Автор: Денис Аветисян
Исследователи представляют OpenLID-v3 — усовершенствованную систему определения языка, демонстрирующую высокую точность даже в сложных случаях и при работе с данными из интернета.
В статье подробно описаны принципы работы OpenLID-v3, результаты оценки на стандартных и специализированных бенчмарках, а также улучшения по сравнению с предыдущими версиями.
Определение языка текста является критически важным этапом при создании качественных многоязычных корпусов, однако существующие инструменты часто испытывают трудности в различении близкородственных языков и фильтрации шума. В данной работе, представленной в статье ‘OpenLID-v3: Improving the Precision of Closely Related Language Identification — An Experience Report’, описывается усовершенствование классификатора OpenLID путем расширения обучающих данных, объединения проблемных языковых кластеров и введения специальной метки для обозначения шума. Разработанная система OpenLID-v3 демонстрирует улучшенную точность на стандартных и специализированных бенчмарках, особенно при работе с близкородственными языками и данными, полученными из сети Интернет. Какие перспективы открываются для дальнейшего повышения качества автоматического определения языка в условиях все более сложных и разнообразных текстовых данных?
Вызовы Лингвистического Разнообразия
Автоматическое определение языка (LID) играет ключевую роль в развитии многоязыковой обработки естественного языка, однако существующие системы часто сталкиваются с трудностями при распознавании близкородственных языков и языков с ограниченными ресурсами. Проблема усугубляется тем, что языки, имеющие схожую лексику и грамматику, могут приводить к ошибкам классификации, а недостаток размеченных данных для менее распространенных языков ограничивает эффективность алгоритмов машинного обучения. Это создает существенные препятствия для создания универсальных и надежных систем, способных корректно обрабатывать тексты на всех языках мира, что особенно важно в контексте экспоненциального роста объемов онлайн-контента и необходимости точной фильтрации и анализа информации.
Неуклонный рост объемов информации в сети Интернет на множестве языков диктует необходимость создания надежных и точных систем автоматического определения языка. С увеличением числа онлайн-платформ и пользователей, генерирующих контент на различных языках, существующие методы часто оказываются неспособными эффективно справляться с этой задачей. Отсутствие универсальных и масштабируемых решений в области автоматического определения языка приводит к снижению качества автоматического перевода, некорректной фильтрации контента и затрудняет поиск необходимой информации для пользователей, говорящих на разных языках. Поэтому, разработка новых подходов к определению языка, способных обрабатывать огромные объемы данных и учитывать лингвистические особенности различных языков, является критически важной задачей для современной обработки естественного языка.
Традиционные методы автоматического определения языка (ЯОЯ) зачастую опираются на обширные, тщательно отобранные корпусы текстов, что создает существенные препятствия для языков с ограниченными ресурсами. Эффективность таких систем напрямую зависит от объема и качества обучающих данных, и языки, для которых подобные данные недоступны или представлены в недостаточном количестве, неизбежно демонстрируют более низкую точность распознавания. Это приводит к тому, что многие языки, особенно малораспространенные или находящиеся под угрозой исчезновения, остаются недостаточно охваченными современными технологиями обработки естественного языка, ограничивая доступ к информации и возможностям коммуникации для их носителей. Разработка альтернативных подходов, не требующих огромных объемов размеченных данных, является ключевой задачей для обеспечения лингвистического разнообразия в цифровом пространстве.
Неправильная идентификация языка может приводить к каскаду ошибок в последующих этапах обработки текста. Например, автоматический перевод, основанный на ошибочно определенном языке, выдаст бессмысленный или искаженный результат. Аналогично, системы фильтрации контента, полагающиеся на языковую принадлежность текста для блокировки нежелательного материала, могут либо пропустить вредоносную информацию, либо ошибочно заблокировать безобидный контент. В сфере информационного поиска некорректное определение языка может привести к тому, что релевантные документы будут проигнорированы, а пользователю предложены результаты на неверном языке, существенно снижая эффективность поиска и затрудняя доступ к необходимой информации. Таким образом, точность автоматической идентификации языка является критически важным фактором для обеспечения корректной работы всего конвейера обработки текста.
OpenLID-v3: Эволюция в Определении Языка
OpenLID-v3 представляет собой эволюционное развитие системы OpenLID-v2, включающее в себя значительные улучшения как в объеме и качестве обучающих данных, так и в архитектуре самой модели. В частности, увеличено количество языков, для которых обеспечена поддержка, и расширен набор текстов для обучения, что позволило повысить точность идентификации. Архитектурные изменения включают в себя оптимизацию алгоритмов классификации и использование более эффективных методов представления текста, что привело к снижению вычислительных затрат и повышению скорости работы системы. Эти улучшения направлены на повышение надежности и масштабируемости OpenLID-v3 для обработки больших объемов текстовых данных.
Иерархическое определение языка (Hierarchical LID) в OpenLID-v3 представляет собой подход, при котором языки классифицируются по многоуровневой структуре. Вместо прямого определения языка из всего доступного списка, система сначала определяет языковую семью или группу (например, романские языки, германские языки), а затем уточняет определение внутри этой группы. Такая иерархия позволяет значительно повысить точность классификации, особенно для языков, имеющих схожие характеристики, и снизить вычислительную сложность процесса, поскольку поиск ограничивается более узким подмножеством языков на каждом уровне классификации. Это особенно важно при обработке больших объемов текста, где скорость и точность являются критическими параметрами.
Система OpenLID-v3 использует библиотеку FastText для создания векторных представлений текста, что позволяет эффективно обрабатывать большие объемы данных. FastText представляет слова как n-граммы символов, что обеспечивает обработку редких слов и опечаток, а также позволяет учитывать морфологические особенности языка. Векторные представления, полученные с помощью FastText, имеют фиксированный размер, что значительно ускоряет процесс классификации и снижает требования к вычислительным ресурсам. Благодаря этому, OpenLID-v3 способна быстро и точно определять язык текста даже при обработке больших массивов данных, например, в задачах мониторинга социальных сетей или анализа многоязычного контента.
Улучшение производительности OpenLID-v3 достигается за счет применения методов аугментации данных. Данные методы включают в себя генерацию новых обучающих примеров путем незначительной модификации существующих, например, замена синонимов или незначительное изменение порядка слов. Это позволяет искусственно увеличить размер обучающей выборки, что повышает устойчивость модели к шуму и вариациям в тексте, а также улучшает её способность к обобщению на новые, ранее не встречавшиеся данные. Применение аугментации данных особенно эффективно для языков с ограниченными ресурсами, где объем доступных обучающих данных невелик.
Проверка и Валидация: Подтверждение Превосходства
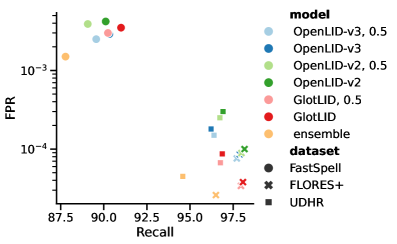
Система OpenLID-v3 прошла оценку с использованием общепринятых бенчмарков, таких как `FLORES+` и `UDHR`. Результаты демонстрируют конкурентоспособную и улучшенную точность определения языка во многих языковых группах. Бенчмарк `FLORES+` охватывает широкий спектр языков и диалектов, что позволило оценить способность системы к обобщению. Использование `UDHR` (Всеобщая декларация прав человека) обеспечило оценку производительности на текстах, доступных на множестве языков, подтверждая надежность системы при обработке разнообразных лингвистических данных.
Для дополнительной валидации производительности OpenLID-v3 использовался датасет HPLT 3.0, представляющий собой выборку веб-данных. Результаты показали высокую точность системы при определении языка на данных, полученных из сети Интернет. В частности, OpenLID-v3 продемонстрировал способность корректно идентифицировать язык веб-страниц и текстовых фрагментов, что подтверждает его пригодность для использования в задачах, связанных с анализом и обработкой веб-контента. Высокая точность на HPLT 3.0 указывает на эффективную работу системы с данными, характерными для реальной интернет-среды.
Сравнительный анализ OpenLID-v3 с существующими системами определения языка, такими как GlotLID, подтверждает преимущества подхода OpenLID-v3. В частности, комбинация (ансамблирование) GlotLID и OpenLID-v3 демонстрирует повышенную эффективность. Результаты показывают, что ансамблевая модель превосходит отдельные системы GlotLID и OpenLID-v3 по ключевым метрикам, обеспечивая более точное определение языка в различных тестовых наборах данных.
Комбинирование систем GlotLID и OpenLID-v3 посредством ансамблевого подхода позволило добиться минимального уровня ложноположительных срабатываний (False Positive Rate, FPR) на различных тестовых наборах данных. Экспериментальные результаты показали, что использование ансамбля привело к повышению общей точности определения языка по сравнению с использованием каждой системы по отдельности. Данное улучшение демонстрирует эффективность совместного использования моделей для повышения надежности и точности автоматического определения языка.
Включение в обучающую выборку данных на латыни и других исторических языках позволило повысить точность и расширить охват поддерживаемых языков в OpenLID-v3. Использование исторических данных способствует улучшению моделирования лингвистических особенностей современных языков, поскольку многие из них имеют общее происхождение и схожие структуры. Это особенно важно для языков с ограниченными ресурсами, где доступ к современным данным невелик, а исторические тексты могут служить ценным источником информации для обучения модели. Расширение языкового охвата включает в себя не только повышение точности идентификации распространенных языков, но и возможность определения менее распространенных или устаревших языковых форм.
Расширяя Лингвистические Горизонты: Последствия и Перспективы
Повышенная точность системы OpenLID-v3 открывает новые возможности для машинного перевода, значительно улучшая надёжность и качество межъязыковой коммуникации. Благодаря более точной идентификации языка, система способна корректно обрабатывать текст на различных языках, минимизируя ошибки и искажения при переводе. Это особенно важно для языков с ограниченными ресурсами, где точность идентификации часто бывает низкой. Повышенная надёжность перевода способствует более эффективному обмену информацией между людьми, говорящими на разных языках, и облегчает доступ к знаниям и культурным ценностям, представленным на различных языках. В конечном итоге, улучшенная идентификация языка является ключевым фактором для создания более естественных и понятных переводов, способствующих глобальному взаимодействию и сотрудничеству.
Повышенная точность определения языка (LID) играет ключевую роль в автоматизированной фильтрации и модерации контента в сети. Более точная идентификация языка позволяет системам эффективно выявлять и блокировать дезинформацию, вредоносный контент и онлайн-ненависть, распространяемые на различных языках. Это особенно важно в условиях глобального информационного потока, где быстрое и надежное выявление языка публикации необходимо для оперативного реагирования на угрозы и защиты пользователей от нежелательной информации. Благодаря улучшенному LID, платформы могут автоматически направлять контент на проверку модераторам, владеющим соответствующим языком, или использовать автоматические инструменты для блокировки нарушений, значительно повышая эффективность борьбы с онлайн-вредительством.
Открытый исходный код системы OpenLID-v3 создает благоприятную среду для коллективного развития в области многоязыковой обработки естественного языка. Предоставление доступа к коду позволяет исследователям и разработчикам по всему миру изучать, адаптировать и улучшать систему, способствуя появлению новых подходов и решений. Этот подход стимулирует инновации, поскольку сообщество может совместно решать сложные задачи, такие как поддержка малоресурсных языков или оптимизация алгоритмов для повышения эффективности. Благодаря коллективному вкладу, OpenLID-v3 имеет потенциал для быстрого развития и адаптации к постоянно меняющимся потребностям в области многоязыковой обработки информации, что делает её ценным инструментом для исследователей и практиков.
В перспективе разработчики планируют значительно расширить охват языков системы, уделив особое внимание улучшению производительности для языков с ограниченными ресурсами. Это предполагает не только добавление поддержки новых языков, но и совершенствование существующих алгоритмов для повышения точности и скорости обработки. Параллельно исследуются инновационные архитектуры, направленные на повышение эффективности системы в целом, что позволит снизить вычислительные затраты и сделать технологию более доступной для широкого круга пользователей и применений. Особое внимание уделяется поиску методов, позволяющих адаптировать систему к новым языкам и задачам с минимальными затратами ресурсов и усилий.
Разработка OpenLID-v3 демонстрирует стремление к созданию не просто инструмента, но и живой системы, способной адаптироваться к сложностям реальных данных. Как отмечал Дональд Дэвис: «Документация фиксирует структуру, но не передаёт поведение — оно рождается во взаимодействии». Это особенно актуально для задачи языковой идентификации, где необходимо учитывать не только формальные признаки, но и контекст, особенности сбора данных из сети и близость родственных языков. Улучшения в OpenLID-v3, направленные на повышение точности определения языков в сложных условиях, подтверждают эту мысль — система функционирует эффективно благодаря постоянному взаимодействию с данными и адаптации к их особенностям.
Куда двигаться дальше?
Развитие систем идентификации языка, как и любая инфраструктура, неизбежно сталкивается с необходимостью эволюционировать, а не перестраиваться. OpenLID-v3, безусловно, представляет собой шаг вперёд, но проблема различения близкородственных языков, особенно в шумных веб-данных, остаётся сложной. Необходимо сосредоточиться не только на совершенствовании алгоритмов классификации, но и на более глубоком понимании лингвистических особенностей, определяющих различия между языками на уровне морфологии и синтаксиса. Простое увеличение объёма обучающих данных не всегда является решением; важна их репрезентативность и качество.
Перспективным направлением представляется разработка систем, способных к адаптации к новым языкам и диалектам без необходимости полной переподготовки. Подобный подход, имитирующий способность живого организма к самоорганизации, позволит избежать жёсткой привязки к фиксированному набору языков и сделает системы более устойчивыми к изменениям в языковом ландшафте. Следует также уделить внимание разработке более надёжных метрик оценки, учитывающих специфику низкоресурсных языков и сложность различения близкородственных вариантов.
В конечном итоге, успех в этой области зависит не от создания всё более сложных моделей, а от стремления к элегантной простоте и ясности. Хорошая система идентификации языка должна быть подобна хорошо спроектированному городу: её инфраструктура должна развиваться органично, без необходимости перестраивать весь квартал при появлении нового жителя.
Оригинал статьи: https://arxiv.org/pdf/2602.13139.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект и закон: гармония неизбежна
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Нейросеть-Корректор: Новый Подход к Решению Сложных Задач
- Память на заказ: Новый подход к моделированию последовательностей
- Молекулярная динамика под присмотром ИИ: новый взгляд на химические процессы
- Предвидение будущего текста: новый подход к генерации
- От токенов к смыслу: новая стратегия адаптивной обработки больших языковых моделей
- Моделирование биомолекул: новый импульс от нейросетей
- За гранью ImageNet: Новый горизонт для машинного обучения в экологии
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
2026-02-16 23:46