Автор: Денис Аветисян
Новое исследование оценивает способность современных моделей искусственного интеллекта самостоятельно выполнять полные проекты по анализу данных, от подготовки данных до получения выводов.
В статье представлен комплексный бенчмарк для оценки производительности генеративных моделей ИИ в сквозных проектах анализа данных, демонстрирующий возможности и ограничения существующих систем.
Несмотря на значительный прогресс в области искусственного интеллекта, оценка его возможностей в выполнении комплексных задач, требующих сочетания технических, аналитических и коммуникативных навыков, остается сложной проблемой. В данной работе, ‘Benchmarking AI Performance on End-to-End Data Science Projects’, предложен новый подход к оценке производительности генеративных моделей ИИ при решении полных проектов в области анализа данных. Результаты исследования показали, что современные модели, такие как Claude Opus 4.6, способны демонстрировать результаты, сопоставимые с уровнем подготовки студентов, однако требуют проверки, особенно в задачах, требующих субъективной оценки. Сможет ли ИИ полностью автоматизировать процесс анализа данных или же роль эксперта-аналитика останется незаменимой?
Автоматизированная Оценка: Преодолевая Узкие Места в Развитии Больших Языковых Моделей
Традиционно оценка больших языковых моделей (БЯМ) представляет собой трудоемкий, отнимающий много времени и дорогостоящий процесс, существенно замедляющий прогресс в данной области. Каждая проверка требует участия квалифицированных специалистов для анализа сгенерированного текста на соответствие заданным критериям — точность, логичность, креативность и т.д. Этот ручной подход не позволяет оперативно тестировать многочисленные итерации моделей, а также эффективно сравнивать их производительность. В результате, разработчики сталкиваются с задержками в выявлении и устранении недостатков, что приводит к увеличению затрат и замедлению внедрения инновационных решений на основе БЯМ. Автоматизация оценки становится критически важной для ускорения разработки и обеспечения надежности этих мощных инструментов.
Существующие эталоны оценки больших языковых моделей (LLM) зачастую не способны адекватно отразить их возможности в реальных задачах анализа данных. Традиционные тесты, сконцентрированные на узких областях, как правило, не учитывают многогранность и сложность практических сценариев, с которыми сталкиваются специалисты в области Data Science. Например, оценка способности модели к интерпретации неструктурированных данных, выявлению скрытых закономерностей или решению комплексных проблем, требующих комбинирования различных навыков, остается сложной задачей для существующих методик. Это приводит к тому, что результаты тестов могут не соответствовать реальной производительности LLM при работе с реальными данными, что затрудняет выбор наиболее подходящей модели для конкретной задачи и замедляет прогресс в области искусственного интеллекта. Таким образом, существует острая необходимость в разработке более комплексных и реалистичных эталонов, способных достоверно оценивать возможности LLM в контексте реальных задач анализа данных.
Для эффективной разработки больших языковых моделей (LLM) и обеспечения достоверности сравнений между ними, масштабируемые и автоматизированные методы оценки становятся жизненно необходимыми. Традиционные подходы, требующие ручной проверки, существенно замедляют прогресс и ограничивают возможности быстрого итеративного улучшения. Автоматизация позволяет проводить оценку на гораздо больших объемах данных, выявлять слабые места моделей и отслеживать прогресс в режиме реального времени. Более того, стандартизированные автоматизированные оценки обеспечивают объективное и воспроизводимое сравнение различных LLM, что крайне важно для выбора оптимальной модели для конкретных задач и для стимулирования дальнейших исследований в области искусственного интеллекта. Без эффективных автоматизированных инструментов, развитие LLM сталкивается с серьезными ограничениями, препятствующими реализации их полного потенциала.
DataSciBench: Строгий Эталон для LLM в Области Науки о Данных
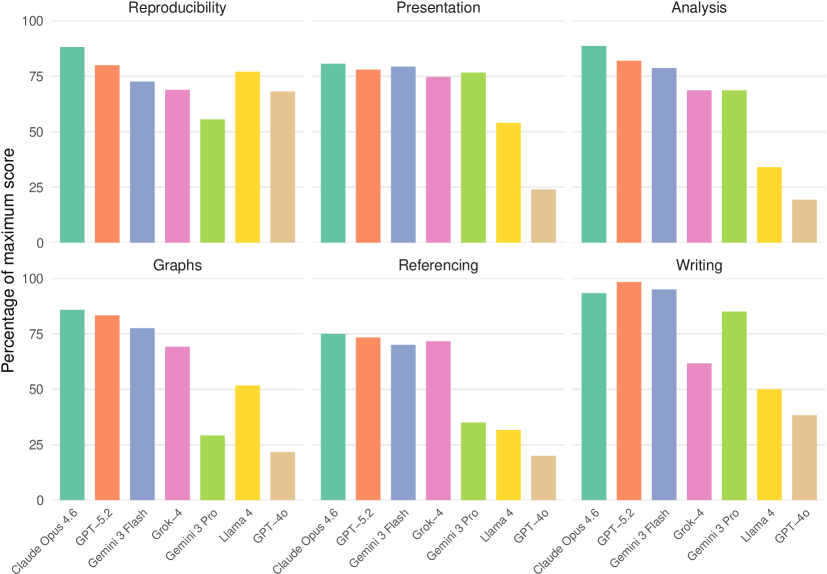
DataSciBench — это новый эталон, предназначенный для оценки больших языковых моделей (LLM) при решении комплексных задач анализа данных. В отличие от традиционных тестов, фокусирующихся на отдельных навыках, DataSciBench требует от LLM выполнения полного цикла работы с данными, включающего очистку, разведочный анализ, визуализацию и построение прогностических моделей. Эталон позволяет оценить способность LLM к последовательному выполнению задач, интеграции различных инструментов и принятию обоснованных решений на каждом этапе проекта, что обеспечивает более реалистичную оценку их применимости в сфере Data Science.
В качестве основы для оценки используются реальные наборы данных, полученные из открытого источника Open Data Toronto. Это обеспечивает практическую релевантность и сложность задач, с которыми сталкиваются модели. Наборы данных охватывают различные предметные области и форматы, что позволяет оценить способность моделей к работе с неструктурированной и неполной информацией, типичной для реальных проектов анализа данных. Использование данных из Open Data Toronto гарантирует, что оценка проводится на задачах, отражающих актуальные потребности и проблемы в области анализа данных, и позволяет сравнить производительность моделей в контексте практических приложений.
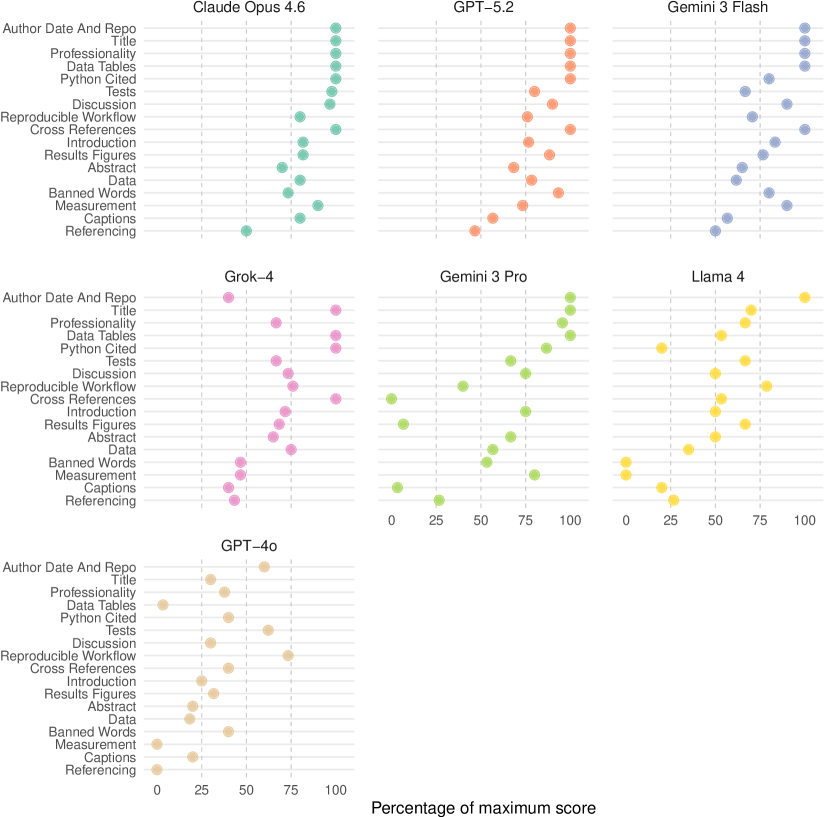
Процесс выполнения проектов в DataSciBench структурирован и состоит из девяти последовательных этапов, что обеспечивает унифицированный подход к промптингу и оценке LLM. Данная структура позволяет последовательно оценивать способность модели решать задачи, начиная с формулировки проблемы и заканчивая построением и оценкой предсказательной модели. Для реализации и автоматизации этапов используются инструменты: Quarto — для создания воспроизводимых отчетов и документации; UV — для управления зависимостями и виртуальными окружениями; и pydantic — для валидации данных и обеспечения типобезопасности. Использование этих инструментов обеспечивает надежность и воспроизводимость результатов, что критически важно для объективной оценки LLM в контексте задач анализа данных.
Внедрение BibTeX в конвейер DataSciBench обеспечивает воспроизводимость исследований и точную цитируемость используемых ресурсов. BibTeX позволяет автоматически генерировать библиографические списки в стандартном формате, что упрощает проверку источников и подтверждение достоверности результатов. Использование BibTeX гарантирует, что все внешние источники, такие как научные статьи, книги и веб-сайты, корректно указаны и доступны для дальнейшего изучения. Это особенно важно для проектов DataSciBench, где анализ данных и построение моделей опираются на существующие исследования и алгоритмы, и точная ссылка на эти работы является неотъемлемой частью научной добросовестности и возможности повторного проведения анализа.
LLM в Роли Судьи: Автоматизация Оценки с Высокой Точностью
Для автоматизированной оценки проектов, сгенерированных различными языковыми моделями, была разработана система “LLM-as-a-judge”. В качестве основной модели для оценки используется Anthropic Claude Sonnet 4.5, обеспечивающая последовательную и объективную проверку кода. Система позволяет оценивать проекты по заданным критериям, включая корректность кода, качество анализа данных и общую структуру проекта, что позволяет стандартизировать процесс оценки и снизить субъективность.
Оценка проектов, генерируемых различными языковыми моделями, осуществляется посредством автоматизированного конвейера с использованием заранее определенной рубрики. Данная рубрика стандартизирует процесс оценки, фокусируясь на трех ключевых аспектах: корректности кода, качестве анализа данных и общей структуре проекта. Четкое определение критериев оценки по каждому из этих пунктов позволяет обеспечить последовательность и объективность при проверке, минимизируя субъективные факторы и обеспечивая сопоставимость результатов для различных проектов и моделей.
Для валидации надежности автоматизированного оценочного конвейера, в качестве перекрестной оценки подмножества проектов был использован GPT-5.2. Данный подход позволил обеспечить согласованность оценок и минимизировать субъективность. Статистический анализ показал стандартное отклонение всего в 1.2 балла из 45, что демонстрирует высокую степень надежности и воспроизводимости оценок, выдаваемых конвейером ‘LLM-as-a-judge’. Низкое стандартное отклонение подтверждает стабильность системы и ее способность к объективной оценке проектов.
Для оценки и подтверждения работоспособности системы автоматической оценки, были использованы существующие отраслевые бенчмарки, включающие HumanEval, MBPP и SWE-bench. HumanEval предназначен для оценки способности LLM генерировать функциональный код на основе текстового описания. MBPP (Mostly Basic Programming Problems) проверяет навыки решения простых задач программирования. SWE-bench, в свою очередь, оценивает способность LLM решать более сложные задачи, типичные для разработки программного обеспечения. Использование этих бенчмарков позволило провести объективное сравнение производительности системы ‘LLM-as-a-Judge’ и подтвердить ее эффективность в оценке проектов, генерируемых различными LLM.
Картина Производительности: Бенчмаркинг Ведущих LLM
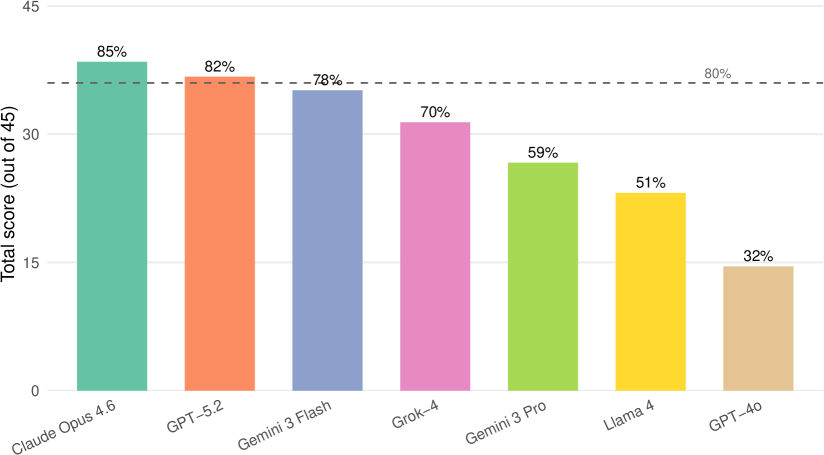
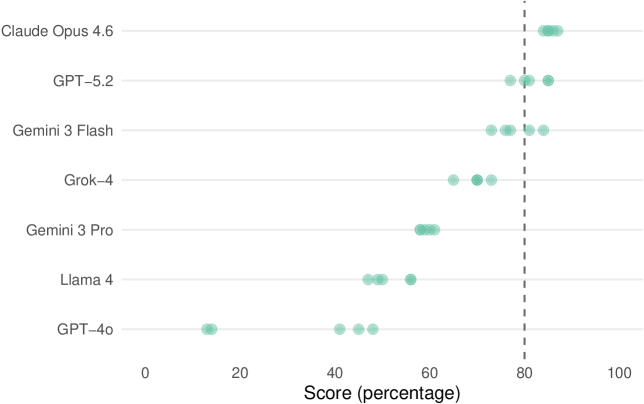
Модель Claude Opus 4.6 продемонстрировала выдающиеся результаты в комплексном тестировании DataSciBench, набрав 85% от максимального балла. Этот показатель не только превзошел результаты всех протестированных аналогов, но и соответствует уровню знаний и навыков студента, успешно осваивающего программу бакалавриата, оцениваемому как «хорошо» или «очень хорошо» (соответствует порогу в 80%). Полученные данные свидетельствуют о значительном прогрессе в возможностях больших языковых моделей в решении задач, характерных для реальных рабочих процессов в области анализа данных и науки о данных, и позволяют оценить потенциал данной модели для автоматизации и поддержки деятельности специалистов.
Исследования показали, что языковая модель GPT-5.2 продемонстрировала результаты, сопоставимые с лидирующей моделью Claude Opus 4.6, набрав 82% в комплексном тесте DataSciBench. Такое близкое соответствие свидетельствует о значительном прогрессе в разработке больших языковых моделей и их способности решать сложные задачи в области анализа данных. Полученные результаты подчеркивают, что GPT-5.2 эффективно справляется с задачами, требующими логического мышления и умения работать с информацией, что делает ее серьезным конкурентом в сфере искусственного интеллекта и обработки естественного языка. Достижение 82% подтверждает, что модель достигла уровня, близкого к успеваемости студента на продвинутом этапе обучения в университете.
Модель Gemini 3 Flash продемонстрировала впечатляющие результаты, набрав 78% на DataSciBench, что соответствует уровню успеваемости студента, получающего оценку A-/B+. Данный показатель свидетельствует о высокой компетентности модели в решении задач, типичных для рабочих процессов в области Data Science. Несмотря на незначительное отставание от лидеров, Claude Opus 4.6 и GPT-5.2, Gemini 3 Flash демонстрирует надежную производительность и способность успешно справляться с широким спектром аналитических задач, что делает её ценным инструментом для специалистов в данной области. Такой уровень эффективности подтверждает значительный прогресс в разработке больших языковых моделей и их растущую роль в автоматизации и оптимизации процессов анализа данных.
Исследования показали, что модель GPT-4o демонстрирует умеренный уровень производительности, набрав 32% в ходе тестирования на DataSciBench. Этот результат значительно уступает показателям более новых моделей, таких как Claude Opus 4.6, GPT-5.2 и Gemini 3 Flash, что указывает на существенный прогресс в развитии больших языковых моделей за последнее время. В частности, разница в оценках подчеркивает важность постоянной оптимизации архитектуры и обучающих данных для повышения эффективности и точности в решении задач, связанных с анализом и обработкой данных.
Результаты, полученные при оценке производительности больших языковых моделей, подчеркивают критическую важность использования всесторонних бенчмарков, отражающих реальные рабочие процессы в области анализа данных. Традиционные тесты часто оказываются недостаточными для адекватной оценки способности моделей решать практические задачи, с которыми сталкиваются специалисты по Data Science. Комплексные бенчмарки, такие как DataSciBench, позволяют более точно измерить не только общие языковые способности, но и умение моделей применять знания для решения специфических задач, включая обработку данных, статистический анализ и машинное обучение. Использование таких инструментов необходимо для объективной оценки прогресса в развитии LLM и определения наиболее подходящих моделей для конкретных приложений, что способствует более эффективному и надежному внедрению искусственного интеллекта в сферу науки о данных.
Представленное исследование демонстрирует, что даже самые передовые модели генеративного искусственного интеллекта, такие как Claude Opus 4.6, хоть и способны выполнять задачи на уровне студента-бакалавра в рамках комплексных проектов анализа данных, всё же нуждаются в контроле со стороны человека, особенно в тех случаях, когда требуется суждение. Это подтверждает идею о том, что робастность системы возникает не из централизованного управления, а из локальных правил, действующих в рамках каждого этапа обработки данных. Как однажды заметил Стивен Хокинг: «Интеллект — это способность адаптироваться к изменениям». Подобная адаптивность, в контексте исследования, требует от человека не управления процессом, а влияния на него, корректируя траекторию на основе оценки результатов, что и формирует устойчивую и эффективную систему.
Куда Ведет Дорога?
Представленная работа, оценивая возможности генеративных моделей в решении комплексных задач анализа данных, лишь обнажает глубину нерешенных вопросов. Достижение «уровня студента» — это скорее констатация способности к имитации, чем проявление истинного понимания. Важнее осознать, что любые метрики, даже те, что основаны на оценке других моделей, неизбежно упрощают реальную сложность данных и контекста. Попытки создать универсальную систему оценки, вероятно, обречены на провал — порядок не нуждается в архитекторе, он возникает из локальных правил.
Будущие исследования должны сместить фокус с простого повышения «результативности» на понимание границ применимости таких моделей. Где они действительно усиливают возможности человека, а где — лишь создают иллюзию контроля? Какие типы задач принципиально не поддаются автоматизации из-за необходимости учета нюансов, не выражаемых в формальных критериях?
В конечном счете, ценность подобных работ не в создании «искусственного интеллекта», а в углублении понимания самих процессов анализа данных. Контроль — иллюзия, влияние — реально. Задача состоит не в том, чтобы заменить человека машиной, а в том, чтобы создать инструменты, расширяющие его возможности и позволяющие ему лучше понимать мир вокруг.
Оригинал статьи: https://arxiv.org/pdf/2602.14284.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Искусственный интеллект и закон: гармония неизбежна
- Квантовые вычисления для молекул: оптимизация ресурсов
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Мир текстов без границ: Новые возможности многоязыковых представлений
- Топoлогические формы и тайны Вселенной
- Молекулярный интеллект: проверка химического мышления
- Звук как помощник зрения: Новые горизонты генерации видео
- Живые частицы: самоорганизация в новом свете
2026-02-17 16:33