Автор: Денис Аветисян
Исследователи представили MXFormer — архитектуру, использующую инновационные транзисторы и микромасштабирование данных для значительного повышения производительности и энергоэффективности при обработке коротких последовательностей.
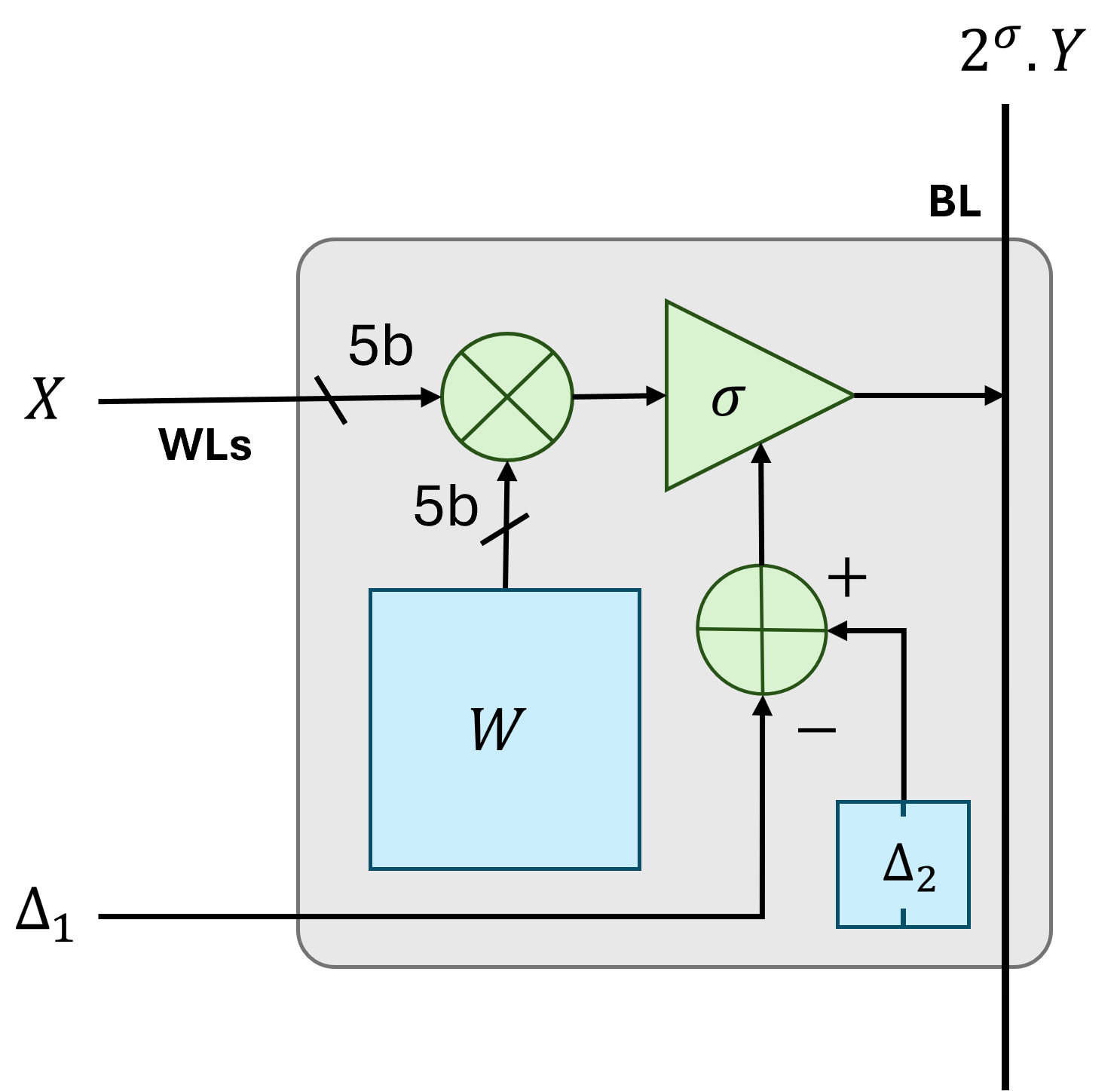
Ускоритель MXFormer использует транзисторы с плавающим затвором и вычисления в памяти для эффективной реализации архитектуры Transformer.
Развертывание моделей Transformer часто сдерживается значительными вычислительными затратами и пропускной способностью памяти. В данной работе представлена архитектура ‘MXFormer: A Microscaling Floating-Point Charge-Trap Transistor Compute-in-Memory Transformer Accelerator’, — гибридный, весо-стационарный (weight-stationary) ускоритель вычислений в памяти (CIM), использующий Charge-Trap Transistors (CTT) и микромасштабированные форматы данных (MXFP4) для достижения высокой эффективности при выводе Transformer для коротких последовательностей. Предложенная реализация демонстрирует существенное увеличение вычислительной плотности и энергоэффективности по сравнению с существующими цифровыми, гибридными и фотонными ускорителями, обеспечивая до 60.5-кратного прироста производительности. Сможет ли данный подход стать основой для создания энергоэффективных и высокопроизводительных систем искусственного интеллекта, способных работать на периферийных устройствах?
Преодолевая Квадратичную Сложность: Вызовы Масштабируемости Трансформеров
Архитектура Transformer произвела революцию в области моделирования последовательностей, однако её квадратичная сложность представляет собой серьезное ограничение для масштабируемости при работе с длинными последовательностями и сложными задачами. В основе этой проблемы лежит необходимость вычисления внимания между каждой парой элементов входной последовательности, что приводит к экспоненциальному росту вычислительных затрат и потребления памяти с увеличением длины последовательности. Это особенно критично в приложениях, требующих обработки больших объемов данных, таких как обработка естественного языка, компьютерное зрение и анализ временных рядов. Вследствие этого, для эффективной работы с крупномасштабными задачами необходимо разрабатывать новые методы, направленные на снижение вычислительной сложности архитектуры Transformer, сохраняя при этом её высокую точность и эффективность.
Традиционные методы обработки информации, применимые к моделям на основе трансформеров, сталкиваются с существенными трудностями при работе с постоянно растущими объемами данных и увеличением размеров самих моделей. По мере увеличения количества параметров и сложности задач, вычислительные затраты возрастают экспоненциально, что приводит к замедлению обучения и снижению эффективности работы. Сохранение высокой точности при одновременном обеспечении приемлемой скорости обработки становится все более сложной задачей, требующей разработки новых подходов к оптимизации архитектуры и алгоритмов. В частности, существующие методы часто оказываются неспособными эффективно использовать доступные вычислительные ресурсы, что ограничивает возможность масштабирования моделей для решения задач, требующих обработки больших объемов данных и сложных зависимостей.
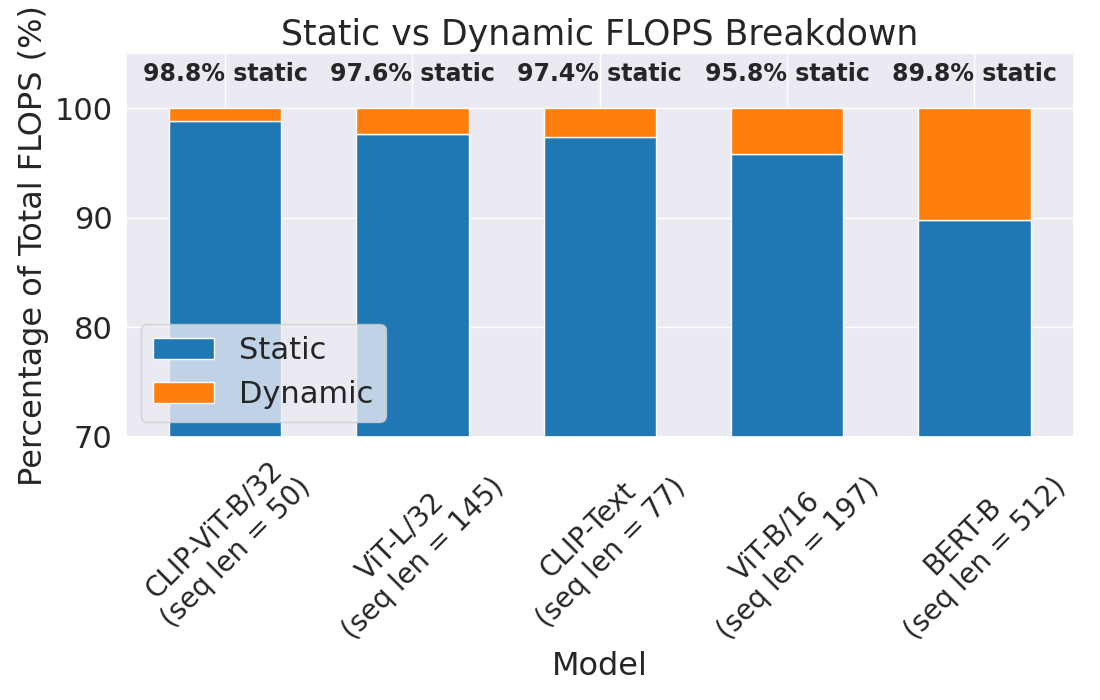
Особую остроту проблема масштабируемости приобретает в задачах визуального рассуждения, где обработка изображений требует огромных вычислительных ресурсов. Традиционные подходы оказываются неэффективными при увеличении разрешения изображений и сложности сцен, что ограничивает возможности моделей в понимании визуальной информации. В связи с этим, разработка новых методов снижения вычислительной нагрузки становится критически важной. Исследования в этой области направлены на создание архитектур и аппаратных ускорителей, способных эффективно обрабатывать визуальные данные. Так, предложенный аппаратный ускоритель демонстрирует впечатляющую производительность, достигая 58.3 тысячи кадров в секунду (FPS) при обработке модели ViT-L/32, что открывает новые перспективы для задач, требующих обработки видео в реальном времени и сложных визуальных рассуждений.
Микромасштабирование: Баланс Между Точностью и Производительностью
Микромасштабирование (MX) представляет собой перспективное решение для снижения требований к памяти и ускорения вычислений за счет использования низкоточных числовых представлений. Вместо стандартных 32- или 16-битных чисел, MX использует форматы с меньшей разрядностью, что позволяет существенно уменьшить объем необходимой памяти для хранения данных и, как следствие, повысить скорость обработки. Снижение точности неизбежно влечет за собой некоторую потерю информации, однако, при грамотной реализации и применении к определенным типам задач, эта потеря может быть минимальной и компенсироваться значительным увеличением производительности. Такой подход особенно актуален для задач машинного обучения и глубокого обучения, где большие объемы данных и интенсивные вычисления являются нормой.
Формат Microscaling MXFP4 использует 4-битное представление для элементов данных и 8-битный экспонент, что обеспечивает значительное сжатие данных. Такая структура позволяет снизить требования к памяти, сохраняя при этом приемлемую точность вычислений. Соотношение сжатия достигается за счет уменьшения разрядности представления чисел, в то время как 8-битный экспонент позволяет сохранить широкий динамический диапазон, минимизируя потери точности при работе с различными масштабами значений. Практическая реализация MXFP4 демонстрирует возможность существенного снижения объема памяти, необходимого для хранения данных, без критического снижения производительности и точности вычислений.
Эффективное использование формата MXFP4 требует применения стратегий конвертации, в частности, преобразования MXFP4 в BF16, для обеспечения совместимости с существующими аппаратными и программными платформами. Конвертация в BF16 позволяет использовать преимущества существующих оптимизаций и библиотек, разработанных для работы с форматами пониженной точности. Практическая реализация данной стратегии позволяет достичь пиковой производительности в диапазоне 2.3-3.9 TOPS/mm², что подтверждает эффективность MXFP4 в задачах, требующих высокой скорости вычислений и ограниченных ресурсов памяти.
Систолические Массивы и Gemmini: Аппаратное Ускорение Вычислений
Архитектуры систолических массивов представляют собой эффективное решение для ускорения матричных операций, которые являются основой для многих рабочих нагрузок глубокого обучения. В отличие от традиционных архитектур, где данные перемещаются между памятью и процессором, систолические массивы организуют вычисления таким образом, чтобы данные оставались локализованными и повторно использовались несколькими вычислительными элементами. Это существенно снижает потребность в доступе к внешней памяти, которая является узким местом в большинстве современных систем. Принцип работы заключается в последовательном прохождении данных через массив вычислительных элементов, где на каждом шаге выполняются простые операции, такие как умножение и сложение. Такая организация позволяет достичь высокой степени параллелизма и эффективности использования ресурсов, особенно при обработке больших матриц, характерных для нейронных сетей и других приложений машинного обучения.
Gemmini представляет собой специализированную архитектуру систолического массива, разработанную для эффективного выполнения цифровых этапов в системах искусственного интеллекта. Ключевым принципом работы Gemmini является повторное использование данных (data reuse), что позволяет минимизировать перемещение данных между памятью и вычислительными элементами. Архитектура также активно использует параллелизм, позволяя одновременно выполнять множество операций над различными частями данных. Это достигается за счет организации вычислительных элементов в виде массива, где каждый элемент выполняет небольшую часть общей задачи, а результаты передаются соседним элементам. Такая структура позволяет значительно повысить пропускную способность и энергоэффективность при выполнении операций, характерных для цифровых этапов AI, таких как умножение матриц и активационные функции.
Интеграция оптимизаций, таких как FlashAttention, с архитектурами систолических массивов позволяет значительно повысить производительность. Достигнутая пиковая пропускная способность составляет от 3.1 до 14.5 TOPS/W, при плотности хранения весов 1756 кб/мм², что в 50 раз превышает показатели предыдущих разработок. Данное улучшение достигается за счет эффективного использования повторного использования данных и параллелизма, характерных для систолических массивов, в сочетании с алгоритмическими оптимизациями FlashAttention, направленными на снижение вычислительной сложности и объема необходимой памяти.
![В представленной систолической матрице каждый элемент обрабатывает только два блока MXFP ([𝐐\mathbf{Q}] и [𝐊\mathbf{K}^{\mathsf{T}}]) на каждые 32 входных и весовых значения, причем блоки [𝐐\mathbf{Q}] квантуются по строкам, а матрица [𝐊\mathbf{K}] - в формате строчной MXFP-квантизации.](https://arxiv.org/html/2602.12480v1/systolic_array_mxfp.drawio.png)
Представленная работа демонстрирует стремление к оптимизации вычислительных систем, акцентируя внимание на эффективности и скорости обработки информации. Подобный подход к проектированию, с использованием инновационных технологий вроде compute-in-memory и микромасштабирования данных, неизбежно влечет за собой компромиссы. Как отмечал Андрей Колмогоров: «Математика — это искусство упрощения». В данном исследовании упрощение достигается за счет использования Charge Trap Transistors и новых форматов данных, однако, как и любое упрощение, оно требует тщательного анализа и понимания возможных последствий для точности и надежности вычислений. Архитектура MXFormer, будучи weight-stationary, стремится к минимизации перемещения данных, что, в свою очередь, снижает энергопотребление и повышает производительность, но требует продуманной организации памяти и эффективного использования доступных ресурсов.
Куда Далее?
Представленная работа, подобно любому коммиту в летописи вычислительных архитектур, фиксирует состояние на определенный момент. MXFormer демонстрирует потенциал микромасштабирования и вычислений в памяти для ускорения трансформеров, но, как и любая оптимизация, не избавляет от фундаментальных ограничений. Задержка с внедрением столь перспективных решений — неизбежный налог на амбиции, особенно учитывая сложность интеграции аналоговых вычислений в существующие цифровые инфраструктуры. Вопрос не в том, насколько быстро можно ускорить вычисления, а в том, насколько долговечным окажется сам подход в условиях постоянно меняющихся требований к моделям и данным.
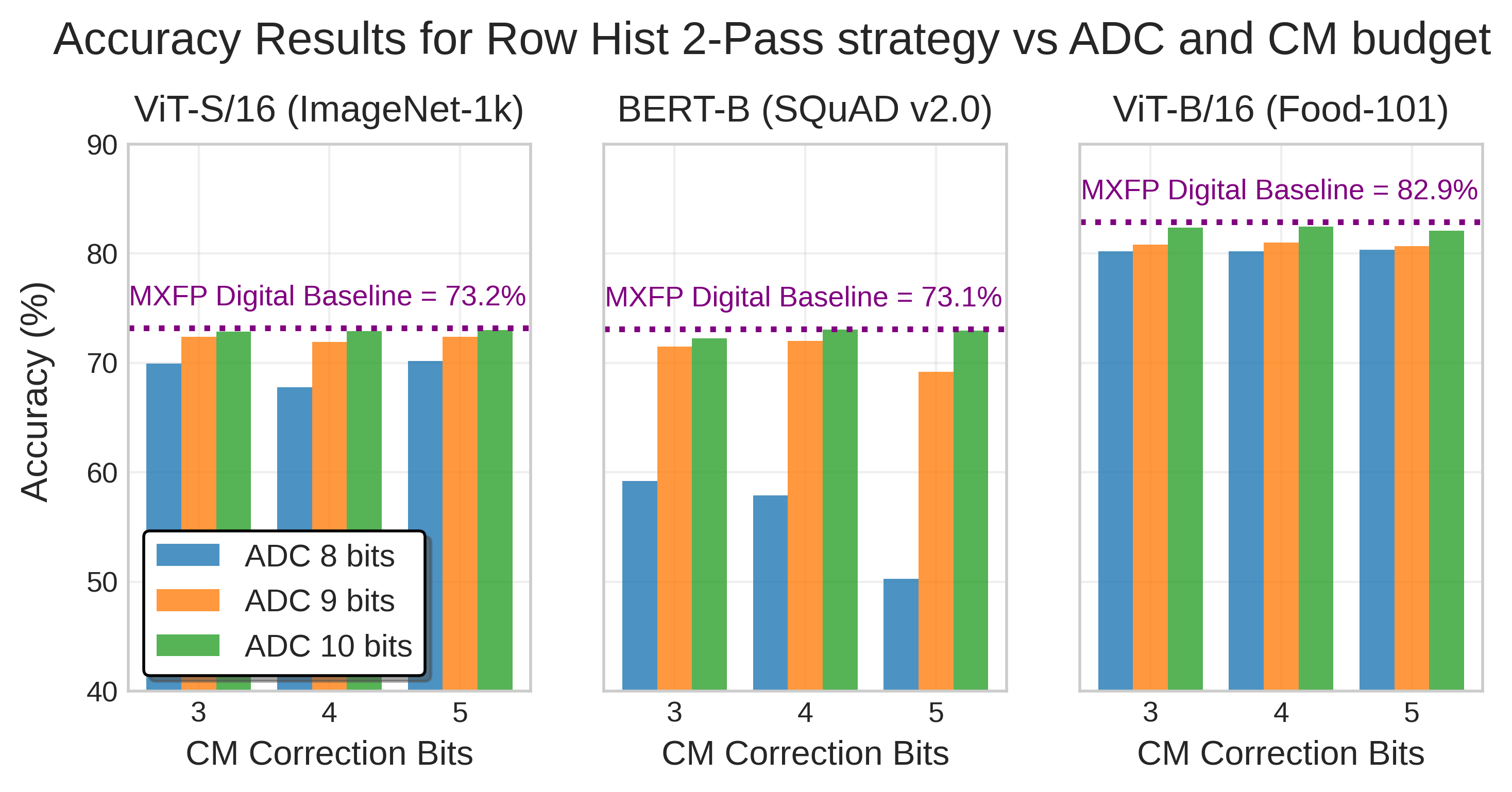
Будущие исследования неизбежно столкнутся с необходимостью преодоления ограничений, связанных с точностью аналоговых вычислений и масштабируемостью представленной архитектуры. Более глубокое изучение компромисса между точностью и энергоэффективностью, а также поиск новых материалов и технологий для создания более надежных и долговечных charge-trap транзисторов представляется критически важным. Переход от ускорения коротких последовательностей к более сложным моделям и задачам потребует разработки новых алгоритмов и архитектурных решений, способных эффективно использовать преимущества вычислений в памяти.
В конечном счете, ценность MXFormer не только в достигнутых результатах, но и в том, что он подчеркивает необходимость переосмысления традиционных подходов к проектированию вычислительных систем. Каждый шаг вперед — это лишь новая глава в истории, и каждый коммит должен быть осмысленным, а каждая версия — достойно стареть.
Оригинал статьи: https://arxiv.org/pdf/2602.12480.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект и закон: гармония неизбежна
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Звук как помощник зрения: Новые горизонты генерации видео
- Иллюзии понимания: Как правильно оценивать объяснимые модели
- Поймать изменчивый сигнал: Как нейросети расшифровывают политику ФРС
- Искусственный интеллект и эксперт: как совместная работа меняет Data Science
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Геометрия устойчивости: новый взгляд на представления в нейросетях
- БиоАгент: Проверка ИИ на прочность в мире геномики
2026-02-17 03:18