Автор: Денис Аветисян
Новое исследование демонстрирует, что тщательно подобранные навыки значительно повышают эффективность интеллектуальных агентов в решении различных задач.
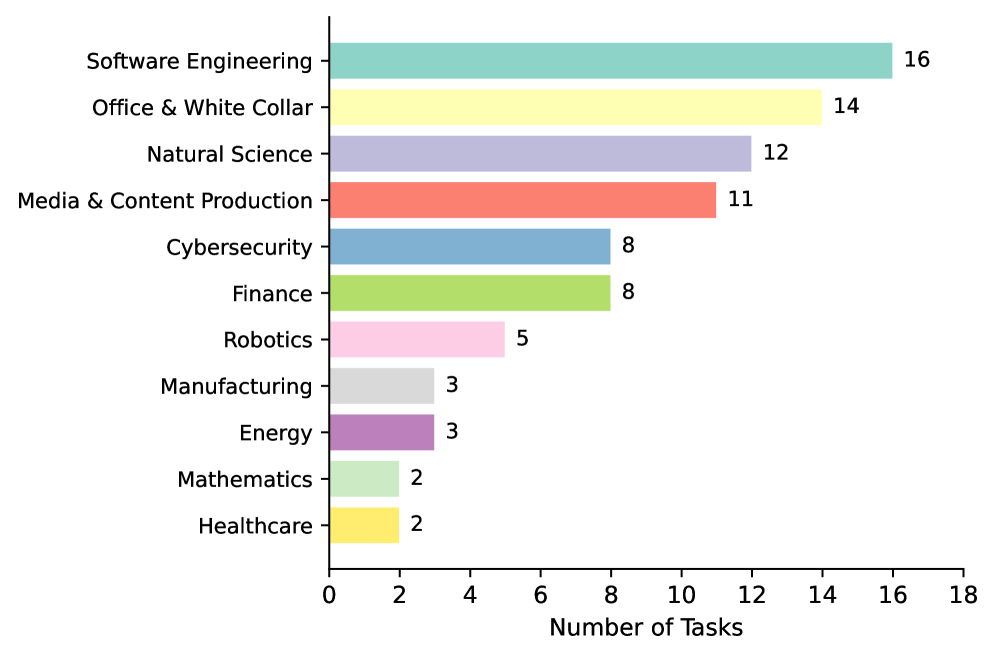
Представлен SkillsBench — эталон для оценки эффективности использования готовых навыков в задачах, требующих процедурных знаний и расширения возможностей агентов.
Несмотря на растущую популярность использования структурированных наборов процедурных знаний для улучшения работы LLM-агентов, объективной оценки их эффективности до настоящего момента не проводилось. В данной работе представлена платформа SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, предназначенная для всестороннего тестирования влияния «Agent Skills» на решение широкого спектра задач из 11 доменов. Эксперименты с 7 конфигурациями агентов и 7308 траекториями показали, что использование тщательно подобранных «Skills» повышает средний процент успешного выполнения задач на 16.2%, в то время как самогенерируемые навыки не приносят ощутимой пользы. Возможно ли создание универсальных наборов «Skills», способных значительно улучшить производительность LLM-агентов в различных областях, или необходим индивидуальный подход к каждой задаче?
Иллюзии и Реальность: За Пределами Больших Языковых Моделей
Несмотря на впечатляющие возможности, основанные на больших языковых моделях (LLM) агенты часто сталкиваются с трудностями при решении сложных, многоступенчатых задач, требующих последовательного рассуждения. В то время как LLM превосходно справляются с генерацией текста и пониманием языка, им не хватает способности поддерживать длительную когнитивную последовательность, необходимую для планирования и выполнения действий, разнесенных во времени. Это проявляется в трудностях с задачами, требующими запоминания предыдущих шагов, адаптации к меняющимся условиям или эффективного использования инструментов. В результате, даже относительно простые задачи, разбитые на несколько этапов, могут оказаться непосильными для LLM-агентов без дополнительной поддержки и оптимизации.
Успешное выполнение сложных задач напрямую зависит от доступа к специализированным знаниям в конкретной области и чёткому алгоритму действий. Исследования показывают, что простого владения языком недостаточно для решения проблем, требующих глубокого понимания предметной области, будь то медицинская диагностика, финансовый анализ или юридическое консультирование. Поэтому, для повышения эффективности агентов, основанных на больших языковых моделях, необходимо интегрировать в них структурированные базы знаний и детальные инструкции, определяющие последовательность шагов для достижения поставленной цели. Такой подход позволяет агентам не только понимать суть запроса, но и применять релевантные знания и навыки для его решения, значительно повышая точность и надёжность результатов.
Существующие методы оценки влияния специализированных навыков на эффективность агентов на базе больших языковых моделей (LLM) часто оказываются несостоятельными и не позволяют объективно измерить прирост производительности. Для решения этой проблемы была разработана платформа SkillsBench, представляющая собой стандартизированный подход к оценке. Результаты, полученные с использованием SkillsBench, демонстрируют значительное улучшение показателей работы агентов — в среднем на 16.2 процентных пункта — после интеграции тщательно отобранных и структурированных навыков. Это указывает на критическую важность целенаправленного расширения функциональности агентов с помощью специализированных знаний для решения сложных задач и повышения общей эффективности.
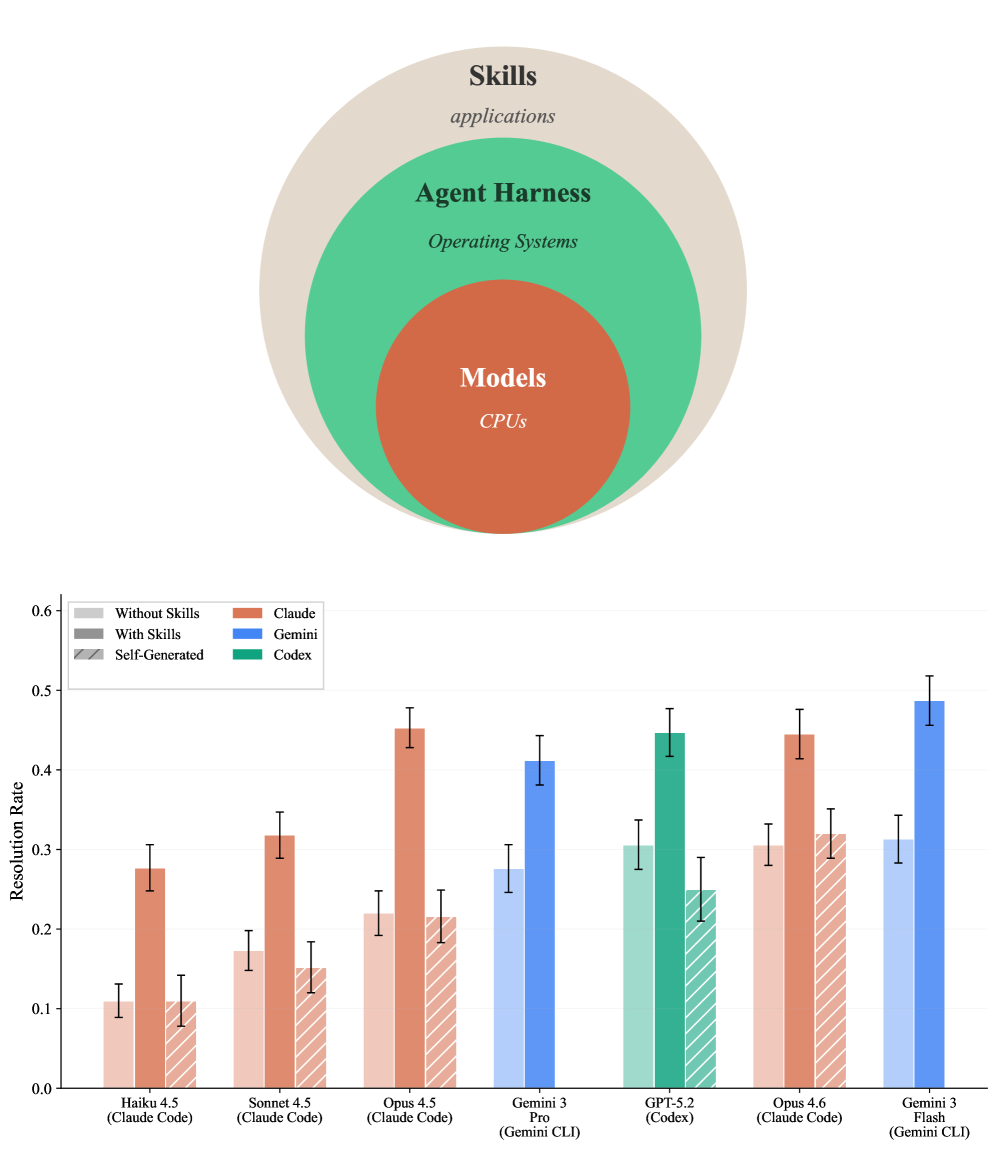
SkillsBench: Строгий Контроль Эффективности Навыков Агентов
SkillsBench — это новый эталон, разработанный специально для оценки эффективности навыков агентов как полноценных артефактов для оценки. В отличие от существующих подходов, которые часто фокусируются на общих показателях производительности, SkillsBench позволяет оценивать конкретные навыки агентов изолированно и количественно. Это достигается путем определения четких критериев оценки для каждого навыка и предоставления набора задач, предназначенных для его проверки. Использование SkillsBench позволяет исследователям и разработчикам более точно определить сильные и слабые стороны различных агентов, а также оценить влияние конкретных навыков на общую производительность.
Для обеспечения воспроизводимости и надежности оценки задач в SkillsBench используется контейнеризация и детерминированная верификация. Контейнеризация, посредством Docker, позволяет создавать изолированные среды выполнения, гарантируя согласованность окружения для каждого запуска задачи, независимо от базовой инфраструктуры. Детерминированная верификация включает в себя использование заранее определенных наборов входных данных и эталонных результатов, что позволяет автоматизированно и объективно оценивать ответы агентов. Этот подход исключает влияние случайных факторов и обеспечивает возможность повторного выполнения оценок для проверки и аудита.
Управление контекстом является критически важным компонентом SkillsBench, поскольку позволяет решать проблему ограничения длины входных данных (token limits) при работе с историей взаимодействия. В ходе бенчмарка были протестированы 7 конфигураций агентов-моделей на 84 различных задачах. Результаты продемонстрировали измеримое влияние использования дополнительных навыков (skill augmentation) на производительность агентов, подтверждая эффективность подхода к оценке и улучшению их функциональности в условиях ограниченного контекста.
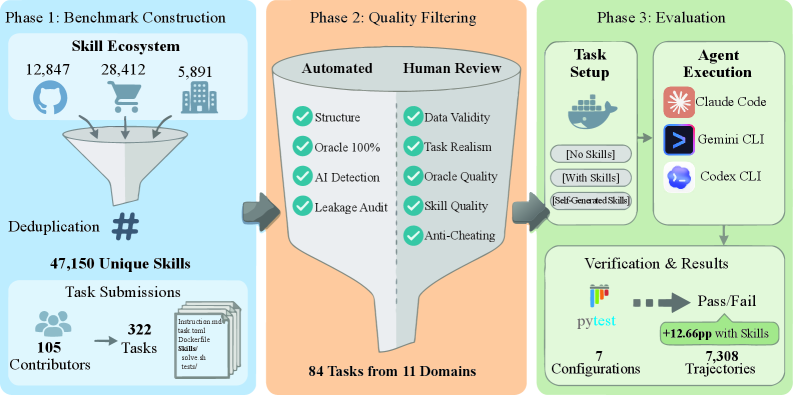
Измерение Ценности Навыков: Нормализованный Прирост и За Его Пределами
Для оценки эффективности приобретенных навыков платформа SkillsBench использует метрику нормализованного прироста (Normalized Gain), что позволяет учесть исходный уровень производительности агента. Нормализованный прирост рассчитывается как разница между итоговой и исходной производительностью, нормированная на максимальный возможный прирост. Это обеспечивает сопоставимую оценку улучшения навыков независимо от абсолютного уровня производительности агента до обучения. Применение данной метрики позволяет объективно измерить, насколько эффективно новые или самогенерируемые навыки улучшают способность агента выполнять поставленные задачи, учитывая его начальные возможности.
В рамках SkillsBench поддерживаются два типа навыков: разработанные экспертами (Curated Skills) и сгенерированные агентом самостоятельно (Self-Generated Skills). Анализ показывает, что использование навыков, созданных агентом, в среднем привело к снижению процента успешного выполнения задач на 1.3 процентных пункта. Данный результат указывает на необходимость дальнейшей оптимизации алгоритмов генерации и оценки эффективности самообучающихся навыков для достижения сопоставимых или превосходящих показателей по сравнению с навыками, разработанными экспертами.
Эффективность применения навыков (Skills) напрямую зависит от сложности решаемой задачи; наиболее значительные улучшения наблюдаются при решении задач повышенной сложности. Анализ показал, что задачи, такие как подсчет монет в игре Mario, анализ сводных таблиц продаж, анализ риска наводнений и анализ финансовых отчетов SEC, демонстрируют наибольший прирост эффективности — до +85.7 процентных пунктов. Это указывает на то, что Skills особенно полезны при решении задач, требующих значительных вычислительных ресурсов или анализа больших объемов данных.
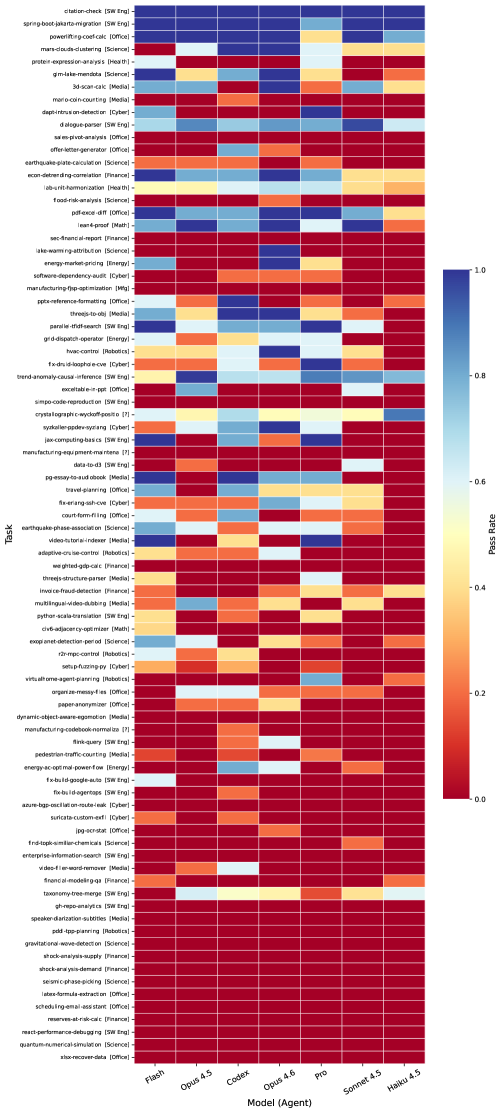
Разнообразие Инструментов для Валидации Навыков
В рамках платформы SkillsBench активно используются различные инструменты, известные как “agent harnesses”, для развертывания и оценки навыков, которыми оперируют интеллектуальные агенты. К числу этих инструментов относятся Claude Code, Codex CLI и Gemini CLI, каждый из которых предоставляет уникальные возможности для тестирования и анализа способностей агентов в различных задачах. Использование разнообразных harnesses позволяет исследователям комплексно оценить производительность агентов, выявить сильные и слабые стороны каждого подхода и, в конечном итоге, создать более надежные и эффективные системы искусственного интеллекта, способные решать широкий спектр прикладных задач. Такой подход к валидации навыков гарантирует объективность и воспроизводимость результатов, что крайне важно для дальнейшего развития области.
Для обеспечения воспроизводимости и упрощения процесса оценки агентов, разработан фреймворк Harbor. Данная платформа предоставляет стандартизированную среду для создания и выполнения контейнеризированных задач, что позволяет исследователям и разработчикам последовательно тестировать навыки агентов в различных условиях. Использование контейнеров гарантирует, что все зависимости и окружение задачи будут идентичными при каждом запуске, исключая влияние внешних факторов на результаты. Это особенно важно при сравнении различных подходов к обучению и оценке агентов, поскольку обеспечивает надежность и объективность полученных данных. Фреймворк Harbor способствует формированию более прозрачной и надежной методологии оценки, что необходимо для дальнейшего развития области интеллектуальных агентов.
Развивающаяся экосистема инструментов и фреймворков свидетельствует о совместных усилиях, направленных на создание общепринятых стандартов оценки и внедрения агентов, дополненных навыками. Исследования показывают, что оптимальное количество навыков, максимизирующих прирост производительности агента, находится в диапазоне от двух до трех. Дальнейшее увеличение числа навыков приводит к уменьшению эффекта от их добавления, что указывает на существование точки насыщения и необходимости оптимизации архитектуры агента для достижения максимальной эффективности. Такой подход позволяет создавать более специализированные и эффективные системы искусственного интеллекта, способные решать сложные задачи с высокой точностью.
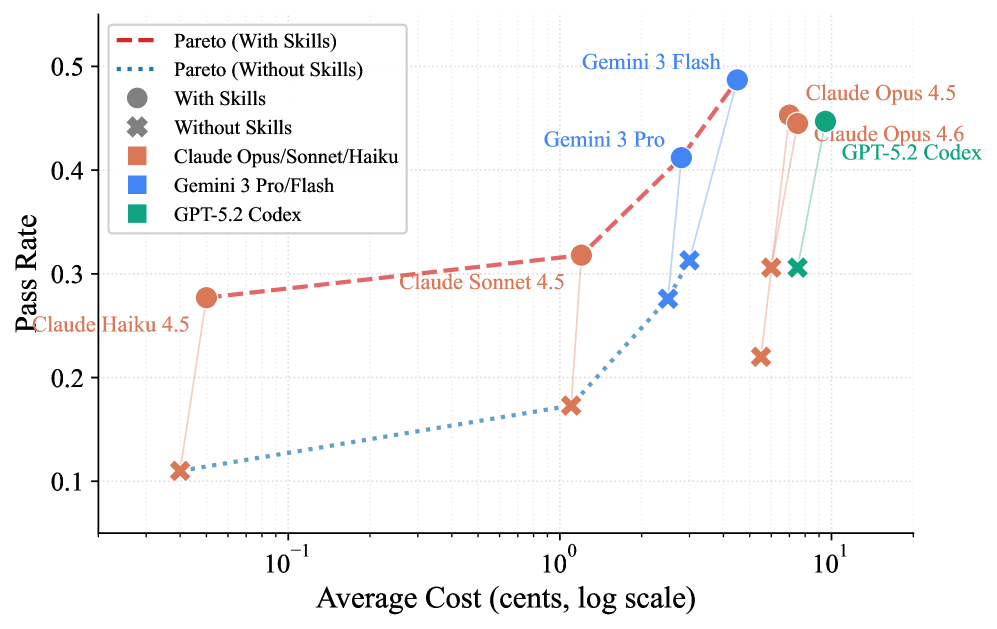
Исследование демонстрирует, что тщательно отобранные ‘Навыки Агента’ действительно повышают эффективность LLM-агентов в различных задачах, в то время как самогенерируемые навыки оказываются бесполезными. Это подтверждает давно известную истину: элегантная теория бессильна перед суровой реальностью продакшена. Как однажды заметил Брайан Керниган: «Простота — это высшая степень совершенства». И в данном случае, простота заключается в осознании, что не стоит изобретать велосипед, а лучше использовать проверенные решения. Документация к этим решениям, конечно, будет полна оптимистичных заявлений, но это лишь форма коллективного самообмана, как мы все прекрасно знаем.
Что дальше?
Представленный анализ демонстрирует, что тщательно подобранные «навыки» для агентов действительно способны улучшить их производительность. Однако, эта победа, вероятно, временная. История помнит множество «революционных» подходов к представлению знаний, каждый из которых, в конечном итоге, превращался в сложный и трудно поддерживаемый монолит. Вполне вероятно, что и здесь возникнет необходимость в постоянной курации и обновлении этих самых «навыков», иначе эффект быстро сойдёт на нет. И не стоит забывать: зелёные тесты — это, как правило, признак того, что проверяется недостаточно.
Очевидно, что самогенерируемые навыки, не оправдав ожиданий, лишь подтверждают старую истину: элегантная теория быстро разбивается о суровую реальность продакшена. Возникает вопрос: а не проще ли просто больше данных? Или, может быть, мы снова изобретаем велосипед, надеясь обойти фундаментальные ограничения языковых моделей? На горизонте маячит перспектива бесконечной гонки вооружений: всё более сложные навыки против всё более изощрённых способов их обхода.
Вместо того, чтобы фокусироваться на создании идеального набора «навыков», возможно, стоит пересмотреть саму парадигму. Как сделать агентов более адаптивными, способными к самостоятельному обучению и решению новых задач? Или, может быть, ключ к успеху лежит в более тесной интеграции с внешними инструментами и источниками знаний? Время покажет, но одно можно сказать наверняка: всё, что выглядит слишком хорошо, скорее всего, уже было в 2012-м, только называлось иначе.
Оригинал статьи: https://arxiv.org/pdf/2602.12670.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Поймать изменчивый сигнал: Как нейросети расшифровывают политику ФРС
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект и закон: гармония неизбежна
- От токенов к смыслу: новая стратегия адаптивной обработки больших языковых моделей
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Тёмная материя, радужная гравитация и горизонты событий
- Нейросети, повинующиеся физике: новый подход к моделированию сложных систем
- Моделирование биомолекул: новый импульс от нейросетей
- Молекулярная динамика под присмотром ИИ: новый взгляд на химические процессы
2026-02-17 06:32