Автор: Денис Аветисян
Новая серия моделей jina-embeddings-v5 обеспечивает высокую производительность в задачах семантического поиска и сравнения текстов, предлагая оптимальный баланс между размером и качеством.
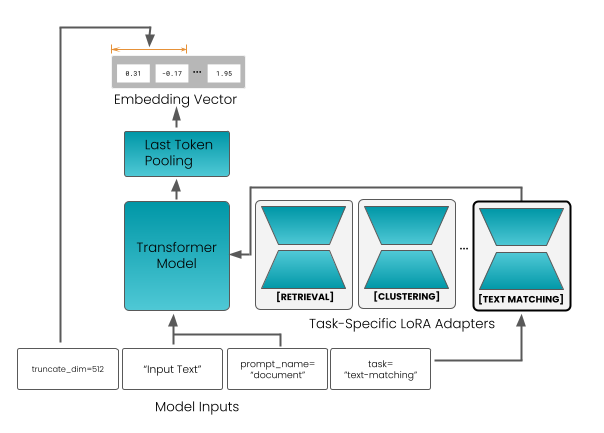
Исследование представляет семейство компактных многоязычных моделей векторных представлений, обученных с применением дистилляции знаний и контрастивного обучения для повышения эффективности и точности.
Несмотря на широкое распространение моделей векторных представлений текста, достижение высокой производительности при одновременном снижении вычислительных затрат остается сложной задачей. В данной работе, посвященной ‘jina-embeddings-v5-text: Task-Targeted Embedding Distillation’, представлен новый подход к обучению компактных многоязычных моделей, сочетающий дистилляцию знаний и контрастивное обучение, ориентированное на конкретные задачи. Полученные модели, jina-embeddings-v5-text, демонстрируют передовые результаты для моделей аналогичного размера, поддерживают длинные тексты и сохраняют устойчивость к усечению и квантованию. Не откроет ли это путь к созданию еще более эффективных и доступных систем семантического поиска и анализа текста?
Фундамент: Векторное представление смысла
Современные системы обработки естественного языка (NLP) все больше опираются на представление слов и предложений в виде плотных векторов, что позволяет улавливать семантические связи между ними. Вместо традиционных методов, где слова рассматривались как отдельные символы, векторы фиксируют значение слова в многомерном пространстве, где близкие по смыслу слова располагаются рядом. Это достигается за счет сложных алгоритмов машинного обучения, анализирующих огромные объемы текста для выявления закономерностей и зависимостей. Такой подход позволяет компьютеру не просто распознавать слова, но и понимать их контекст и взаимосвязи, открывая возможности для решения сложных задач, таких как машинный перевод, анализ тональности и ответы на вопросы. \vec{w} = [w_1, w_2, ..., w_n] — пример векторного представления слова, где каждое значение w_i отражает определенный аспект его значения.
Современные модели обработки естественного языка, известные как текстовые эмбеддинги, позволяют компьютерам «понимать» текст, преобразуя слова и фразы в числовые векторы. Суть заключается в том, что семантически близкие слова и предложения отображаются в векторы, находящиеся рядом друг с другом в многомерном пространстве. Это достигается путем обучения моделей на огромных объемах текстовых данных, что позволяет им выявлять и кодировать тонкие нюансы значения. Таким образом, компьютер может не просто распознать отдельные слова, но и оценить их взаимосвязь и контекст, количественно определяя степень сходства или различия между различными текстовыми фрагментами. similarity = cos(\theta) — мера косинусного сходства часто используется для оценки близости векторов, представляющих текст.
Эффективный поиск в пространствах плотных векторов является ключевым аспектом современных систем поиска информации. Вместо традиционных методов, основанных на сопоставлении ключевых слов, современные алгоритмы используют векторы, представляющие семантическое значение текста. Это позволяет находить документы, релевантные запросу не только по точному совпадению слов, но и по смыслу. Высокая скорость поиска в этих многомерных пространствах достигается благодаря специализированным алгоритмам, таким как Approximate Nearest Neighbor (ANN) поиск, позволяющим находить ближайшие векторы к вектору запроса за доли секунды, даже в базах данных, содержащих миллиарды векторов. Такой подход значительно повышает точность и скорость поиска, открывая возможности для создания интеллектуальных систем, способных понимать и обрабатывать информацию на качественно новом уровне.
Архитектурная основа: Трансформеры и за её пределами
Архитектура Transformer стала доминирующим подходом к созданию текстовых эмбеддингов благодаря использованию механизмов самовнимания (self-attention). В отличие от рекуррентных и сверточных сетей, Transformer позволяет обрабатывать все элементы последовательности параллельно, что значительно ускоряет процесс обучения и инференса. Механизм самовнимания позволяет модели взвешивать различные части входной последовательности при создании представления каждого токена, эффективно улавливая зависимости между словами, независимо от их расстояния друг от друга. Это обеспечивает более точное и контекстуально-зависимое представление текста по сравнению с предыдущими подходами, что делает Transformer основой для современных моделей обработки естественного языка.
Ключевым фактором эффективности архитектуры Transformer является использование слоя пулинга для агрегации информации во встраивания фиксированного размера. В процессе обработки входной последовательности, слой пулинга применяет функцию (например, max-pooling или average-pooling) к выходным данным механизма self-attention. Это позволяет преобразовать последовательность векторов переменной длины, представляющих различные части входного текста, в вектор фиксированной размерности. Полученный вектор содержит сжатое представление всей входной последовательности и используется для последующих задач, таких как классификация текста или поиск семантического сходства. Выбор функции пулинга и ее параметров влияет на качество получаемых встраиваний и, соответственно, на производительность модели.
Модели, такие как Sentence-BERT (SBERT), представляют собой модификацию стандартной архитектуры Transformer, оптимизированную для решения задач семантической схожести предложений. В отличие от классических Transformer-моделей, генерирующих контекстуализированные представления слов, SBERT обучена производить векторные представления целых предложений, пригодные для вычисления косинусного сходства или других метрик расстояния. Это достигается за счет применения пулинговых стратегий и специализированных функций потерь, таких как triplet loss или contrastive loss, которые позволяют модели различать семантически схожие и различные предложения. Обучение SBERT требует значительно меньше вычислительных ресурсов по сравнению с обучением больших языковых моделей с нуля, что делает ее эффективным решением для задач, требующих быстрого вычисления семантического сходства.
Стратегии обучения: Формирование осмысленных представлений
Контрастивное обучение — это эффективный метод тренировки моделей, основанный на обучении различать семантически близкие и далёкие примеры текста. В процессе обучения модель получает пары текстов, где одна пара содержит схожие по смыслу фрагменты, а другая — различные. Модель обучается таким образом, чтобы векторы представлений (embeddings) схожих текстов были близки друг к другу в векторном пространстве, а векторы представлений различных текстов — далеки. Это позволяет модели формировать более качественные и информативные представления текста, что особенно полезно для задач семантического поиска, кластеризации и анализа схожести текстов. Эффективность контрастивного обучения обусловлена способностью модели улавливать тонкие семантические различия и обобщать информацию о схожести и различиях между текстами.
Метод дистилляции знаний позволяет передавать информацию из больших, предварительно обученных моделей, таких как Qwen3-4B, в более компактные модели, называемые «студентами». Этот процесс включает в себя обучение «студента» имитировать поведение «учителя», включая его выходные данные и внутренние представления. В результате «студент» может достичь сопоставимой производительности, при этом требуя значительно меньше вычислительных ресурсов и памяти. Ключевым аспектом является использование «мягких меток» (soft labels) — вероятностных распределений, выдаваемых «учителем», вместо жестких меток (hard labels), что позволяет «студенту» усваивать более тонкие нюансы и обобщающие способности исходной модели.
Модель Jasper демонстрирует практическое применение дистилляции знаний для создания эффективных векторных представлений (embeddings). В процессе обучения, большая модель-учитель, такая как Qwen3-4B, передает свои знания и навыки меньшей модели-ученику (Jasper). Это достигается путем обучения Jasper имитировать выходные данные учителя, что позволяет создать компактную модель, сохраняющую высокую точность представления текстовой информации при значительно меньших вычислительных затратах и требованиях к памяти. В результате, Jasper обеспечивает эффективное создание embeddings для различных задач обработки естественного языка.
Оценка и усовершенствование: Эталоны и передовые техники
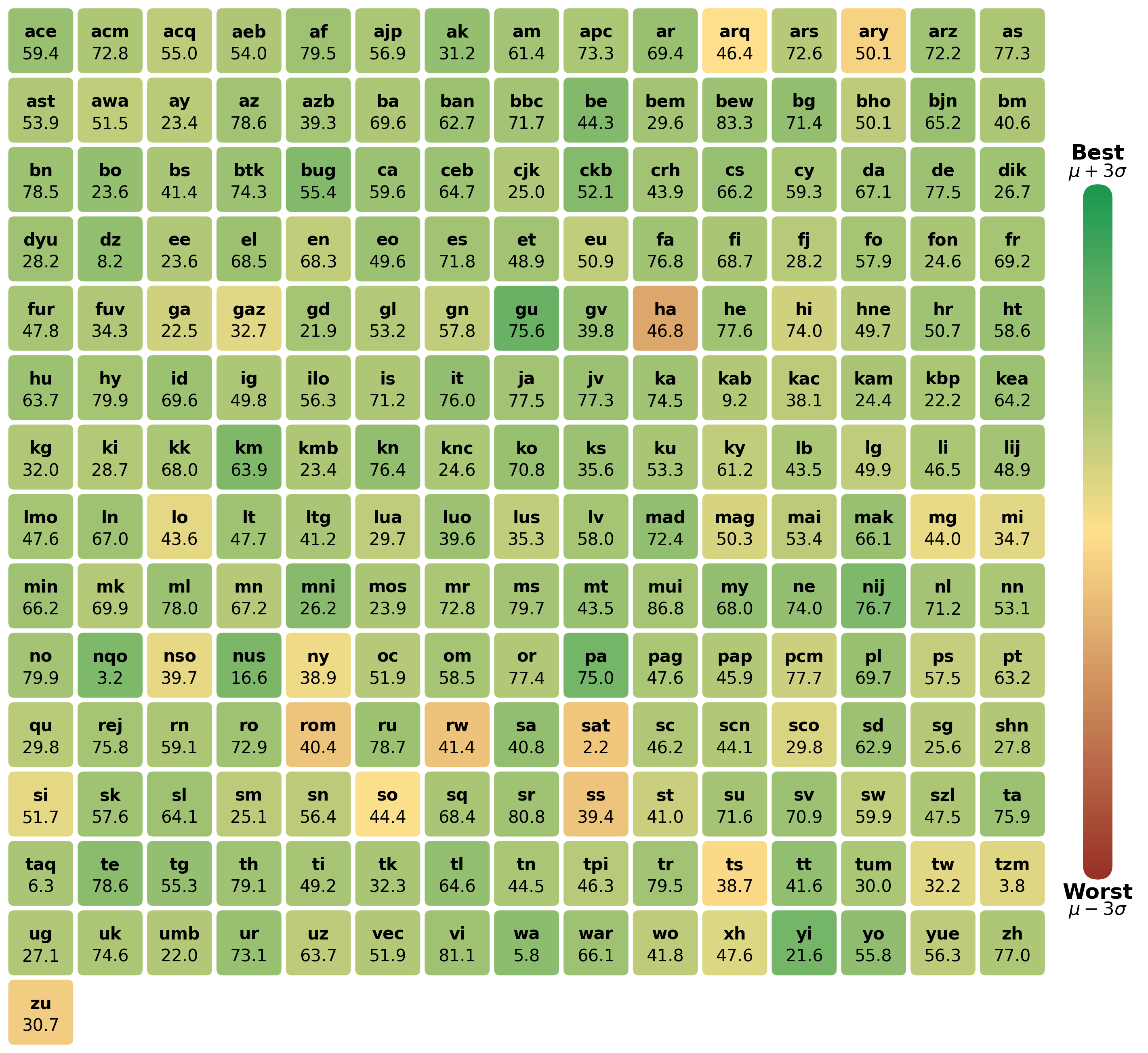
Оценка качества текстовых представлений — сложная задача, требующая использования специализированных эталонов. Такие бенчмарки, как MTEB (Massive Text Embedding Benchmark), RTEB (Retrieval-augmented Text Embedding Benchmark) и Long Embed Benchmark, представляют собой комплексные наборы данных, предназначенные для всесторонней проверки эффективности моделей в различных сценариях. Эти эталоны позволяют объективно сравнить различные подходы к созданию текстовых представлений, оценивая их способность к семантическому поиску, кластеризации и другим задачам. Разнообразие задач, включенных в эти бенчмарки, гарантирует, что модели, показавшие высокие результаты, действительно обладают обобщающей способностью и могут быть успешно применены в широком спектре практических приложений, от информационного поиска до анализа тональности.
Асимметричный поиск представляет собой инновационный подход к извлечению информации, который отказывается от традиционного симметричного подхода к запросам и документам. Вместо этого, он рассматривает их по-разному, используя, например, префиксацию запросов. Суть метода заключается в том, чтобы модифицировать запрос, добавляя к нему контекст или дополнительные инструкции, что позволяет модели лучше понять намерение пользователя и точнее сопоставить его с релевантными документами. Такой подход особенно эффективен в ситуациях, когда запросы короткие или неоднозначные, а документы содержат богатый контекст. В результате, асимметричные стратегии поиска демонстрируют значительное улучшение производительности, позволяя находить более релевантные результаты и повышать общую эффективность систем извлечения информации.
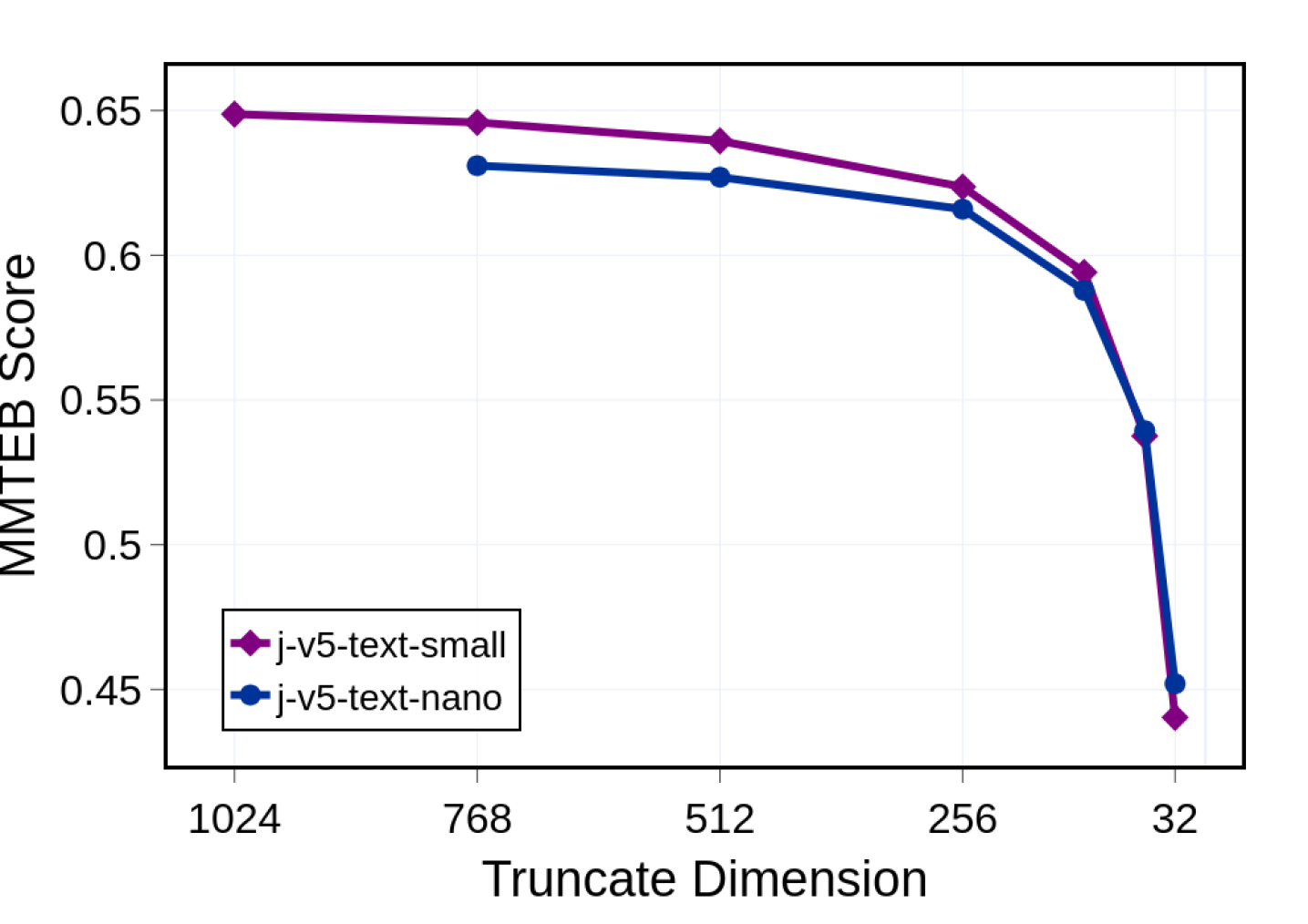
Метод обучения представлений «Матрешка» (Matryoshka Representation Learning) предлагает инновационный подход к снижению размерности векторных представлений текста, позволяя создавать более компактные и эффективные модели. В основе лежит идея последовательного уменьшения размерности, подобно русской матрешке, где каждый слой содержит предыдущий, но в более сжатом виде. В сочетании с такими техниками, как LoRA (Low-Rank Adaptation) адаптеры, этот метод обеспечивает не только уменьшение вычислительных затрат и требований к памяти, но и возможность эффективной тонкой настройки моделей на конкретных задачах. LoRA адаптеры позволяют обучать лишь небольшое количество дополнительных параметров, оставляя основную модель неизменной, что значительно ускоряет процесс обучения и снижает риск переобучения, сохраняя при этом высокую точность и качество векторных представлений.
Современные модели, такие как jina-embeddings-v5-text-small, демонстрируют передовые результаты в области создания текстовых представлений. Достигнутый средний показатель MMTEB в 64.50 свидетельствует о значительном прогрессе в способности моделей понимать и сопоставлять значения различных текстовых фрагментов. Это позволяет им эффективно решать широкий спектр задач, включая поиск информации, анализ семантической близости и классификацию текстов. Такая высокая производительность открывает новые возможности для приложений, требующих точного и надежного понимания естественного языка, и является важным шагом на пути к созданию более интеллектуальных систем.
Недавние разработки в области моделей представления текста демонстрируют значительное повышение устойчивости к бинарной квантизации. В ходе исследований зафиксировано снижение деградации производительности на 30-50% при использовании данных моделей, по сравнению с предыдущими поколениями. Это означает, что даже при значительном уменьшении размера модели, за счет использования бинарных весов, сохраняется высокий уровень точности и эффективности при решении различных задач, связанных с обработкой естественного языка. Подобное улучшение открывает возможности для развертывания сложных моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы, без существенной потери качества.
Результаты тестирования новых моделей на бенчмарке RTEB демонстрируют значительный прогресс в области семантического поиска и понимания текста, достигая показателя в 66.45. Данный результат подтверждает высокую эффективность реализованных техник и подходов к построению векторных представлений текста. Повышение производительности на RTEB свидетельствует о том, что модели способны более точно сопоставлять запросы и документы, даже при наличии сложных лингвистических конструкций и неоднозначностей. Достигнутый уровень точности открывает новые возможности для различных приложений, таких как интеллектуальный поиск, ответы на вопросы и анализ текста, позволяя создавать более эффективные и удобные инструменты для работы с информацией.
Исследование представляет собой элегантное подтверждение того, что эффективность модели определяется не только её размером, но и глубиной понимания целевой задачи. Авторы, подобно математикам, стремящимся к доказательству теорем, фокусируются на дистилляции знаний и контрастивном обучении для достижения оптимальной производительности при минимальных вычислительных затратах. В данном случае, подход к созданию компактных мультиязычных эмбеддингов jina-embeddings-v5 демонстрирует, что истинная ценность заключается в точности представления семантического сходства, а не в избыточности параметров. Как однажды заметил Пол Эрдёш: «В математике нет ничего практичного, но всё, что практично, основано на математике». Эта фраза отражает суть работы — стремление к математической чистоте в практической задаче — создании эффективных и точных эмбеддингов.
Что Дальше?
Без чёткого определения критериев «достаточно хорошего» представления текста, любые дальнейшие улучшения — лишь вариации шума. Представленная работа, безусловно, демонстрирует снижение вычислительных издержек при сохранении (или даже улучшении) показателей качества. Однако, фундаментальный вопрос о том, как измерить истинную семантическую близость, остаётся открытым. Улучшение метрик на стандартных датасетах не гарантирует адекватность представления в реальных приложениях, где контекст и нюансы играют решающую роль.
Перспективным направлением представляется не просто увеличение объёма данных для обучения, а разработка формальных методов проверки корректности векторных представлений. Доказательство того, что конкретное представление действительно отражает семантические отношения, а не просто статистические корреляции, — вот где кроется истинный прогресс. Использование формальных методов верификации и доказательство свойств embedding-пространства — задача, требующая значительных усилий, но оправдывающая себя в долгосрочной перспективе.
Наконец, необходимо признать, что «универсального» embedding-пространства не существует. Оптимальное представление текста всегда будет зависеть от конкретной задачи. Разработка адаптивных моделей, способных динамически настраивать свои параметры в зависимости от контекста, представляется более плодотворной, чем погоня за абстрактным «супероптимальным» решением.
Оригинал статьи: https://arxiv.org/pdf/2602.15547.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Упорядоченный разум: Как языковые модели учатся справляться с длинными текстами
- Нейросеть предсказывает сродство антител к COVID-19
- Искусственный интеллект как клиницист: обучение на опыте для точной диагностики
- Роботы учатся на собственном опыте: новый подход к обучению с подкреплением
- Искуственный интеллект: хрупкость смысла в сложных задачах
- Понимание видео: новый вызов для искусственного интеллекта
2026-02-18 19:46