Автор: Денис Аветисян
Исследователи предлагают инновационный метод, использующий мощь больших языковых моделей для выявления причинно-следственных связей в данных.
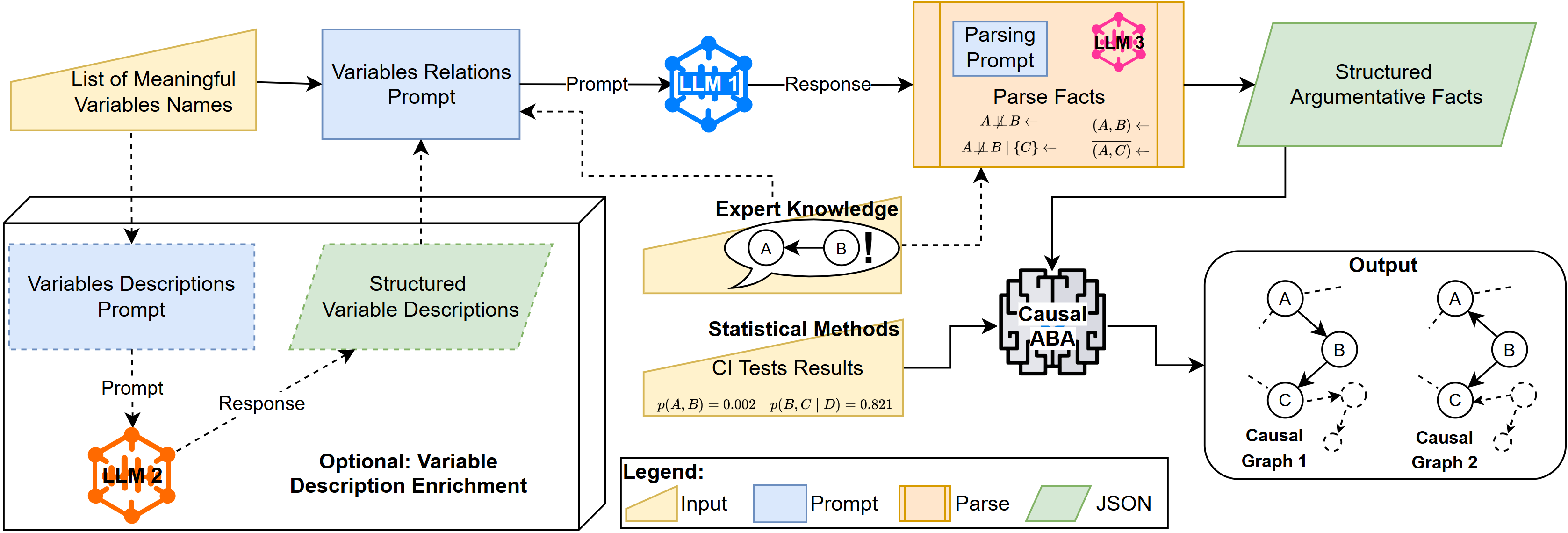
Предложенная методика объединяет генерацию причинных ограничений с помощью языковых моделей и аргументацию на основе ограничений (Causal ABA) для повышения точности и интерпретируемости анализа данных.
Поиск причинно-следственных связей в данных, несмотря на развитые статистические методы, часто требует привлечения экспертных знаний для построения адекватных моделей. В данной работе, ‘Leveraging Large Language Models for Causal Discovery: a Constraint-based, Argumentation-driven Approach’, предложен новый подход, использующий большие языковые модели (LLM) для генерации высокоточных причинных ограничений, интегрированных в систему аргументации на основе ограничений (Causal ABA). Это позволяет не только улучшить точность выявления причинно-следственных связей, но и повысить интерпретируемость полученных результатов. Возможно ли дальнейшее развитие данного подхода для автоматизации процесса выявления причинности в сложных системах и снижения зависимости от экспертных оценок?
Пределы Традиционного Выявления Причинности
Традиционные алгоритмы выявления причинно-следственных связей часто сталкиваются с трудностями при анализе сложных, многомерных данных, что приводит к появлению ложных корреляций. Это обусловлено тем, что при увеличении числа переменных возрастает вероятность обнаружения статистически значимых, но фактически случайных связей. Представьте себе поиск закономерностей в огромном наборе данных, где шум и случайные колебания могут легко маскировать истинные причинные связи. Алгоритмы, полагающиеся исключительно на статистическую независимость, не способны эффективно отфильтровать этот «шум», что приводит к выявлению фиктивных взаимосвязей, не отражающих реальные механизмы влияния. Таким образом, интерпретация результатов, полученных при анализе высокоразмерных данных с использованием традиционных методов, требует особой осторожности и критической оценки.
Основанные на проверках статистической независимости методы выявления причинно-следственных связей часто оказываются недостаточными при наличии скрытых вмешивающихся факторов или сложных петель обратной связи. В подобных ситуациях, когда переменные связаны не только прямыми причинными связями, но и общими, не наблюдаемыми причинами, стандартные тесты могут ошибочно указывать на ложные корреляции. Представьте, что наблюдается связь между продажами мороженого и количеством утоплений — стандартный анализ может увидеть корреляцию, но не учтет, что оба фактора зависят от третьей переменной — температуры воздуха. Более того, при наличии петель обратной связи, когда переменная влияет на другую, а затем возвращается обратно, определение направления причинности становится крайне затруднительным, поскольку стандартные тесты не способны различать, что является причиной, а что следствием. В результате, анализ, основанный исключительно на статистической независимости, может привести к неверным выводам о причинно-следственных связях и, следовательно, к неэффективным решениям.
Существующие методы выявления причинно-следственных связей зачастую страдают от неспособности эффективно интегрировать априорные знания и экспертные оценки, что существенно снижает точность и интерпретируемость полученных результатов. Вместо того чтобы использовать существующие данные как единственный источник информации, современные алгоритмы игнорируют ценный контекст, предоставляемый специалистами в конкретной области. Например, в медицинской диагностике, знание о распространенности определенных заболеваний или типичных симптомах могло бы значительно сузить пространство поиска причинно-следственных связей и избежать ложных корреляций. Ограниченность в использовании экспертных оценок приводит к тому, что алгоритмы часто выявляют статистически значимые, но биологически или физически неправдоподобные связи, требуя дополнительной ручной проверки и интерпретации, что значительно усложняет процесс анализа и снижает практическую ценность полученных результатов. Неспособность к интеграции априорных знаний является серьезным препятствием на пути к созданию надежных и интерпретируемых моделей причинно-следственных связей.
Внедрение Ограничений, Выведенных из Больших Языковых Моделей
Предлагается конвейер интеграции больших языковых моделей (LLM) в процесс обнаружения причинно-следственных связей, направленный на получение высокоточных ограничений. Данный конвейер позволяет использовать LLM для формулирования гипотез о зависимостях между переменными, которые затем могут быть проверены и использованы в алгоритмах обнаружения причинно-следственных связей. Внедрение LLM позволяет автоматизировать часть процесса, традиционно требующую экспертных знаний, и повысить эффективность выявления значимых причинно-следственных связей в данных. Выходные данные конвейера представляют собой набор ограничений, которые задают допустимые причинно-следственные структуры, сужая пространство поиска и облегчая идентификацию истинных причинно-следственных моделей.
Для повышения точности генерации причинно-следственных ограничений, процесс использует детальные описания переменных. Предоставление LLM подробной информации о каждой переменной, включая её определение и контекст, значительно улучшает понимание модели и направляет процесс генерации ограничений. Применение механизма консенсуса, основанного на агрегации нескольких ответов LLM, позволяет достичь точности до 1.0, стабилизируя выходные данные и снижая влияние случайности, присущей вероятностным языковым моделям.
Механизм консенсуса, применяемый к выводам больших языковых моделей (LLM), направлен на снижение влияния присущей им стохастичности и повышение надежности генерируемых ограничений. Суть подхода заключается в многократном запросе LLM для получения нескольких вариантов ответа на один и тот же вопрос, после чего применяется процедура агрегации, например, голосование или усреднение, для выявления наиболее согласованного и, следовательно, наиболее вероятного ответа. Это позволяет уменьшить вариативность результатов, вызванную случайными факторами, и получить более стабильные и воспроизводимые ограничения, необходимые для задач открытия причинно-следственных связей. Использование консенсуса существенно повышает доверие к ограничениям, полученным от LLM, особенно в ситуациях, когда требуется высокая точность и надежность.
CausalABA: Аргументационный Подход к Выявлению Причинности
CausalABA представляет собой аргументационную структуру, предназначенную для выявления причинно-следственных связей посредством комбинирования логического вывода и рассуждений, основанных на ограничениях. В основе подхода лежит построение аргументов, подтверждающих или опровергающих наличие причинной связи между переменными. Логический вывод используется для оценки валидности этих аргументов, а ограничения, заданные системой, направляют процесс поиска, сужая область возможных причинно-следственных отношений. Данная комбинация позволяет CausalABA эффективно исследовать сложные системы и выявлять причинные связи, которые могут быть неявными или трудно обнаруживаемыми при использовании только одного из этих методов.
В основе CausalABA лежит использование D-разделения (D-separation) для оценки условной независимости переменных. Этот метод позволяет определить, являются ли две переменные независимыми друг от друга при условии знания значения третьей переменной или набора переменных. Процесс оценки условной независимости направляется ограничениями, предоставляемыми большой языковой моделью (LLM). LLM определяет, какие направления причинно-следственных связей следует учитывать, а какие исключить, что позволяет сузить пространство поиска и повысить эффективность выявления истинных причинно-следственных отношений. X \perp Y | Z означает, что X и Y условно независимы при условии Z. Таким образом, LLM выступает в роли эксперта, предоставляющего априорные знания для направления процесса D-разделения.
В основе CausalABA лежит возможность явного задания априорных знаний о причинно-следственных связях посредством указания как обязательных (required), так и запрещенных (forbidden) направлений причинности. Это позволяет исследователю или эксперту задать, какие связи должны быть обязательно учтены при построении графа причинности, а какие, напротив, исключены из рассмотрения, даже если статистический анализ мог бы предложить их. Такой подход повышает точность и интерпретируемость модели, особенно в случаях, когда доступные данные ограничены или зашумлены, и позволяет интегрировать существующие знания предметной области в процесс обнаружения причинно-следственных связей.
Надежная Оценка и Метрики Эффективности
Для обеспечения надежной оценки и контроля за влиянием скрытых факторов, были сгенерированы синтетические наборы данных с использованием платформы ‘Synthetic CauseNet Data’. Этот подход позволил создать контролируемые условия, в которых можно было точно оценить эффективность разработанного метода CausalABA в различных сценариях, включая сложные причинно-следственные связи. Использование синтетических данных гарантирует, что результаты оценки не искажены неконтролируемыми переменными, что критически важно для объективного сравнения с существующими методами и демонстрации преимуществ предложенного подхода в задачах обнаружения причинно-следственных связей.
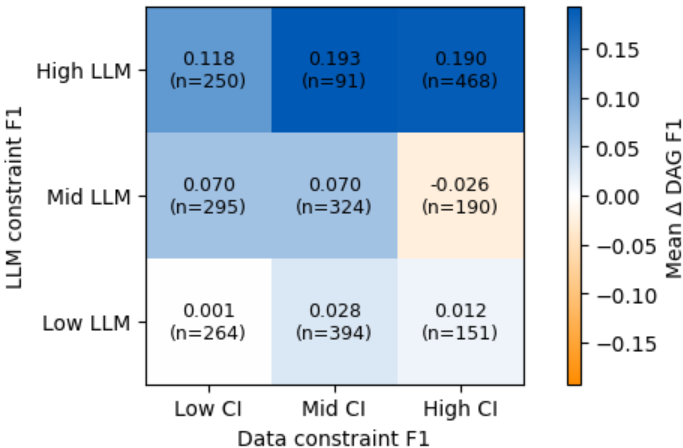
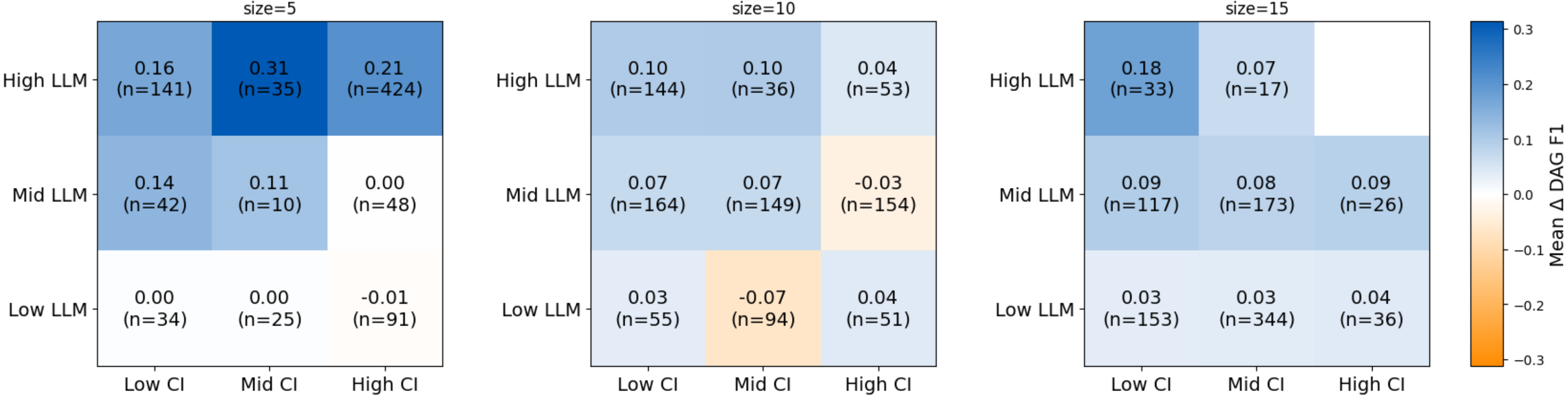
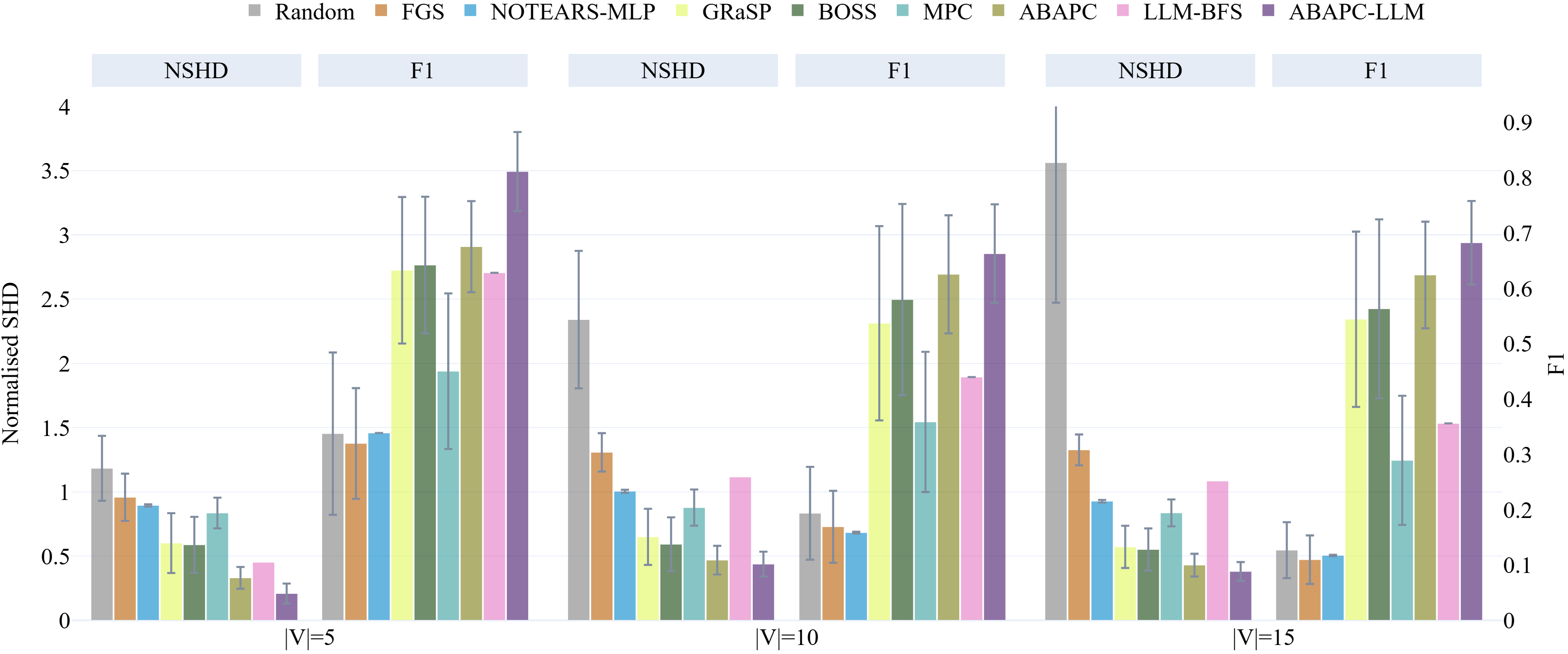
Для всесторонней оценки точности предложенного подхода использовались метрики F1-Score, Structural Hamming Distance и Structural Intervention Distance. F1-Score, являясь гармоническим средним между точностью и полнотой, позволяет оценить общую эффективность модели в выявлении причинно-следственных связей. В то время как Structural Hamming Distance и Structural Intervention Distance фокусируются на структурном сходстве между обнаруженной и истинной причинно-следственными моделями, что особенно важно для оценки способности алгоритма к корректному восстановлению структуры. Результаты показали, что предложенный метод демонстрирует наивысший наблюдаемый показатель F1-Score среди протестированных наборах данных, подтверждая его превосходство в определении причинно-следственных связей по сравнению с существующими подходами.
Исследования показали, что разработанный подход CausalABA демонстрирует значительное превосходство над существующими методами, особенно в задачах, связанных со сложными причинно-следственными связями. В ходе экспериментов, CausalABA последовательно достигал самых низких значений наблюдаемой Нормализованной Структурной Hamming Distance (NSHD) и Структурной Intervention Distance (SID) во всех протестированных наборах данных. Полученные результаты свидетельствуют о том, что данный подход обеспечивает более точное и надежное восстановление причинно-следственных структур, что особенно важно при анализе сложных систем, где традиционные методы могут оказаться неэффективными. Превосходство CausalABA подтверждается его способностью эффективно справляться с трудностями, возникающими при определении истинных причинно-следственных связей в условиях высокой сложности и взаимосвязанности данных.
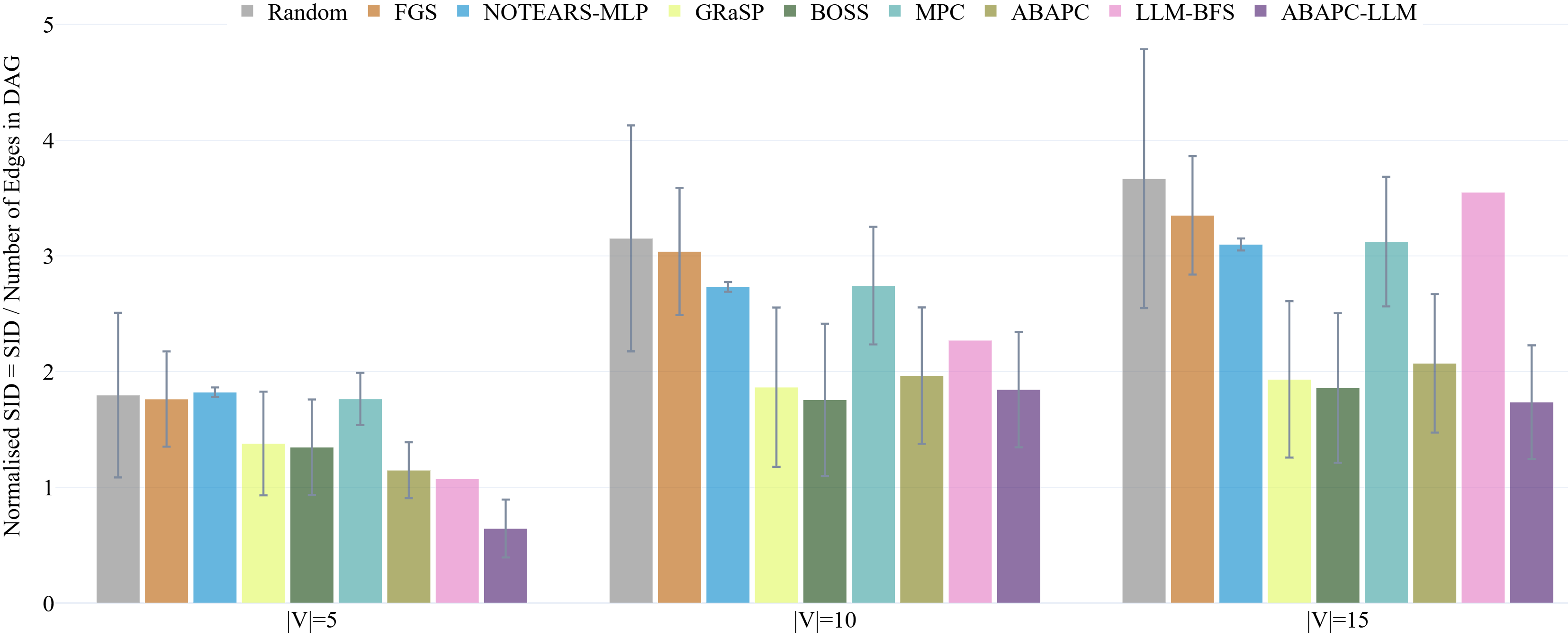
Представленное исследование демонстрирует стремление к математической чистоте в области обнаружения причинно-следственных связей. Авторы предлагают подход, в котором большие языковые модели генерируют высокоточные причинные ограничения, интегрируя их с аргументационным подходом, основанным на ограничениях (Causal ABA). Этот метод позволяет не только повысить точность обнаружения причинно-следственных связей из данных, но и улучшить интерпретируемость полученных результатов. Как однажды заметил Дональд Кнут: «Прежде чем оптимизировать код, убедитесь, что он работает правильно». В данном контексте, корректность алгоритма, выраженная в строгих причинных ограничениях, является фундаментом для любой дальнейшей оптимизации и интерпретации данных.
Куда двигаться дальше?
Представленная работа, хоть и демонстрирует потенциал использования больших языковых моделей для выявления причинно-следственных связей, не решает фундаментальную проблему — воспроизводимости. Если сгенерированные ограничения оказываются зависимыми от конкретной реализации языковой модели или случайной инициализации, то ценность полученных результатов стремится к нулю. Строгая формализация процесса генерации ограничений, возможно, с использованием методов доказательства корректности, представляется необходимой. Иначе, мы получаем не причинно-следственные связи, а лишь статистические артефакты, прикрытые словесной демагогией.
Особое внимание следует уделить проблеме масштабируемости. Применимость предложенного подхода к реальным, сложным системам, где число переменных и связей велико, вызывает обоснованные сомнения. Необходимо разработать методы, позволяющие эффективно обрабатывать большие объемы данных и уменьшать вычислительную сложность. В противном случае, мы рискуем остаться с элегантной, но бесполезной теорией.
Наконец, следует признать, что синтетическое генерирование данных, используемое в данной работе, является упрощением реальности. Реальные данные всегда зашумлены и неполны. Разработка методов, устойчивых к этим факторам, представляется критически важной задачей. В конечном счете, истинная проверка подхода заключается в его способности выявлять причинно-следственные связи в реальных, неидеальных данных.
Оригинал статьи: https://arxiv.org/pdf/2602.16481.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусство синтеза: Новая модель для объединения текста и изображений
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Квантовые Загадки: От Теории к Реальности
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Диффузия и обучение с подкреплением: новый подход к масштабированию
- Квантовые алгоритмы против нейросетей: есть ли смысл в переходе?
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
2026-02-19 09:08