Автор: Денис Аветисян
Новый подход к оценке потенциала языковых моделей позволяет более точно прогнозировать их производительность после обучения.
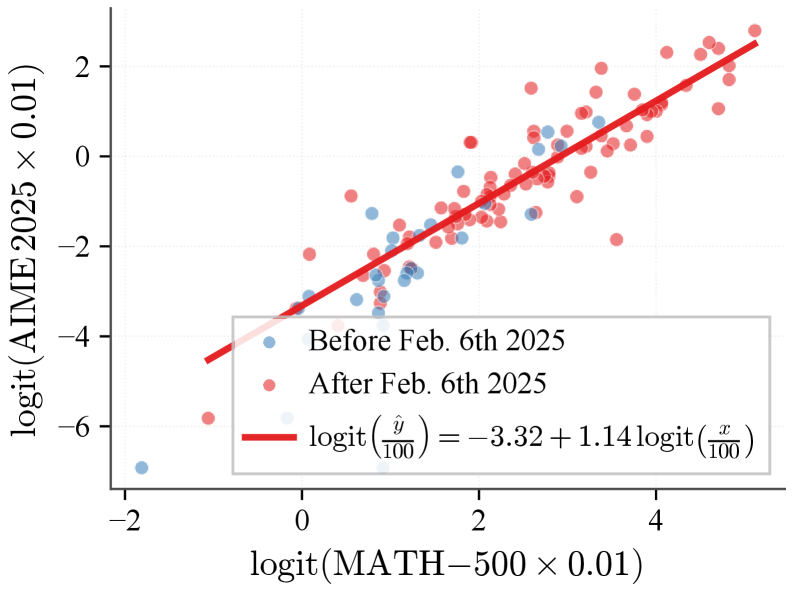
Исследование представляет метод ‘предписывающего масштабирования’ для определения границ возможностей языковых моделей на основе объема предварительного обучения.
Несмотря на стремительный прогресс в области языковых моделей, предсказание достижимой производительности при заданном объеме вычислительных ресурсов остается сложной задачей. В работе ‘Prescriptive Scaling Reveals the Evolution of Language Model Capabilities’ представлен новый подход — “предписывающее масштабирование”, позволяющий оценивать границы возможностей моделей после дообучения, исходя из объема предварительного обучения. Авторы используют регрессионный анализ для определения квантилей производительности на различных задачах, демонстрируя стабильность этих границ во времени, за исключением задач, требующих математического рассуждения. Возможно ли с помощью этого метода эффективно отслеживать эволюцию возможностей языковых моделей и прогнозировать будущие достижения в области искусственного интеллекта?
Прогнозирование Производительности: Основа Масштабирования Больших Языковых Моделей
Современные большие языковые модели (БЯМ) демонстрируют впечатляющий прогресс в решении разнообразных задач, однако прогнозирование их производительности остается сложной проблемой. Несмотря на увеличение вычислительных мощностей и объемов данных для обучения, точное предсказание возможностей БЯМ — от способности генерировать связный текст до решения сложных логических задач — затруднено из-за нелинейной зависимости между масштабом модели, объемом данных и фактической производительностью. Эта неопределенность создает препятствия для эффективного распределения ресурсов, поскольку определение оптимального баланса между размером модели и вычислительными затратами требует дорогостоящих экспериментов и зачастую приводит к неоптимальному использованию вычислительных мощностей. Таким образом, совершенствование методов прогнозирования производительности БЯМ является ключевым фактором для дальнейшего развития и масштабирования этих мощных инструментов.
В основе понимания возможностей больших языковых моделей (LLM) лежит тесная взаимосвязь между объемом предварительного обучения (вычислительными ресурсами) и размером модели. Эта зависимость не случайна и формализована так называемыми законами масштабирования. Эти законы позволяют предсказать, как изменится производительность модели при увеличении количества параметров или объема данных для обучения. Например, увеличение вычислительных ресурсов и размера модели обычно приводит к уменьшению ошибки и повышению точности, что описывается степенными функциями Error \propto Size^{-\alpha} и Error \propto Compute^{-\beta}, где α и β — эмпирические константы. Понимание этих закономерностей имеет решающее значение для эффективного масштабирования LLM и оптимизации использования вычислительных ресурсов, позволяя добиваться максимальной производительности при заданных ограничениях.
Точное прогнозирование производительности языковых моделей позволяет значительно оптимизировать распределение ресурсов и ускорить процесс их разработки. Вместо проведения дорогостоящих и длительных экспериментов с различными конфигурациями, исследователи и разработчики могут использовать предсказанные показатели для выбора наиболее перспективных архитектур и параметров обучения. Это особенно важно при масштабировании моделей, где вычислительные затраты могут быть огромными. Возможность заранее оценить потенциал модели позволяет целенаправленно инвестировать ресурсы в наиболее эффективные направления, сокращая время и стоимость разработки, а также повышая общую производительность и эффективность получаемых результатов. y = a * x^b — подобное предсказание, основанное на вычислительных затратах и размере модели, становится ключевым инструментом в эпоху быстрого развития искусственного интеллекта.
Отсутствие надежных методов прогнозирования производительности больших языковых моделей существенно замедляет прогресс в этой области. Разработчики вынуждены тратить огромные вычислительные ресурсы и время на дорогостоящие эксперименты, чтобы определить оптимальный размер модели и объем данных для обучения. Каждая итерация, основанная на эмпирических данных, а не на точных предсказаниях, сопряжена с риском неэффективного использования ресурсов и затягиванием сроков реализации. В результате, инновации тормозятся, а потенциал масштабного применения этих мощных инструментов остается нереализованным из-за непредсказуемости и высоких затрат, связанных с процессом разработки.
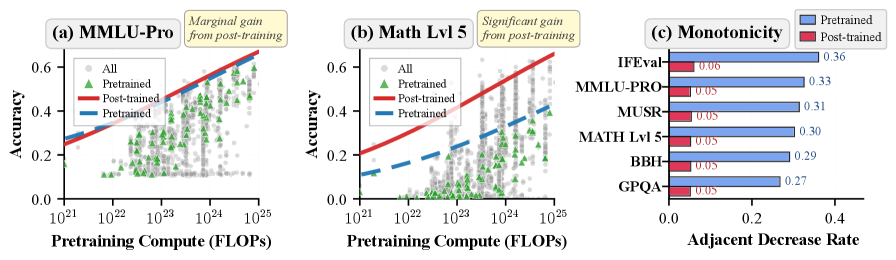
Определение Границы Возможностей: Моделирование Пределов Производительности
Граница возможностей (capability boundary) представляет собой верхний квантиль наблюдаемой точности, достижимой при заданном объеме вычислительных ресурсов. Это означает, что для конкретного бюджета вычислений, данная граница определяет максимальный уровень производительности, который можно разумно ожидать от любой модели. Определение этой границы позволяет оценить, насколько эффективно используются вычислительные ресурсы и какие пределы существуют для дальнейшего улучшения производительности. По сути, это статистическая оценка верхнего предела достижимой точности, учитывающая распределение результатов, полученных при заданном объеме вычислений.
Для моделирования границы возможностей, определяющей достижимую точность при заданном объеме вычислений, применяются различные функциональные формы. Наиболее простым вариантом является использование сигмоидальной функции, однако для более точного представления зависимости могут использоваться и сплайны I-типа. Сплайны I-типа, в отличие от сигмоиды, обладают большей гибкостью и позволяют более детально учитывать особенности зависимости точности от объема вычислений, особенно в областях с высокой кривизной. Выбор конкретной функции зависит от требуемой точности моделирования и доступных вычислительных ресурсов.
Наши исследования показали, что границы производительности больших языковых моделей (LLM) эффективно описываются сигмоидными функциями от логарифма вычислительных затрат. Коэффициент детерминации R^2 для данной модели варьируется от 0.85 до 0.95 применительно к различным задачам. Это указывает на высокую степень соответствия наблюдаемых данных теоретической сигмоидной функции, что позволяет использовать данную модель для прогнозирования максимальной достижимой точности в зависимости от доступных вычислительных ресурсов. Применение логарифмической шкалы для вычислительных затрат обеспечивает более линейную зависимость и, как следствие, более точное моделирование границы производительности.
Точное определение границы возможностей capability boundary имеет решающее значение для объективной оценки и сравнения больших языковых моделей (LLM). Предлагаемый нами подход обеспечивает высокую точность, поддерживая погрешность покрытия всего в 1-2%. Это означает, что в 98-99% случаев предсказанные границы возможностей соответствуют фактическим наблюдаемым значениям, что позволяет проводить более надежный анализ и сравнение производительности различных LLM при заданных вычислительных ресурсах.
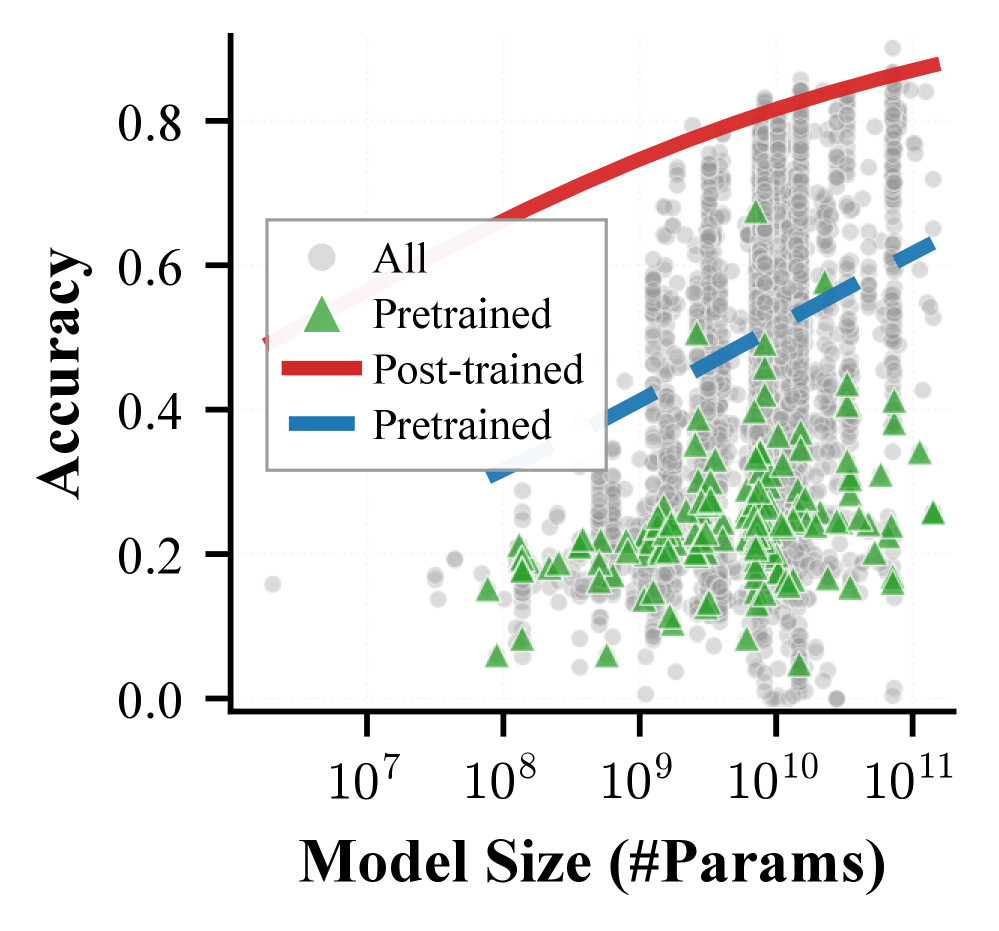
Эффективная Оценка Моделей: Баланс между Информацией и Разнообразием
Оценка всех доступных больших языковых моделей (LLM) представляет собой вычислительно невыполнимую задачу из-за экспоненциального роста их числа и сложности. Это обусловлено необходимостью проведения большого количества дорогостоящих вычислений для каждого теста, что делает полный перебор непрактичным. Поэтому, для эффективной оценки, требуется применение стратегий отбора, позволяющих выделить репрезентативную подгруппу моделей для детального анализа. Эти стратегии направлены на минимизацию вычислительных затрат при сохранении необходимого уровня информативности и надежности результатов оценки.
Сбалансированный I-оптимальный дизайн представляет собой метод выбора разнообразного подмножества языковых моделей (LLM) с целью максимизации информативности оценки. В основе подхода лежит концепция минимизации неопределенности в оценке производительности моделей. Выбор осуществляется не случайным образом, а на основе матриц ковариаций, отражающих взаимосвязь между производительностью различных моделей на различных задачах. Алгоритм стремится отобрать модели, которые обеспечивают наибольший прирост информации о производительности всего пула моделей, избегая избыточности и фокусируясь на моделях, существенно различающихся по своим характеристикам. Это позволяет получить надежную оценку производительности, используя лишь небольшую часть от общего числа доступных LLM.
Оптимизация процесса отбора моделей достигается за счет применения математических методов, таких как формула Шермана-Моррисона и биннинг. Формула Шермана-Моррисона (I - uv^T)^{-1} = I + \frac{uv^T}{1 + v^T u} позволяет эффективно вычислять обратную матрицу ранга-1, что ускоряет расчеты при добавлении новых моделей к отобранному набору. Биннинг, в свою очередь, представляет собой разделение моделей на группы по схожим характеристикам, что позволяет выбрать репрезентативные модели из каждой группы и обеспечить разнообразие в отобранной выборке, избегая избыточности и снижая вычислительные затраты.
Для практической реализации и оптимизации затрат на оценку моделей, совместно с методами I-оптимального планирования используется жадный алгоритм. В процессе выбора подмножества моделей для оценки, жадный алгоритм последовательно добавляет модель, максимизирующую прирост информации, до достижения заданного бюджета. Такой подход позволяет снизить вычислительные затраты на 20-50% по сравнению со стратегиями наивной оценки, при которых модели выбираются без учета их информативности и взаимосвязи. Использование жадного алгоритма в сочетании с методами, такими как формула Шермана-Моррисона и биннинг, обеспечивает эффективный баланс между разнообразием и информативностью выбранных моделей.
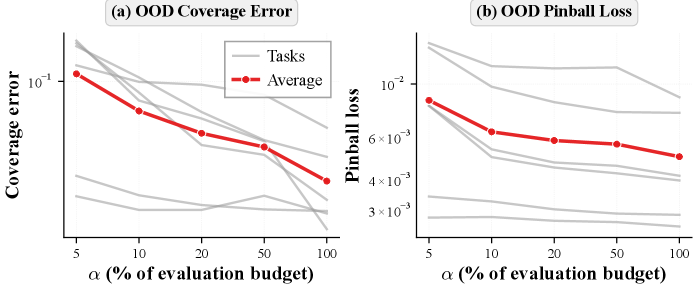
Обеспечение Валидности: Решение Проблем при Оценке в Практических Задачах
Оценка эффективности больших языковых моделей (LLM) в конечном итоге определяется их результатами в решении практических задач — так называемых “downstream” задачах. Однако, существует серьезная проблема, известная как “загрязнение” данных, когда часть тестового набора случайно или намеренно оказывается включенной в обучающую выборку модели. Это приводит к искусственному завышению показателей производительности, поскольку модель уже «видела» ответы на определенные вопросы во время обучения. Таким образом, высокие баллы, полученные на тестовом наборе, могут не отражать истинную способность модели к обобщению и решению новых, ранее не встречавшихся задач, что существенно искажает картину её реального потенциала и затрудняет объективное сравнение различных LLM.
Искусственное завышение оценок производительности, вызванное “загрязнением” обучающих данных тестовыми примерами, представляет собой серьезную проблему для объективной оценки больших языковых моделей. Включение фрагментов тестовых данных в процесс обучения позволяет модели, по сути, “списать” ответы, создавая иллюзию более высокой компетентности, чем есть на самом деле. Такое искажение приводит к неверным выводам о реальных возможностях модели и может ввести в заблуждение исследователей и разработчиков, принимающих решения на основе этих показателей. В результате, оценка становится не отражением истинного интеллекта, а лишь свидетельством успешного распознавания и воспроизведения ранее увиденных примеров, что препятствует прогрессу в области искусственного интеллекта и ограничивает потенциал для создания действительно интеллектуальных систем.
Изменения в производительности больших языковых моделей (LLM) с течением времени представляют собой значительную проблему для объективной оценки. Наблюдается, что модели, демонстрирующие впечатляющие результаты на определенный момент, могут со временем показывать ухудшение или, наоборот, улучшение показателей. Это связано с непрерывным обучением моделей, обновлениями в алгоритмах и изменениями в данных, используемых для обучения. Поэтому, единичные оценки, сделанные в определенный момент времени, могут не отражать истинный потенциал модели и не позволяют провести корректное сравнение между различными LLM. Для получения надежных результатов необходим постоянный мониторинг и повторная оценка моделей с учетом временного фактора, а также учет потенциальных изменений в их возможностях и характеристиках.
Платформы, такие как Open LLM Leaderboard, играют ключевую роль в оценке возможностей больших языковых моделей, однако для обеспечения достоверности сравнительных данных необходимо учитывать ряд сложностей. Искусственное завышение результатов, вызванное попаданием тестовых данных в обучающую выборку, может создать ложное впечатление о превосходстве одной модели над другой. Кроме того, временные изменения в производительности моделей, обусловленные обновлениями или изменениями в данных, также требуют постоянного мониторинга и учета. Для получения объективной картины необходимо внедрять строгие протоколы контроля целостности данных и отслеживать динамику показателей во времени, что позволит избежать предвзятых оценок и обеспечит более надежное сравнение различных языковых моделей.
Исследование демонстрирует, что традиционные законы масштабирования зачастую оказываются неадекватными при оценке потенциальных возможностей языковых моделей после дополнительного обучения. Предложенный подход — ‘предписываемое масштабирование’ — стремится к более точному прогнозированию, опираясь на объем вычислений, затраченных на предварительное обучение. Как заметил Бертран Рассел: «Всякое определение мира есть отчасти ложь». Подобно этому, и законы масштабирования представляют собой упрощение сложной реальности, а предложенный метод — попытка приблизиться к истинному пониманию границ возможностей языковых моделей, учитывая влияние этапа предварительного обучения на конечный результат. Ясность в определении этих границ — минимальная форма любви к науке.
Куда же дальше?
Представленный подход к «предписываемому масштабированию» — не столько прорыв, сколько признание неадекватности существующих моделей предсказания возможностей языковых моделей после обучения. Попытка выявить границы достижимого, опираясь на вычислительные ресурсы, затраченные на предварительное обучение, выглядит разумно, но упускает из виду фундаментальную сложность самой задачи. Ведь истинное ограничение — не в вычислительной мощности, а в самой природе данных, в их внутренней противоречивости и неполноте.
Дальнейшие исследования неизбежно столкнутся с необходимостью более точного определения «способности» — этого скользкого понятия, которое мы продолжаем измерять косвенными метриками. Очевидно, что повышение «предсказательной силы» — само по себе не является достаточным условием для достижения истинного интеллекта. Необходимо сосредоточиться на выявлении и устранении внутренних противоречий в моделях, на создании систем, способных к самокритике и коррекции.
Возможно, истинный прогресс заключается не в наращивании вычислительных мощностей, а в поиске более эффективных алгоритмов обучения и представления знаний. Сложность — это не вызов, а признак неэффективности. Простота — не ограничение, а высшая форма интеллекта. Истинное понимание возможностей языковых моделей придет, когда их принципы работы можно будет объяснить одним предложением.
Оригинал статьи: https://arxiv.org/pdf/2602.15327.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Диагностика заболеваний печени: новый подход с использованием искусственного интеллекта
- Квантовые точки и литий танталат: новый путь к фотонным микросхемам
- Квантовый скачок или технологический тупик? Анализ новостей о квантовых технологиях
- Шёпот хаоса в унифицированном представлении: Ming-Flash-Omni и алхимия мульмодальности.
- Распознавание антинуклеарных антител: обучение на собственном темпе
- Упорядоченный разум: Как языковые модели учатся справляться с длинными текстами
2026-02-18 14:28