Автор: Денис Аветисян
Исследователи предлагают инновационный подход, позволяющий моделям самостоятельно улучшать свои ответы, используя цепочку рассуждений и итеративную доработку.
Представлен UniT — унифицированный фреймворк для масштабирования мультимодальных моделей в процессе тестирования с использованием цепочки рассуждений и синтеза данных.
Несмотря на успехи унифицированных моделей в обработке мультимодальной информации, их способность к итеративному уточнению результатов оставалась ограниченной. В работе ‘UniT: Unified Multimodal Chain-of-Thought Test-time Scaling’ представлен новый подход, позволяющий унифицированным моделям применять цепочку рассуждений (Chain-of-Thought) во время тестирования для последовательного улучшения ответов. Ключевым результатом является демонстрация возможности масштабирования производительности мультимодальных моделей за счет итеративного уточнения, что повышает эффективность при решении задач, требующих сложного пространственного анализа и редактирования. Каким образом подобные методы итеративного масштабирования могут быть расширены для создания более гибких и интеллектуальных мультимодальных систем?
Понимание сложности визуальных задач
Современные модели, объединяющие зрение и язык, зачастую сталкиваются с трудностями при выполнении задач, требующих сложного логического мышления и постепенной доработки результатов. Несмотря на впечатляющие успехи в распознавании объектов и понимании простых инструкций, они демонстрируют ограниченные возможности в ситуациях, где необходимо не просто идентифицировать элементы на изображении, но и анализировать их взаимосвязь, делать выводы на основе контекста и последовательно улучшать ответ, учитывая дополнительные детали или уточнения. Это особенно заметно в задачах, требующих композиционного анализа, планирования действий или решения проблем, где требуется не просто «увидеть», но и «понять» и «подумать» над представленной визуальной информацией.
Традиционные методы компьютерного зрения зачастую демонстрируют ограниченные возможности при решении задач, требующих последовательного анализа и интерпретации сложных инструкций. Ограничения проявляются в неспособности эффективно комбинировать различные визуальные элементы и понимать тонкие нюансы заданий, что существенно снижает применимость этих методов в реальных сценариях. Например, системы могут успешно распознавать отдельные объекты на изображении, но испытывают трудности при выполнении инструкций, требующих установить пространственные отношения между ними или учесть контекст. В результате, сложные визуальные задачи, такие как детальное описание сцены или выполнение многоступенчатых действий на основе визуальной информации, остаются серьезным вызовом для существующих алгоритмов и требуют разработки новых подходов, способных к более глубокому пониманию и рассуждению.
UniT: Агентный подход к масштабированию в процессе тестирования
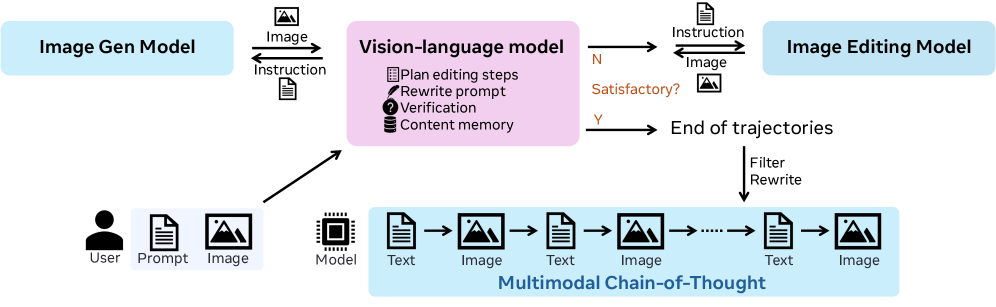
Фреймворк UniT использует агентный синтез данных для автоматической генерации обучающих данных, адаптированных к сложным задачам. Этот процесс предполагает использование автономных агентов, способных итерировать и улучшать данные на основе заданных критериев. Вместо ручной разметки, система самостоятельно создает и оптимизирует обучающий набор, что позволяет эффективно решать задачи, требующие значительного объема размеченных данных. Такой подход особенно полезен в ситуациях, когда получение размеченных данных затруднено или требует больших затрат времени и ресурсов, обеспечивая масштабируемость и адаптивность к новым задачам.
Синтез данных в UniT осуществляется посредством итеративного процесса критики и усовершенствования, в котором ключевую роль играют модели Flux Pro и Qwen3-VL. Flux Pro используется для генерации первичных данных, а Qwen3-VL применяется для оценки и критики этих данных, выявляя несоответствия и требующие улучшения аспекты. После анализа, данные перерабатываются и вновь оцениваются, формируя цикл обратной связи. Данный процесс повторяется до достижения требуемого уровня качества и соответствия поставленной задаче, обеспечивая высокую точность и надежность синтезированных данных для последующего обучения модели.
Архитектура UniT объединяет синтез данных, обучение модели и процесс инференса в единую систему. В качестве базовой модели используется Bagel, обеспечивающая основу для дальнейшей оптимизации и адаптации. Этот интегрированный подход позволяет UniT автоматизировать весь цикл — от генерации обучающих данных, необходимых для выполнения сложных задач, до обучения модели на этих данных и последующего использования обученной модели для решения этих задач. Интеграция процессов снижает необходимость ручной настройки и переключения между различными инструментами, повышая эффективность и скорость разработки.
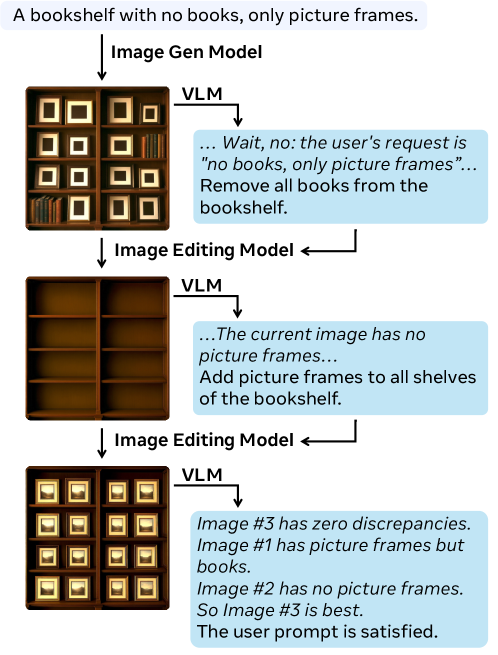
Для эффективной обработки сложных инструкций, фреймворк UniT использует декомпозицию задач на подцели и механизм Content Memory. Декомпозиция позволяет разбить сложную задачу на последовательность более простых, решаемых подзадач, что упрощает процесс планирования и исполнения. Content Memory обеспечивает сохранение и извлечение релевантной информации из предыдущих шагов выполнения, что позволяет модели учитывать контекст и избегать повторных вычислений или ошибок. Это достигается за счет хранения промежуточных результатов и знаний, полученных в процессе выполнения подзадач, и использования их для решения последующих подзадач или для уточнения общего плана действий. В результате, UniT способен последовательно и эффективно выполнять сложные инструкции, требующие многошагового рассуждения и учета контекста.

Масштабирование рассуждений с помощью алгоритмов, применяемых в процессе тестирования
Для повышения производительности модели используются методы масштабирования на этапе тестирования, включающие последовательное (Sequential Scaling) и параллельное (Parallel Scaling) масштабирование. Последовательное масштабирование подразумевает последовательное применение нескольких экземпляров модели к одному и тому же входному запросу, объединяя результаты для получения более точного ответа. Параллельное масштабирование, напротив, использует несколько экземпляров модели одновременно для обработки различных частей запроса или для генерации нескольких вариантов ответа, из которых затем выбирается оптимальный. Оба подхода позволяют динамически распределять вычислительные ресурсы в зависимости от сложности запроса и требуемого качества выходных данных.
Методы масштабирования во время выполнения позволяют динамически распределять вычислительные ресурсы в зависимости от сложности входных данных и требований к генерации. Этот подход предполагает, что более сложные запросы или сцены получают больше вычислительной мощности, что приводит к повышению качества выходных данных. Распределение ресурсов осуществляется на основе анализа входных данных и может включать в себя увеличение числа итераций, использование более сложных моделей или увеличение размера входных данных, обрабатываемых на каждом шаге. Такое интеллектуальное выделение ресурсов позволяет оптимизировать баланс между вычислительными затратами и качеством сгенерированных результатов, обеспечивая эффективное использование доступных ресурсов.
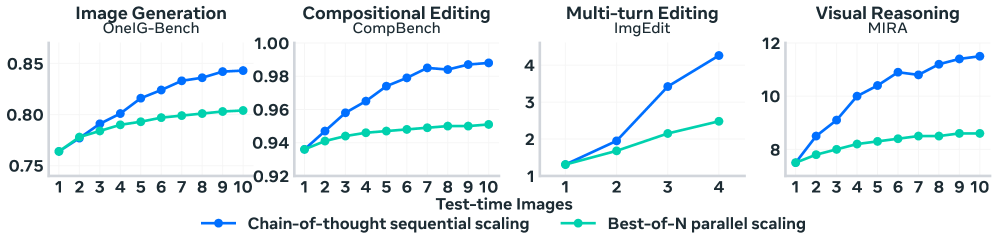
Эффективность предложенного фреймворка была подтверждена на стандартных бенчмарках, включая T2I-CoReBench. Результаты показывают улучшение на 10.34% в метрике OneIG-Bench, оценивающей генерацию изображений по одному запросу. В задачах многообъектного редактирования, оцениваемых CompBench, достигнуто увеличение производительности на 5.56%. При оценке качества многошагового редактирования изображений (ImgEdit) с использованием оценок пользователей, предложенный подход превзошел базовую модель на 2.95 баллов по шкале предпочтений.
Итеративный характер UniT обеспечивает возможность непрерывного улучшения качества работы модели. Этот подход позволяет последовательно совершенствовать логические рассуждения и визуальное понимание, что подтверждается результатом в 53.33% прироста эффективности при решении задач визуального рассуждения, оцениваемых с помощью MIRA (Multimodal Interactive Reasoning Assessment). Итеративный процесс позволяет модели последовательно анализировать и корректировать свои выводы, повышая точность и надежность результатов.

Влияние и перспективы развития
Новая архитектура UniT представляет собой перспективный путь к созданию более надежных и эффективных моделей, объединяющих зрение и язык. В отличие от традиционных подходов, UniT обеспечивает последовательную обработку информации, позволяя модели лучше понимать сложные инструкции и контекст визуальных данных. Это открывает возможности для решения задач, требующих глубокого понимания как изображений, так и текстовых описаний, таких как генерация детализированного контента по запросу или интеллектуальное редактирование изображений. Благодаря этому, UniT позволяет создавать системы, способные не просто распознавать объекты на картинке, но и интерпретировать их взаимосвязи и выполнять сложные операции на их основе, что значительно расширяет спектр применимости моделей компьютерного зрения и обработки естественного языка.
Предложенный подход открывает широкие перспективы для автоматизации создания контента, позволяя генерировать изображения и тексты, отвечающие сложным и детализированным запросам. В частности, становится возможным редактирование изображений не просто по общим критериям, а с учетом тонких нюансов, заданных пользователем. Это, в свою очередь, ведет к развитию систем, способных к продвинутому визуальному мышлению и решению задач, требующих понимания контекста и сложных взаимосвязей между изображениями и текстом. Такие системы могут быть использованы в самых разных областях, от создания персонализированного контента до помощи в научных исследованиях и разработке интеллектуальных помощников.
В дальнейшем планируется расширение возможностей разработанного фреймворка UniT, в частности, исследование новых подходов к агентному синтезу данных. Это предполагает создание систем, способных самостоятельно генерировать обучающие примеры, исходя из заданных целей и ограничений, что позволит значительно повысить эффективность обучения моделей и адаптировать их к новым задачам без необходимости в ручной разметке данных. Особое внимание будет уделено разработке алгоритмов, позволяющих агентам не только генерировать данные, но и оценивать их качество и релевантность, обеспечивая тем самым устойчивость и надежность получаемых результатов. Исследования в этой области открывают перспективы для создания самообучающихся систем, способных к непрерывному совершенствованию и адаптации к изменяющимся условиям.
Разработанная структура UniT демонстрирует значительные улучшения в вычислительной эффективности. В ходе исследований было установлено, что предложенный подход позволяет снизить вычислительные затраты в 2,5 раза по сравнению с методом параллельной выборки. Это достигается благодаря оптимизации процесса обработки данных и более рациональному использованию ресурсов. Такое существенное снижение затрат открывает возможности для применения модели на менее мощном оборудовании и для решения задач, требующих обработки больших объемов визуальной информации, делая передовые технологии компьютерного зрения более доступными и масштабируемыми.
Исследование, представленное в данной работе, демонстрирует, как итеративное уточнение ответов посредством цепочки рассуждений может значительно улучшить производительность мультимодальных моделей. Подобный подход к решению задач, требующих композиционного генерирования и визуального мышления, находит глубокий отклик в словах Фэй-Фэй Ли: «Искусственный интеллект должен быть построен на понимании, а не просто на распознавании образов». UniT, предлагая унифицированный фреймворк для последовательного совершенствования результатов, подчеркивает важность не просто получения ответа, но и понимания логики его формирования. Если закономерность нельзя воспроизвести или объяснить, её не существует — и именно это принцип лежит в основе эффективного применения цепочки рассуждений при масштабировании моделей во время тестирования.
Куда Ведет Этот Путь?
Представленная работа, демонстрируя возможности итеративного уточнения выводов в мультимодальных моделях, лишь приоткрывает завесу над сложной проблемой — истинным когнитивным способностям искусственного интеллекта. Успешное применение UniT, безусловно, обнадечивает, однако не стоит забывать о фундаментальном вопросе: является ли имитация “цепочки рассуждений” реальным пониманием, или лишь искусно замаскированным статистическим паттерном? Будущие исследования, вероятно, столкнутся с необходимостью разработки более строгих метрик оценки, способных отличить подлинное мышление от его убедительной симуляции.
Особый интерес представляет возможность применения UniT в условиях ограниченных данных. “Агентный синтез данных”, как описано в статье, выглядит перспективным, но не решает проблему предвзятости, заложенной в исходных данных. Неизбежно возникает вопрос: насколько “креативным” может быть искусственный интеллект, если его возможности ограничены рамками существующих знаний и предрассудков? Преодоление этого ограничения потребует, возможно, интеграции принципов обучения без учителя и активного исследования, а не простого повторения заученного.
В конечном счете, UniT — это не столько конечная точка, сколько отправная. Задача, стоящая перед исследователями, заключается не в создании все более сложных моделей, а в понимании того, что вообще означает “интеллект”, и как его можно объективно измерить. Ведь даже самая совершенная имитация, оставаясь лишь имитацией, не способна заменить истинное понимание.
Оригинал статьи: https://arxiv.org/pdf/2602.12279.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Квантовые Загадки: От Теории к Реальности
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Искусство синтеза: Новая модель для объединения текста и изображений
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Искусство по запросу: Как нейросети учатся понимать ваш вкус
- Погода под контролем: Квантово-классическое моделирование для точного прогнозирования
- Квантовый щит для искусственного интеллекта
2026-02-19 05:35