Автор: Денис Аветисян
Новое исследование ставит под сомнение способность разреженных автокодировщиков извлекать значимые признаки, показывая, что они могут достигать высокой производительности реконструкции, не превосходя случайные модели.
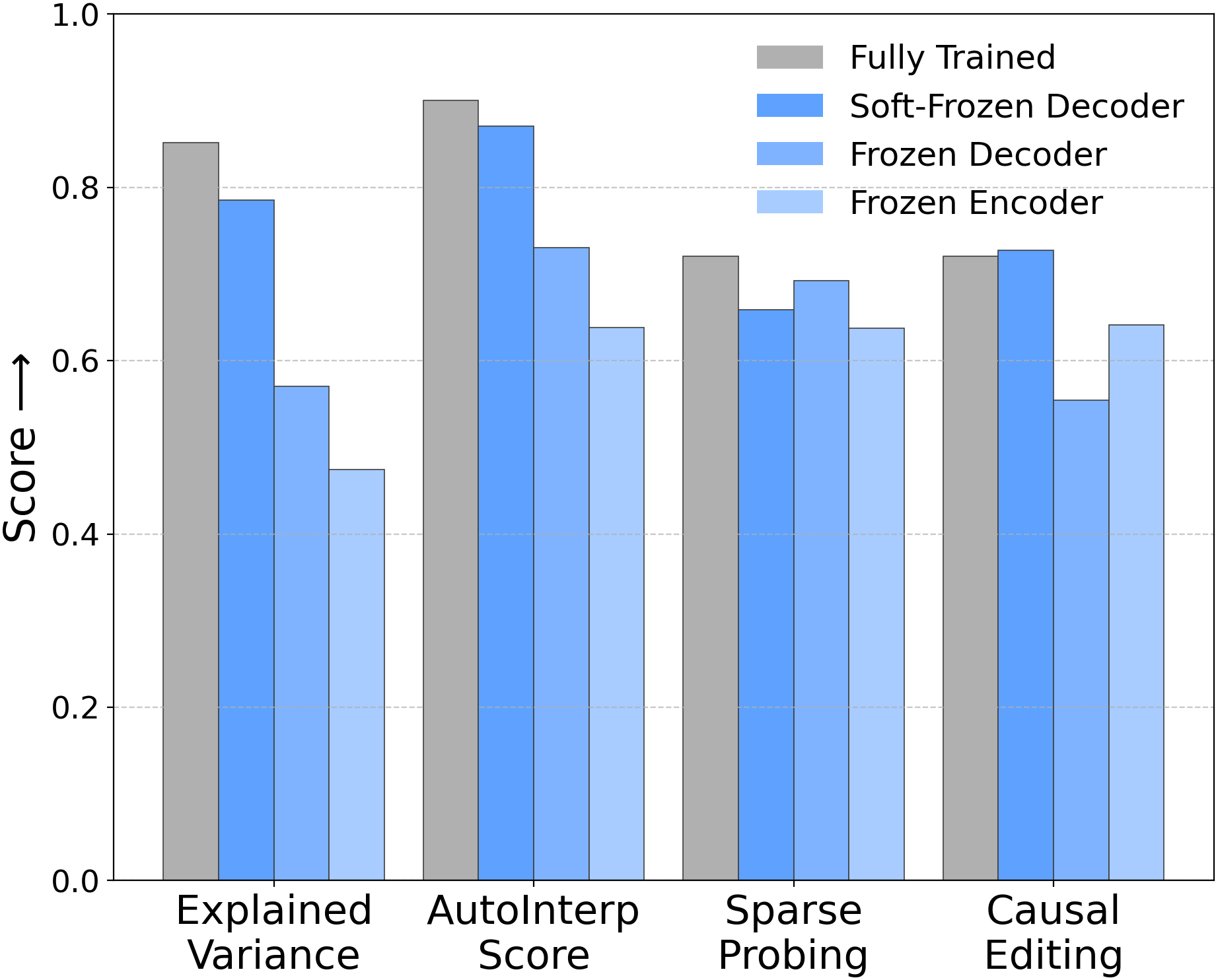
Работа демонстрирует, что разреженные автокодировщики часто достигают высокой точности реконструкции и кажущейся интерпретируемости, не обучаясь при этом осмысленным представлениям, а по своим характеристикам сравнимы со случайными моделями.
Несмотря на растущий интерес к интерпретируемым методам анализа нейронных сетей, остается неясным, действительно ли извлекаемые признаки отражают истинные внутренние механизмы моделей. В работе ‘Sanity Checks for Sparse Autoencoders: Do SAEs Beat Random Baselines?’ авторы проводят всестороннюю проверку разреженных автокодировщиков (SAE), популярных инструментов для декомпозиции активаций. Полученные результаты показывают, что SAE часто достигают высокой точности реконструкции и кажущейся интерпретируемости, не превосходя при этом случайные базовые модели по ключевым показателям, таким как точность определения истинных признаков и эффективность редактирования. Могут ли существующие SAE надежно раскрывать внутреннюю логику сложных нейронных сетей, или необходимы принципиально новые подходы к интерпретируемому машинному обучению?
Разоблачение Сложности: Обещание Разреженных Автокодировщиков
Несмотря на впечатляющую эффективность, плотные нейронные сети часто сталкиваются с проблемой избыточности представлений. Вместо того чтобы выделять наиболее значимые признаки, они активируют множество нейронов для кодирования информации, что приводит к неэффективному использованию вычислительных ресурсов и затрудняет понимание логики работы сети. Этот феномен снижает интерпретируемость моделей, поскольку сложно определить, какие именно признаки оказывают наибольшее влияние на принятие решений. Избыточные представления также могут приводить к переобучению, особенно при работе с ограниченными объемами данных, и снижать способность сети к обобщению на новые, ранее не встречавшиеся примеры. Таким образом, стремление к более компактным и значимым представлениям является ключевым направлением в развитии искусственного интеллекта.
В отличие от традиционных нейронных сетей, склонных к избыточному кодированию информации, разреженные автокодировщики (RAE) представляют собой эффективный метод извлечения наиболее значимых признаков из многомерных данных. Суть подхода заключается в обучении сети создавать сжатое, лаконичное представление входных данных, активируя лишь небольшое подмножество нейронов в скрытом слое. Этот процесс, подобно отбору ключевой информации, позволяет не только уменьшить вычислительную нагрузку, но и существенно повысить интерпретируемость полученных признаков. RAE способны выделять наиболее релевантные аспекты данных, представляя их в виде небольшого числа активных элементов, что облегчает понимание логики работы модели и позволяет выявлять скрытые закономерности в данных. Таким образом, разреженные автокодировщики открывают новые возможности для анализа и обработки сложных данных, предоставляя более понятные и эффективные модели.
Принцип работы разреженных автокодировщиков (RAE) находит параллели в эффективных стратегиях кодирования, используемых мозгом человека. Нейробиологические исследования показывают, что мозг не хранит информацию избыточно, а использует небольшое количество активируемых нейронов для представления сложных концепций. RAE, стремясь к подобной разреженности в представлениях данных, имитируют этот процесс, выделяя наиболее значимые признаки и игнорируя несущественные. Такой подход позволяет создавать более устойчивые и обобщающие системы искусственного интеллекта, поскольку они менее подвержены переобучению и лучше адаптируются к новым, незнакомым данным. В отличие от плотных нейронных сетей, RAE способны эффективно обрабатывать большие объемы информации, используя значительно меньше вычислительных ресурсов, что открывает перспективы для создания более энергоэффективных и масштабируемых AI-решений.

Установление Базы: Методы Оценки Разреженных Признаков
Для оценки эффективности разреженных автоэнкодеров (SAE) используются несколько базовых методов, включая конфигурации с фиксированным (замороженным) декодером и фиксированным (замороженным) энкодером. В конфигурации с фиксированным декодером веса декодера остаются неизменными в процессе обучения, что позволяет оценить вклад энкодера в процесс обучения разреженным представлениям. Аналогично, в конфигурации с фиксированным энкодером фиксируются веса энкодера, позволяя оценить влияние декодера. Эти конфигурации служат контрольными точками для сравнения с результатами, полученными при обучении всего автоэнкодера, и позволяют изолировать влияние отдельных компонентов на общую производительность.
Для оценки эффективности обучения разрешенным автоэнкодером (SAE) используются базовые методы, фиксирующие веса либо декодера, либо энкодера. Фиксация весов одного из компонентов позволяет создать контрольную группу, в которой влияние обучения SAE на конкретный компонент изолируется. Это достигается путем предотвращения обновления весов выбранного компонента во время тренировки, что позволяет оценить, насколько обучение SAE приводит к осмысленному обучению признаков по сравнению с ситуацией, когда веса остаются неизменными. Такой подход позволяет определить, действительно ли разреженность способствует улучшению представления данных или же наблюдаемые улучшения связаны с другими факторами.
Сравнение производительности разреженных автоэнкодеров (SAE) с базовыми моделями, в которых веса энкодера или декодера зафиксированы, позволяет оценить, действительно ли разреженность приводит к осмысленному обучению признакам. Если SAE демонстрирует значительное улучшение по сравнению с фиксированными конфигурациями, это указывает на то, что разреженность способствует извлечению и представлению более информативных признаков. Отсутствие существенной разницы, напротив, может свидетельствовать о том, что разреженность не оказывает значимого влияния на процесс обучения признаков, либо требует дальнейшей оптимизации архитектуры или параметров обучения. Анализ результатов сравнения позволяет определить, является ли разреженность эффективным методом для улучшения качества представления данных.

Архитектурные Вариации и Метрики Производительности
В рамках исследования были изучены различные варианты Автоэнкодера с разреженностью (SAE), а именно ReLU SAE, BatchTopK SAE и JumpReLU SAE. Каждый из этих вариантов использует уникальные механизмы для индуцирования разреженности в представлениях. ReLU SAE применяет функцию активации ReLU, что приводит к естественной разреженности за счет обнуления отрицательных значений. BatchTopK SAE, напротив, отбирает только K наибольших значений в каждом пакете, обнуляя остальные. JumpReLU SAE комбинирует ReLU с механизмом «jump connections», что позволяет модели игнорировать незначительные признаки и фокусироваться на наиболее важных, тем самым усиливая эффект разреженности.
Для оценки качества работы автоэнкодеров разреженности (SAE) использовались метрики Explained Variance и AutoInterp. Explained Variance количественно оценивает долю дисперсии исходных данных, воспроизведенную автоэнкодером, что отражает точность реконструкции. Полученные значения Explained Variance варьировались в диапазоне от 0.79 до 0.86, что свидетельствует о высокой способности моделей восстанавливать исходную информацию. Метрика AutoInterp, в свою очередь, измеряет интерпретируемость полученных представлений, отражая степень, в которой скрытые признаки соответствуют семантически значимым характеристикам данных.
Эксперименты, проведенные с использованием моделей Gemma-2-2B, Llama-3-8B и CLIP ViT-B/32, продемонстрировали эффективность предложенных архитектур на различных типах данных. В частности, архитектура Soft-Frozen Decoder SAE достигла показателя AutoInterp в 0.88, что свидетельствует о высокой степени интерпретируемости реконструированных данных. Данный результат подтверждает возможность применения данной архитектуры для анализа и обработки данных, представленных в различных модальностях, включая текст и изображения.

За Пределами Реконструкции: Зондирование для Выявления Причинно-Следственных Связей
Для оценки того, насколько извлеченные автоматическим энкодером (SAE) признаки отражают истинные причинно-следственные связи в данных, были применены методы разреженного зондирования (Sparse Probing) и каузального редактирования (Causal Editing). Эти техники позволяют изолировать и целенаправленно изменять отдельные признаки, что дает возможность оценить их влияние на последующие задачи. Разреженное зондирование выявляет, какие признаки наиболее важны для конкретных прогнозов, а каузальное редактирование позволяет проверить, действительно ли изменение определенного признака приводит к ожидаемому изменению в выходных данных, подтверждая тем самым его причинную роль. Такой подход позволяет выйти за рамки простой реконструкции данных и глубже понять, насколько хорошо SAE действительно «понимает» лежащие в их основе механизмы.
Для оценки влияния изученных признаков на решение задач, применялись методы разреженного зондирования и каузального редактирования. Эти техники позволяют изолировать и целенаправленно изменять отдельные признаки, что дает возможность проследить, как эти изменения сказываются на результатах работы модели. Анализ демонстрирует, что изменение определенных признаков приводит к предсказуемым изменениям в выходных данных, что подтверждает их важность для конкретных задач. Однако, в ряде случаев, манипуляции с признаками не оказывают ожидаемого эффекта, что указывает на необходимость дальнейшего изучения принципов формирования признаков и их связи с причинно-следственными связями в данных. Такой подход позволяет не только оценить значимость признаков, но и проверить, действительно ли они отражают фундаментальные свойства данных, а не являются просто побочными продуктами процесса обучения.
Исследования показали, что, несмотря на способность автоэнкодеров (SAE) эффективно восстанавливать данные, вопрос об их способности к выделению истинно причинных признаков остаётся открытым. Полученные результаты подтверждают гипотезу о “ленивой тренировке”, согласно которой SAE могут достигать хорошего восстановления, не изучая при этом глубокие причинно-следственные связи. В частности, замороженные SAE демонстрируют показатели RAVEL disentanglement в диапазоне 0.72-0.78, сопоставимые с полностью обученными моделями, а векторы декодера остаются близкими к начальным значениям, что подтверждается косинусным сходством ≥ 0.8. Эксперименты с синтетическими данными показали, что SAE способны восстановить лишь 9-71% истинных признаков, даже при высокой объясненной дисперсии, что указывает на ограниченность их способности к причинному моделированию.

Исследование демонстрирует закономерность, знакомую по другим сложным системам: кажущаяся эффективность не всегда свидетельствует о глубоком понимании. Авторы показывают, что разреженные автокодировщики (SAE) могут достигать высокой точности реконструкции, не обязательно извлекая значимые признаки. Это напоминает о неизбежной склонности систем к зависимости и уязвимости. Бертранд Рассел однажды заметил: «Всё, что кажется сложным, обычно является результатом простого нежелания понять». В данном случае, простота случайной инициализации может давать сопоставимые результаты, подчеркивая, что архитектурный выбор — это лишь пророчество о будущих сбоях, особенно если не уделяется должного внимания истинному обучению представлений, а лишь поверхностной оптимизации реконструкции.
Что Дальше?
Представленные результаты заставляют задуматься: стремление к интерпретируемости — это не поиск истины, а попытка наложить порядок на неизбежный хаос. Если разреженные автоэнкодеры достигают сопоставимой производительности с случайными моделями, то архитектурный выбор становится не инструментом построения, а пророчеством о будущей ошибке. Упор на высокую точность реконструкции, без глубокого понимания лежащих в основе представлений, — это гарантия не успеха, а лишь иллюзия стабильности, хорошо закэшированная в метриках.
Будущие исследования должны сместить фокус с оптимизации метрик на понимание природы этих «случайных» представлений. Какова их устойчивость к возмущениям? Как они обобщаются на новые данные? Попытки «научить» модель — наивны. Необходимо изучить, как системы самоорганизуются в условиях неопределённости, как проявляется информация в шуме. Ведь хаос — это не сбой, а язык природы.
Возможно, истинный прогресс лежит не в создании более сложных архитектур, а в принятии фундаментальной неопределенности. Гарантии — это договор с вероятностью, и наилучшая стратегия — это не их поиск, а подготовка к неизбежному. Разреженные автоэнкодеры, как и любые другие системы, — это не инструменты, а экосистемы, которые можно лишь выращивать, а не строить.
Оригинал статьи: https://arxiv.org/pdf/2602.14111.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Погода под контролем: Квантово-классическое моделирование для точного прогнозирования
- Квантовый щит для искусственного интеллекта
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Искусство синтеза: Новая модель для объединения текста и изображений
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Искусство по запросу: Как нейросети учатся понимать ваш вкус
- Квантовый код: Слияние классики и управления
2026-02-19 03:53