Автор: Денис Аветисян
Исследователи предлагают метод COMPOT, позволяющий значительно уменьшить размер моделей-трансформеров без существенной потери точности.
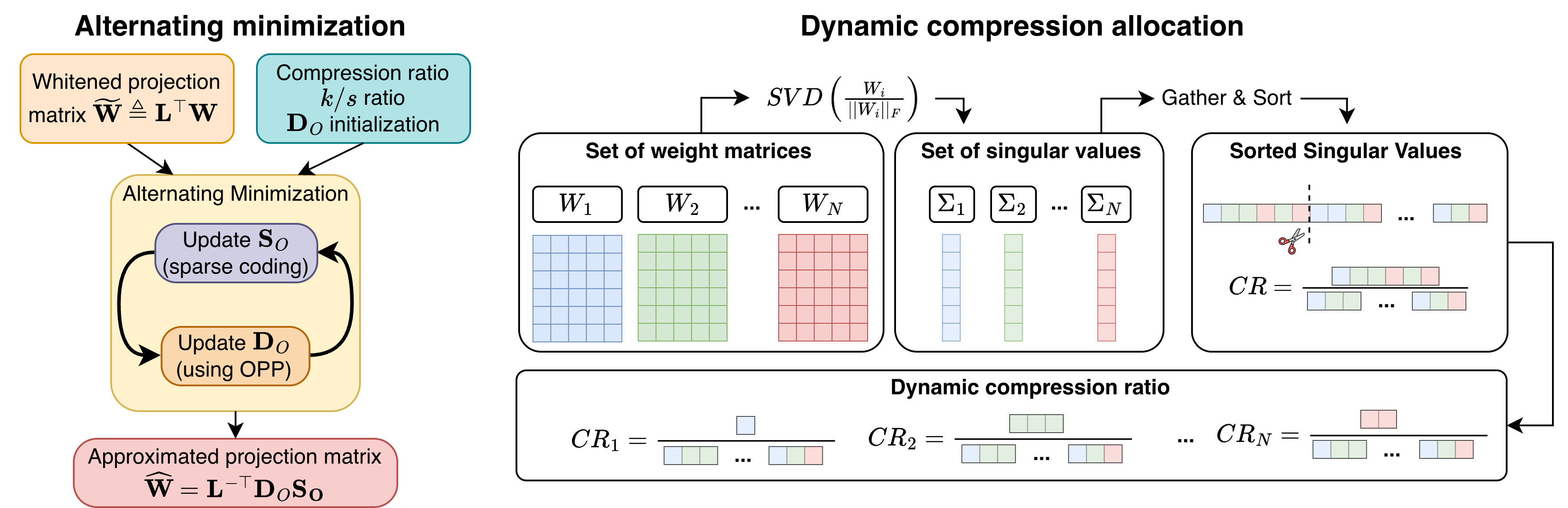
Предложенная схема COMPOT использует оптимизированную матричную прокрустову ортогонализацию для эффективного сжатия и повышения калибровки моделей.
Пост-обучающая компрессия трансформеров, несмотря на широкое применение сингулярного разложения, часто приводит к снижению точности при умеренном сжатии. В данной работе представлена методика COMPOT (Calibration-Optimized Matrix Procrustes Orthogonalization for Transformers Compression) — фреймворк, не требующий обучения, для компрессии трансформеров, использующий калибровку для оценки разреженной факторизации весов. COMPOT обеспечивает быстрые обновления за счет ортогональных словарей и аналитического разреженного кодирования, превосходя по качеству и степени сжатия существующие подходы. Сможет ли предложенная стратегия динамического распределения степени сжатия по слоям еще больше повысить эффективность компрессии трансформеров и открыть новые возможности для их развертывания?
Масштабируемость Трансформеров: Преодолевая Квадратичную Сложность
Трансформеры, несмотря на свою впечатляющую способность к обработке информации, сталкиваются с серьезными ограничениями при масштабировании. Основная проблема заключается в квадратичной сложности механизма внимания — O(n^2), где n — длина последовательности. Это означает, что вычислительные затраты и потребность в памяти растут пропорционально квадрату длины обрабатываемого текста. В результате, обработка длинных последовательностей становится крайне ресурсоемкой и практически невозможной на стандартном оборудовании. Таким образом, квадратичная сложность внимания является фундаментальным препятствием для применения трансформеров в задачах, требующих анализа больших объемов данных, таких как обработка длинных документов, видео или геномных последовательностей.
Возникающие трудности с масштабированием трансформеров напрямую ограничивают их применение к задачам, требующим обработки длинных последовательностей данных, таким как анализ объемных текстов, расшифровка продолжительных аудиозаписей или обработка видеопотоков. Причина кроется в квадратичной сложности механизма внимания — с увеличением длины последовательности вычислительные затраты растут экспоненциально. Это порождает потребность в эффективных методах сжатия моделей, позволяющих уменьшить их размер и вычислительную нагрузку без существенной потери в производительности. Разработка подобных техник является ключевой задачей, поскольку существующие подходы часто сопряжены либо со значительным снижением точности, либо с необходимостью дорогостоящей переподготовки модели, что создает серьезные препятствия для практического внедрения трансформеров в приложениях, требующих обработки больших объемов информации.
Существующие методы сжатия трансформерных моделей, направленные на уменьшение вычислительной нагрузки, часто сталкиваются с серьезными компромиссами. В большинстве случаев, значительное уменьшение размера модели приводит к заметному снижению её производительности, что делает сжатую версию менее эффективной для решения исходной задачи. Альтернативой является трудоемкий процесс переобучения, требующий обширных вычислительных ресурсов и больших объемов размеченных данных для восстановления утраченной точности. Такая необходимость в масштабном переобучении создает ощутимое практическое препятствие для широкого применения сжатых моделей, особенно в условиях ограниченных ресурсов или при необходимости быстрой адаптации к новым данным. Таким образом, поиск эффективных методов сжатия, не требующих существенной потери качества или длительного переобучения, остается актуальной задачей в области искусственного интеллекта.
Низкоранговое Разложение: Основа для Сжатия
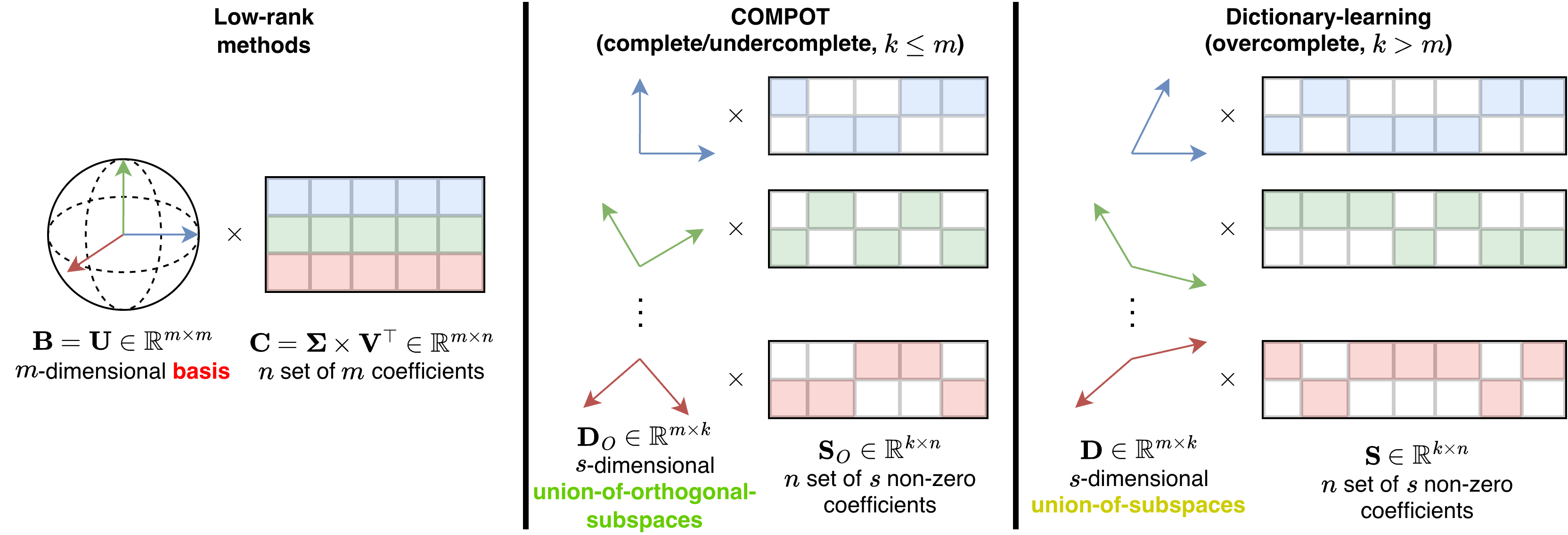
Метод понижения размерности, известный как разложение на матрицы низкого ранга, заключается в аппроксимации исходных матриц представлениями более низкого ранга. Это достигается путем выделения наиболее значимых компонентов данных, игнорируя менее важные. Математически, если исходная матрица A имеет размерность m \times n и ранг r, то разложение низкого ранга стремится представить A как произведение двух матриц меньшего размера, например, U \times V, где U имеет размерность m \times k, а V — k \times n, и k < r. Такой подход позволяет существенно сократить объем хранимых параметров модели и вычислительные затраты, сохраняя при этом значительную часть исходной информации.
Методы сингулярного разложения (SVD) и его варианты, такие как SVD-LLM и Dobi-SVD, позволяют эффективно снизить вычислительные затраты и объем памяти, необходимые для работы с матрицами. В основе этих методов лежит представление исходной матрицы в виде произведения двух матриц меньшего размера, сохраняя при этом наиболее значимую информацию. SVD выполняет разложение матрицы на три компоненты: U, Σ и V^T, где Σ содержит сингулярные значения, определяющие вклад каждого компонента в исходную матрицу. Отбрасывая сингулярные значения, близкие к нулю, можно получить приближение исходной матрицы с существенно меньшим количеством параметров, минимизируя при этом потери информации. SVD-LLM и Dobi-SVD являются оптимизированными вариантами SVD, адаптированными для работы с большими языковыми моделями и предлагающими улучшения в скорости и эффективности вычислений.
Непосредственное применение методов понижения размерности, таких как сингулярное разложение (SVD), требует тщательной калибровки для достижения оптимальной производительности. Неоптимизированное применение этих техник к конкретным архитектурам может приводить к снижению точности и эффективности модели. Экспериментальные данные демонстрируют, что более современные подходы, такие как COMPOT, зачастую превосходят SVD и его варианты по ключевым показателям, указывая на необходимость использования специализированных алгоритмов для достижения наилучших результатов в задачах сжатия и понижения размерности.
COMPOT: Калиброванное Ортогональное Обучение Словарю для Трансформеров
Метод COMPOT представляет собой фреймворк сжатия Transformer-моделей, не требующий этапа обучения. Он использует откалибренное ортогональное обучение словаря (Orthogonal Dictionary Learning) для создания разреженных представлений весов модели, что позволяет эффективно снизить размер модели при сохранении ключевой информации. Вместе с этим применяется глобальное распределение (Global Allocation) бюджета сжатия между слоями на основе сингулярных значений, что позволяет максимизировать сохранение производительности. В отличие от традиционных методов, COMPOT не требует дополнительной тренировки модели после сжатия, что значительно упрощает процесс и снижает вычислительные затраты.
В основе COMPOT лежит метод обучения ортогональному словарю (Orthogonal Dictionary Learning), который позволяет создавать разреженные представления весов модели. Этот подход повышает эффективность сжатия за счет уменьшения количества параметров, сохраняя при этом ключевую информацию. В отличие от традиционных методов, использующих, например, сингулярное разложение (SVD), обучение ортогональному словарю направлено на поиск набора базисных векторов, которые оптимально представляют исходные веса модели в разреженном виде. Разреженность достигается за счет того, что большинство коэффициентов, соответствующих этим базисным векторам, равны нулю или близки к нулю. Это позволяет значительно сократить объем памяти, необходимый для хранения модели, без существенной потери производительности. Процесс обучения направлен на минимизацию ошибки реконструкции исходных весов из разреженного представления, обеспечивая сохранение наиболее важных параметров модели.
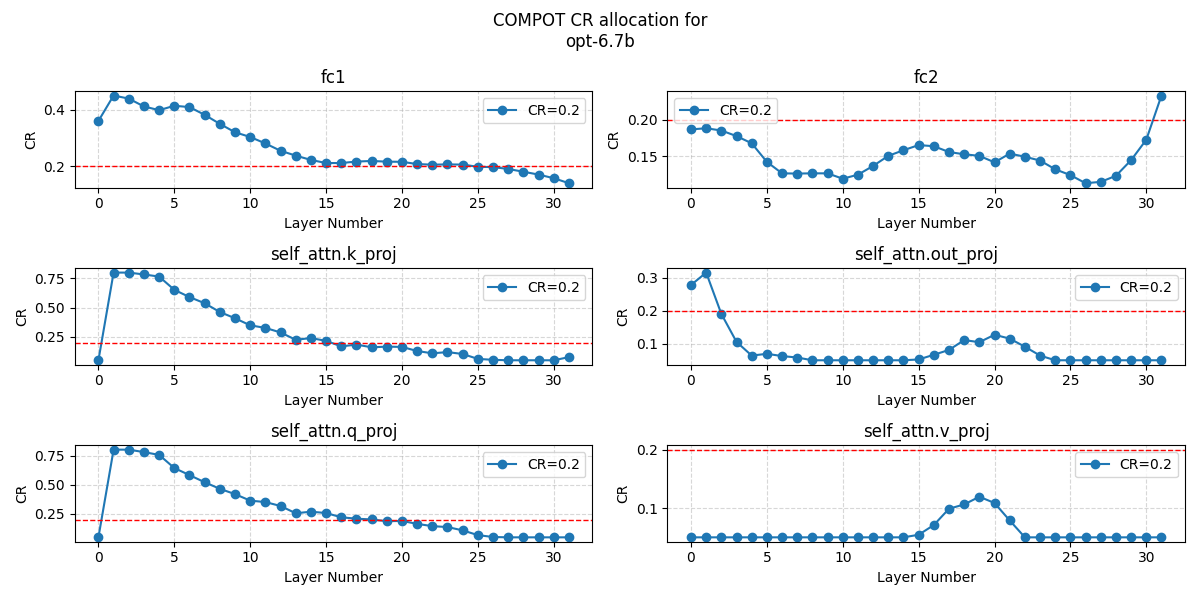
Глобальное распределение бюджета сжатия в COMPOT осуществляется на основе анализа сингулярных значений весов каждого слоя Transformer. Данный подход позволяет динамически адаптировать степень сжатия для различных слоев, выделяя больший бюджет слоям, содержащим более значимую информацию, что определяется величиной их сингулярных значений. В отличие от равномерного сжатия, данная стратегия максимизирует сохранение производительности модели, поскольку слои с высокой информативностью подвергаются меньшему сжатию, а менее важные слои могут быть сжаты сильнее без существенного влияния на общую точность. Использование сингулярных значений в качестве метрики важности позволяет COMPOT эффективно распределять ограниченный бюджет сжатия, достигая оптимального баланса между степенью сжатия и сохранением производительности модели.
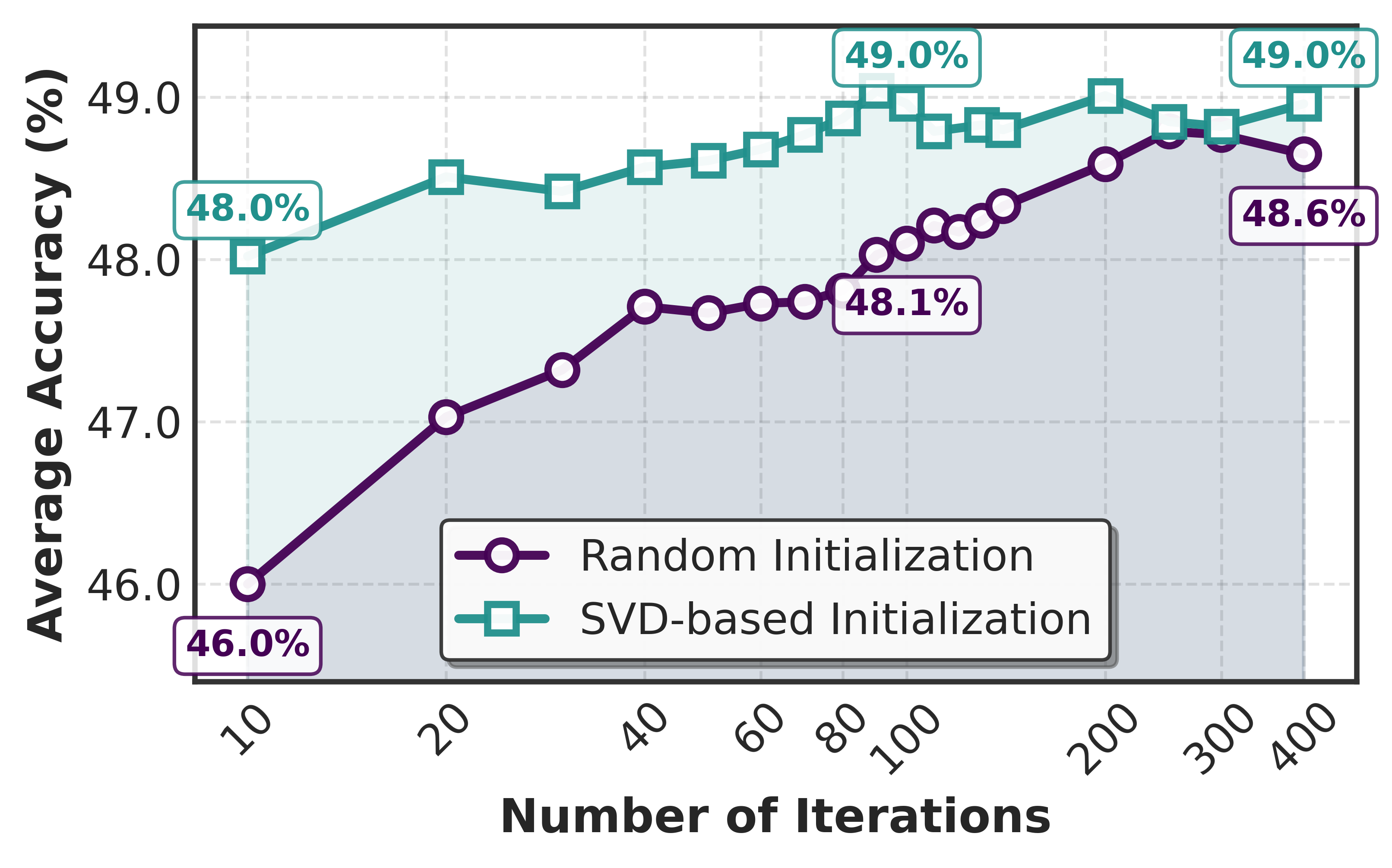
Калибровка, осуществляемая с применением методов, таких как Whitening, обеспечивает соответствие полученного словаря внутренней структуре модели. Это достигается за счет нормализации данных перед обучением словаря, что позволяет выделить наиболее значимые компоненты весов модели. В результате, COMPOT демонстрирует превосходство над методами SVD-LLM и CoSpaDi при различных коэффициентах сжатия, достигая передовых результатов на эталонных тестах, включая WikiText-2 и широкий спектр задач zero-shot. Эффективность калибровки подтверждается более высокой точностью сжатых моделей по сравнению с альтернативными подходами, обеспечивая сохранение критически важных параметров и производительности.
В ходе тестирования было установлено, что оптимизация COMPOT приблизительно в два раза быстрее, чем у CoSpaDi. При этом, на задачах, таких как оценка Word Error Rate модели Whisper на датасете LibriSpeech, COMPOT демонстрирует производительность, близкую к показателям некомпрессированной базовой модели. Это достигается благодаря эффективному алгоритму сжатия и сохранению ключевой информации в весах модели, что позволяет поддерживать высокую точность при значительном снижении вычислительных затрат.
За пределами COMPOT: Расширение Методов Сжатия
Несмотря на значительный прогресс, представленный COMPOT, важно отметить, что данная технология не существует изолированно, а опирается на и дополняет существующие методы компрессии, такие как постобработанная квантизация. Примером эффективной постобработанной квантизации служит алгоритм GPTQ, позволяющий значительно уменьшить размер модели без существенной потери точности. Комбинирование COMPOT и GPTQ открывает возможности для достижения еще более высоких коэффициентов сжатия и повышения эффективности использования вычислительных ресурсов. Вместо конкуренции, эти подходы демонстрируют синергию, позволяя разработчикам выбирать оптимальную комбинацию техник в зависимости от конкретных требований к производительности и размеру модели. Такой подход к компрессии позволяет преодолеть ограничения отдельных методов и приблизиться к созданию действительно компактных и эффективных нейронных сетей.
Сочетание различных методов сжатия нейронных сетей, таких как COMPOT и постобучение квантизации (например, GPTQ), позволяет добиться существенного увеличения степени сжатия и повышения эффективности. Исследования показывают, что последовательное или параллельное применение этих техник позволяет не только уменьшить размер модели, но и сохранить, а в некоторых случаях даже улучшить ее производительность. Например, предварительное сжатие с использованием GPTQ может подготовить модель к более агрессивной компрессии с помощью COMPOT, уменьшая потери точности. Такой синергетический эффект открывает новые возможности для развертывания сложных моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы, и значительно снижает затраты на хранение и передачу данных.
Принципы разреженного представления и построения ортогональных базисов, лежащие в основе COMPOT, имеют далеко идущие последствия для разработки более эффективных архитектур нейронных сетей. Вместо традиционных плотных матриц весов, где большинство элементов не вносят существенного вклада в итоговый результат, разреженное представление позволяет выделить лишь наиболее значимые параметры, существенно снижая вычислительную сложность и объем памяти. Использование ортогональных базисов, в свою очередь, способствует улучшению устойчивости и обобщающей способности моделей, предотвращая проблему коллинеарности признаков и облегчая процесс обучения. Эти концепции не ограничиваются только компрессией существующих моделей; они открывают возможности для создания принципиально новых архитектур, ориентированных на эффективность и масштабируемость, что особенно важно в контексте растущих требований к ресурсам при работе со сложными задачами искусственного интеллекта.
Представленная работа демонстрирует стремление к математической чистоте в области сжатия трансформеров. Разработанный метод COMPOT, основанный на калибровке и оптимизации матричной прокрустовой ортогонализации, подчеркивает важность доказанной корректности алгоритмов. Как некогда заметил Анри Пуанкаре: «Математика — это искусство логически упорядоченных отношений». Данный подход, в отличие от эмпирических методов, гарантирует стабильность и предсказуемость результатов, особенно при применении к сложным моделям, где даже небольшая ошибка может привести к существенной потере точности. Ортогональность, являющаяся ключевым элементом COMPOT, обеспечивает устойчивость решения и способствует эффективному сжатию, что полностью соответствует принципам доказательной математики.
Куда двигаться дальше?
Представленная работа, фокусируясь на изящном применении ортогонализации и оптимизации калибровки для сжатия трансформеров, лишь подчеркивает фундаментальную проблему: стремление к эффективности часто оборачивается компромиссом между точностью и вычислительными затратами. COMPOT демонстрирует, что аккуратное манипулирование матричными представлениями может принести ощутимые результаты, однако истинная элегантность решения заключается в его способности к формальному доказательству, а не в эмпирическом превосходстве на ограниченном наборе тестов. Вопрос в том, насколько далеко можно зайти, полагаясь исключительно на оптимизацию существующих структур, и не настало ли время для переосмысления базовых принципов архитектуры трансформеров.
Особый интерес представляет возможность интеграции методов, применяемых в COMPOT, с техниками разреженного кодирования нового поколения. Вместо простого уменьшения размерности матриц, можно ли разработать алгоритмы, которые эффективно идентифицируют и удаляют избыточную информацию, сохраняя при этом критически важные для функционирования модели параметры? Более того, перспективным направлением представляется исследование влияния различных метрик калибровки на процесс сжатия, а также разработка адаптивных стратегий, позволяющих автоматически подстраивать параметры алгоритма под специфические особенности каждой модели.
В конечном счете, в хаосе данных спасает только математическая дисциплина. Эмпирические успехи, безусловно, важны, но истинное прозрение приходит лишь тогда, когда алгоритм можно строго доказать. Иначе это лишь иллюзия эффективности, которая рано или поздно рассеется под натиском новых, более сложных задач.
Оригинал статьи: https://arxiv.org/pdf/2602.15200.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Молекулярный интеллект: проверка химического мышления
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовые вычисления для молекул: оптимизация ресурсов
- Искусственный интеллект проектирует алгоритмы: новый подход к автоматизации
- Искусственный интеллект и векторный поиск: рука об руку
- Молекулярная динамика под присмотром ИИ: новый взгляд на химические процессы
- Моделирование биомолекул: новый импульс от нейросетей
- За гранью ImageNet: Новый горизонт для машинного обучения в экологии
2026-02-18 12:42