Автор: Денис Аветисян
Исследователи предлагают инновационную архитектуру видео-трансформера, вдохновленную принципами кодирования видео, для более эффективного и надежного анализа визуальной информации.
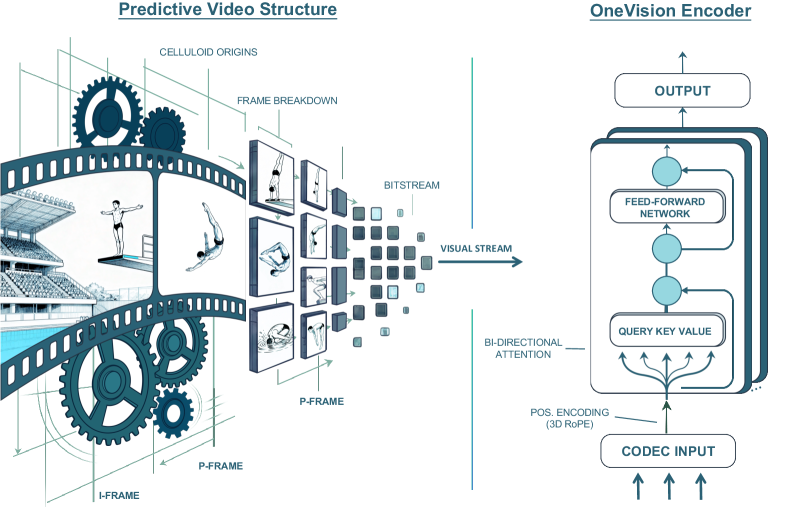
OneVision-Encoder использует кодек-ориентированный выбор патчей для достижения эффективного и робастного пространственно-временного понимания видеосигналов.
Современные архитектуры компьютерного зрения часто игнорируют присущую видеоданным избыточность и разреженность значимой информации. В работе ‘OneVision-Encoder: Codec-Aligned Sparsity as a Foundational Principle for Multimodal Intelligence’ предложен новый подход к кодированию видео, основанный на принципах сжатия, используемых в современных кодеках. OneVision-Encoder эффективно выделяет и обрабатывает лишь небольшую часть пикселей, содержащих наиболее важную информацию, что позволяет достичь высокой точности и эффективности при решении задач мультимодального анализа. Не является ли выстраивание архитектур ИИ в соответствии с принципами сжатия данных ключом к созданию действительно интеллектуальных систем?
За пределами Отдельных Кадров: Необходимость Пространственно-Временного Рассуждения
Традиционный анализ видео часто рассматривает отдельные кадры как независимые изображения, упуская из виду критически важные временные взаимосвязи. Такой подход, фокусирующийся на статических моментах, не позволяет в полной мере понять динамику происходящего, что особенно заметно в сложных сценах и реальных видеопотоках. Игнорирование последовательности кадров приводит к потере информации о движении, взаимодействии объектов и общем контексте, что существенно ограничивает возможности систем компьютерного зрения в задачах, требующих понимания происходящих событий. По сути, это похоже на попытку прочитать книгу, рассматривая каждую страницу отдельно, без учета связи между ними и общей сюжетной линии.
Анализ видеопотока, основанный на последовательной обработке отдельных кадров, часто оказывается неэффективным при работе со сложными сценами и реальными условиями. Такой подход игнорирует взаимосвязь между кадрами, что приводит к потере важной информации о движении, взаимодействии объектов и общей динамике происходящего. Для полноценного понимания видео необходимо учитывать не только то, что изображено на каждом кадре, но и как это изображение меняется во времени. Это требует перехода к более целостному взгляду, учитывающему пространственно-временные зависимости, что позволит алгоритмам более точно интерпретировать происходящее и успешно решать задачи, связанные с распознаванием действий, прогнозированием поведения объектов и навигацией в динамической среде.
Эффективное улавливание динамики, сочетающей пространственные и временные аспекты видео, становится все более важным для широкого спектра приложений. От систем автономного вождения, где мгновенное распознавание движущихся объектов и прогнозирование их траекторий жизненно необходимо, до современных методов сжатия видео, стремящихся к максимальной эффективности при сохранении качества изображения, — способность обрабатывать видео как непрерывный поток, а не как набор отдельных кадров, определяет прогресс. По мере того, как модели искусственного интеллекта становятся все более сложными и требовательными к объему визуальной информации, необходимость в эффективных алгоритмах, способных захватывать и анализировать эти пространственно-временные зависимости, возрастает экспоненциально, открывая новые возможности для более точного и реалистичного восприятия видеоконтента.
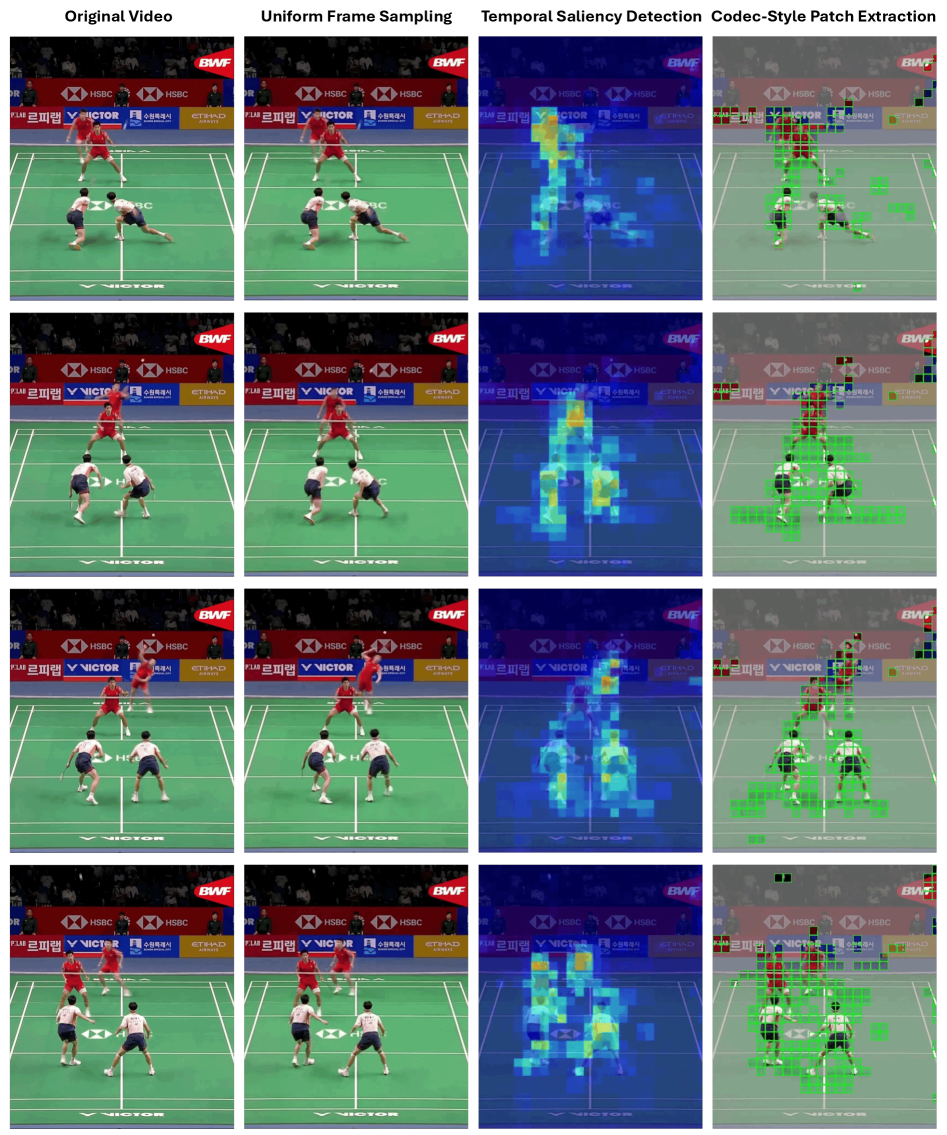
Кодековая Разбивка: Структурирование Визуального Мира
Метод Codec Patchification представляет собой подход к построению разреженных пространственно-временных токенов, основанный на принципах видеокомпрессии. В отличие от плотной обработки видео, данный метод стратегически отбирает и организует видеофрагменты (патчи), формируя компактное представление, которое сохраняет важную информацию о визуальном контенте. Использование принципов, применяемых в видеокодеках, позволяет создавать разреженные макеты токенов, эффективно представляющие видеоданные с минимальными избыточными данными.
Метод Codec Patchification осуществляет стратегический отбор и организацию видеофрагментов, фокусируясь на наиболее заметных областях и сохраняя временную согласованность. В результате, достигается снижение количества токенов на 75%-96.9% по сравнению с плотной обработкой видеопотока. Приоритезация значимых регионов и поддержание временной когерентности позволяет создавать более компактные представления видеоданных без существенной потери информации, что повышает эффективность обработки и снижает вычислительные затраты.
Метод кодирования, вдохновленный принципами видеокомпрессии, позволяет создавать компактные и информативные представления визуальных данных. Вместо обработки каждого пикселя или плотной выборки, система стратегически отбирает и организует видеофрагменты (патчи), имитируя структуру, используемую в алгоритмах сжатия видео. Это позволяет существенно снизить количество обрабатываемых токенов — на 75%-96.9% — при сохранении значимой информации, поскольку приоритет отдается наиболее заметным областям и поддержанию временной согласованности. Таким образом, достигается эффективное представление видеоданных с минимальными потерями ключевых деталей.
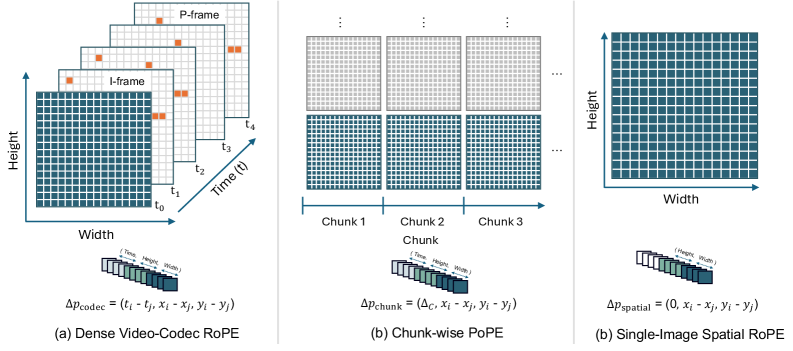
OneVision-Encoder: Унифицированная Пространственно-Временная Архитектура
Архитектура OneVision-Encoder объединяет метод разбиения видео на фрагменты Codec Patchification с архитектурой Vision Transformer. Codec Patchification позволяет эффективно кодировать видеоданные, разбивая их на небольшие, независимые фрагменты, что снижает вычислительные затраты и объем памяти, необходимые для обработки. Интеграция с Vision Transformer обеспечивает возможность эффективного моделирования как пространственных, так и временных зависимостей в видеопоследовательности, что критически важно для задач анализа и понимания видеоконтента. Данный подход позволяет обрабатывать видео как последовательность патчей, что упрощает применение механизмов внимания и обеспечивает эффективное извлечение признаков.
В архитектуре OneVision-Encoder для обеспечения когерентного внимания используется 3D Rotary Position Embedding (RoPE). RoPE представляет собой метод внедрения позиционной информации, адаптированный для обработки трехмерных данных (пространство и время), позволяющий модели эффективно учитывать взаимосвязи между кадрами и пространственными координатами. Для ускорения вычислений применяется Flash Attention 2 — оптимизированная реализация механизма внимания, снижающая потребление памяти и увеличивающая пропускную способность за счет параллелизации и оптимизации доступа к памяти. Flash Attention 2 позволяет обрабатывать более длинные последовательности и значительно ускорить процесс обучения и инференса по сравнению с традиционными реализациями внимания.
Для обучения надежным представлениям из немаркированных видеоданных используется самообучение с функцией потерь, основанной на дискриминации кластеров (Cluster Discrimination Objective). Данный подход позволяет модели различать различные кластеры признаков в видео, тем самым извлекая более информативные и устойчивые к шуму представления. Экспериментальные результаты демонстрируют, что предложенный метод превосходит существующие аналоги по ключевым показателям производительности, достигая передовых результатов в задачах анализа видеоданных.
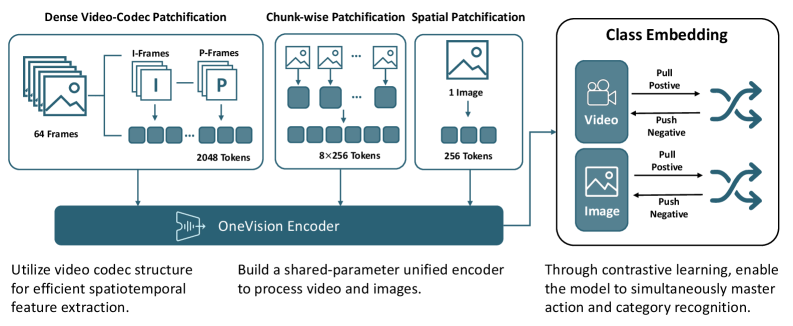
За Пределами Производительности: К Обобщаемому Видеоинтеллекту
В основе OneVision-Encoder лежит принцип обработки видео в исходном разрешении, что позволяет избежать потери информации, неизбежной при масштабировании. Традиционное уменьшение размера изображения для ускорения анализа часто приводит к удалению важных деталей, критичных для точного распознавания объектов и понимания происходящего. Сохраняя исходное разрешение, система способна улавливать тонкие визуальные нюансы и контекст, что значительно повышает надежность и точность анализа видеоданных. Этот подход особенно важен в задачах, где даже незначительные детали могут иметь решающее значение, например, в системах видеонаблюдения, автоматизированном контроле качества или анализе медицинских изображений. Отказ от масштабирования позволяет OneVision-Encoder предоставлять более полные и достоверные результаты, необходимые для построения действительно интеллектуальных систем анализа видео.
Представленная система демонстрирует высокую устойчивость и точность анализа видео благодаря одновременному использованию как пространственной, так и временной информации. В ходе сравнительного тестирования на 16 различных бенчмарках, разработанная архитектура значительно превзошла существующие модели, такие как SigLIP2 и Qwen3-ViT. Такой подход позволяет эффективно обрабатывать широкий спектр видеоданных, включая сложные сцены и динамичные события, обеспечивая надежную работу в разнообразных условиях и сценариях применения. Способность учитывать изменения во времени, в сочетании с анализом отдельных кадров, существенно повышает общую производительность и точность распознавания в видеопотоке.
Интеграция разработанной системы с крупными мультимодальными моделями, такими как LLaVA, демонстрирует значительный потенциал для создания интеллектуальных систем, способных к рассуждениям о визуальном мире. В ходе тестирования наблюдалось улучшение точности на 17,1% в метрике Top-1 на наборе данных Diving-48 и превосходство над моделью DINOv3 на 8,1%. Примечательно, что эти результаты были достигнуты, несмотря на то, что система была предварительно обучена на существенно меньшем количестве визуально-текстовых токенов — приблизительно 100 миллиардов против 2,1 триллиона, используемых в DINOv3. Это свидетельствует о высокой эффективности предложенного подхода к обучению и способности к обобщению, даже при ограниченном объеме данных.

Расширяя Горизонты: Адаптация и Масштабирование Пространственно-Временного Обучения
Принципы, лежащие в основе метода «Codec Patchification», изначально разработанного для обработки видеоданных, демонстрируют значительный потенциал за пределами этой области. Суть подхода заключается в разбиении данных на компактные, информативные «патчи», что позволяет эффективно кодировать и обрабатывать информацию различной природы. Исследования показывают, что аналогичная структурализация данных применима не только к визуальным последовательностям, но и к аудиосигналам, текстам, а также к данным, полученным в результате научных экспериментов. Такой универсальный подход позволяет создавать более компактные и эффективные модели машинного обучения, способные к обобщению и адаптации к новым типам данных, что открывает перспективы для развития мультимодальных систем и решения сложных задач, требующих интеграции информации из различных источников.
Исследования показали, что принцип патчификации, изначально разработанный для обработки видеоданных, успешно адаптируется и к статичным изображениям. Данный подход, известный как пространственная патчификация одиночного изображения, позволяет эффективно структурировать визуальную информацию, разбивая её на отдельные фрагменты для последующего анализа. Это открывает новые возможности для исследований в области компьютерного зрения, позволяя создавать более эффективные алгоритмы для распознавания образов, сегментации изображений и других задач. Успешная адаптация данной техники демонстрирует её универсальность и потенциал для применения в различных областях обработки данных, где необходимо структурировать и анализировать сложные визуальные сцены.
Постоянное совершенствование механизмов внимания и методов самообучения открывает новые перспективы для систем, способных к пространственно-временному рассуждению. Разработка более эффективных алгоритмов внимания позволяет обрабатывать большие объемы данных, фокусируясь на наиболее релевантных участках, что критически важно для понимания сложных динамических процессов. В то же время, самообучение, позволяющее моделям извлекать знания непосредственно из неразмеченных данных, снижает зависимость от трудоемкой ручной разметки и повышает обобщающую способность систем. Сочетание этих двух направлений исследований позволяет создавать более мощные и адаптивные модели, способные к более глубокому пониманию и анализу информации, представленной в пространстве и времени, что находит применение в различных областях, от обработки видео и анализа медицинских изображений до робототехники и автономного вождения.
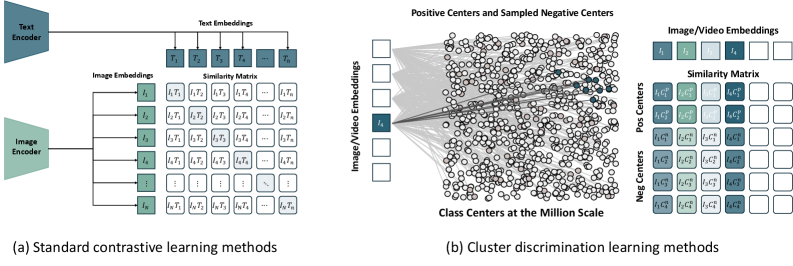
Исследование демонстрирует, что элегантность и эффективность алгоритмов напрямую связаны с их математической строгостью. Как отмечает Джеффри Хинтон: «Искусственный интеллект должен быть способен к обучению без учителя, опираясь на внутреннюю структуру данных». OneVision-Encoder, представленный в статье, воплощает этот принцип, используя вдохновлённые кодеками методы отбора патчей для достижения эффективного и надёжного понимания видео. Подход, основанный на выстраивании представления, соответствующего предсказуемой структуре видеосигналов, позволяет добиться высокой степени точности, при этом избегая излишней сложности, что соответствует стремлению к математической чистоте в проектировании алгоритмов. Особенно важен принцип кластерной дискриминации, обеспечивающий устойчивость и обобщающую способность системы.
Что Дальше?
Представленная работа, хоть и демонстрирует элегантность подхода к разреженности представлений, все же оставляет открытым вопрос о фундаментальной природе «понимания» видео. Утверждать, что модель «понимает» структуру видеосигнала, основываясь лишь на корреляции с предсказаниями кодека, — не более чем удобная метафора. Доказательство истинного понимания требует не просто успешной реконструкции, а способности к обобщению, к экстраполяции за пределы тренировочного набора данных, что пока остается недостижимым идеалом.
Особый интерес представляет проблема масштабируемости предложенного подхода. Увеличение разрешения и частоты кадров видео неизбежно ведет к экспоненциальному росту вычислительных затрат. Истинная элегантность алгоритма заключается в его способности эффективно справляться с подобными вызовами, а не просто демонстрировать успехи на ограниченных наборах данных. Необходимо исследовать возможность применения принципов информационного сжатия не только для уменьшения размерности представлений, но и для снижения вычислительной сложности самих операций.
В конечном итоге, задача состоит не в создании все более сложных моделей, а в разработке теоретической основы для понимания того, что вообще означает «интеллект» в контексте обработки видеоинформации. Пока же, следует признать, что большинство достижений в данной области являются, скорее, инженерными уловками, чем прорывом в области искусственного интеллекта. Истинная красота, как известно, кроется в простоте и математической строгости.
Оригинал статьи: https://arxiv.org/pdf/2602.08683.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект и закон: гармония неизбежна
- Поймать изменчивый сигнал: Как нейросети расшифровывают политику ФРС
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект и эксперт: как совместная работа меняет Data Science
- Иллюзии понимания: Как правильно оценивать объяснимые модели
- Квантовые модели для моделирования потоков: новый взгляд на сжатие данных
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
- Моделирование биомолекул: новый импульс от нейросетей
- Геометрия устойчивости: новый взгляд на представления в нейросетях
2026-02-17 06:27