Автор: Денис Аветисян
Исследователи разработали метод, позволяющий измерять данные и восстанавливать лежащие в их основе дифференциальные уравнения, описывающие физические процессы.
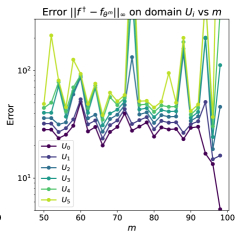
Предложенная работа демонстрирует сходимость полученных решений к истинным, используя символические сети и оптимизацию регуляризации для восстановления уравнений в частных производных.
Идентификация лежащих в основе физических законов по данным наблюдений представляет собой сложную задачу, особенно при наличии шума и неполноты измерений. В работе, посвященной ‘Symbolic recovery of PDEs from measurement data’, предлагается подход к символическому восстановлению уравнений в частных производных (УЧП) на основе нейронных сетей, использующих рациональные функции для представления законов физики. Показано, что при идеальных условиях, такие сети способны однозначно реконструировать простые физические законы, сохраняя их интерпретируемость благодаря регуляризации, направленной на минимизацию параметров. Сможет ли данная методика быть успешно применена для анализа реальных, сложных систем и раскрытия скрытых закономерностей в данных?
В поисках скрытых законов: вызов современной науки
Многие научные и инженерные задачи сводятся к определению фундаментальных физических законов на основе наблюдаемых данных — это классическая “обратная задача”. В отличие от прямого моделирования, где известны законы и предсказывается поведение системы, здесь ситуация обратная: по наблюдаемым результатам необходимо восстановить сами законы, управляющие этой системой. Этот процесс представляет значительную сложность, поскольку часто существует бесконечное множество возможных законов, которые могут объяснить имеющиеся данные. Поэтому успешное решение обратной задачи требует не только мощных вычислительных ресурсов, но и применения специальных методов анализа, позволяющих отделить истинные закономерности от случайных отклонений и обеспечить надежность полученных моделей. Именно поэтому обратные задачи представляют собой один из ключевых вызовов современной науки и техники.
Традиционные методы определения управляющих законов часто сталкиваются с серьезными трудностями при работе со сложными системами. Они зачастую требуют введения значительных упрощающих предположений о природе изучаемого процесса, что может существенно исказить конечный результат и снизить точность модели. Альтернативой является увеличение вычислительных ресурсов, однако и этот подход имеет свои пределы, поскольку сложность вычислений может расти экспоненциально с увеличением числа переменных и взаимодействий в системе. В результате, моделирование таких систем становится не только трудоемким, но и вычислительно невозможным, что ограничивает возможности прогнозирования и контроля над ними. В таких случаях необходимы принципиально новые подходы, способные эффективно справляться с высокой сложностью и неопределенностью, присущими реальным физическим системам.
Успешное решение этой обратной задачи имеет первостепенное значение для моделирования широкого спектра явлений, от динамики жидкостей до квантовой механики. В гидродинамике, например, точное определение управляющих законов позволяет предсказывать поведение потоков, оптимизировать аэродинамические формы и создавать более эффективные транспортные системы. В квантовой физике, идентификация фундаментальных законов необходима для понимания поведения элементарных частиц и разработки новых технологий, таких как квантовые компьютеры. Более того, способность извлекать физические законы из данных не ограничивается этими областями — она лежит в основе прогресса в материаловедении, биологии, астрофизике и многих других дисциплинах, позволяя создавать более точные и надежные модели окружающего мира и предсказывать его поведение.
Отсутствие точных физических законов, лежащих в основе прогностических моделей, существенно ограничивает их надежность и способность к обобщению. Модели, построенные на неверных или неполных принципах, демонстрируют хрупкость при изменении исходных условий и не способны адекватно предсказывать поведение системы в новых, ранее не встречавшихся ситуациях. Это особенно критично в сложных системах, где даже незначительные отклонения в базовых законах могут приводить к экспоненциальному расхождению предсказаний и реальности. Таким образом, точность фундаментальных принципов является краеугольным камнем для создания устойчивых и универсальных моделей, способных эффективно работать в широком диапазоне условий и обеспечивать достоверные прогнозы.
Обучение моделей на данных: новый подход к сложным системам
Обучение моделей на основе данных представляет собой эффективную альтернативу традиционным методам моделирования сложных систем. В отличие от подходов, требующих априорного определения структуры модели и последующей подгонки параметров, данный подход позволяет непосредственно извлекать модели из наблюдаемых данных. Это достигается путем анализа экспериментальных данных и выявления закономерностей, которые могут быть представлены в виде математических выражений. Такой метод особенно полезен в случаях, когда аналитическое описание системы затруднено или отсутствует, позволяя создавать модели, основанные исключительно на эмпирических наблюдениях и статистическом анализе, что обеспечивает более точное и адекватное описание реальных процессов.
В основе обучения моделей сложным системам на основе данных лежит процесс оценки параметров, заключающийся в определении значений параметров математической модели таким образом, чтобы она наилучшим образом соответствовала наблюдаемым данным. Этот процесс включает в себя формулирование целевой функции, отражающей расхождение между предсказаниями модели и фактическими наблюдениями, и последующую оптимизацию этой функции для нахождения оптимальных значений параметров. В общем случае, целевая функция может включать в себя L_2 норму ошибки или другие метрики, а оптимизация выполняется с использованием численных методов, таких как градиентный спуск или алгоритмы Левенберга-Марквардта. Успешная оценка параметров требует достаточного количества данных и корректной постановки математической модели, а также учета неопределенностей и шумов в данных.
Обеспечение уникальности оцениваемых параметров — проблема идентифицируемости — остается ключевой задачей при построении моделей на основе данных. Неидентифицируемость возникает, когда различные наборы параметров приводят к одинаковому описанию наблюдаемых данных, что делает невозможным определение истинных значений параметров модели. Это может быть вызвано недостаточным количеством данных, высокой степенью корреляции между параметрами или неполнотой математической модели. В результате, оценка параметров становится неоднозначной, что приводит к неточностям в прогнозах и затрудняет интерпретацию модели. Для решения данной проблемы применяются методы регуляризации, анализа чувствительности и, при необходимости, пересмотр структуры модели или сбор дополнительных данных.
Для точного построения моделей сложных систем критически важны полные измерения, обеспечиваемые оператором измерений. Под “полнотой” подразумевается наличие достаточного количества независимой информации, необходимой для однозначного определения всех параметров модели. Недостаток данных, или наличие коррелированных измерений, приводит к проблемам идентифицируемости — невозможности уникально восстановить параметры модели по наблюдаемым данным. Оператор измерений M преобразует истинное состояние системы x в наблюдаемые данные y: y = M(x). Качество и полнота данных, получаемых через этот оператор, напрямую влияют на точность и надежность построенной модели, определяя ее способность адекватно описывать и прогнозировать поведение системы.
Символические сети: объединение интерпретируемости и мощности
Символьная регрессия представляет собой метод поиска математических выражений непосредственно из данных, позволяющий выявить аналитическую зависимость между переменными без предварительного задания функциональной формы. Однако, в отличие от традиционных методов машинного обучения, процесс поиска оптимальной модели в символьной регрессии требует перебора большого количества возможных математических комбинаций, что приводит к значительно высоким вычислительным затратам, особенно при работе с большими объемами данных или сложными задачами. Вычислительная сложность возрастает экспоненциально с увеличением количества входных переменных и глубины искомого выражения, что ограничивает применимость метода к задачам реального времени и крупномасштабному анализу данных.
Символические сети объединяют возможности символьной регрессии и нейронных сетей для создания моделей, сочетающих в себе точность и интерпретируемость. В отличие от традиционных нейронных сетей, являющихся “черными ящиками”, символические сети строятся на основе математических выражений, что позволяет напрямую анализировать и понимать логику принятия решений моделью. Данный подход достигается путем использования нейронных сетей для поиска оптимальной структуры и параметров математических функций, описывающих данные, что позволяет получить компактные и понятные модели, сохраняя при этом высокую прогностическую способность. Фактически, символические сети представляют собой способ параметризации математических выражений с помощью нейронной сети, что открывает возможности для автоматического обнаружения закономерностей в данных и построения интерпретируемых моделей.
Символические сети используют рациональные функции и базовые функции для представления сложных зависимостей в данных. Рациональные функции, представляющие собой отношение двух полиномов \frac{P(x)}{Q(x)} , позволяют эффективно аппроксимировать широкий спектр нелинейных отношений, включая те, которые сложно моделировать традиционными полиномами. Базовые функции, такие как синусы, косинусы, экспоненты и логарифмы, расширяют возможности модели, позволяя представлять периодические и экспоненциальные зависимости. Комбинация этих функций обеспечивает более компактное и точное представление данных по сравнению с полносвязными нейронными сетями, что приводит к повышению точности и эффективности модели, а также к снижению вычислительных затрат.
Регуляризация, в частности L1-регуляризация, является критически важной для предотвращения переобучения и повышения обобщающей способности моделей Symbolic Networks. L1-регуляризация добавляет к функции потерь штраф, пропорциональный абсолютной величине весов, что способствует разреженности модели и снижает сложность. Наши результаты демонстрируют, что применение L1-регуляризации приводит к сходимости параметров обучения, подтверждая её эффективность в предотвращении переобучения и улучшении способности модели к обобщению на новых данных. В процессе обучения наблюдается уменьшение значений весов, что свидетельствует о выборе наиболее значимых признаков и исключении избыточных параметров, что, в свою очередь, способствует повышению устойчивости и интерпретируемости модели. Эффект регуляризации проявляется в более плавной кривой обучения и предотвращении резких колебаний, что указывает на улучшение стабильности процесса обучения и повышение качества полученной модели.
«All-at-Once» подход: унифицированное решение для идентификации систем
Предложенная методика «All-at-Once» позволяет одновременно оценивать как состояние системы, так и лежащий в её основе физический закон. В отличие от традиционных подходов, требующих последовательной идентификации, данный метод объединяет эти задачи в единый процесс. Это достигается за счёт представления уравнений в частных производных в функциональном пространстве, что позволяет эффективно использовать информацию о динамике системы для восстановления как её текущего состояния, так и параметров, определяющих её эволюцию. Такой подход особенно полезен в случаях, когда точное знание физического закона неизвестно или подвержено неопределенности, обеспечивая более точную и вычислительно эффективную идентификацию по сравнению с раздельными методами. Результаты показывают, что предложенная методика способна к сходимости как к истинному состоянию системы, так и к её физическому закону, что подтверждается численными экспериментами для различных типов уравнений в частных производных, включая уравнения Навье-Стокса, реакции-диффузии и уравнения Шрёдингера.
Предложенный подход, основанный на представлении частных дифференциальных уравнений в функциональном пространстве, обеспечивает повышенную точность и вычислительную эффективность. Вместо традиционного решения уравнений в дискретных точках, данный метод оперирует с функциями как таковыми, что позволяет более точно отразить непрерывную природу физических процессов. Это достигается за счет использования компактного представления уравнений и снижения размерности решаемой задачи, что, в свою очередь, ведет к уменьшению вычислительных затрат и ускорению сходимости алгоритма. f_{\theta_m}(u, u_x) = 1.006u - 0.005u_x^2 + 2.116u_x - 0.535 — пример приближения истинного физического закона, полученного в ходе численных экспериментов, демонстрирующий эффективность метода даже в случаях неполной идентифицируемости.
Предложенный метод, основанный на одновременной оценке состояния системы и лежащих в её основе физических законов, демонстрирует универсальность применения к широкому спектру физических явлений. Он успешно применяется для моделирования динамики жидкостей, описываемой уравнениями Навье-Стокса, процессов диффузии, моделируемых уравнениями реакции-диффузии, и даже квантово-механических систем, описываемых уравнением Шрёдингера. Данный подход позволяет эффективно анализировать и прогнозировать поведение сложных систем, охватывающих различные области науки и техники, от гидродинамики и химии до физики элементарных частиц. Возможность адаптации к различным типам уравнений в частных производных делает его мощным инструментом для решения задач, ранее требовавших специализированных методов и значительных вычислительных ресурсов.
Результаты численных экспериментов демонстрируют сходимость к истинному закону и состоянию системы при использовании предложенного подхода. В частности, для уравнений в частных производных, имеющих единственное решение, была достигнута аппроксимация истинного закона в виде f_{\theta_m}(u, u_x) = 1.006u - 0.005u_x^2 + 2.116u_x - 0.535 при m = 100. Даже в случаях, когда задача идентификации не имеет единственного решения, наблюдается сходимость, что подтверждается полученным приближением закона в виде f_{\theta_m}(u, u_x) = -0.982u - 0.016u_x. Эти результаты свидетельствуют о высокой точности и надежности метода идентификации систем, позволяющего восстанавливать как динамику состояния, так и лежащие в её основе физические законы, даже в сложных и неоднозначных ситуациях.
Исследование, представленное в данной работе, демонстрирует элегантный подход к восстановлению интерпретируемых физических законов из моделей уравнений в частных производных. Особый интерес представляет доказательство сходимости полученного решения к истинному, при условии оптимальной параметризации регуляризации. Как отмечал Бертран Рассел: «Чем больше я узнаю, тем больше понимаю, как мало я знаю». Это высказывание перекликается с постоянным стремлением к углублению понимания сложных систем, что и является движущей силой научных исследований в области Scientific Machine Learning. По сути, предложенный фреймворк представляет собой попытку не просто аппроксимировать решение, а извлечь из данных фундаментальные принципы, лежащие в основе описываемого явления, что соответствует идее поиска устойчивых и обобщаемых закономерностей.
Что дальше?
Представленная работа, по сути, констатирует закономерность: любые модели, даже те, что претендуют на описание физических законов, подвержены энтропии. Поиск «истинного» решения — это не столько достижение стационарного состояния, сколько затягивание неизбежного. Рациональные функции, используемые в качестве преобразований, — лишь один из способов замедлить процесс деградации информации, временно сдерживая поток неопределенности. Гарантированная сходимость, о которой идёт речь, — это не абсолютная победа над временем, а лишь локальное снижение налога за каждый запрос, за каждый акт наблюдения.
Очевидным направлением дальнейших исследований представляется ослабление предположений об идентифицируемости. Реальные системы редко подчиняются идеализированным уравнениям. Более того, сама концепция «истинного» решения может быть иллюзорной. Вместо того чтобы стремиться к однозначному восстановлению законов, стоит сосредоточиться на построении робастных моделей, способных адаптироваться к неполноте и шуму данных. Стабильность — это иллюзия, кэшированная временем, и любая попытка её удержать обречена на провал.
В конечном счёте, задача восстановления уравнений в частных производных сводится к управлению потоком информации. Каждый акт наблюдения вносит возмущение, каждый алгоритм — искажение. Задача исследователя — не остановить этот процесс, а научиться извлекать из него пользу, позволяя системе эволюционировать достойно, даже в условиях неизбежной деградации.
Оригинал статьи: https://arxiv.org/pdf/2602.15603.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусственный интеллект, действующий по цели: эволюция архитектуры
- Нейросеть предсказывает сродство антител к COVID-19
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Понимание видео: новый вызов для искусственного интеллекта
- От основ к интеллекту: как объединить машинное обучение и большие языковые модели
- Квантовые сети под контролем: новая библиотека для моделирования гибридных схем
- Визуальная навигация по множеству изображений: новый подход с использованием больших языковых моделей
2026-02-18 19:53