Автор: Денис Аветисян
Новое исследование показывает, что модели, обрабатывающие изображения и текст, уязвимы к визуальным манипуляциям, что открывает возможности для управления их поведением.
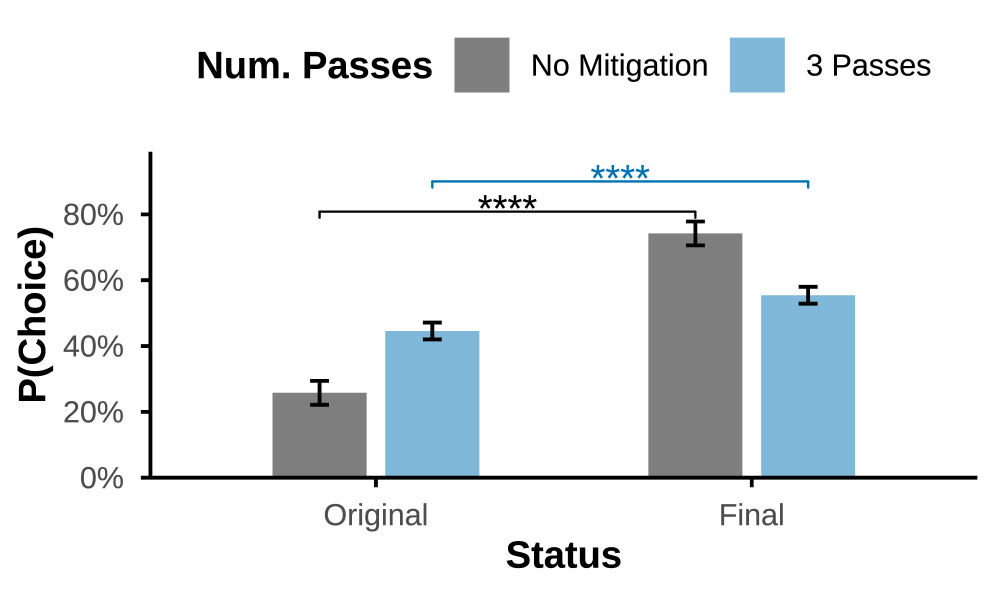
Исследователи выявили и систематизировали визуальные особенности, определяющие решения моделей «зрение-язык», и продемонстрировали возможность влияния на них с помощью оптимизированных визуальных подсказок.
В условиях экспоненциального роста визуального контента в сети, все больше решений принимается агентами, использующими модели «зрение-язык». Исследование ‘Visual Persuasion: What Influences Decisions of Vision-Language Models?’ посвящено выявлению факторов, определяющих визуальные предпочтения этих моделей. Показано, что систематическое изменение входных изображений позволяет выявить и использовать скрытые визуальные чувствительности, значительно влияющие на принимаемые решения. Не открывает ли это путь к пониманию и аудиту потенциальных уязвимостей в системах искусственного интеллекта, основанных на обработке изображений?
Разоблачение Скрытых Уязвимостей в Визуально-Языковых Моделях
Визуально-языковые модели (ВЯМ) демонстрируют неожиданную чувствительность к незначительным изменениям в изображениях, что вызывает серьезные опасения относительно их надежности и устойчивости. Исследования показывают, что даже почти незаметные для человеческого глаза модификации способны существенно повлиять на способность модели правильно интерпретировать визуальную информацию и, как следствие, на точность ее ответов. Такая восприимчивость к незначительным искажениям ставит под вопрос возможность безопасного применения ВЯМ в критически важных областях, где требуется высокая степень достоверности, таких как автономное вождение или медицинская диагностика. Необходимость повышения устойчивости ВЯМ к визуальным помехам становится очевидной, поскольку даже небольшие изменения могут приводить к непредсказуемым и потенциально опасным результатам.
Первоначальные оценки устойчивости языково-визуальных моделей (ЯВМ) часто использовали специально разработанные, так называемые «атакующие» изображения, призванные максимально исказить результат. Однако, эти изображения, хотя и продемонстрировали наличие уязвимостей, не отражают те типы искажений, с которыми модели сталкиваются в реальных условиях. Естественные дефекты изображений, такие как незначительные изменения освещения, размытость или небольшие помехи, оказываются более распространёнными и могут существенно влиять на производительность ЯВМ. Исследования показывают, что даже небольшие, визуально незаметные изменения в изображении способны приводить к значительным ошибкам в распознавании и классификации, что подчеркивает необходимость разработки более устойчивых и реалистичных методов оценки безопасности этих моделей.
Изучение визуальной чувствительности моделей, объединяющих зрение и язык, имеет первостепенное значение для их надежного применения в реальных условиях. Исследования показали, что даже незначительные изменения в изображениях могут существенно влиять на принимаемые этими моделями решения. В ходе проведенной работы были количественно оценены эти чувствительности: оптимизированные редактирования изображений приводили к сдвигу вероятностей выбора ответов на величину от 0.20 до 0.40. Данный результат подчеркивает необходимость разработки более устойчивых моделей, способных корректно функционировать в условиях вариативного качества изображений и неоднозначного контекста, что критически важно для широкого спектра практических применений, включая автономные системы и анализ изображений в медицине.
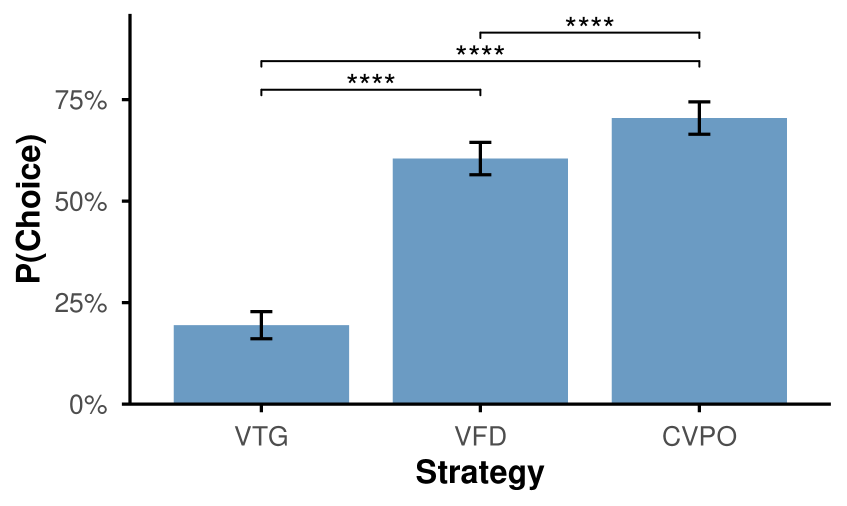
Систематическое Исследование с Использованием Естественной Редактировки Изображений
Для создания разнообразного набора реалистичных визуальных запросов был использован метод ‘Zero-Shot Editing’, предполагающий модификацию изображений без предварительного обучения модели. Данный подход позволяет вносить изменения в исходные изображения, используя существующие инструменты редактирования, и получать новые визуальные стимулы, не требуя дополнительной тренировки алгоритма. Это обеспечивает гибкость и возможность генерации широкого спектра визуальных данных для исследования чувствительности и реакций визуально-языковых моделей (VLM) на различные изменения в изображении.
Использование методики редактирования изображений без предварительного обучения позволяет исследовать чувствительность визуальных языковых моделей (ВЯМ) к незначительным изменениям в содержании и стиле изображения. В частности, данный подход позволяет оценить, как даже небольшие модификации, такие как изменение освещения, добавление объектов или корректировка цветовой гаммы, влияют на выходные данные ВЯМ и их интерпретацию визуальной информации. Анализ этих реакций дает возможность понять, какие аспекты изображения являются наиболее значимыми для ВЯМ и как они формируют свои ответы, что критически важно для разработки более надежных и точных систем.
Для точной настройки визуальных подсказок и максимизации изменений в ответах визуально-языковых моделей (VLM) применялись методы оптимизации, включая ‘TextGrad’ и ‘Feedback Descent’. В ходе сравнительных тестов разработанный нами метод Competition-Based Visual Prompt Optimization (CVPO) демонстрировал стабильно более высокие результаты, превосходя алгоритмы VTD и VFD в прямых сопоставлениях. CVPO позволяет эффективно находить визуальные изменения, вызывающие наиболее заметные изменения в выходных данных VLM, что подтверждается количественными метриками и качественным анализом результатов.
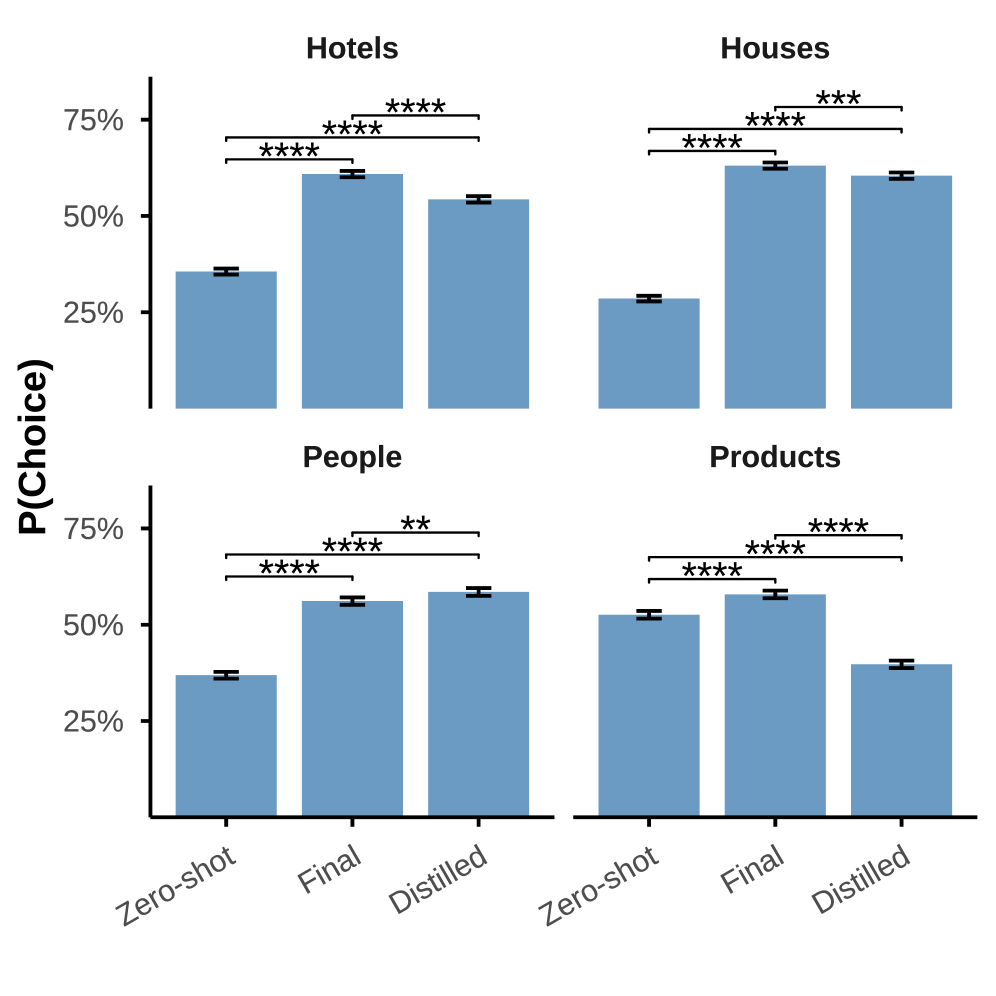
Деконструкция Процесса Принятия Решений ВЯМ с Помощью Автоматизированного Конвейера Интерпретируемости
Автоматизированный конвейер интерпретируемости, разработанный нами, позволяет автоматически выявлять визуальные факторы, определяющие ответы визуальных языковых моделей (VLM). В основе работы конвейера лежит анализ сходства, использующий векторные представления изображений, полученные с помощью модели CLIP (Contrastive Language-Image Pre-training). CLIP Embeddings, представляющие собой многомерные векторы, кодирующие семантическое содержание изображений, используются для количественной оценки визуального сходства между входными изображениями и различными их модификациями. Этот подход позволяет определить, какие конкретно визуальные элементы оказывают наибольшее влияние на выходные данные VLM, обеспечивая детализированный анализ процесса принятия решений моделью.
Для оценки соответствия отредактированных изображений исходным и обеспечения перцептивной релевантности использовались метрики структурного сходства (SSIM) и LPIPS (Learned Perceptual Image Patch Similarity). SSIM измеряет восприятие изменений в структуре изображения, сравнивая яркость, контрастность и структуру. LPIPS, в свою очередь, использует глубокие нейронные сети для оценки перцептивного сходства, что позволяет более точно отражать человеческое восприятие различий в изображениях. Обе метрики позволяют количественно оценить степень изменений, внесенных в изображение, и гарантировать, что отредактированные версии остаются визуально сопоставимыми с исходными, что критически важно для анализа влияния визуальных факторов на ответы визуальных языковых моделей.
Автоматизированный конвейер интерпретируемости выявил, что даже незначительные визуальные изменения в исходном изображении могут приводить к существенным изменениям в ответах визуальных языковых моделей (VLM). Это указывает на недостаточную устойчивость процессов извлечения признаков в данных моделях. Наблюдаемая чувствительность к мелким модификациям свидетельствует о том, что VLM не всегда способны выделять семантически значимые визуальные компоненты, что потенциально приводит к непредсказуемым и непоследовательным результатам при незначительных вариациях входных данных.
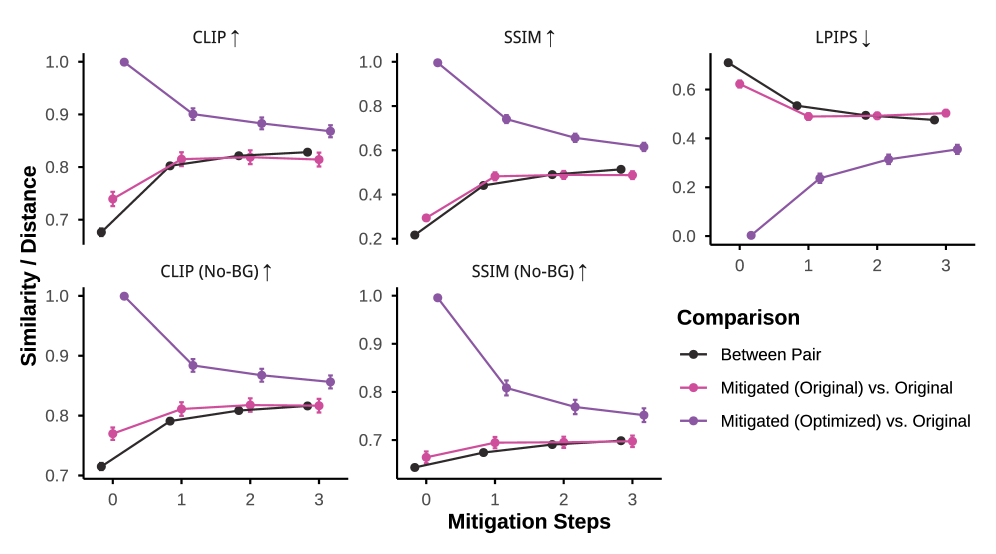
Повышение Надежности и Беспристрастности Путем Нормализации Изображений
Исследования показали, что применение нормализации изображений — выравнивания контекстуальных признаков — значительно повышает устойчивость визуально-языковых моделей (VLM) к незначительным изменениям в изображениях. Данный подход позволяет моделям сохранять стабильность и точность даже при небольших искажениях, шумах или вариациях освещения. Эффективность нормализации изображений заключается в снижении влияния поверхностных характеристик изображения на процесс принятия решений моделью, что позволяет ей сосредоточиться на более существенных и информативных признаках. В результате, VLM становятся менее восприимчивы к «обману» со стороны визуальных артефактов и демонстрируют повышенную надежность в различных условиях эксплуатации.
Для повышения эффективности визуальных изменений, направленных на повышение устойчивости и справедливости больших визуальных моделей (VLM), была применена техника оптимизации визуальных подсказок, основанная на соревновательном подходе. В её основе лежит модель Брэдли-Терри, позволяющая эффективно отбирать наиболее значимые редактирования изображений. Данный метод предполагает сопоставление различных вариантов изменений, оценивая их влияние на выходные данные модели, и отбор тех, которые демонстрируют наибольшую эффективность в снижении визуальной уязвимости и повышении надежности VLM. Использование модели Брэдли-Терри позволило автоматизировать процесс выбора оптимальных визуальных изменений, существенно снижая вычислительные затраты и обеспечивая более точный и эффективный подход к нормализации изображений.
Исследование демонстрирует значительный потенциал предложенного подхода к повышению надежности и справедливости визуальных языковых моделей (VLM). Нормализация изображений, направленная на снижение перцептивных различий между ними, успешно смягчает визуальные уязвимости, что особенно важно в приложениях, чувствительных к предвзятости. Уменьшение влияния тонких визуальных вариаций позволяет создавать более устойчивые и надежные VLM, способные к более объективной обработке информации. Это открывает перспективы для использования таких моделей в критически важных областях, где точность и беспристрастность являются первостепенными требованиями, например, в системах медицинской диагностики или при оценке справедливости алгоритмов.
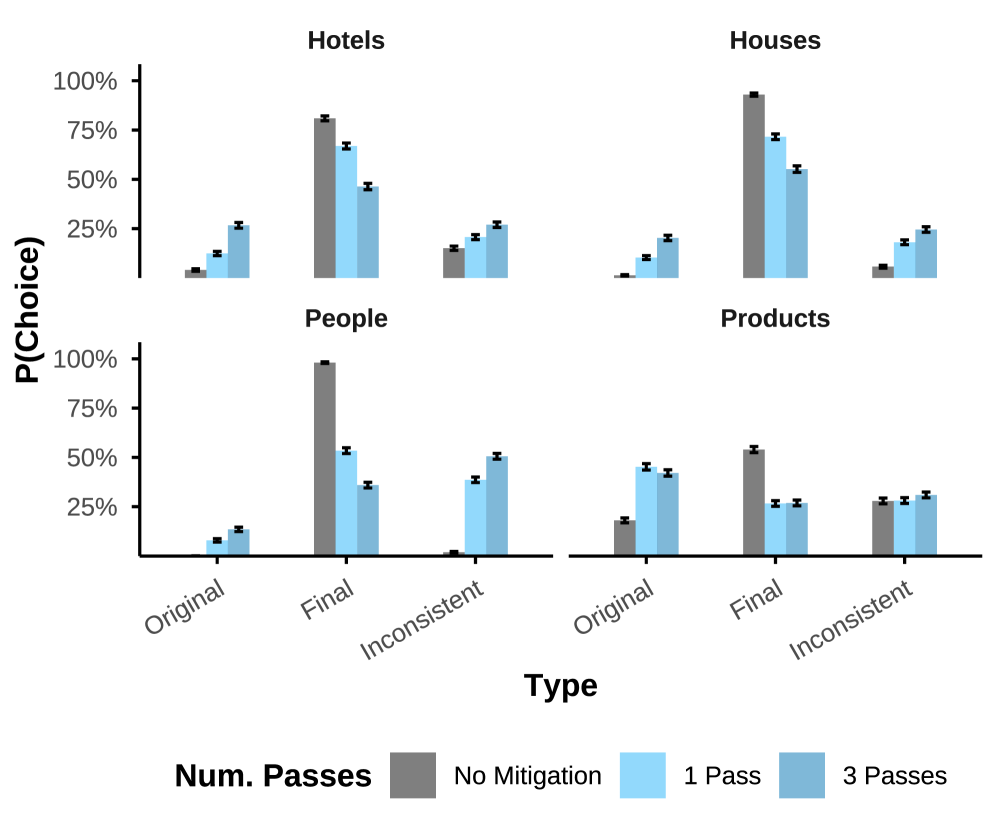
Исследование показывает, что визуальные языковые модели не являются абсолютно объективными, а подвержены влиянию определённых визуальных паттернов. Как отмечает Фэй-Фэй Ли: «Искусственный интеллект должен служить людям, а не наоборот». Эта цитата особенно актуальна в контексте данной работы, поскольку выявление и использование визуальных чувствительностей моделей может привести к непредсказуемым последствиям в агентных системах. Понимание этих закономерностей, как подчеркивается в исследовании, необходимо для обеспечения надёжности и безопасности ИИ, а также для разработки методов интерпретации принимаемых моделью решений. Работа демонстрирует, что оптимизация визуальных подсказок позволяет влиять на выбор модели, что ставит вопросы о её истинной рациональности и объективности.
Куда ведут визуальные иллюзии?
Исследование закономерностей, управляющих решениями мультимодальных моделей, неизбежно наталкивается на вопрос о границах видимого. Обнаруженные визуальные чувствительности — это лишь верхушка айсберга. Что остаётся за пределами воспринимаемого спектра, какие тонкие искажения, незаметные для человека, способны радикально изменить вектор принятия решений? Важно понимать, что систематическое выявление этих «слепых зон» — не просто академический интерес, а необходимость для создания действительно надежных автономных систем.
Представляется, что дальнейшее развитие исследований должно быть направлено на изучение не только того, что влияет на модели, но и как эти влияния взаимодействуют. Необходимо перейти от простого обнаружения чувствительностей к построению моделей, способных предсказывать их проявление в различных контекстах. Кроме того, критически важно исследовать устойчивость этих чувствительностей к шумам и небольшим изменениям входных данных — насколько легко манипулировать системой, используя незначительные визуальные артефакты?
В конечном счете, понимание визуальных предубеждений моделей — это, по сути, отражение наших собственных когнитивных искажений, воплощенных в алгоритмах. Поэтому, возможно, самым сложным вызовом станет не столько создание более «умных» моделей, сколько осознание границ нашего собственного восприятия и проектирование систем, способных критически оценивать и компенсировать эти ограничения.
Оригинал статьи: https://arxiv.org/pdf/2602.15278.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект и квантовая физика: кто кого?
- Автоматическая оптимизация вычислений: новый подход к библиотекам математических функций
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Учимся с интересом: как создать AI-репетитора, вдохновлённого лучшими учителями
- Языковые модели и границы возможного: что делает язык человеческим?
- Игры без модели: новый подход к управлению в условиях неопределенности
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Ожившие Пиксели: Создание Реалистичных Видео с Сохранением Личности
- Гендерные стереотипы в найме: что скрывают языковые модели?
2026-02-18 09:25