных алгоритмов, в частности систем рекомендаций. Эти инструменты, как правило, не имеют специализированных стратегий для улучшения производительности таких алгоритмов, ограничиваясь общими подходами к модификации кода. Отсутствие целенаправленной оптимизации для систем рекомендаций связано с их специфической структурой и требованиями к производительности, которые отличаются от задач, решаемых в более простых сценариях эволюции кода.
Наш подход развивает существующие методы эволюции кода с использованием больших языковых моделей (LLM), интегрируя их с новой системой обратной связи для целенаправленной оптимизации. В отличие от существующих фреймворков, таких как AlphaEvolve и DeepEvolve, которые часто не имеют четкой стратегии для оптимизации сложных алгоритмов, наша система позволяет LLM не просто генерировать новые варианты кода, но и оценивать их производительность на заданном наборе данных. Результаты оценки автоматически передаются обратно в LLM, формируя цикл обратной связи, который направляет процесс эволюции кода к более эффективным решениям. Это обеспечивает более точное и эффективное улучшение кода, особенно в контексте сложных систем, таких как рекомендательные системы.

Self-EvolveRec: Автоматизированная Оптимизация в Действии
Self-EvolveRec представляет собой инновационную систему, использующую большие языковые модели (LLM) для непрерывной автоматической оптимизации кода рекомендательных систем. В отличие от традиционных подходов, Self-EvolveRec опирается не только на количественные метрики, такие как Normalized Discounted Cumulative Gain (NDCG) и Hit Ratio (HR), но и на качественные оценки, полученные в процессе работы системы. Это достигается путем итеративной модификации кода рекомендательной системы на основе комбинации этих двух типов обратной связи, что позволяет системе адаптироваться и улучшать качество рекомендаций в динамике без непосредственного вмешательства человека.
Для количественной оценки качества рекомендаций система Self-EvolveRec использует инструмент Model Diagnosis Tool, который анализирует метрики, такие как NDCG и HR. Дополнительно, для получения более детальной оценки, учитывающей нюансы пользовательского опыта, применяется User Simulator. Этот симулятор позволяет эмулировать поведение пользователей и предоставлять информацию о качестве рекомендаций, которая выходит за рамки стандартных количественных показателей, обеспечивая более полное понимание эффективности системы рекомендаций.
В основе Self-EvolveRec лежит механизм направленной обратной связи, динамически адаптирующий инструмент диагностики к изменяющейся архитектуре рекомендательной системы. Это позволяет системе оперативно реагировать на изменения, вносимые в процесс оптимизации. В ходе экспериментов на различных наборах данных, framework достиг показателей до 0.5138 NDCG@5 и 0.5070 Hit Ratio@5, превзойдя результаты базовых моделей. При этом, пиковая производительность достигалась всего за 8-11 итераций, что свидетельствует о высокой эффективности и скорости сходимости алгоритма.

За Пределами Современных Систем: Будущее Автоматизированного ML
Представленная работа значительно расширяет возможности Автоматизированного Машинного Обучения (AutoML), демонстрируя практическое применение эволюции кода на основе больших языковых моделей (LLM) в сложной, реальной предметной области. Вместо традиционных методов, полагающихся на предопределенный поиск в пространстве моделей, данное исследование использует LLM для итеративной модификации и улучшения исходного кода алгоритма рекомендаций. Этот подход позволяет системе самостоятельно адаптироваться к особенностям данных и требованиям задачи, что приводит к повышению производительности и снижению необходимости в ручной настройке. Фактически, система способна «самообучаться» путем анализа собственной работы и внесения изменений в код, подобно эволюционному процессу, что открывает новые перспективы для создания полностью автономных систем машинного обучения.
Разработанный подход демонстрирует значительное повышение эффективности рекомендательных систем, но его ключевым преимуществом является существенное снижение потребности в ручном вмешательстве. Автоматизация процесса оптимизации позволяет минимизировать затраты на разработку и поддержку, поскольку система способна самостоятельно адаптироваться к изменяющимся данным и требованиям. Это достигается за счет интеллектуального анализа и автоматической модификации кода, что освобождает специалистов от рутинных задач и позволяет им сосредоточиться на более сложных аспектах проекта. Снижение зависимости от человеческого фактора не только экономит ресурсы, но и повышает надежность и масштабируемость системы в долгосрочной перспективе.
Принципы, лежащие в основе Self-EvolveRec, обладают широкой применимостью, открывая перспективы для создания полностью автономных систем, способных к самооптимизации и адаптации в различных задачах машинного обучения. Данный подход демонстрирует устойчивую эффективность даже при работе с ограниченными объемами данных, что свидетельствует о высокой надежности и ресурсоэффективности системы. Это позволяет предполагать, что разработанная методология может быть успешно использована не только в рекомендательных системах, но и в других областях, требующих автоматической настройки и улучшения моделей, значительно снижая необходимость в ручном вмешательстве и обеспечивая постоянную адаптацию к меняющимся условиям.

Исследование демонстрирует, что системы рекомендаций, подобно любым сложным конструкциям, подвержены старению и требуют постоянной адаптации. Авторы предлагают Self-EvolveRec — механизм, позволяющий системе не просто оптимизироваться, но и эволюционировать, используя обратную связь от симулятора пользователя и инструмента диагностики модели. Как однажды заметил Брайан Керниган: «Отладка — это удаление ошибок; программирование — внесение новых». Эта фраза отражает суть подхода Self-EvolveRec — постоянное внесение изменений и корректировок для поддержания актуальности и эффективности системы, признавая, что любая абстракция несет груз прошлого и только медленные изменения сохраняют устойчивость. Вместо однократной оптимизации, предложенный фреймворк обеспечивает непрерывную эволюцию, что позволяет системе оставаться жизнеспособной в динамично меняющейся среде.
Куда Ведет Эволюция?
Представленная работа, безусловно, расширяет границы автоматизированной оптимизации рекомендательных систем. Однако, необходимо признать, что сама идея “самоэволюции” — это скорее признание неизбежной энтропии, нежели ее преодоление. Любая система, даже управляемая большими языковыми моделями, неминуемо столкнется с ограничениями симулятора пользователя и неполнотой инструментов диагностики. Вопрос не в достижении идеальной рекомендации, а в том, как достойно система адаптируется к неточностям и ошибкам, которые неизбежно возникают во времени.
Будущие исследования, вероятно, будут сосредоточены не столько на улучшении алгоритмов, сколько на создании более гибких и саморефлексивных систем. Необходимо разработать механизмы, позволяющие системе не только исправлять ошибки, но и извлекать уроки из неудач, формируя собственную “историю” и контекст. Интересным направлением представляется исследование возможности интеграции элементов случайности и непредсказуемости, имитирующих естественную эволюцию, а не строго детерминированную оптимизацию.
В конечном счете, успех подобных систем будет оцениваться не по абсолютной точности рекомендаций, а по их способности поддерживать долгосрочные отношения с пользователем, адаптируясь к меняющимся потребностям и предпочтениям. Время — это не метрика для измерения производительности, а среда, в которой система учится, ошибается и, возможно, со временем, достигает определенной формы зрелости.
Оригинал статьи: https://arxiv.org/pdf/2602.12612.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект и закон: гармония неизбежна
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Время и эмпатия: проверка ИИ-агентов на сложности распознавания эмоций.
- Предвидение будущего текста: новый подход к генерации
2026-02-16 11:53