Автор: Денис Аветисян
Исследователи представили REDSearcher — систему, позволяющую обучать интеллектуальных агентов для эффективного решения сложных, многоэтапных задач с использованием веб-поиска и оптимизации обучения.
Предложен фреймворк REDSearcher для масштабируемого и экономичного обучения агентов, способных к поиску решений в долгосрочных задачах путем оптимизации синтеза задач, обучения и пост-обучения.
Несмотря на значительный прогресс больших языковых моделей, оптимизация их для решения сложных задач глубокого поиска остается серьезной проблемой из-за редкости качественных траекторий и высокой стоимости взаимодействия с внешними инструментами. В данной работе представлена система REDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents, объединяющая синтез задач, промежуточное и конечное обучение для масштабируемой оптимизации агентов поиска. Предложенный подход позволяет генерировать сложные задачи, поощрять активное использование инструментов и усиливать базовые возможности агентов, существенно снижая затраты на обучение. Не откроет ли это путь к созданию более эффективных и доступных интеллектуальных систем для решения реальных задач поиска и принятия решений?
Неизбежность Глубокого Рассуждения
Несмотря на впечатляющие возможности, традиционные большие языковые модели демонстрируют трудности при решении задач, требующих развернутого рассуждения и синтеза информации. Они часто оказываются неспособны эффективно объединять разрозненные данные из различных источников, выявлять ключевые взаимосвязи и формировать последовательные, логически обоснованные выводы. Эта проблема особенно проявляется в ситуациях, когда необходимо не просто извлечь информацию, но и проанализировать ее, оценить достоверность и использовать для решения сложных проблем, требующих многоступенчатого анализа и учета множества факторов. В результате, модели могут выдавать поверхностные или неполные ответы, упуская важные детали и приводя к ошибочным заключениям, несмотря на кажущуюся убедительность формулировок.
Ограничения традиционных больших языковых моделей особенно заметны в сложных сценариях “глубокого поиска”, требующих последовательного сбора информации. В подобных задачах, растянутых во времени и требующих многоступенчатого анализа, модели часто демонстрируют снижение точности и неспособность эффективно поддерживать контекст на протяжении всего процесса. Приходится сталкиваться с тем, что первоначальные предположения и поисковые запросы, не подкрепленные достаточным анализом промежуточных результатов, приводят к отклонению от верного пути и необходимости повторного поиска. Это особенно критично в ситуациях, когда информация распределена по множеству источников и требует интеграции для формирования целостной картины, что подчеркивает потребность в системах, способных не просто извлекать данные, но и активно планировать и корректировать стратегию поиска.
Эффективный глубокий поиск требует от агентов не просто извлечения информации, но и способности к динамическому планированию и надежному обоснованию запросов. В отличие от простого поиска по ключевым словам, сложные задачи требуют от системы определения последовательности действий для достижения цели, адаптации стратегии в процессе получения новых данных и проверки достоверности найденной информации. Такие агенты должны уметь формулировать уточняющие вопросы, оценивать релевантность источников и интегрировать полученные знания в последовательную и логически обоснованную картину. Надежное обоснование запросов подразумевает способность агента объяснить ход своих рассуждений и предоставить доказательства в поддержку своих выводов, что критически важно для повышения доверия к результатам поиска и обеспечения прозрачности процесса принятия решений.
Современные подходы к поиску информации, несмотря на значительный прогресс в области обработки естественного языка, часто оказываются неэффективными при решении сложных задач, требующих глубокого анализа и синтеза данных. Это проявляется в неточности результатов и избыточном расходовании вычислительных ресурсов, поскольку системы нередко возвращают нерелевантную информацию или тратят время на повторный сбор уже известных фактов. Ограничения текущих алгоритмов особенно заметны в сценариях, где требуется последовательное уточнение запросов и проверка достоверности полученных сведений, приводя к снижению производительности и увеличению затрат на обработку информации. Таким образом, существующие методы нуждаются в совершенствовании для обеспечения более точных, эффективных и экономичных решений в области интеллектуального поиска.
REDSearcher: Архитектура Разумных Агентов
REDSearcher представляет собой новую структуру для обучения агентов, использующих инструменты, разработанную специально для эффективной работы в задачах глубокого поиска и обработки мультимодальных данных. В отличие от традиционных подходов, REDSearcher ориентирован на создание агентов, способных не только находить информацию, но и интегрировать данные из различных источников, таких как текст, изображения и видео. Ключевой особенностью является оптимизация для сложных поисковых сценариев, требующих анализа больших объемов информации и адаптации к различным типам данных, что позволяет агентам демонстрировать высокую производительность в задачах, где требуется глубокое понимание контекста и сложных взаимосвязей.
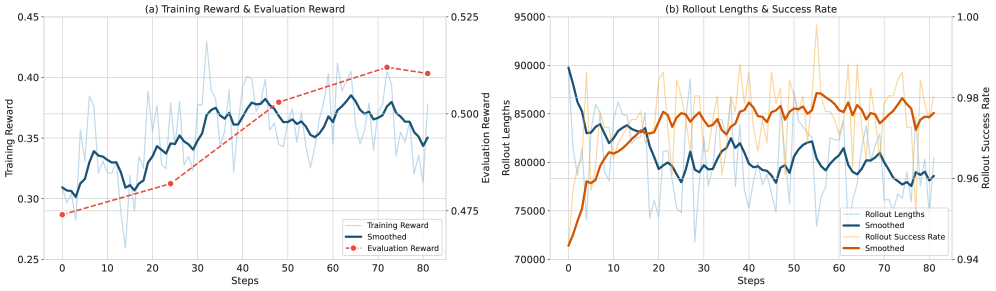
Ключевым нововведением REDSearcher является трехэтапный процесс обучения, в котором этап ‘Mid-Training’ концентрируется на приобретении навыков — привязке к намерению (intent-anchored grounding) и иерархическом планировании. Важно отметить, что данный этап осуществляется независимо от интерактивного выполнения задач. Это позволяет агенту сначала освоить логику решения задач и построение планов, не требуя непосредственного взаимодействия с внешней средой или пользователем, что существенно повышает масштабируемость и экономическую эффективность обучения.
Разделение процесса обучения на этапы, не зависящие от интерактивного исполнения, значительно повышает масштабируемость и экономическую эффективность REDSearcher. Традиционные методы обучения агентов, требующие постоянного взаимодействия с окружением, становятся вычислительно дорогими и трудно масштабируемыми при усложнении задач. Предложенный подход позволяет предварительно обучать навыки привязки интентов к данным и иерархического планирования в изолированной среде, снижая потребность в дорогостоящих интерактивных сессиях. Это, в свою очередь, позволяет более эффективно разрабатывать агентов со сложными возможностями рассуждения, требующих значительных вычислительных ресурсов, и значительно сокращает время, необходимое для обучения и развертывания.
В основе REDSearcher лежит большая языковая модель Qwen3-30B-A3B, разработанная компанией Alibaba. Эта модель представляет собой авторегрессионную языковую модель с 30 миллиардами параметров, обученную на обширном корпусе данных, включающем текст и код. Qwen3-30B-A3B отличается высокой производительностью в задачах обработки естественного языка, включая генерацию текста, машинный перевод и ответы на вопросы. Использование данной архитектуры позволяет REDSearcher эффективно выполнять сложные рассуждения и обеспечивать качественное взаимодействие с пользователем в задачах глубокого поиска и обработки мультимодальных данных. Модель поддерживает как английский, так и китайский языки, что расширяет возможности REDSearcher в глобальном масштабе.

Пост-Обучение: Оттачивание Разума Агента
Фаза “Пост-обучения” включает в себя два основных метода улучшения производительности агента: контролируемое дообучение и обучение с подкреплением, ориентированное на агента. Контролируемое дообучение использует высококачественные обучающие данные для точной настройки модели и повышения ее способности к обобщению. Обучение с подкреплением, в свою очередь, оптимизирует стратегии интерактивного поиска агента, позволяя ему более эффективно исследовать информационное пространство и адаптироваться к различным задачам. Комбинация этих двух подходов обеспечивает существенное повышение эффективности агента в решении сложных задач и достижении поставленных целей.
Супервизированное обучение (supervised fine-tuning) на высококачественных данных позволяет уточнить модель, оптимизируя ее способность к генерации релевантных ответов и выполнению задач. В процессе обучения модель корректирует свои параметры на основе размеченных примеров, повышая точность и надежность. Параллельно, обучение с подкреплением (reinforcement learning) фокусируется на оптимизации стратегий интерактивного поиска информации. Модель обучается выбирать наиболее эффективные последовательности действий для достижения цели, оценивая результаты каждого шага и корректируя свою стратегию для максимизации вознаграждения. Комбинация этих двух подходов позволяет достичь существенного улучшения производительности агента, обеспечивая как точность в генерации контента, так и эффективность в поиске и использовании информации.
Критически важным элементом процесса обучения является использование «Функционально-эквивалентной среды моделирования». Данная среда позволяет проводить эффективное тестирование и сбор данных, необходимых для обучения агента, без необходимости использования и обращения к реальным API. Это значительно ускоряет процесс итеративной доработки, снижает затраты и позволяет проводить большое количество экспериментов для оптимизации стратегий поиска и синтеза информации, избегая ограничений и потенциальных проблем, связанных с использованием внешних сервисов и их API-ключей.
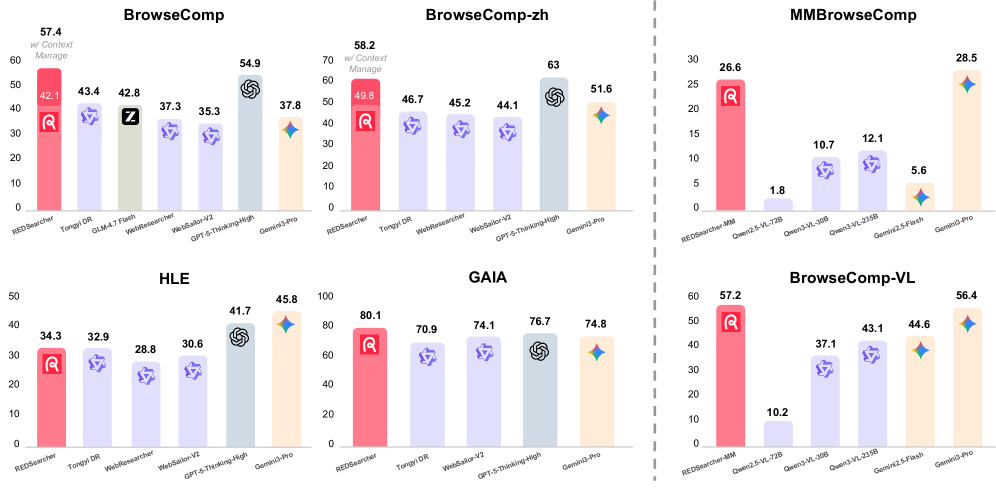
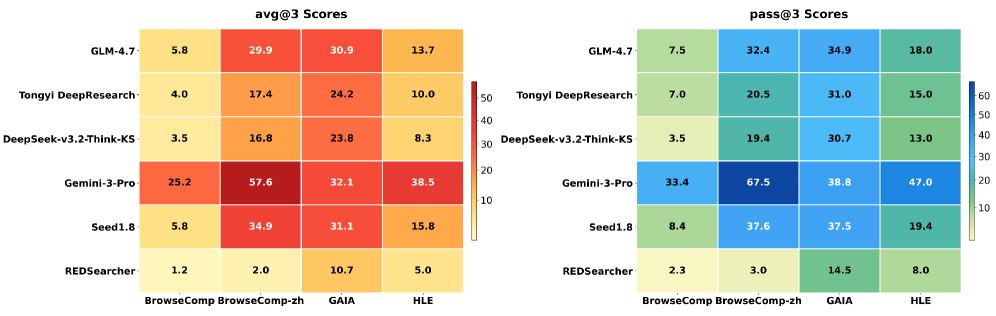
Итеративный процесс дообучения позволяет создавать агентов, способных формулировать эффективные поисковые запросы и синтезировать информацию из различных источников. В результате данного процесса, агенты демонстрируют общую оценку в 51.3 балла, что свидетельствует о значительном улучшении их способности к решению задач, требующих как поиска информации, так и её последующего анализа и обобщения. Данный показатель является результатом сочетания методов контролируемого обучения и обучения с подкреплением, направленных на оптимизацию стратегий интерактивного поиска.
Расширение Возможностей: Мультимодальный Поиск и За Его Пределами
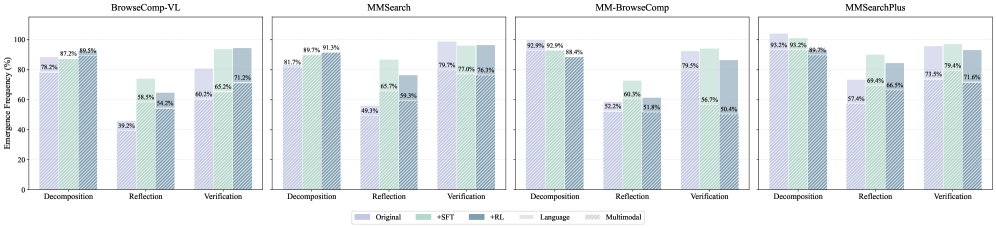
Архитектура REDSearcher изначально спроектирована для поддержки многомодального поиска, что позволяет агентам эффективно обрабатывать и интегрировать информацию, поступающую как в текстовом, так и в визуальном формате. Это означает, что система способна не просто находить релевантные документы по текстовым запросам, но и анализировать изображения, извлекать из них значимую информацию и использовать её в процессе рассуждений и принятия решений. Такой подход открывает новые возможности для решения сложных задач, требующих понимания информации, представленной в различных форматах, и позволяет создавать более интеллектуальные и адаптивные поисковые системы, способные к комплексному анализу и синтезу данных.
В основе REDSearcher лежит метод “Двойного Ограничения при Синтезе Задач”, позволяющий создавать сложные задачи, требующие последовательного планирования и объединения информации из различных источников. Этот подход не просто проверяет способность агента к рассуждениям, но и стимулирует разработку более надёжных и адаптивных стратегий поиска. В процессе генерации задач система ставит перед агентом ограничения, касающиеся как конечного результата, так и процесса достижения цели, что вынуждает его не просто находить информацию, но и критически оценивать её релевантность и достоверность, а также синтезировать новые знания на основе имеющихся данных. Такой метод позволяет значительно повысить эффективность поиска и обеспечить более глубокое понимание сложных концепций.
Данный подход позволил не только подтвердить способность агента к логическому мышлению, но и способствовал развитию более устойчивых и адаптивных стратегий поиска информации. В ходе тестирования REDSearcher продемонстрировал результат 80.1 по шкале GAIA, превзойдя показатель GPT-5-Thinking-high, равный 76.7. Это свидетельствует о том, что разработанная архитектура способствует формированию более эффективных алгоритмов, способных успешно справляться со сложными задачами, требующими глубокого анализа и синтеза информации из различных источников. Повышенная адаптивность позволяет агенту оптимизировать процесс поиска и выдавать более релевантные результаты, даже при изменяющихся условиях и неоднозначных запросах.
В процессе обучения с подкреплением REDSearcher продемонстрировал значительное повышение эффективности. Система улучшила свой результат в тесте BrowseComp на 2.7 балла, что свидетельствует о более успешной навигации и извлечении информации из веб-страниц. Более того, количество обращений к инструментам, необходимым для выполнения задач, сократилось на 10.4%. Это указывает на оптимизацию стратегии поиска и более рациональное использование ресурсов, позволяя REDSearcher достигать целей с меньшими вычислительными затратами и большей скоростью, подтверждая перспективность подхода к построению интеллектуальных агентов.
Рассматривая REDSearcher, становится очевидным, что стремление к масштабируемости и экономичности в обучении агентов поиска — это лишь попытка примирить несовместимое. Каждый архитектурный выбор, каждое решение об оптимизации — это, по сути, пророчество о будущих сбоях, о тех задачах, которые система окажется не в силах решить. Как писал Блез Паскаль: «Все великие дела на земле зиждятся на безумии». И в этом нет ничего удивительного: стремление к идеальному решению в сложной системе неизбежно приводит к компромиссам, которые, застывая во времени, формируют её ограничения. REDSearcher, как и любая другая сложная система, — это не структура, а компромисс, рожденный из необходимости оптимизировать долгосрочное поведение агента в условиях неопределенности.
Что впереди?
Представленная работа, словно карта, указывает на новые территории в исследовании агентов глубокого поиска. Однако, как известно, любая карта — это лишь упрощение реальности. Эффективность REDSearcher в синтезе сложных задач — это не триумф архитектуры, а скорее свидетельство того, что система способна отложить неизбежный рост технического долга на более поздний срок. Оптимизация в процессе и после обучения — необходимые процедуры, но они не избавляют от фундаментальной проблемы: долгосрочное поведение агента остаётся непрозрачным, словно сад, за которым не ухаживали.
Следующим шагом представляется не столько усложнение архитектуры, сколько развитие методов понимания внутренних процессов. Устойчивость системы — не в изоляции компонентов, а в их способности прощать ошибки друг друга. Ключевым вопросом остаётся: как научить агента не просто достигать цели, но и объяснять свой путь, предвидеть потенциальные сбои и адаптироваться к неожиданностям, словно опытный садовник, предвидящий капризы погоды?
В конечном счете, задача не в создании идеального инструмента, а в выращивании экосистемы, способной к саморазвитию и адаптации. Поиск — это не решение задачи, а непрерывный процесс, требующий постоянного внимания и заботы. И, возможно, истинный прогресс заключается не в увеличении масштаба, а в осознании границ наших возможностей.
Оригинал статьи: https://arxiv.org/pdf/2602.14234.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Молекулярный интеллект: проверка химического мышления
- Искусственный интеллект и закон: гармония неизбежна
- Топoлогические формы и тайны Вселенной
- Мир текстов без границ: Новые возможности многоязыковых представлений
- Стиль сквозь века: математика искусства
- Химическое мышление машин: новый подход к обучению
- Проверка свойств бесконечных семейств систем: новый подход
2026-02-18 01:12