Автор: Денис Аветисян
Новый подход позволяет эффективно развертывать сложные алгоритмы искусственного интеллекта в реальном мире, снижая требования к вычислительным ресурсам и энергопотреблению.

Предложена схема совместного вывода больших моделей ИИ с учетом квантования и распределения ресурсов для воплощенных систем.
Несмотря на растущую роль больших искусственных интеллектов в воплощенных системах, их вычислительные требования остаются серьезным препятствием для развертывания на ресурсоограниченных устройствах. В данной работе, посвященной ‘Quantization-Aware Collaborative Inference for Large Embodied AI Models’, предложен фреймворк, оптимизирующий совместное инференсное вычисление больших моделей путем совместного проектирования стратегий квантования и распределения вычислительных ресурсов. Полученные теоретические оценки верхней и нижней границ искажений, вызванных квантованием, позволяют минимизировать потери качества при соблюдении ограничений по задержке и энергопотреблению. Сможет ли предложенный подход обеспечить эффективное развертывание сложных ИИ-систем непосредственно на грани вычислений, открывая новые возможности для автономных агентов?
Воплощенный Искусственный Интеллект: От Теории к Практике
Современные достижения в области робототехники и искусственного интеллекта диктуют необходимость создания систем, способных не только обрабатывать информацию, но и активно взаимодействовать с окружающим миром, воспринимая его, понимая и адекватно реагируя на изменения. Это привело к формированию новой области — воплощенному искусственному интеллекту (Embodied AI), где акцент делается на интеграции интеллектуальных алгоритмов с физическими телами — роботами, дронами или другими устройствами. Такие системы, в отличие от чисто программных решений, способны к непосредственному восприятию реальности через сенсоры, что позволяет им адаптироваться к непредсказуемым условиям и решать задачи, требующие физического взаимодействия с окружающей средой. Развитие Embodied AI открывает новые возможности для автоматизации сложных процессов, создания автономных помощников и расширения границ человеческих возможностей.
Для эффективного функционирования в сложных условиях реального мира, воплощенный искусственный интеллект требует наличия мощного ядра — больших языковых моделей (БЯМ). Эти модели обеспечивают обработку поступающей информации, позволяя системе понимать окружающую обстановку и принимать обоснованные решения. БЯМ способны анализировать разнообразные данные — от визуальных образов до текстовых команд — и, используя накопленные знания, формировать адекватные поведенческие стратегии. Их ключевая роль заключается в предоставлении интеллекта, необходимого для автономной навигации, взаимодействия с объектами и адаптации к меняющимся условиям, что делает БЯМ незаменимым компонентом современных интеллектуальных агентов.
Внедрение крупных языковых моделей (LLM) в реальные приложения, такие как робототехника и автономные системы, сталкивается со значительными трудностями, связанными с потреблением вычислительных ресурсов и энергоэффективностью. Эти модели, демонстрирующие впечатляющие возможности в лабораторных условиях, требуют огромных объемов памяти и вычислительной мощности для обработки данных и принятия решений в режиме реального времени. Это создает проблемы для развертывания на мобильных устройствах или в условиях ограниченных ресурсов, где энергопотребление и стоимость вычислений являются критическими факторами. Разработка более компактных и эффективных алгоритмов, а также использование специализированного аппаратного обеспечения, такого как нейроморфные чипы, становится ключевым направлением исследований для преодоления этих ограничений и обеспечения широкого применения интеллектуальных агентов в различных сферах.
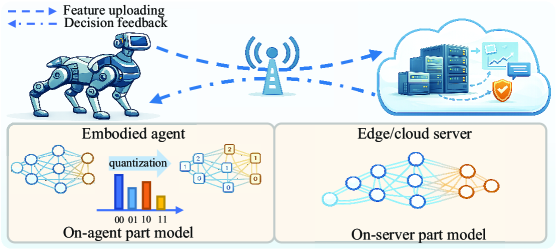
Стратегии Развертывания: Локальная Обработка vs. Облачные Решения
Традиционные подходы к развертыванию моделей искусственного интеллекта (ИИ) основываются на двух основных стратегиях: обработке на устройстве (on-device) и обработке в облаке (on-cloud). Обработка на устройстве подразумевает выполнение вычислений непосредственно на конечном устройстве, что обеспечивает минимальную задержку (latency) и быстрое время отклика. Однако, ресурсы таких устройств, как правило, ограничены в плане вычислительной мощности, памяти и энергопотребления. В отличие от этого, облачная обработка использует удаленные серверные ресурсы, предлагая практически неограниченные возможности для вычислений и хранения данных. Недостатком облачного подхода является зависимость от стабильного сетевого соединения и потенциальная задержка, связанная с передачей данных между устройством и сервером. Выбор между этими стратегиями определяется конкретными требованиями приложения и доступными ресурсами.
Развертывание моделей искусственного интеллекта непосредственно на устройстве обеспечивает повышенную конфиденциальность данных, поскольку обработка происходит локально, без передачи информации во внешние системы. Это также обеспечивает более высокую скорость отклика и меньшую задержку, что критично для приложений реального времени. Однако, ресурсы вычислительной мощности и памяти конечных устройств ограничены, что накладывает ограничения на сложность и размер развертываемых моделей. В противоположность этому, облачное развертывание позволяет использовать практически неограниченные вычислительные ресурсы, что обеспечивает возможность масштабирования и обработки больших объемов данных. Кроме того, облачные решения часто более экономически эффективны за счет использования модели оплаты по мере использования. В то же время, облачное развертывание требует стабильного сетевого подключения и связано с потенциальными рисками, связанными с безопасностью и конфиденциальностью передаваемых данных.
Эффективная реализация LAIM (Lightweight AI Models) является критически важной для обеих стратегий развертывания — как на конечном устройстве, так и в облаке. Размер модели и вычислительная сложность напрямую влияют на производительность и энергопотребление. Для развертывания на устройствах с ограниченными ресурсами требуется оптимизация модели, включая квантизацию, прунинг и дистилляцию знаний, чтобы уменьшить ее размер и снизить вычислительные затраты. В облачных средах, хотя и доступно больше ресурсов, оптимизация LAIM все равно важна для повышения масштабируемости, снижения задержек и уменьшения эксплуатационных расходов.
Совместный Вывод: Синтез Возможностей
Совместный вывод (co-inference) представляет собой перспективный подход к оптимизации производительности и эффективности задач машинного обучения, основанный на распределении вычислительной нагрузки между различными платформами — непосредственно устройством, граничными серверами (edge) и облачными вычислениями. Данная техника позволяет задействовать сильные стороны каждой платформы: сложные вычислительные операции выполняются в облаке, а задачи, требующие минимальной задержки и быстрого отклика, обрабатываются локально на устройстве или на граничных серверах. Такой подход позволяет снизить общие затраты энергии и повысить скорость обработки данных, что особенно важно для приложений, работающих в реальном времени и требующих высокой отзывчивости.
Техника совместного вывода (co-inference) предполагает распределение вычислительной нагрузки между различными вычислительными средами — устройством, периферийными вычислениями (edge) и облаком — для оптимизации производительности и энергоэффективности. Вычислительно сложные операции, требующие значительных ресурсов, переносятся в облако, в то время как задачи, критичные к задержке и требующие немедленного отклика, выполняются локально на устройстве или на периферии. Такой подход позволяет использовать преимущества каждой среды: высокую вычислительную мощность облака и низкую задержку локальных вычислений, обеспечивая баланс между скоростью обработки и потреблением энергии.
Практическая эффективность совместного вывода (co-inference) была продемонстрирована в ходе экспериментов с использованием моделей BLIP-2 и GIT, а также на наборах данных MS-COCO и VaTeX. В ходе тестов было показано, что распределение вычислительной нагрузки между различными платформами — устройствами, периферийными серверами и облаком — позволяет оптимизировать производительность и энергопотребление. Особенно заметные улучшения наблюдались при обработке задач компьютерного зрения и обработки естественного языка, что подтверждает применимость данного подхода в реальных сценариях использования.
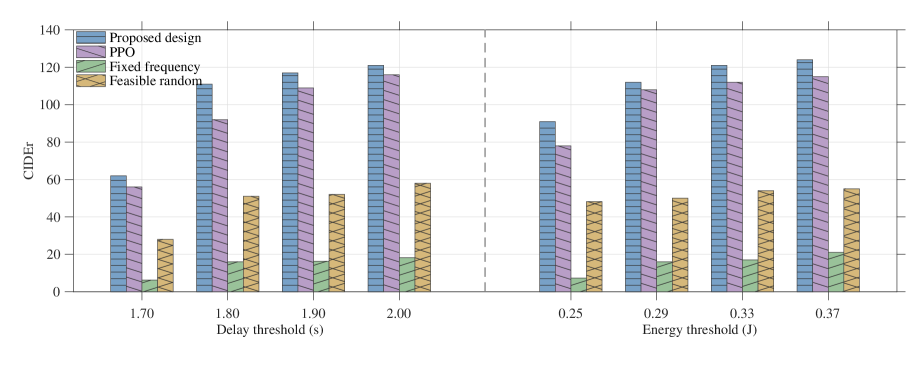
Эффективность совместного вывода (co-inference) ограничена как временными задержками, так и энергопотреблением. Данная работа представляет теоретическую основу для количественной оценки компромиссов между этими ограничениями. Предложенная модель была верифицирована на различных архитектурах, включая FCDNN-16, BLIP-2 и GIT, демонстрируя возможность анализа и прогнозирования влияния распределения вычислительной нагрузки между устройствами, краем сети и облаком на общую производительность и энергоэффективность системы. Полученные границы rate-distortion согласуются с численно оцененными функциями distortion-rate, что обеспечивает характеристику поведения системы в зависимости от скорости передачи данных и уровня искажений.
Оптимизация Моделей: Квантизация и Прунинг
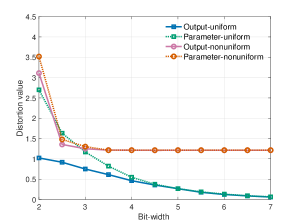
Квантизация, заключающаяся в уменьшении разрядности параметров модели, является эффективным методом снижения её размера и вычислительной сложности. Данный подход основан на принципах теорииRate-Distortion, которая устанавливает взаимосвязь между скоростью передачи данных (разрядностью) и искажениями (потерей точности). Уменьшение разрядности, например, с 32-битной плавающей точки до 8-битного целого числа, позволяет существенно сократить объём памяти, необходимый для хранения модели, и снизить требования к вычислительным ресурсам при выполнении операций. При этом необходимо учитывать, что чрезмерное снижение разрядности может привести к заметной потере точности модели, поэтому выбор оптимальной разрядности является компромиссом между степенью сжатия и сохранением приемлемого уровня производительности.
Как равномерная, так и неравномерная квантизация предоставляют различные компромиссы между степенью сжатия и точностью модели. Равномерная квантизация, используя одинаковый шаг квантования для всех параметров, обеспечивает более высокую скорость вычислений и простоту реализации, но может приводить к значительным потерям точности при высокой степени сжатия. Неравномерная квантизация, напротив, позволяет адаптировать шаг квантования к распределению параметров, что обеспечивает лучшую точность при той же степени сжатия, но требует дополнительных вычислительных затрат и более сложной реализации. Выбор между этими методами зависит от конкретных требований к скорости, точности и ресурсам, доступным для развертывания модели.
Удаление избыточных параметров или нейронов, известное как прунинг (pruning), является эффективным методом снижения вычислительной сложности модели без существенной потери производительности. Этот процесс заключается в выявлении и удалении наименее значимых весов или целых нейронов, что приводит к уменьшению размера модели и снижению требований к памяти и вычислительным ресурсам. Существуют различные стратегии прунинга, включая неструктурированный прунинг (удаление отдельных весов) и структурированный прунинг (удаление целых каналов или слоев). Эффективность прунинга зависит от степени избыточности в модели и выбранного алгоритма прунинга, однако при правильной реализации позволяет значительно сократить размер модели без значительного ухудшения точности.
Оптимизация моделей, включающая квантизацию и прунинг, является критически важной для эффективного развертывания LAIM (Lightweight AI Models) на периферийных устройствах с ограниченными ресурсами. Данный подход, основанный на снижении точности параметров и удалении избыточных элементов, демонстрирует стабильное превосходство над эталонными схемами как в симуляционных средах, так и в реальных тестовых конфигурациях. Результаты тестов показывают, что оптимизированные модели обеспечивают снижение вычислительных затрат и уменьшение занимаемого объема памяти, что делает их пригодными для использования на устройствах с ограниченной мощностью и памятью.
Будущие Направления: Интеллектуальная, Эффективная AI-RAN
Схождение воплощенного искусственного интеллекта, совместного вывода и оптимизации моделей открывает путь к созданию интеллектуальных и эффективных архитектур AI-RAN. Воплощенный ИИ, интегрируя восприятие и действия в физическом мире, позволяет системам адаптироваться к динамичным условиям окружающей среды. Совместный вывод, объединяя возможности нескольких моделей и устройств, значительно повышает надежность и точность обработки данных. А оптимизация моделей, направленная на снижение вычислительных затрат и энергопотребления, обеспечивает масштабируемость и устойчивость AI-RAN. В результате, эти взаимосвязанные направления исследований формируют основу для разработки систем связи нового поколения, способных к автономной работе, эффективному управлению ресурсами и предоставлению услуг с минимальными задержками, что критически важно для развития робототехники и автономных систем.
Новый подход в архитектуре AI-RAN открывает возможности для создания принципиально нового поколения робототехнических и автономных систем. Эти системы смогут эффективно функционировать в сложных, динамично меняющихся реальных условиях, преодолевая ограничения, связанные с нестабильностью связи и ограниченностью ресурсов. Благодаря интеграции интеллектуальных алгоритмов и оптимизированных моделей, они будут способны адаптироваться к различным сценариям, обеспечивая надежную и бесперебойную работу в условиях помех, меняющейся загруженности сети и непредсказуемости окружающей среды. Это позволит расширить сферу применения автономных систем, включая логистику, сельское хозяйство, мониторинг окружающей среды и даже поисково-спасательные операции, где надежность и адаптивность являются критически важными.
Перспективные исследования в области интеллектуальных радиосетей (AI-RAN) сосредоточены на разработке адаптивных стратегий оптимизации, способных динамически подстраиваться к изменяющимся условиям ресурсов и требованиям приложений. Данный подход предполагает создание алгоритмов, которые не просто настраивают параметры сети, но и предвидят изменения в нагрузке, доступности спектра и энергопотреблении. Особое внимание уделяется разработке самообучающихся систем, использующих методы машинного обучения для анализа данных в реальном времени и принятия оптимальных решений по распределению ресурсов. Такая динамическая оптимизация позволит значительно повысить эффективность использования сетевых ресурсов, снизить задержки и обеспечить надежную связь даже в условиях высокой загруженности или неблагоприятных внешних факторов, открывая новые возможности для роботизированных систем и автономных устройств.
В конечном итоге, прогресс в области интеллектуальных сетей радиодоступа (AI-RAN) обещает коренным образом изменить природу искусственного интеллекта, сделав его не только более отзывчивым и надежным, но и значительно более энергоэффективным. Разработка адаптивных алгоритмов оптимизации и интеграция воплощенного искусственного интеллекта позволяют создавать системы, способные динамически подстраиваться под изменяющиеся условия и потребности, минимизируя потребление ресурсов. Такой подход открывает новые возможности для широкого спектра приложений, от роботизированных систем, действующих в сложных условиях, до автономных устройств, требующих длительной работы от одного заряда. В результате, искусственный интеллект будущего сможет не просто решать задачи, но и делать это разумно, эффективно и с минимальным воздействием на окружающую среду.
Исследование демонстрирует стремление к упрощению сложных систем, что находит отклик в философии Брайана Кернигана. Он однажды сказал: «Простота — это высшая степень совершенства». Работа, представленная в статье, акцентирует внимание на оптимизации совместного вывода больших моделей искусственного интеллекта, используя квантование и распределение ресурсов. Этот подход направлен на снижение вычислительных затрат и задержек, что, по сути, является попыткой достичь элегантности и эффективности в реализации сложных алгоритмов. Авторы, подобно Кернигану, стремятся к ясности и избегают ненужных усложнений, чтобы обеспечить более широкую применимость и доступность технологий воплощенного искусственного интеллекта.
Куда Дальше?
Представленная работа, хоть и демонстрирует элегантное решение в области совместного вывода для крупных моделей воплощенного искусственного интеллекта, лишь осторожно касается краеугольных проблем. Оптимизация, основанная на компромиссе между скоростью и точностью, неизбежно ведет к вопросу: где та грань, за которой снижение вычислительных затрат становится неприемлемым упрощением реальности? Более того, акцент на распределении ресурсов предполагает статичность среды, что является несомненным упрощением для систем, функционирующих в динамичном мире.
Истинным вызовом представляется не просто увеличение эффективности существующих моделей, а разработка принципиально новых подходов к их построению. Необходимо сместить фокус с оптимизации вычислений на оптимизацию представления информации. До тех пор, пока модели будут стремиться к полному воспроизведению сложности мира, они останутся обременительными и непрактичными. Простота — не ограничение, а проявление интеллекта.
В перспективе, исследования должны быть направлены на создание моделей, способных к адаптивному самообучению и самооптимизации, минимизирующих потребность в ручном вмешательстве и предварительной настройке. Иначе, все усилия по оптимизации вычислений превратятся в бесконечную гонку за ускользающей эффективностью, не приближающую нас к истинному пониманию.
Оригинал статьи: https://arxiv.org/pdf/2602.13052.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Искусственный интеллект и закон: гармония неизбежна
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- За гранью ImageNet: Новый горизонт для машинного обучения в экологии
- Звук как помощник зрения: Новые горизонты генерации видео
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Искусственный интеллект и эксперт: как совместная работа меняет Data Science
- Моделирование биомолекул: новый импульс от нейросетей
- Геометрия устойчивости: новый взгляд на представления в нейросетях
- БиоАгент: Проверка ИИ на прочность в мире геномики
2026-02-17 03:13