Автор: Денис Аветисян
Новый подход использует обучение с подкреплением для оптимизации процесса рассуждений и повышения точности поиска информации в различных модальностях.
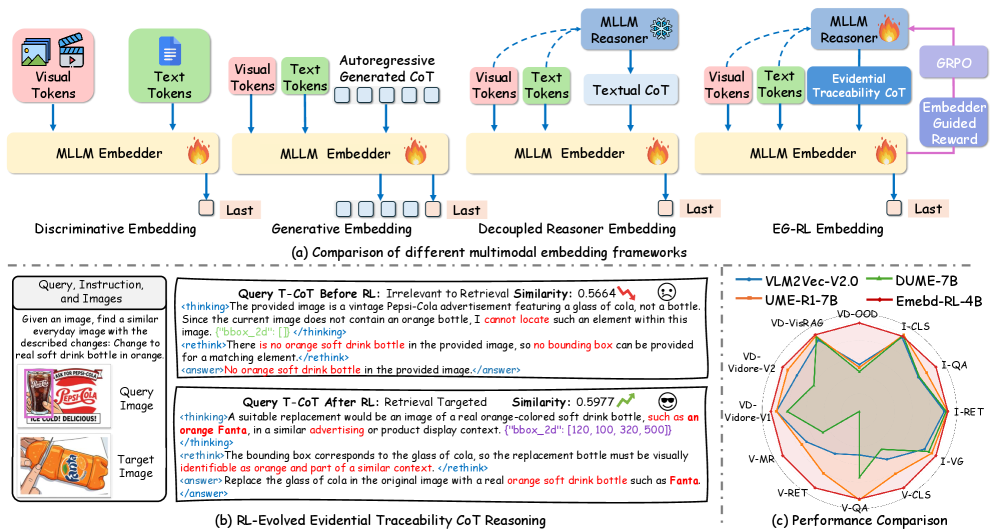
Предложена универсальная мультимодальная система встраивания, основанная на обучении с подкреплением, управляемом встраивателем, для улучшения траекторий рассуждений и повышения производительности поиска.
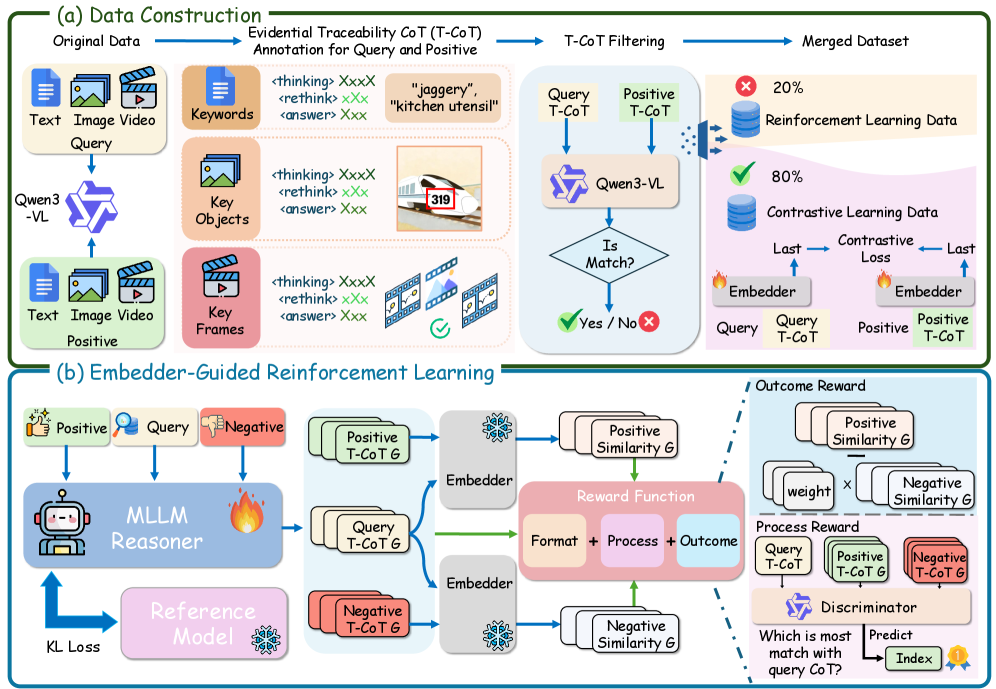
Несмотря на успехи в области универсальных мультимодальных представлений, существующие подходы часто игнорируют важность обоснованного рассуждения при извлечении семантической информации. В работе ‘Embed-RL: Reinforcement Learning for Reasoning-Driven Multimodal Embeddings’ предложен новый фреймворк, использующий обучение с подкреплением, управляемое эмбеддером (Embedder-Guided Reinforcement Learning), для оптимизации процесса рассуждений и повышения эффективности поиска мультимодальных данных. Ключевой инновацией является разработка трассируемого контекста рассуждений (Traceability CoT), ориентированного на релевантные мультимодальные сигналы и улучшающего согласованность между модальностями. Может ли подобный подход к оптимизации рассуждений стать основой для создания более интеллектуальных и эффективных мультимодальных систем, способных к глубокому пониманию сложных сценариев?
За гранью простого сопоставления: Основы многомодального понимания
Для успешного выполнения задач, объединяющих различные модальности данных, например, поиск изображений по текстовому запросу или наоборот, критически важно создание осмысленных совместных представлений. Эти представления позволяют модели понимать не просто отдельные элементы каждого типа данных, но и сложные взаимосвязи между ними. Вместо обработки каждого типа данных изолированно, эффективные системы стремятся к интеграции информации на ранних этапах, формируя единое пространство признаков, где изображения и текст могут быть сопоставлены и поняты в контексте друг друга. Такой подход значительно повышает точность и релевантность результатов, позволяя модели эффективно находить соответствия между визуальным и текстовым контентом, даже если они не являются очевидными.
Традиционные подходы к созданию совместных представлений для задач, объединяющих различные модальности, такие как архитектуры с двойными кодировщиками, зачастую обрабатывают каждую модальность изолированно на начальных этапах. Это означает, что информация из текста и изображения, например, кодируется отдельно, без непосредственного взаимодействия на уровне признаков. Такое разделение может ограничивать способность модели улавливать тонкие и сложные взаимосвязи между различными типами данных, поскольку важные корреляции могут быть упущены до этапа объединения. В результате, итоговое совместное представление может быть менее полным и эффективным для решения задач, требующих глубокого понимания взаимосвязей между модальностями.
Изолированная обработка различных модальностей данных, например, изображения и текста, в традиционных моделях может существенно ограничивать их способность улавливать сложные взаимосвязи. Когда каждая модальность анализируется отдельно до этапа объединения, модель упускает возможность извлечь более глубокое понимание, возникающее при одновременном рассмотрении взаимодействий между ними. Это особенно критично для задач, где значение заключается не в отдельных элементах каждой модальности, а в их совместном контексте и корреляции. В результате, модель может испытывать трудности с распознаванием тонких нюансов и неявных связей, что негативно сказывается на точности и эффективности решения задач, требующих мультимодального понимания.
Взгляд за пределы изоляции: Дискриминативные вложения для усиленного объединения
Дискриминативные модели эмбеддингов представляют собой альтернативный подход к извлечению признаков, основанный на непосредственной обработке взаимодействий на уровне токенов. В отличие от традиционных методов, которые обрабатывают модальности раздельно и затем объединяют их представления, эти модели анализируют комбинации токенов из различных модальностей для формирования единого векторного представления. Это позволяет учитывать контекст и взаимосвязи между элементами разных модальностей непосредственно на этапе формирования признаков, что повышает эффективность последующей обработки и позволяет лучше улавливать сложные зависимости в данных.
Модели, использующие функцию потерь Contrastive Loss, стремятся минимизировать расстояние между векторами представлений (embeddings) семантически близких концепций из различных модальностей (например, текст и изображение) и максимизировать расстояние между несвязанными концепциями. Этот процесс обучения основан на сравнении пар представлений: если пара содержит соответствующие концепции, расстояние между их векторами уменьшается; в противном случае — увеличивается. В результате, в пространстве представлений формируется кластеризация, где близкие по смыслу элементы располагаются рядом, что позволяет более эффективно осуществлять кросс-модальное сопоставление и поиск релевантной информации. Использование Contrastive Loss позволяет модели выучивать более робастные и дискриминативные представления, улучшая качество последующего объединения (fusion) модальностей.
В отличие от простого объединения (конкатенации) эмбеддингов отдельных модальностей, метод извлечения дискриминативных эмбеддингов позволяет улавливать более тонкие взаимосвязи между элементами данных. Конкатенация рассматривает каждую модальность изолированно, не учитывая взаимодействие между ними на уровне отдельных токенов. Дискриминативные модели, напротив, непосредственно анализируют взаимодействие токенов из разных модальностей, что позволяет получить более детализированное представление об их отношениях и зависимостях, повышая точность последующей обработки и анализа.
Рассуждения во вложениях: Генеративные подходы к пониманию смысла
Генеративное рассуждение выходит за рамки простого представления данных, активно моделируя сам процесс рассуждения. В традиционных подходах модель учится отображать входные данные в выходные, в то время как генеративное рассуждение стремится воспроизвести последовательность логических шагов, которые привели к определенному выводу. Это достигается путем обучения модели генерировать промежуточные этапы рассуждений, которые можно рассматривать как объяснение принятого решения. Вместо прямого отображения входных данных в результат, модель учится строить цепочку аргументов, что позволяет ей не только выдавать правильный ответ, но и демонстрировать логическую основу этого ответа.
Обучение моделей генерации промежуточных этапов рассуждений достигается за счет использования задач предсказания следующего токена (Next-Token Prediction). В рамках этой задачи модель обучается генерировать последовательность токенов, представляющих собой шаги логического вывода, на основе входных данных. Этот процесс стимулирует модель не просто выдавать конечный результат, а явно демонстрировать процесс рассуждения, что позволяет ей лучше понимать и обрабатывать сложные задачи. Эффективность обучения повышается при использовании больших объемов данных, содержащих примеры рассуждений и соответствующие им решения.
Встраивание промежуточных этапов рассуждений в векторное пространство (embedding space) позволяет модели получить более полное и интерпретируемое представление входных данных. Традиционные методы представления данных фокусируются на конечном результате, в то время как встраивание шагов рассуждений кодирует не только сам факт, но и логическую цепочку, приведшую к нему. Это достигается путем представления каждого шага рассуждений в виде вектора, который затем соотносится с исходными данными и конечным выводом. Такая структура позволяет модели не только классифицировать или прогнозировать, но и объяснять ход своих мыслей, облегчая отладку и повышая доверие к результатам. Более того, анализ полученных векторных представлений шагов рассуждений позволяет выявить закономерности и оценить качество логических цепочек, что способствует улучшению модели.
Эффективная реализация: Масштабирование мультимодальных рассуждений с Qwen3-VL
Крупномасштабные мультимодальные языковые модели, такие как Qwen3-VL, представляют собой перспективную платформу для реализации передовых методов создания векторных представлений данных. Их способность одновременно обрабатывать и понимать информацию из различных модальностей — текст, изображения, видео — позволяет создавать более полные и контекстуально богатые представления. В отличие от традиционных подходов, Qwen3-VL не просто объединяет отдельные признаки, но и устанавливает сложные взаимосвязи между ними, что критически важно для решения задач, требующих глубокого понимания мультимодальных данных. Это открывает новые возможности в областях, таких как поиск по изображениям и видео, визуальный вопрос-ответ и создание интеллектуальных систем, способных эффективно работать с разнообразной информацией.
Методы параметрически-эффективной тонкой настройки, такие как LoRA (Low-Rank Adaptation), позволяют адаптировать крупные мультимодальные языковые модели к конкретным задачам, значительно экономя вычислительные ресурсы. Вместо обучения всех параметров модели, LoRA замораживает предварительно обученные веса и обучает лишь небольшое количество дополнительных, низкоранговых матриц. Такой подход существенно снижает требования к памяти и вычислительной мощности, делая возможным применение мощных моделей, таких как Qwen3-VL, даже на оборудовании с ограниченными возможностями. Это открывает новые перспективы для широкого спектра приложений, где адаптация модели к специфическим данным является ключевым требованием, но ресурсы для полноценного обучения ограничены.
Предложенная авторами схема UME, основанная на управляемом обучении с подкреплением (Embedder-Guided Reinforcement Learning или EG-RL), демонстрирует передовые результаты в области мультимодального анализа. В ходе тестирования на бенчмарке MMEB-V2, данная схема достигла общего балла в 61.1, что на 2.7 пункта превышает показатели наиболее сильного конкурента. Это свидетельствует о значительном прогрессе в способности модели эффективно интегрировать и анализировать информацию из различных модальностей, открывая новые возможности для задач, требующих комплексного понимания визуальных и текстовых данных.
Разработанная система продемонстрировала передовые результаты в задаче UVRB, достигнув показателя mAP в 68.3. Этот результат свидетельствует о значительном улучшении качества мультимодальных вложений и, как следствие, повышении эффективности поиска и извлечения информации. Повышенная точность в формировании вложений позволяет системе более эффективно сопоставлять различные модальности данных — изображения, видео и текст — обеспечивая более релевантные и точные результаты при поиске.
В ходе экспериментов с предложенным фреймворком зафиксировано существенное повышение эффективности извлечения информации в различных мультимодальных задачах. В частности, точность поиска изображений (MMEB-V2 Image Retrieval Hit@1) достигла 74.8%, что на 1.5 процентных пункта превышает показатели наиболее сильных базовых моделей. Аналогичные улучшения наблюдаются и в задачах поиска видео (MMEB-V2 Video Retrieval Hit@1), где показатель достиг 68.2% (+2.1 пункта), а также при поиске по визуальным документам (MMEB-V2 Visual Document NDCG@5), где достигнут результат в 78.9% (+1.3 пункта). Эти данные демонстрируют значительный прогресс в области мультимодального поиска и извлечения информации, подтверждая эффективность предложенного подхода.

Наблюдения за развитием мультимодальных систем неизменно подводят к мысли о хрупкости даже самых изящных архитектур. Работа, представленная в статье, с её акцентом на обучение с подкреплением для оптимизации траекторий рассуждений, лишь подтверждает закономерность: любая попытка создать универсальное представление данных сталкивается с необходимостью компромиссов. Как однажды заметил Джеффри Хинтон: «Иногда лучший алгоритм — это просто тот, который работает в данной конкретной ситуации». Эта фраза особенно актуальна в контексте Embed-RL, где адаптация к различным модальностям требует постоянной калибровки и готовности к тому, что оптимизированное сегодня, завтра потребует переосмысления. Ведь, в конечном счёте, задача не в создании идеального эмбеддинга, а в обеспечении работоспособности системы в реальных условиях.
Что дальше?
Представленная работа, безусловно, демонстрирует изящный подход к проблеме универсальных мультимодальных представлений. Однако, как показывает опыт, каждая «революция» в области машинного обучения неизбежно порождает новый тип технического долга. Оптимизация траекторий рассуждений с помощью обучения с подкреплением — это хорошо, но продукшен всегда найдёт способ сломать даже самую элегантную теорию. Возникает вопрос: насколько устойчива эта система к шуму в данных, к неполноте информации, к банальной нелогичности реального мира? Багтрекер, как известно, — это дневник боли, и, скорее всего, он скоро пополнится новыми строками.
Вместо того чтобы гнаться за универсальностью, возможно, стоит обратить внимание на более прагматичные задачи. Например, на методы, позволяющие быстро адаптировать модель к новым модальностям или к специфическим доменам. Или на способы верификации и отладки траекторий рассуждений — ведь, если модель «думает» неправильно, это не просто ошибка — это потенциальная катастрофа. Мы не деплоим — мы отпускаем, и рано или поздно эта «отпущенная» система столкнётся с реальностью.
В конечном счёте, успех этого направления исследований будет зависеть не только от совершенства алгоритмов, но и от способности разработчиков признавать ограничения и учитывать неизбежные компромиссы. Скрам — это просто способ убедить людей, что хаос управляем, и, возможно, настало время взглянуть на проблему мультимодальных представлений без иллюзий.
Оригинал статьи: https://arxiv.org/pdf/2602.13823.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Языковые модели и границы возможного: что делает язык человеческим?
- Визуальное мышление машин: новый вызов для ИИ
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Разумные языковые модели: новый подход к логическому мышлению
- Взрыв скорости: Оптимизация внимания для современных GPU
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Ребусы для ИИ: новый масштабный тест на сообразительность
- Квантовый разум: Новая эра языковых моделей
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Обучение языковых моделей по предпочтениям: новый подход к повышению точности
2026-02-17 09:56