Автор: Денис Аветисян
Ученые представляют ResearchGym — платформу, позволяющую проверить, насколько хорошо ИИ способен самостоятельно проводить научные исследования и делать открытия.
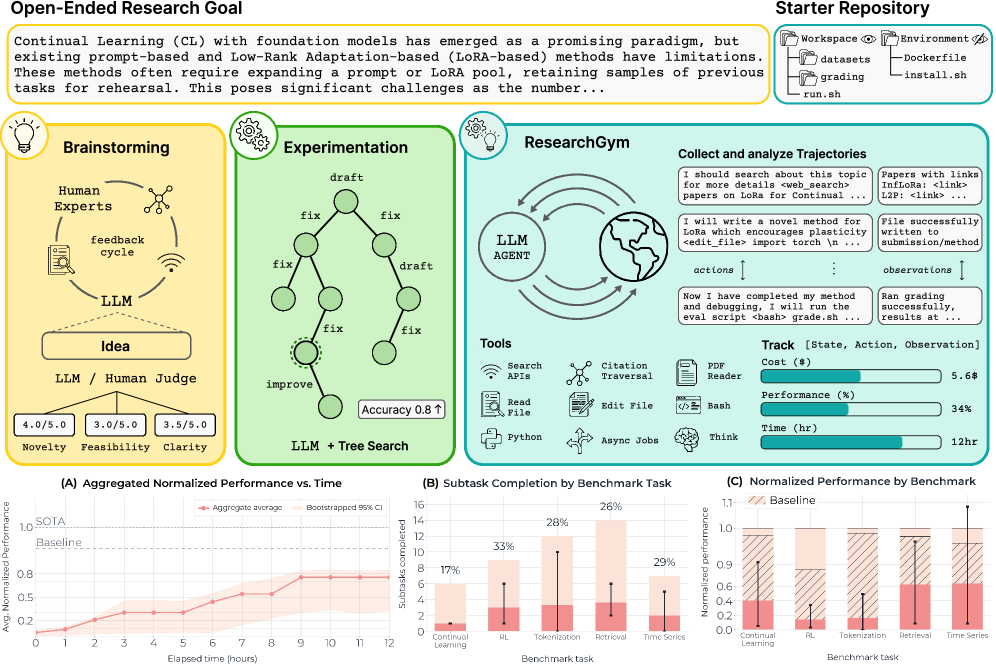
ResearchGym — это эталонный набор и среда исполнения для оценки агентов на основе больших языковых моделей в условиях замкнутого цикла исследований, автоматизированного экспериментирования и обеспечения воспроизводимости результатов.
Несмотря на впечатляющий прогресс в области больших языковых моделей (LLM), их способность к самостоятельному проведению научных исследований остается недостаточно изученной. В работе ‘ResearchGym: Evaluating Language Model Agents on Real-World AI Research’ представлена новая среда оценки ResearchGym, предназначенная для тестирования LLM-агентов в условиях замкнутого цикла научных исследований, включающего выдвижение гипотез, проведение экспериментов и анализ результатов. Результаты показывают, что даже передовые модели демонстрируют значительный разрыв между потенциалом и надежностью, успешно решая задачи лишь в единичных случаях, и часто сталкиваются с проблемами планирования и управления ресурсами. Возможно ли создание действительно автономных научных агентов, способных к последовательным открытиям, и какие архитектурные решения необходимы для преодоления выявленных ограничений?
Изучение Сложных Исследовательских Ландшафтов
Для создания действительно надежных агентов искусственного интеллекта необходимо оценивать их производительность в разнообразных, циклически замкнутых исследовательских задачах. Вместо одностороннего тестирования на статичных наборах данных, подобные задачи требуют от агента активного взаимодействия с окружающей средой, планирования действий и адаптации к меняющимся условиям. Именно такой подход позволяет выявить истинную способность агента к обобщению знаний и применению их в новых, ранее не встречавшихся ситуациях. Использование циклов взаимодействия — от действия к наблюдению и обратно — имитирует реальные сценарии и позволяет оценить не только эффективность алгоритмов, но и их устойчивость к ошибкам и неопределенности, что является критически важным для надежной работы в сложных системах.
Современные оценочные тесты для искусственного интеллекта зачастую не способны в полной мере выявить способность агентов к обобщению — то есть, к успешной работе в незнакомых ситуациях. Это связано с тем, что существующие бенчмарки, как правило, представляют собой упрощенные, изолированные задачи, не отражающие многогранность реального мира. Агент, преуспевающий в узкоспециализированном тесте, может оказаться неэффективным при столкновении со сложными, динамично меняющимися условиями, требующими адаптации и применения знаний в новом контексте. Таким образом, для разработки действительно интеллектуальных систем необходимо создавать более реалистичные и комплексные оценочные среды, способные всесторонне проверить способность агента к обобщению и переносу опыта.
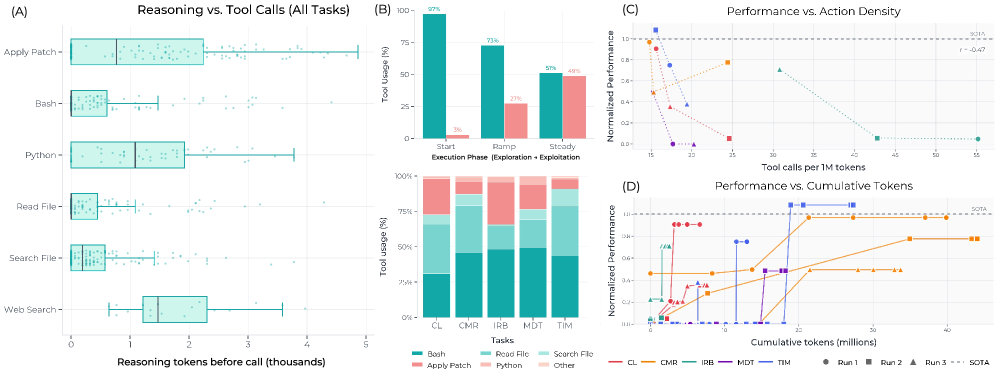
Улучшение Памяти и Опыта Агента
В основе нашей системы обучения агента лежит надежный механизм “ReplayBuffer” — буфер воспроизведения опыта. Этот компонент предназначен для хранения кортежей опыта, состоящих из состояний среды, действий агента, полученных наград и следующих состояний. Реализация включает в себя возможность масштабирования для обработки больших объемов данных, необходимых для обучения сложных агентов. Сохраненные данные используются для формирования обучающих пакетов, которые многократно передаются в алгоритм обучения с подкреплением, обеспечивая эффективное использование данных и стабильность процесса обучения. Буфер поддерживает различные стратегии выборки данных, включая случайную выборку и приоритезированную выборку, для оптимизации процесса обучения.
Для повышения эффективности обучения агент используется механизм ‘PriorityReplay’, который позволяет фокусироваться на наиболее значимых эпизодах взаимодействия со средой. Вместо случайной выборки эпизодов из буфера опыта, ‘PriorityReplay’ назначает каждому эпизоду приоритет, основанный на величине ошибки TD (Temporal Difference). Эпизоды с большей ошибкой TD, указывающие на неожиданные или сложные ситуации, получают более высокий приоритет и чаще используются для обновления параметров агента. Это позволяет агенту быстрее учиться на опыте, который предоставляет наибольшую информационную ценность, и, как следствие, улучшает общую производительность и скорость сходимости обучения.
Для расширения обучающей выборки и повышения устойчивости агента к разнообразным ситуациям, в систему включена генерация синтетических данных с использованием диффузионной модели (Diffusion Model). Данный подход позволяет создавать новые сценарии обучения, дополняя реальные данные, собранные в процессе взаимодействия агента с окружением. Диффузионная модель обучается на существующих данных, а затем используется для генерации новых, реалистичных примеров, что способствует улучшению обобщающей способности агента и его способности адаптироваться к непредсказуемым условиям. Сгенерированные данные интегрируются в процесс обучения наряду с реальными данными, поступающими из ReplayBuffer, обеспечивая более полное и разнообразное представление об окружающей среде.
Повышение Надежности посредством Диверсификации
Для снижения влияния зашумленных или ограниченных данных, в нашей системе применяются методы оценки неопределенности (Uncertainty Estimation). Эти методы позволяют количественно оценить уверенность модели в своих предсказаниях, предоставляя информацию о вероятности ошибки. Оценка неопределенности может быть реализована различными способами, включая байесовские нейронные сети, ансамбли моделей и методы, основанные на вычислении дисперсии предсказаний. Полученные оценки используются для фильтрации ненадежных предсказаний и повышения общей надежности системы, особенно в условиях, когда входные данные неполны или содержат ошибки.
Для повышения устойчивости и обобщающей способности агента внедряется регуляризация разнообразия (Diversity Regularization). Данный метод стимулирует исследование более широкого спектра стратегий действий, предотвращая переобучение на конкретном наборе данных или задачах. Регуляризация достигается путем добавления к функции потерь компонента, поощряющего разнообразие в векторах действий или политиках агента. Это заставляет агента избегать чрезмерной специализации и развивать более гибкие и адаптивные стратегии, что особенно важно при работе с ограниченными или зашумленными данными и при обобщении на новые, неизвестные задачи.
Для обеспечения эффективной обобщающей способности агентов при решении различных исследовательских задач, критически важным является преодоление ограничений, связанных с зашумленными или недостаточными данными. Способность к обобщению напрямую зависит от того, насколько хорошо агент способен адаптироваться к новым, ранее не встречавшимся сценариям. Применение техник оценки неопределенности и регуляризации разнообразия позволяет агенту не только избегать переобучения на конкретном наборе данных, но и формировать более устойчивые стратегии, что существенно повышает его производительность и надежность при переходе к новым задачам и исследовательским направлениям.
Демонстрация Обобщения и Адаптивности
Разработанная система демонстрирует выдающиеся возможности в области кросс-модального поиска и токенизации материалов, что свидетельствует о ее способности успешно решать многогранные задачи. Кросс-модальный поиск позволяет системе эффективно сопоставлять и извлекать информацию из различных типов данных — изображений, текста, звука и других — объединяя их для более глубокого понимания. Токенизация материалов, в свою очередь, представляет собой процесс разбиения сложных объектов или данных на более простые и управляемые компоненты, что значительно упрощает анализ и обработку информации. Сочетание этих двух ключевых функций обеспечивает высокую адаптивность системы к различным типам входных данных и позволяет ей эффективно справляться с комплексными задачами, требующими интеграции информации из разных источников.
Исследование продемонстрировало успешное применение разработанного подхода к задаче объяснения временных рядов. В симулированной среде Hopper-v2 агент достиг среднего вознаграждения в 2915.27, что значительно превосходит показатели базовой модели на 85.9%. Данный результат свидетельствует о высокой эффективности предложенного алгоритма в динамически меняющихся условиях и его способности к принятию обоснованных решений на основе анализа временных данных. Полученные цифры подтверждают перспективность использования данной технологии в широком спектре задач, связанных с прогнозированием и оптимизацией процессов.
Агент продемонстрировал впечатляющую способность к адаптации к новым средам, что свидетельствует о высокой степени обобщения полученных знаний. В ходе экспериментов по доменной адаптации, система успешно осваивала принципиально новые задачи и условия, демонстрируя быстрый переход от обучения к эффективному функционированию. Такая гибкость позволяет агенту не просто запоминать конкретные сценарии, а извлекать общие закономерности и применять их в незнакомых ситуациях, значительно превосходя по эффективности системы, требующие переобучения для каждого нового окружения. Данная способность к быстрой адаптации является ключевым фактором для создания действительно универсальных и автономных интеллектуальных систем.
К Непрерывному Обучению и Улучшенным Агентам
Интеграция представленных методов позволяет агенту достичь непрерывного обучения, избегая явления «катастрофического забывания». В отличие от традиционных систем искусственного интеллекта, склонных к потере ранее полученных знаний при освоении новых, данная архитектура обеспечивает сохранение и накопление опыта. Это достигается благодаря механизмам, позволяющим агенту эффективно интегрировать новую информацию в существующую базу знаний, не переписывая при этом старые данные. По сути, система способна адаптироваться и улучшать свои навыки с течением времени, подобно человеческому мозгу, что открывает возможности для решения сложных и долгосрочных задач, требующих постоянного обучения и адаптации к изменяющимся условиям. Такой подход особенно важен в контексте научных исследований, где накопление знаний и способность к обобщению являются ключевыми факторами успеха.
Стратегическое формирование вознаграждений играет ключевую роль в оптимизации процесса обучения агентов, особенно при решении сложных исследовательских задач. Вместо того чтобы полагаться исключительно на редкие и отсроченные сигналы вознаграждения, подход предполагает постепенное и целенаправленное формирование желаемого поведения посредством промежуточных, более частых наград. Это позволяет агенту эффективно исследовать пространство решений, избегая застревания в локальных оптимумах и ускоряя сходимость к оптимальной стратегии. Этот метод, подобно искусству скульптора, позволяет постепенно «вылепить» нужное поведение, обеспечивая стабильное улучшение производительности и позволяя агенту успешно осваивать задачи, требующие длительного планирования и сложных взаимодействий с окружающей средой. В результате, агенты демонстрируют повышенную эффективность и надежность в решении исследовательских задач, что открывает новые возможности для автоматизации научных открытий.
В основе автоматизированных научных открытий лежит концепция использования LLM-агента в качестве центрального управляющего механизма. Этот агент, обученный на обширных массивах научных данных, способен не только формулировать гипотезы и планировать эксперименты, но и самостоятельно анализировать полученные результаты, корректируя дальнейший ход исследований. Такой подход позволяет значительно ускорить процесс научных открытий, автоматизируя рутинные задачи и высвобождая ресурсы для решения более сложных проблем. Агент способен интегрировать информацию из различных источников, выявлять закономерности, которые могут быть упущены человеком, и предлагать новые направления для исследований, что открывает перспективы для прорывных открытий в различных областях науки. Использование LLM-агента, таким образом, представляет собой качественно новый этап в автоматизации научного поиска и анализа.
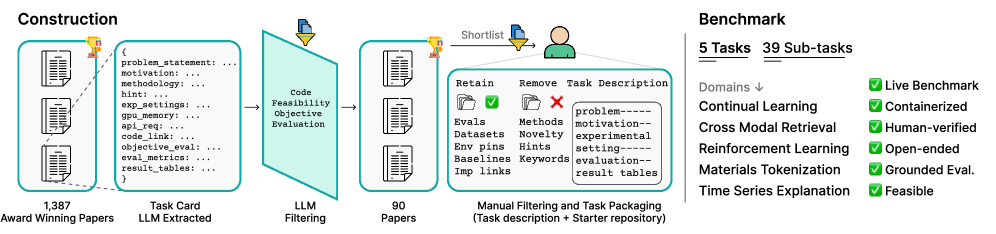
Исследование, представленное в статье, подчеркивает сложность автоматизации полного цикла научных исследований. Авторы демонстрируют, что создание агентов, способных самостоятельно проводить эксперименты и анализировать результаты, требует учета множества факторов и компромиссов. Это созвучно мысли Блеза Паскаля: “Все великие вещи начинаются с малого и кажутся невозможными, пока они не сделаны.” Действительно, как показывает представленная работа над ResearchGym, путь к автоматизированному научному открытию требует постепенного, итеративного подхода, где каждая упрощающая оптимизация имеет свою цену, а каждая изощрённая функция — свои риски. Успех в этой области зависит от способности находить баланс между эффективностью и надежностью, простотой и полнотой анализа.
Что дальше?
Представленная работа, демонстрируя возможности автоматизации научного поиска, неизбежно поднимает вопрос о границах этой автоматизации. Как и в случае с попыткой пересадки сердца, не понимая всей циркуляторной системы, простое увеличение вычислительной мощности или сложности агента не гарантирует прорывных открытий. Напротив, существует риск усугубления существующих предубеждений и неспособности к истинному новому мышлению. Настоящая сложность заключается не в скорости экспериментов, а в способности агента формулировать правильные вопросы.
Очевидным направлением дальнейших исследований является разработка более надежных метрик оценки. Текущие показатели часто фокусируются на количественных результатах, упуская из виду качественные аспекты, такие как элегантность решения или его соответствие фундаментальным принципам. Крайне важно понимать, что эффективная система — это не просто набор работающих компонентов, а гармоничный организм, где структура определяет поведение. Иначе мы рискуем создать сложную машину, которая будет производить шум, а не знания.
В конечном счете, успех автоматизированного научного поиска будет зависеть не от создания всемогущего агента, а от разработки инструментов, которые расширят возможности человеческого интеллекта. Агент должен быть не заменителем ученого, а его партнером, способным обрабатывать огромные объемы данных и выявлять скрытые закономерности, которые могут ускорить процесс открытия. Истинная революция произойдет тогда, когда машина сможет не просто находить ответы, но и формулировать вопросы, которые мы сами не могли бы задать.
Оригинал статьи: https://arxiv.org/pdf/2602.15112.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовые вычисления для молекул: оптимизация ресурсов
- Молекулярный интеллект: проверка химического мышления
- Восстановление рейтингов: Машинное обучение для неполных данных
- Проверка свойств бесконечных семейств систем: новый подход
- Видео-рассуждения: готовы ли модели выйти за рамки лаборатории?
- Видеоредактирование по запросу: Новый подход к точности и связности
- Топoлогические формы и тайны Вселенной
2026-02-18 07:54