Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий моделям понимать изображения на более тонком уровне, без необходимости многократного увеличения и обработки отдельных фрагментов.
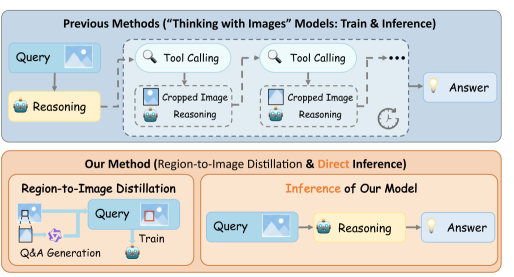
В статье представлена техника Region-to-Image Distillation для повышения точности мультимодальных больших языковых моделей в задачах визуального обоснования и агентского использования инструментов.
Несмотря на успехи больших мультимодальных языковых моделей в понимании изображений, точное восприятие мелких деталей часто уступает глобальному контексту. В работе ‘Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception’ предложен новый подход — дистилляция знаний из локальных областей изображения в полную картину, позволяющая модели эффективно воспринимать детали без итеративного «приближения» во время работы. Авторы демонстрируют, что обучение на данных, полученных путем фокусировки на микро-областях, позволяет значительно улучшить точность распознавания мелких деталей в задачах визуального вопросно-ответного анализа. Может ли такая дистилляция преимуществ «мышления с изображениями» открыть путь к более эффективным и экономичным мультимодальным системам?
Тонкости Визуального Восприятия: Преодоление Границ
Современные мультимодальные большие языковые модели (MLLM) демонстрируют впечатляющие результаты в понимании изображений на общем уровне, однако сталкиваются с трудностями при анализе тонких деталей и нюансов визуальной информации. В то время как MLLM легко справляются с определением основных объектов и сцен, распознавание сложных атрибутов, незначительных изменений или специфических взаимосвязей между элементами изображения представляет значительную проблему. Эта ограниченность в детализированном восприятии снижает эффективность моделей в задачах, требующих высокой точности визуального анализа, таких как диагностика дефектов, идентификация редких объектов или интерпретация сложных схем и диаграмм. Неспособность улавливать тонкости визуальной информации ограничивает потенциал MLLM в широком спектре практических приложений, где требуется не просто общее понимание изображения, а детальный анализ его компонентов.
Ограниченность возможностей в точном визуальном анализе существенно влияет на эффективность современных мультимодальных больших языковых моделей при решении задач, требующих выявления тонких деталей и взаимосвязей между объектами. Например, модели могут испытывать трудности при определении незначительных повреждений на изображении, распознавании едва заметных изменений в текстуре поверхности или установлении сложных пространственных отношений между отдельными элементами сцены. Это связано с тем, что способность к детализированному восприятию играет ключевую роль в понимании контекста и принятии обоснованных решений, особенно в областях, где важна каждая деталь, таких как медицинская диагностика, контроль качества или анализ спутниковых снимков. Неспособность к точному визуальному анализу ограничивает применимость этих моделей в критически важных задачах, где даже небольшая ошибка может привести к значительным последствиям.
Существующие подходы к детализированному визуальному анализу часто полагаются на итеративное увеличение масштаба — многократное повторное кодирование отдельных областей изображения. Такой метод, несмотря на свою интуитивность, оказывается вычислительно затратным и неэффективным, поскольку требует значительных ресурсов для обработки каждого увеличенного фрагмента. В результате, время обработки значительно увеличивается, что делает подобные решения непригодными для задач, требующих оперативной реакции. В отличие от этого, предлагаемый метод позволяет достичь сопоставимой, а зачастую и более высокой точности анализа, избегая необходимости в многократном перекодировании, что существенно ускоряет процесс и снижает вычислительную нагрузку.
Дистилляция Знаний по Областям: Новый Подход к Обучению
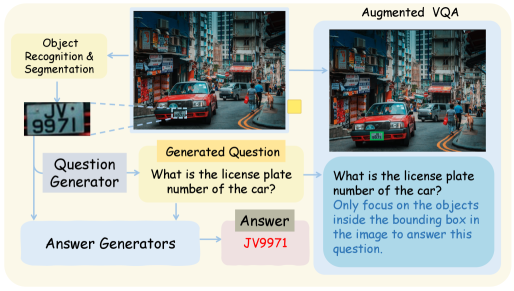
Метод Region-to-Image Distillation предполагает синтез данных для задачи Визуального Ответ-Вопрос (VQA) на небольших фрагментах изображений — так называемых регионах. Вместо обработки изображений целиком, обучающий процесс фокусируется на локальных участках, что позволяет модели изучать детализированное визуальное восприятие. Синтезированные данные, полученные на уровне регионов, затем используются для обучения модели, эффективно передавая навыки точного анализа визуальной информации. Данный подход позволяет создавать более эффективные и точные модели VQA, способные отвечать на вопросы, требующие понимания мелких деталей на изображениях.
Процесс дистилляции данных, полученных на небольших фрагментах изображений, заключается в переносе знаний о детальном восприятии к большой мультимодальной модели (MLLM). В ходе дистилляции модель обучается сопоставлять ответы на вопросы, сформулированные для небольших областей изображения, с полным изображением, что позволяет ей эффективно экстраполировать навыки детального анализа с локальных фрагментов на целое изображение. Это обеспечивает улучшенное понимание визуальной информации и повышение точности ответов на вопросы, требующие анализа мелких деталей, без необходимости повторного кодирования всего изображения.
В отличие от итеративных методов обучения, предложенный подход Region-to-Image Distillation характеризуется высокой вычислительной эффективностью. Он позволяет избежать ограничений, связанных с многократным перекодированием данных, что существенно снижает затраты ресурсов и время обработки. В ходе тестирования было установлено, что скорость получения результатов при использовании данного метода в 10 раз превышает показатели, демонстрируемые альтернативными подходами, основанными на принципах agentic и tool-use.
ZoomBench: Измерение Глубины Визуального Понимания
ZoomBench — это новый бенчмарк, разработанный специально для оценки возможностей моделей в области тонкого мультимодального восприятия. В отличие от существующих наборов данных, ZoomBench фокусируется на оценке способности моделей понимать и интерпретировать детализированные визуальные данные, требующие анализа мелких объектов и взаимосвязей между ними. Бенчмарк включает в себя набор изображений и вопросов, требующих от моделей не только общей визуальной осведомленности, но и способности к детальному анализу и пониманию контекста, что позволяет более точно оценить их производительность в задачах, требующих высокой степени визуального внимания и понимания.
В рамках ZoomBench, оценка производительности осуществляется как на полных изображениях, так и на их вырезанных фрагментах, что позволяет количественно определить так называемый “разрыв масштабирования” (zooming gap). Данный подход заключается в сравнении метрик производительности модели при обработке изображения целиком и при анализе детализированных областей внутри него. Более узкий разрыв масштабирования указывает на более эффективную способность модели сохранять точность и детализацию при переходе от общего обзора к детальному анализу, что является важным показателем для задач, требующих детального понимания визуальной информации на разных уровнях детализации.
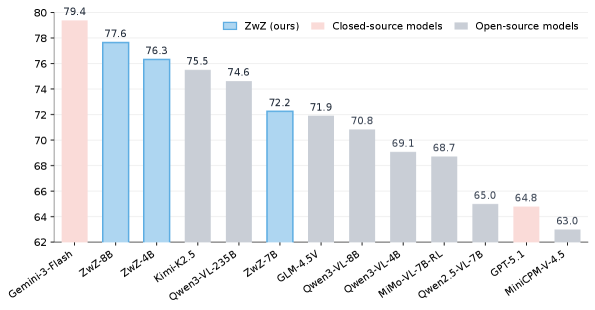
Результаты тестирования на ZoomBench демонстрируют значительное снижение разрыва в производительности между обработкой полных изображений и отдельных областей при использовании метода Region-to-Image Distillation. Модель ZwZ-8B достигла показателя в 58.11% по шкале ZoomBench, превзойдя результат Qwen3-VL-8B, составивший 37.87%. При этом, разрыв в производительности (zooming gap) для ZwZ-8B составил 15.26%, что существенно ниже, чем у Qwen3-VL-8B, где этот показатель равен 25.21%. Данные свидетельствуют об эффективности предложенного метода в улучшении точности обработки локальных деталей изображения.
Расширение Границ Визуального Понимания: Ключевые Концепции
Исследования показывают, что способность к восприятию множественных объектов и пространственное мышление играют ключевую роль в достижении детального и надёжного понимания изображений. Успех в задачах, требующих анализа сложных визуальных сцен, напрямую зависит от того, насколько эффективно модель способна одновременно идентифицировать и интерпретировать взаимосвязи между различными объектами в кадре. Развитие этих способностей позволяет моделям не просто распознавать отдельные элементы, но и понимать их контекст, расположение и взаимодействие, что критически важно для решения сложных задач, связанных с анализом визуальной информации и принятием обоснованных решений на её основе.
Относительное внимание выступает ценным показателем для оценки эффективности фокусировки моделей на релевантных областях изображения. Данная метрика позволяет количественно измерить, насколько точно модель выделяет и анализирует ключевые детали, игнорируя несущественные элементы. Вместо абсолютного значения внимания к отдельным пикселям или областям, относительное внимание сравнивает важность различных регионов изображения друг относительно друга, выявляя, какие области оказывают наибольшее влияние на принятие решения моделью. Это особенно важно в задачах, требующих детального понимания сцены и точного распознавания объектов, поскольку позволяет оценить способность модели различать важные и второстепенные визуальные признаки, что в свою очередь напрямую влияет на точность и надежность ее работы.
Исследование демонстрирует перспективный подход к созданию более совершенных мультимодальных больших языковых моделей (MLLM). Путем объединения метода дистилляции «область к изображению» (Region-to-Image Distillation) с техниками, такими как Textual Chain-of-Thought (CoT), и использованием модели Qwen3-VL, удалось добиться значительного улучшения в точности и глубине понимания визуальной информации. Разработанная модель ZwZ-7B показала впечатляющие результаты на стандартных бенчмарках HR-Bench (75.4%) и VStar (88.5%), превзойдя показатели существующих моделей DeepEyes (75.1%, 90.1%) и Monet-7B (71.0%). Данный подход открывает новые возможности для создания систем, способных к более сложному и детальному анализу изображений и эффективному взаимодействию с визуальным контентом.
Исследование демонстрирует стремление к элегантности в обработке данных, избегая избыточных вычислений. Предложенная методика Region-to-Image Distillation позволяет добиться высокой точности в задачах визуального обоснования, не прибегая к итеративному использованию инструментов, что особенно важно для агентских систем. Как заметил Эндрю Ын: «Иногда самое сложное — это сделать простое». Эта фраза отражает суть представленного подхода — достижение сложной функциональности за счет изящного алгоритма, а не грубой вычислительной силы. Успешное применение дистилляции знаний позволяет модели эффективно воспринимать детализированные изображения, приближаясь к идеалу математической чистоты и доказуемости алгоритма.
Куда Далее?
Представленная работа, хотя и демонстрирует элегантное решение задачи тонкого визуального восприятия, лишь намекает на глубину нерешенных проблем. Успешное применение дистилляции для имитации эффекта «приближения» без фактического масштабирования изображений — это, безусловно, прогресс. Однако, истинная проверка заключается в устойчивости метода к неоднозначности и шуму в реальных данных. Симметрия, лежащая в основе эффективного алгоритма, требует не только точного соответствия между регионами и изображениями, но и способности к обобщению за пределы тренировочного набора.
Очевидным направлением дальнейших исследований представляется изучение возможности адаптации данной техники к другим модальностям. Можно ли, подобно этому, «дистиллировать» вычисления, необходимые для сложного анализа звука или текста, чтобы добиться более быстрой и эффективной обработки? Попытки решить эту задачу, вероятно, столкнутся с фундаментальными ограничениями, связанными со сложностью и неоднородностью данных, но именно в преодолении этих препятствий и кроется истинная ценность научного поиска.
И, наконец, необходимо признать, что за кажущейся простотой решения всегда скрывается сложность реализации. Оптимизация процесса дистилляции, разработка метрик для оценки качества «дистиллированных» знаний и адаптация метода к различным архитектурам мультимодальных моделей — всё это потребует значительных усилий. Но, как известно, совершенство — это не пункт назначения, а бесконечный процесс.
Оригинал статьи: https://arxiv.org/pdf/2602.11858.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект и закон: гармония неизбежна
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Поймать изменчивый сигнал: Как нейросети расшифровывают политику ФРС
- Искусственный интеллект и эксперт: как совместная работа меняет Data Science
- Иллюзии понимания: Как правильно оценивать объяснимые модели
- Геометрия устойчивости: новый взгляд на представления в нейросетях
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Нейронные Заросли: Как Модели Находят Оптимальные Решения
2026-02-17 04:47