Автор: Денис Аветисян
Исследователи представили UniWeTok — инновационный дискретный визуальный токенизатор, открывающий путь к более эффективным и мощным моделям, способным понимать и генерировать как изображения, так и текст.
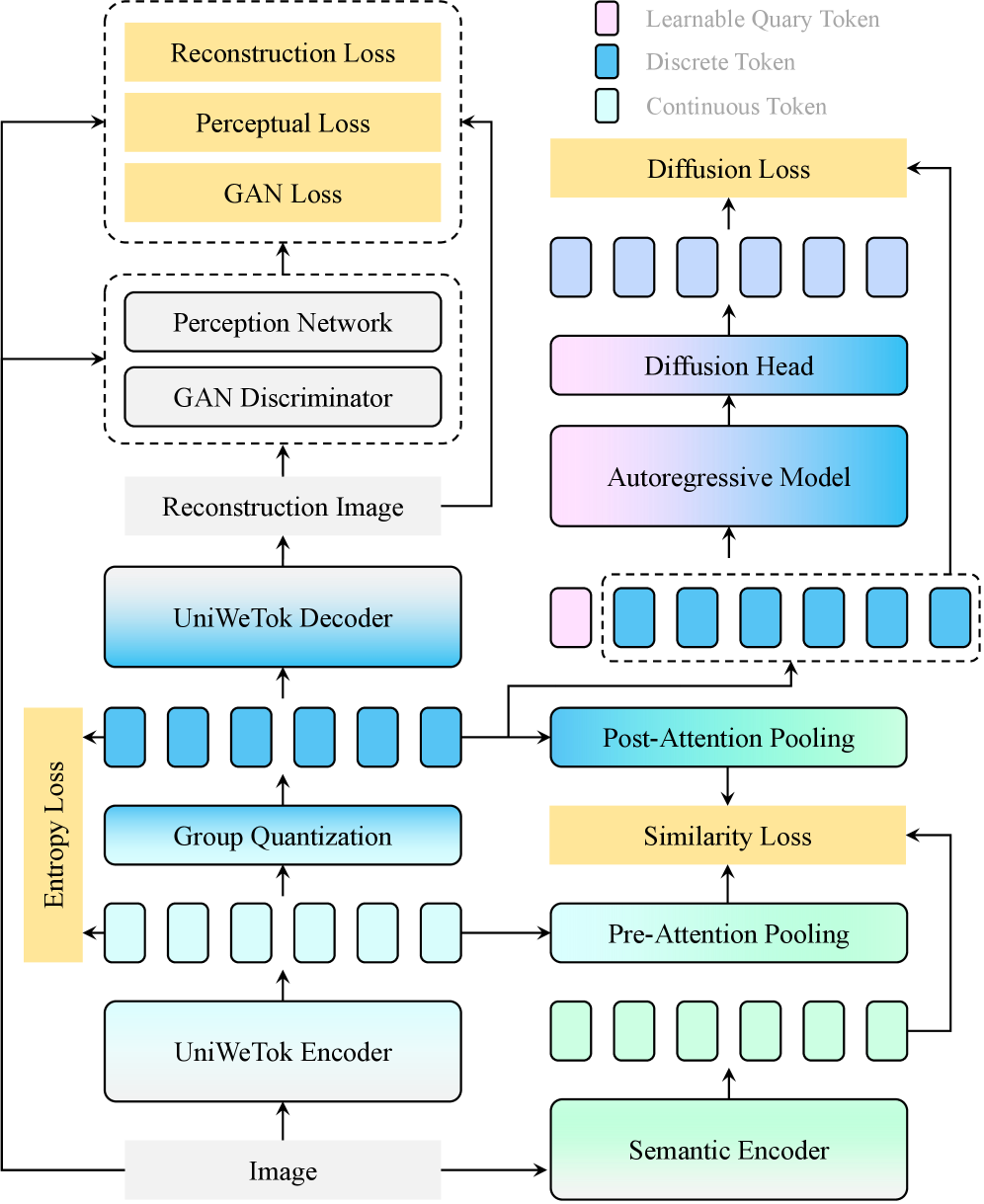
UniWeTok использует кодовую книгу размера 2^128 для достижения передовых результатов в сжатии изображений, извлечении семантики и генеративном моделировании.
Существующие методы визуальной токенизации часто оказываются неспособны одновременно обеспечить высокую точность реконструкции, семантическую выразительность и возможности генерации. В данной работе представлена система UniWeTok — унифицированный двоичный токенизатор с кодовым книгой размера 2^{128} для унифицированных мультимодальных больших языковых моделей. Предложенный подход демонстрирует передовые результаты в задачах генерации изображений, семантического извлечения и понимания мультимодальных данных, требуя при этом значительно меньше вычислительных ресурсов. Сможет ли UniWeTok стать ключевым компонентом для создания более эффективных и мощных мультимодальных моделей будущего?
За пределами Пикселей: Поиск Эффективной Визуальной Токенизации
Традиционные методы обработки изображений сталкиваются со значительными трудностями при работе с данными высокого разрешения. Каждый пиксель требует индивидуальной обработки, что приводит к экспоненциальному росту вычислительных затрат и потребления памяти по мере увеличения размера изображения. Это особенно критично в современных приложениях, таких как обработка спутниковых снимков, медицинская визуализация и создание контента сверхвысокой четкости, где изображения могут содержать миллиарды пикселей. Необходимость в обработке таких объемов данных в реальном времени требует огромных вычислительных ресурсов, что делает традиционные подходы непрактичными и дорогостоящими. В результате, возникает потребность в более эффективных методах, способных существенно снизить вычислительную нагрузку и обеспечить возможность обработки изображений высокого разрешения с приемлемой скоростью и стоимостью.
Существующие методы векторной квантизации, такие как VQ-VAE и VQGAN, хоть и демонстрируют впечатляющие результаты в сжатии изображений, сталкиваются с серьезными ограничениями при работе с данными большого объема. В основе этих методов лежит операция поиска ближайшего вектора в кодовом словаре, что требует значительных вычислительных затрат и времени, особенно при увеличении разрешения изображений и размеров словаря. По мере масштабирования, эта операция поиска становится узким местом, препятствующим эффективной обработке данных и снижающим общую производительность системы. В результате, несмотря на свою эффективность в сжатии, традиционные подходы векторной квантизации оказываются непрактичными для задач, требующих обработки изображений в реальном времени или работы с огромными массивами визуальной информации.
Необходимость в более эффективных методах дискретизации изображений обусловлена растущими требованиями к обработке визуальной информации. Традиционные подходы, основанные на векторизации и квантовании, сталкиваются с ограничениями масштабируемости, поскольку операции поиска в таблицах признаков становятся узким местом при работе с изображениями высокого разрешения. В связи с этим, исследователи стремятся к разработке алгоритмов, способных сжимать изображения в дискретные токены, сохраняя при этом высокую производительность и снижая вычислительные затраты. Оптимизация этого процесса позволит значительно ускорить обработку визуальных данных в различных областях, включая компьютерное зрение, машинное обучение и анализ изображений, открывая новые возможности для создания интеллектуальных систем и приложений.

Квантование Без Таблиц Поиска: Основа Эффективности
Квантование без таблиц поиска (Lookup-Free Quantization) представляет собой значительный прорыв в области оптимизации вычислительных ресурсов. Традиционные методы квантования требуют хранения и доступа к таблицам поиска для преобразования значений, что влечет за собой дополнительные затраты памяти и времени. Данная технология устраняет необходимость в этих таблицах, выполняя квантование непосредственно на основе математических вычислений. Это позволяет существенно снизить вычислительную нагрузку и повысить скорость обработки данных, особенно в задачах, требующих высокой производительности и ограниченных ресурсов, таких как мобильные устройства или встроенные системы. Отсутствие необходимости в хранении и обращении к таблицам поиска также уменьшает общий размер модели, что важно для развертывания на устройствах с ограниченным объемом памяти.
Групповая квантизация без таблиц поиска (Group-Wise Lookup-Free Quantization) оптимизирует процесс квантования за счет одновременного применения к группам признаков. Вместо квантования каждого признака по отдельности, эта техника обрабатывает их совместно, что позволяет уменьшить вычислительные затраты и объем памяти. Такой подход повышает степень сжатия данных, поскольку корреляция между признаками в группе учитывается при квантовании. Кроме того, групповая квантизация ускоряет процесс вычислений, поскольку снижается необходимость в отдельных операциях квантования для каждого признака, что особенно важно для задач, требующих высокой производительности и обработки больших объемов данных.
WeTok использует технику квантования без таблиц поиска для создания базового визуального токенизатора, представляющего собой ключевой элемент для последующих разработок в области компьютерного зрения. Данный токенизатор обеспечивает эффективное преобразование визуальной информации в дискретное представление, необходимое для различных задач, таких как распознавание образов и обработка изображений. Архитектура WeTok спроектирована таким образом, чтобы служить надежной отправной точкой и эталоном для оценки новых подходов к визуальной токенизации, позволяя сравнивать и улучшать производительность различных моделей и алгоритмов.
UniWeTok: Унифицированная Платформа для Визуального Понимания
UniWeTok представляет собой унифицированную структуру, объединяющую надежное сжатие данных, семантическую экстракцию и генеративные априорные знания в едином фреймворке. Данный подход позволяет достичь передовых результатов в области визуального понимания, демонстрируя оценку FID в 1.38. Этот показатель превосходит результат, полученный моделью REPA, которая имеет оценку 1.42. Интеграция этих трех ключевых компонентов в единую систему обеспечивает повышение эффективности и точности обработки визуальной информации.
Архитектура Hybrid Backbone, являющаяся ключевым компонентом UniWeTok, объединяет сверточные и механизмы внимания для улучшения представления признаков. Сверточные слои эффективно захватывают локальные паттерны и пространственные характеристики изображения, в то время как механизмы внимания позволяют модели динамически фокусироваться на наиболее релевантных областях изображения и устанавливать долгосрочные зависимости между признаками. Такое комбинирование позволяет получить более полное и информативное представление изображения, что способствует повышению точности и эффективности модели в задачах визуального понимания. Использование как сверточных, так и attention-based слоев позволяет компенсировать недостатки каждого из подходов и извлечь максимальную пользу из входных данных.
Трехэтапный процесс обучения UniWeTok предназначен для оптимизации производительности на различных разрешениях и наборах данных, обеспечивая масштабируемость и устойчивость системы. Первый этап включает предварительное обучение модели на больших объемах данных для получения общих признаков. Второй этап — точная настройка на целевых данных, адаптирующая модель к специфическим задачам. На заключительном этапе применяется дистилляция знаний, позволяющая перенести знания из более сложной модели в более компактную, что повышает эффективность и снижает вычислительные затраты. Такая последовательность обучения позволяет UniWeTok эффективно работать с изображениями разных размеров и из различных источников, сохраняя при этом высокую точность и надежность.
В UniWeTok для повышения эффективности извлечения семантической информации и ограничения пространства признаков используется метод Pre-Post Distillation и функция активации SigLu. Pre-Post Distillation позволяет передавать знания от более крупной модели к UniWeTok, улучшая ее способность к обобщению. SigLu Activation, в свою очередь, обеспечивает более эффективное представление признаков за счет использования сигмоидальной функции, что способствует повышению точности классификации. В результате применения данных технологий, UniWeTok достигает точности Zero-Shot Top-1 в 51.32%.

Тестирование и Широкая Применимость: Наборы Данных и Интеграция Модели
Модель UniWeTok подверглась всесторонней проверке на общепризнанных наборах данных, включая ImageNet, MS-COCO и DataComp-1B, что позволило продемонстрировать её способность к обобщению и адаптации к различным визуальным задачам. Тщательное тестирование на этих разнообразных данных подтверждает устойчивость UniWeTok к новым, ранее не встречавшимся изображениям и сценариям, что является ключевым показателем эффективности любой модели компьютерного зрения. Достигнутые результаты указывают на высокую степень обобщающей способности модели, позволяющей эффективно решать широкий спектр задач, от классификации изображений до детального распознавания объектов, даже в сложных и меняющихся условиях.
Эффективность модели UniWeTok значительно повышается за счет применения техники Generative-Aware Prior, направленной на обучение генеративным априорным знаниям. Этот подход позволяет модели более эффективно генерировать реалистичные и связные изображения, что подтверждается значением gFID, достигшим 2.38. Примечательно, что добавление Query-токена позволило улучшить этот показатель с первоначальных 2.66, демонстрируя значительное влияние данного компонента на качество генерируемых данных и подтверждая эффективность предложенного метода обучения.
Модель UniWeTok демонстрирует свою универсальность, успешно интегрируясь с существующими архитектурами, такими как BitDance. В результате этой интеграции, UniWeTok выступает в роли надежного визуального токенизатора для унифицированных мультимодальных больших языковых моделей (MLLM). Экспериментальные данные показывают, что данная комбинация достигает показателя DPG (Data-Preserving Generation) в 86.63, что превосходит результат FLUX.1 (Dev) в 83.84. Это подтверждает способность UniWeTok не только эффективно работать самостоятельно, но и значительно улучшать производительность сложных мультимодальных систем, расширяя возможности анализа и генерации визуального контента.
В ходе исследований модель UniWeTok продемонстрировала выдающуюся эффективность при значительно сниженных затратах на обучение. Для достижения сопоставимых и даже превосходящих результатов, UniWeTok потребовалось всего 33 миллиарда токенов, что существенно меньше, чем у модели REPA, которой для обучения потребовалось 262 миллиарда токенов. В результате, UniWeTok достиг общего балла GEdit в 5.09, незначительно превзойдя показатель OmniGen, равный 5.06. Данное достижение подчеркивает оптимизированную архитектуру и эффективность алгоритмов обучения, используемых в UniWeTok, что делает её привлекательным решением для широкого спектра задач компьютерного зрения и обработки изображений.
Исследование демонстрирует, что эффективное представление визуальной информации в дискретном виде является ключевым для создания мощных мультимодальных моделей. Авторы предлагают UniWeTok — токенизатор, способный кодировать изображения с использованием огромного кодекса размером $2^{128}$, что позволяет извлекать семантически богатые признаки. Этот подход, подобно тому, как физик ищет фундаментальные закономерности в природе, стремится к созданию универсального языка представления данных. Как однажды заметил Ян ЛеКюн: «Машинное обучение — это не только алгоритмы, но и умение находить закономерности в данных». UniWeTok, в сущности, реализует эту идею, преобразуя непрерывные визуальные данные в дискретные токены, открывая путь к более эффективным и интеллектуальным системам искусственного интеллекта.
Куда же дальше?
Представленный подход, демонстрируя впечатляющие результаты в области дискретизации визуальной информации, неизбежно наталкивается на вопрос о границах применимости столь масштабного кодового пространства. Кодовая книга размера 2128, безусловно, впечатляет, однако возникает закономерный интерес: не является ли это избыточностью, замаскированной под эффективностью? Необходимо дальнейшее исследование влияния размера кодовой книги на истинную семантическую выразительность, а также на вычислительные издержки, связанные с её поддержанием и использованием. Каждое отклонение от оптимального размера — это возможность выявить скрытые зависимости между размером, сжатием и качеством реконструкции.
Особенно актуальным представляется вопрос о расширении концепции UniWeTok за пределы статичных изображений. Применение к динамическим данным — видео, временным рядам — ставит перед исследователями новые задачи, связанные с обеспечением согласованности дискретизации во времени и адаптацией к изменяющимся условиям. Вероятно, потребуются гибридные подходы, сочетающие дискретную и непрерывную репрезентации, чтобы достичь оптимального баланса между эффективностью и точностью.
И, наконец, не стоит забывать о фундаментальной проблеме интерпретируемости. Дискретизация, как и любое сжатие информации, неизбежно приводит к потере деталей. Ключевым направлением будущих исследований видится разработка методов, позволяющих не только эффективно кодировать визуальную информацию, но и понимать, какие аспекты семантики были сохранены, а какие — отброшены. Именно в этом, а не в гонке за все более впечатляющими цифрами, лежит истинный потенциал унифицированных мультимодальных моделей.
Оригинал статьи: https://arxiv.org/pdf/2602.14178.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Молекулярный интеллект: проверка химического мышления
- Мир текстов без границ: Новые возможности многоязыковых представлений
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Искусственный интеллект и закон: гармония неизбежна
- Зрение и язык: новый шаг к автономному вождению
- Нейросети на резистивной памяти: Новый подход к решению сложных задач
- Скрытые симметрии материи: новая схема для экзотических фаз
- ЭКГ будущего: AI-модель для комплексной диагностики
2026-02-17 23:17