Автор: Денис Аветисян
Новая модель DreamZero позволяет роботам осваивать сложные задачи, используя лишь видеоданные и демонстрируя впечатляющую адаптивность к различным платформам.
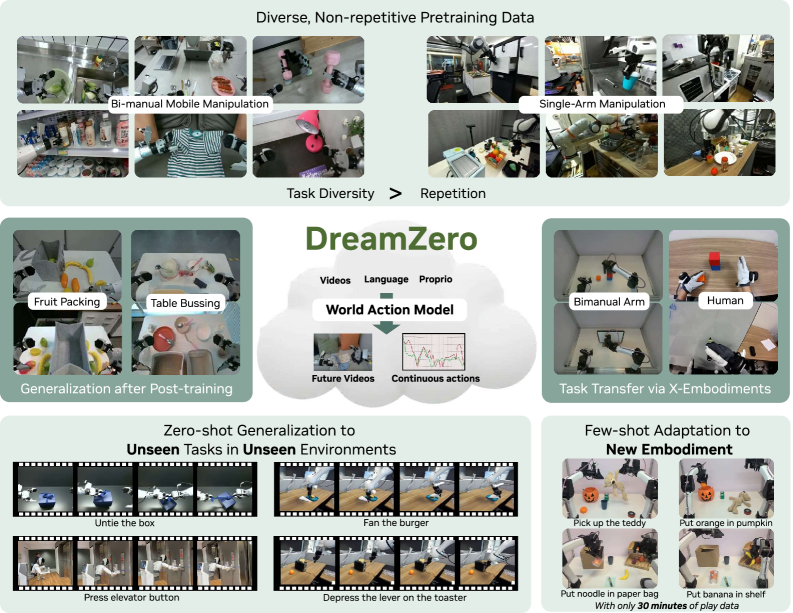
DreamZero — это фундаментальная модель для робототехники, основанная на видеодиффузии и обеспечивающая эффективную передачу навыков между различными типами роботов.
Несмотря на успехи современных моделей «Видение-Язык-Действие» в семантической обобщаемости, они испытывают трудности с переносом навыков на новые физические движения в незнакомых средах. В статье под названием ‘World Action Models are Zero-shot Policies’ представлена DreamZero — Мировая Модель Действий, построенная на базе предобученной диффузионной видео-модели. Этот подход позволяет моделировать динамику мира, предсказывая будущие состояния и действия, и демонстрирует более чем двукратное улучшение обобщающей способности по сравнению с существующими моделями в реальных робототехнических экспериментах. Сможет ли DreamZero стать основой для создания универсальных робототехнических систем, способных адаптироваться к новым задачам и окружениям с минимальным объемом данных?
Преодолевая горизонты предсказания: Взгляд за рамки традиционного моделирования
Традиционно, робототехника часто концентрируется на предсказании конкретных задач, что ограничивает способность роботов к обобщению и пониманию действий и их визуальных последствий. Вместо того, чтобы формировать общее представление о том, как действия изменяют окружающий мир, многие системы ограничиваются предсказанием ближайшего будущего для узкого набора заранее определенных сценариев. Такой подход приводит к хрупкости роботов в новых или незнакомых ситуациях, поскольку они не способны адаптироваться к непредвиденным изменениям. В результате, роботы часто нуждаются в повторном программировании или обучении для каждого нового задания, что снижает их эффективность и универсальность. Подобное ограничение связано с тем, что внимание уделяется исключительно предсказанию что произойдет, а не пониманию механизмов, лежащих в основе изменений, вызванных действиями.
Современные подходы к моделированию мира, использующие латентные пространства или облака трехмерных точек, зачастую испытывают трудности при захвате всей полноты визуальной информации и последовательности действий. Эти модели, несмотря на свою сложность, нередко упрощают визуальную реальность, теряя важные детали и контекст, необходимые для понимания не только что происходит, но и как действие влияет на окружающую среду. В результате, возникают проблемы с предсказанием долгосрочных последствий действий и созданием действительно связных и реалистичных сценариев взаимодействия с миром. Подобные ограничения препятствуют разработке роботов, способных к гибкому и адаптивному поведению в сложных, динамично меняющихся условиях.
Предлагается принципиально новая модель мира — World Action Model (WAM), которая знаменует собой отход от традиционного подхода к предсказанию будущего и переходит к моделированию того, как действия формируют окружающую действительность. Вместо того чтобы просто угадывать, что произойдет дальше, WAM стремится понять причинно-следственные связи между действиями и их визуальными последствиями. Этот подход позволяет не просто прогнозировать развитие событий, но и моделировать влияние различных действий на окружающую среду, что открывает новые возможности для разработки более гибких и адаптивных робототехнических систем. WAM представляет собой сдвиг парадигмы, позволяющий создавать системы, способные не только предвидеть, но и активно формировать будущее.
DreamZero: Фундаментальная модель робототехники, рожденная из диффузии
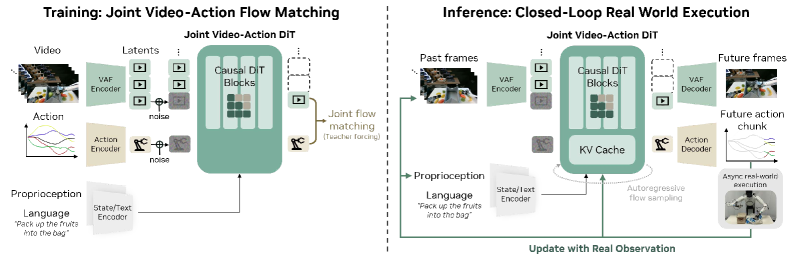
В основе DreamZero лежит предварительно обученная модель диффузии видео, позволяющая генерировать реалистичные и разнообразные визуальные прогнозы. Данный подход использует возможности диффузионных моделей в создании высококачественных видеоданных, что позволяет DreamZero предсказывать вероятные будущие состояния окружающей среды. Предварительное обучение на обширном наборе видеоданных обеспечивает высокую степень детализации и разнообразия генерируемых визуальных представлений, что критически важно для эффективного планирования действий робота в сложных и непредсказуемых условиях. Использование предварительно обученной модели значительно сокращает время и вычислительные ресурсы, необходимые для обучения системы прогнозированию визуальных сценариев.
В основе DreamZero лежит совместное предсказание видео и действий, которое устанавливает связь между визуальными результатами и соответствующими командами управления роботом. Эта система прогнозирует как будущие визуальные сцены, так и необходимые для их достижения моторные команды. В процессе обучения модель одновременно оптимизирует предсказание визуального потока и соответствующих действий робота, что позволяет ей генерировать последовательности действий, приводящие к желаемым визуальным состояниям. Совместное обучение позволяет модели учитывать взаимосвязь между визуальными целями и необходимыми движениями, повышая эффективность и точность планирования действий робота.
Авторегрессионная архитектура DreamZero обеспечивает плавность и связность движений робота, что критически важно для выполнения сложных задач. В данной архитектуре каждое последующее действие робота предсказывается на основе последовательности предыдущих состояний и предсказанных действий. Это позволяет модели учитывать динамику системы и генерировать траектории движений, избегающие резких изменений и обеспечивающие стабильность. Использование авторегрессии позволяет DreamZero прогнозировать не только положение и ориентацию робота, но и его скорость и ускорение, что обеспечивает более реалистичные и управляемые движения в сложных сценариях.
Модель DreamZero использует обратную динамику для планирования действий робота, основываясь на прогнозируемых визуальных результатах. В рамках этого подхода, модель обучается предсказывать необходимые моменты силы и крутящего момента (движения), которые приведут к желаемому визуальному состоянию. Это позволяет роботу не просто реагировать на текущую ситуацию, но и активно стремиться к достижению определенной цели, определяемой заданным визуальным будущим. Обучение происходит на основе данных, связывающих визуальные состояния с соответствующими действиями, что позволяет модели эффективно планировать и выполнять сложные последовательности движений, ориентированные на достижение конкретного визуального результата.
Перенос знаний и адаптация к новым воплощениям: Эволюция интеллекта
Модель DreamZero демонстрирует устойчивый перенос обучения между различными воплощениями, используя данные, собранные как от действий людей, так и от разнообразных робототехнических платформ. Это достигается за счет обучения на гетерогенном наборе данных, включающем визуальные и кинематические данные от людей и роботов, что позволяет модели обобщать знания о действиях и визуальном контексте независимо от конкретного воплощения. Использование данных от людей в качестве отправной точки позволяет ускорить обучение и повысить эффективность модели при адаптации к новым роботам, обеспечивая успешный перенос навыков между различными платформами.
Использование данных, полученных от людей, является ключевым фактором в процессе начальной настройки модели DreamZero. Данные о действиях и визуальном контексте, собранные от людей, позволяют модели сформировать базовое понимание взаимосвязи между визуальной информацией и соответствующими действиями. Этот подход позволяет значительно сократить объем данных, необходимых для обучения на роботах, поскольку модель уже обладает предварительным представлением о задачах и способах их выполнения. Фактически, человеческие данные служат отправной точкой для обучения, обеспечивая более эффективную и быструю адаптацию к новым робототехническим платформам и задачам.
Модель DreamZero демонстрирует способность к быстрой адаптации (few-shot adaptation) к новым робототехническим платформам, таким как робот YAM, используя ограниченное количество обучающих примеров. Это достигается за счет предварительного обучения на обширном наборе данных, включающем как человеческие демонстрации, так и данные, собранные с различных роботов. В результате, модель способна эффективно обобщать полученные знания и быстро приспосабливаться к новым задачам и роботам, требуя лишь минимального количества дополнительных данных для достижения приемлемой производительности. Данный подход существенно сокращает время и ресурсы, необходимые для развертывания системы управления роботами в новых условиях.
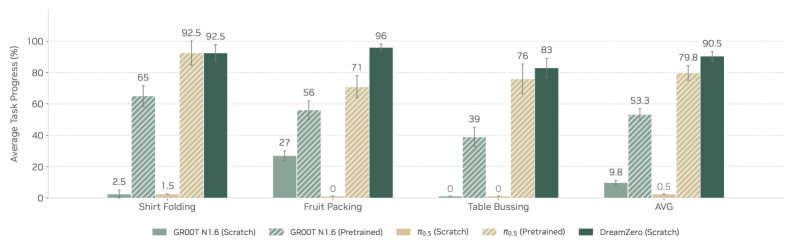
В ходе экспериментов DreamZero демонстрирует средний прогресс в решении новых задач на уровне 39.5%. Этот показатель более чем в два раза превышает результаты предварительно обученных моделей визуально-лингвистического анализа (VLA), которые достигают 16.3% прогресса. Полученные данные свидетельствуют о значительном улучшении способности DreamZero к обобщению и адаптации к неизвестным задачам по сравнению со стандартными подходами, использующими предварительно обученные VLA.
Модель DreamZero демонстрирует значительное улучшение производительности на новых, ранее не встречавшихся задачах, используя всего 10-20 минут данных для обучения. В частности, применение трансфера обучения между различными воплощениями (human-to-robot и robot-to-robot) позволяет достичь более чем 42%-ного относительного улучшения по сравнению с другими предобученными визуально-языковыми агентами (VLA). Это указывает на высокую эффективность трансфера знаний и способность модели быстро адаптироваться к новым роботам и задачам, даже при ограниченном объеме обучающих данных.
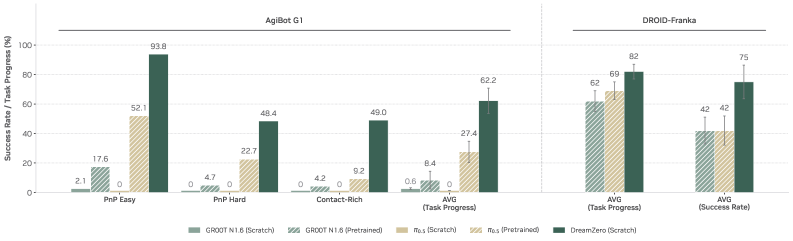
Ускорение вывода и масштабирование развертывания: Поднимая планку производительности
В рамках оптимизации скорости генерации видео, была разработана методика DreamZero-Flash, представляющая собой инновационный подход к разделению графиков добавления шума для видео- и активных компонентов. Традиционно, графики шума применялись единообразно ко всем элементам, что ограничивало возможности параллельной обработки и снижало общую скорость. DreamZero-Flash позволяет независимо оптимизировать графики шума для видеоряда и действий, что обеспечивает более эффективное распределение вычислительной нагрузки и ускоряет процесс инференса. Разделение графиков позволяет адаптировать процесс генерации к специфике каждого компонента, повышая качество и скорость создания реалистичных видеороликов. Данный подход открывает новые возможности для приложений, требующих высокой скорости генерации видео, например, для интерактивных систем и управления в реальном времени.
Для значительного увеличения скорости обработки видео и масштабирования развертывания, применялась методика системного параллелизма, позволяющая распределять вычислительные задачи между несколькими графическими процессорами. Вместо последовательной обработки каждого кадра одним GPU, вычисления разделяются и выполняются одновременно на нескольких устройствах, что существенно снижает общее время обработки. Такой подход позволяет эффективно использовать ресурсы аппаратного обеспечения и добиться линейного масштабирования производительности при добавлении новых GPU. Это особенно важно для задач, требующих обработки больших объемов данных в режиме реального времени, поскольку позволяет поддерживать высокую частоту кадров и обеспечивает плавное взаимодействие с пользователем.
Для эффективного развертывания моделей генерации видео на устройствах с ограниченными ресурсами, применяются методы квантизации. Данный подход позволяет значительно уменьшить размер модели и ее потребление памяти, не жертвуя при этом качеством генерируемых результатов. Квантизация подразумевает снижение точности представления весов и активаций нейронной сети, например, с 32-битных чисел с плавающей точкой до 8-битных целых чисел. Это приводит к пропорциональному уменьшению объема необходимой памяти и ускорению вычислений, что особенно важно для мобильных устройств или систем реального времени, где ресурсы ограничены. В результате, даже сложные модели генерации видео становятся доступными для развертывания на широком спектре платформ, открывая возможности для новых приложений и сервисов.
Для достижения максимальной производительности и эффективного использования ресурсов графического процессора, применялась тонкая настройка CUDA-ядер. Этот процесс включает в себя оптимизацию параметров, управляющих выполнением вычислений на GPU, что позволяет минимизировать задержки и повысить пропускную способность. Специалисты детально анализировали и корректировали такие аспекты, как организация памяти, параллелизм потоков и использование кэша, добиваясь наилучшего соответствия между вычислительной нагрузкой и архитектурой GPU. В результате, была достигнута максимальная утилизация графического процессора, что существенно повысило скорость обработки данных и позволило реализовать сложные алгоритмы в режиме реального времени.
Разработанная методика DreamZero-Flash демонстрирует впечатляющее ускорение процесса инференса в 38 раз, что позволяет достичь управления в реальном времени с частотой 7 Гц. Это значительное повышение производительности открывает новые возможности для интерактивных приложений и систем, требующих мгновенной реакции. Благодаря оптимизации алгоритмов и эффективному использованию вычислительных ресурсов, DreamZero-Flash позволяет обрабатывать сложные задачи генерации видео в режиме, близком к реальному, что ранее было недостижимо. Такой прогресс особенно важен для областей, где требуется высокая скорость обработки и мгновенная визуализация, например, в робототехнике, виртуальной реальности и автоматизированном управлении.
Исследование демонстрирует, что создание фундаментальных моделей, таких как DreamZero, основанных на видеодиффузии, открывает новые горизонты в области робототехники. Способность к обобщению и переносу навыков между различными воплощениями роботов подчеркивает важность построения систем, способных к адаптации и обучению на основе визуальной информации. Как однажды заметил Давид Гильберт: «Мы должны знать. Мы должны знать, что мы можем знать». Этот принцип находит отражение в стремлении создать роботов, способных понимать и взаимодействовать с миром посредством анализа визуальных данных, подобно тому, как человек воспринимает и осмысливает окружающую действительность. Основа, заложенная в DreamZero, позволяет преодолеть ограничения существующих моделей, обеспечивая более эффективный и гибкий подход к обучению роботов.
Куда Ведет Эта Дорога?
Представленная работа, по сути, обнажает очередную границу в освоении мира машинами. Создание DreamZero — не просто демонстрация возможности обучения роботов на видеоданных, это эксплойт понимания, позволяющий обойти традиционные ограничения, связанные с ручной разработкой политик. Однако, за кажущейся универсальностью кроется закономерный вопрос: насколько глубоко эта модель «понимает» физику взаимодействий, или же она оперирует лишь статистическими паттернами, ловко замаскированными под разумное поведение?
Истинный вызов лежит не в увеличении объемов данных или усложнении архитектуры, а в создании систем, способных к абстракции — к выделению фундаментальных принципов, лежащих в основе наблюдаемых явлений. Необходимо переходить от обучения «что делать», к обучению «почему это работает». Очевидным направлением является интеграция с моделями, способными к причинно-следственному анализу, и, возможно, даже к формированию внутреннего «представления о мире», пусть и далекого от человеческого.
Иронично, но, стремясь к созданию универсальных роботов, исследователи вновь и вновь сталкиваются с необходимостью «взломать» реальность, выявляя скрытые правила и закономерности. Истинный прогресс заключается не в создании идеальных симуляций, а в создании систем, способных адаптироваться к непредсказуемости окружающего мира, используя принципы обратной инженерии для постоянного улучшения своих моделей.
Оригинал статьи: https://arxiv.org/pdf/2602.15922.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусство синтеза: Новая модель для объединения текста и изображений
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Квантовые Загадки: От Теории к Реальности
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Диффузия и обучение с подкреплением: новый подход к масштабированию
- Квантовые алгоритмы против нейросетей: есть ли смысл в переходе?
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
2026-02-19 07:24