Автор: Денис Аветисян
Новое исследование показывает, как агенты могут научиться сотрудничать, предсказывая действия других игроков в многоагентной среде.
Обучение последовательных моделей в разнообразных многоагентных средах способствует кооперативному поведению посредством обучения в контексте и своеобразной ‘предсказательной перформативности’.
Достижение кооперации между агентами, преследующими собственные интересы, остаётся сложной задачей в многоагентном обучении с подкреплением. В работе ‘Multi-agent cooperation through in-context co-player inference’ показано, что взаимное сотрудничество может возникать между агентами, учитывающими и формирующими динамику обучения своих партнёров. В отличие от существующих подходов, требующих жёстко заданных предположений об обучении соигроков или разделения временных масштабов, авторы демонстрируют, что возможности последовательных моделей к обучению в контексте позволяют учитывать динамику соигроков без явного кодирования правил или разделения масштабов. Это приводит к возникновению кооперативного поведения через механизм, в котором уязвимость к вымогательству стимулирует взаимное влияние на динамику обучения оппонента, открывая путь к масштабируемым алгоритмам обучения кооперативному поведению в децентрализованных системах.
Нестационарность: Искусство Адаптации в Мире Агентов
Традиционное обучение с подкреплением основывается на предположении о стационарности среды, то есть о её неизменности во времени. Однако, в сложных многоагентных системах это условие практически никогда не выполняется. Каждый агент, обучаясь и адаптируясь, изменяет своё поведение, что, в свою очередь, влияет на окружающую среду для других агентов. Таким образом, среда становится динамичной и непостоянной, представляя собой постоянный вызов для алгоритмов, разработанных для статических условий. Эта нестационарность требует от систем способности адаптироваться к меняющимся обстоятельствам и учитывать влияние действий других обучающихся агентов, что существенно усложняет процесс обучения и поиска оптимальных стратегий.
В системах, состоящих из множества обучающихся агентов, окружающая среда приобретает нестационарный характер. Это означает, что правила и динамика взаимодействия постоянно меняются по мере того, как каждый агент совершенствует свою стратегию. Традиционные алгоритмы обучения с подкреплением, разработанные для статических сред, оказываются неэффективными в таких условиях. Поскольку поведение одного агента влияет на поведение других, а их стратегии постоянно эволюционируют, среда становится непредсказуемой и нестабильной. Агенты, обученные на основе устаревших данных о среде, испытывают трудности с адаптацией к новым условиям, что приводит к снижению производительности и нестабильности системы в целом. Данное явление требует разработки новых методов обучения, способных учитывать и адаптироваться к динамично меняющейся среде, создаваемой взаимодействием обучающихся агентов.
Нестационарность в многоагентных системах возникает из-за непрерывной эволюции стратегий и политик каждого агента. По мере обучения агентов, их действия оказывают влияние на окружающую среду и поведение других агентов, что приводит к постоянному изменению оптимальных стратегий. Этот динамический процесс требует от алгоритмов обучения способности адаптироваться к меняющимся условиям, отказываясь от предположений о стационарности среды. Эффективные подходы к обучению в такой среде должны учитывать, что оптимальное решение сегодня может оказаться неоптимальным завтра, и обеспечивать непрерывную корректировку стратегий на основе получаемого опыта и изменений в поведении других агентов. В результате, алгоритмы должны быть способны не просто находить оптимальное решение, но и быстро приспосабливаться к его постоянному изменению, обеспечивая устойчивость и эффективность в долгосрочной перспективе.
Последовательные Модели: Ключ к Адаптивности Агентов
Агенты, основанные на последовательных моделях, использующих архитектуры, такие как Transformers, представляют собой эффективный подход к моделированию последовательных взаимодействий. Transformers, в отличие от рекуррентных нейронных сетей, позволяют параллельно обрабатывать всю последовательность данных, значительно ускоряя обучение и вывод. Это достигается за счет механизма внимания (attention), который позволяет модели взвешивать важность различных частей последовательности при принятии решений. Архитектура Transformer, изначально разработанная для обработки естественного языка, оказалась применимой и к другим типам последовательных данных, включая данные, возникающие в игровых взаимодействиях и робототехнике, обеспечивая возможность моделировать сложные зависимости и контекст в последовательностях действий.
Агенты, основанные на последовательных моделях, используют историю взаимодействия для вывода стратегий оппонента и прогнозирования будущих состояний игрового процесса. Это достигается путем анализа последовательности действий, предпринятых как самим агентом, так и противником, что позволяет выявлять закономерности и тенденции в поведении оппонента. Полученная информация используется для формирования более обоснованных решений, оптимизирующих стратегию агента и повышающих его эффективность в динамичной среде взаимодействия. Использование исторических данных позволяет агенту адаптироваться к изменяющемуся поведению оппонента и предвидеть его дальнейшие действия, что приводит к более эффективному принятию решений.
Реализация моделей последовательностей, особенно сложных архитектур, таких как Transformers, требует значительных вычислительных ресурсов. Библиотеки высокопроизводительных вычислений, такие как JAX, позволяют эффективно обучать и развертывать эти модели благодаря автоматической дифференциации, компиляции для различных аппаратных платформ (CPU, GPU, TPU) и поддержке векторизации. JAX обеспечивает возможность параллельных вычислений и оптимизированную работу с тензорными данными, что существенно сокращает время обучения и повышает производительность при развертывании модели в реальных условиях. Это особенно важно для приложений, требующих обработки больших объемов данных и быстрой реакции, например, в задачах моделирования поведения агентов и прогнозирования последовательностей.
Предсказательное Улучшение Стратегии и Обучение с Учетом Соигроков
Использование предсказательного улучшения стратегии позволяет агентам совершенствовать свои действия, основываясь на прогнозируемых реакциях оппонентов. Этот подход предполагает построение модели поведения соперника и оптимизацию собственной стратегии с учетом ожидаемых ответов. Агент анализирует возможные действия оппонента и выбирает действия, которые максимизируют его собственную выгоду в каждом сценарии. В результате, стратегия агента становится адаптивной и учитывает динамику взаимодействия с другими игроками, позволяя ему более эффективно достигать своих целей в игре.
Возможность агентов демонстрировать обучение в контексте и развивать осведомленность о ко-игроках является ключевым фактором для улучшения стратегий. Обучение в контексте позволяет агенту адаптировать свое поведение на основе текущих наблюдений за действиями противника, без необходимости явного переобучения модели. Осведомленность о ко-игроках подразумевает способность агента моделировать поведение других игроков и предсказывать их будущие действия, что позволяет оптимизировать собственную стратегию с учетом вероятных реакций. Данный подход позволяет агентам динамически корректировать свои действия в процессе взаимодействия, что существенно повышает их эффективность в сложных игровых ситуациях.
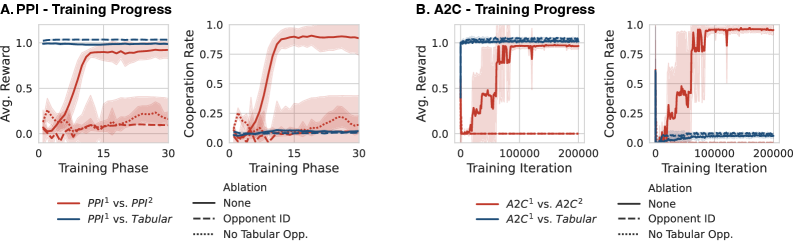
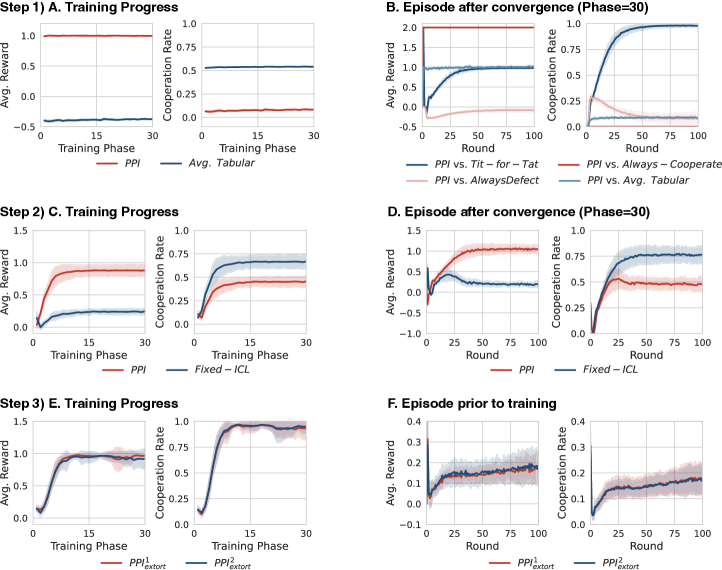
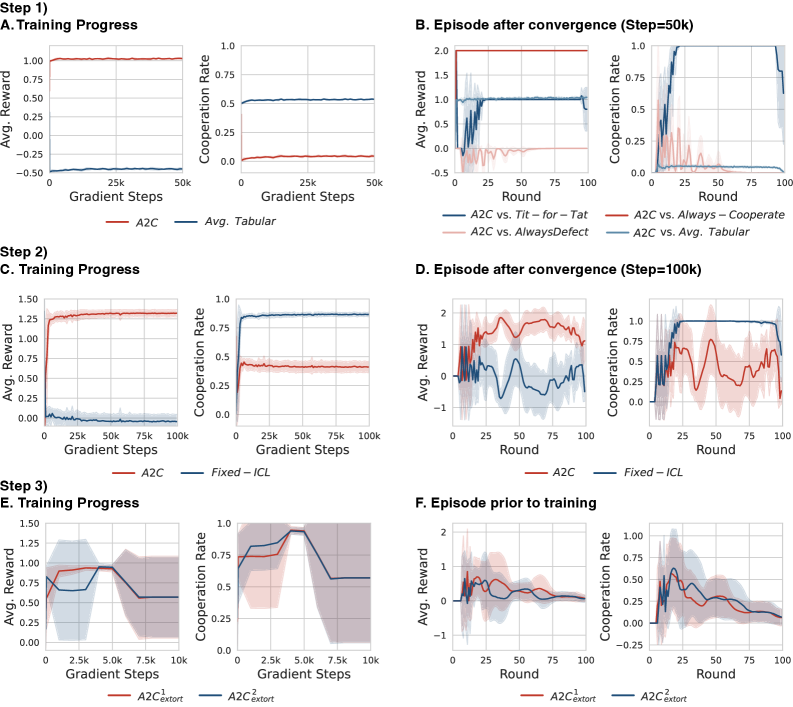
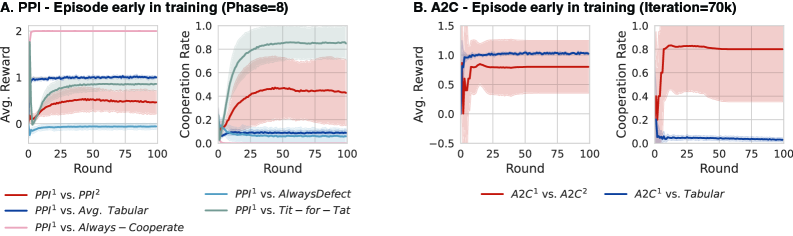
В представленной работе алгоритм Predictive Policy Improvement (PPI) демонстрирует сходимость к субъективному встроенному равновесию (Subjective Embedded Equilibrium), являющемуся ключевым понятием в теории игр. Субъективное встроенное равновесие представляет собой состояние, в котором стратегия агента является оптимальной, учитывая его представления о стратегиях других игроков и их ожидаемых ответах. Достижение данного равновесия подтверждается экспериментально и теоретически, что свидетельствует об эффективности PPI в динамических игровых средах, где стратегии игроков могут изменяться со временем. Алгоритм обеспечивает сходимость даже в условиях неполной информации и асимметричных игровых ситуациях, что делает его применимым к широкому спектру задач.
Эмерджентное Сотрудничество: От Вымогательства к Взаимной Выгоде
Исследования показали, что агенты, способные предвидеть и реагировать на действия обучающихся противников, демонстрируют способность использовать уязвимости посредством стратегий вымогательства. Этот процесс начинается с выявления слабых мест в поведении оппонента и последующего использования их для получения выгоды, зачастую за счет другого агента. Способность к адаптации и прогнозированию позволяет им эффективно эксплуатировать эти уязвимости, максимизируя собственные вознаграждения. Эффективность таких стратегий заключается в постоянном анализе действий противника и корректировке собственного поведения для поддержания преимущества, что создает динамичную и конкурентную среду, где вымогательство становится эффективным инструментом для достижения целей.
Исследование показывает, что при взаимодействии нескольких агентов, стремящихся извлечь выгоду из эксплуатации уязвимостей друг друга, возникает парадоксальный эффект. Вместо бесконечной борьбы за ресурсы и доминирование, попытки взаимного вымогательства приводят к неожиданному результату — возникновению сотрудничества. Каждый агент, осознавая возможность быть эксплуатированным, склонен к компромиссам, что в итоге формирует стабильные, взаимовыгодные отношения. Этот процесс, хотя и начинается с эгоистичных побуждений, неожиданным образом приводит к возникновению коллективной выгоды и устойчивых стратегий, напоминающих равновесие Нэша, где ни одному участнику не выгодно отклоняться от выбранной стратегии.
Исследование демонстрирует, что агенты, обученные с использованием подхода «peer-to-peer interaction» (PPI), способны к проявлению кооперативного поведения. В процессе взаимодействия, даже при изначально склонных к эксплуатации стратегиях, агенты достигают стабильных состояний, аналогичных равновесию Нэша. Данный результат указывает на то, что в условиях многостороннего взаимодействия, стремление к односторонней выгоде парадоксальным образом приводит к формированию взаимовыгодных стратегий и устойчивых, предсказуемых результатов. Полученные данные позволяют предположить, что механизмы, лежащие в основе кооперации, могут возникать спонтанно, как следствие динамики взаимодействия, а не требовать заранее заданных правил или альтруистических мотивов.
Устойчивость Через Смешанное Обучение и Самообучение
Метод Mixed-Pool Training повышает устойчивость агентов за счет обучения в среде с разнообразным пулом противников, включающим как агентов, использующих табличные методы (например, Q-learning с таблицей состояний), так и агентов, использующих обучение с подкреплением (learning agents). Такой подход обеспечивает воздействие широкого спектра стратегий, предотвращая переспециализацию агента под конкретные сценарии и способствуя обобщению знаний на новые, ранее не встречавшиеся ситуации. В частности, столкновение с табличными агентами заставляет агента разрабатывать стратегии, эффективные против простых, но иногда неожиданных действий, в то время как взаимодействие с другими обучающимися агентами стимулирует адаптацию к более сложным и динамичным стратегиям.
Обучение агентов в среде с разнообразными стратегиями противников предотвращает переспециализацию и способствует обобщению. Когда агент сталкивается с широким спектром подходов, он вынужден разрабатывать более универсальные стратегии, устойчивые к различным тактикам. Это отличается от обучения против ограниченного набора агентов, где агент может адаптироваться к конкретным слабостям оппонентов, становясь уязвимым к новым или непредсказуемым стратегиям. Универсальность, достигнутая за счет обучения на разнообразном пуле противников, позволяет агенту успешно действовать в различных игровых сценариях и против ранее неизвестных стратегий, повышая его общую надежность и адаптивность.
Использование методов самообучения позволяет агентам извлекать знания из немаркированных данных, что значительно повышает эффективность обучения и адаптивность. В отличие от обучения с учителем, требующего больших объемов размеченных данных, самообучение позволяет агенту формировать внутреннее представление о структуре данных, предсказывая части входных данных на основе других. Это снижает зависимость от ручной разметки, позволяя агенту обучаться на значительно большем объеме данных и быстрее адаптироваться к новым, ранее не встречавшимся ситуациям. Примерами таких методов являются автоэнкодеры и предсказание вращения изображений, которые позволяют агенту изучать полезные признаки без явных указаний.
Исследование демонстрирует, что агенты, обученные предсказывать поведение других участников в сложной среде, способны к кооперации без явного программирования соответствующих механизмов. Этот подход, основанный на обучении с подкреплением и предсказании действий, напоминает глубокую интуицию Блеза Паскаля: “Человек — это тростник, самый слабый в природе, но он умеет мыслить.” Подобно тому, как человек способен к сложным умозаключениям, несмотря на свою хрупкость, и эти агенты демонстрируют способность к адаптации и сотрудничеству, основываясь на предсказании, а не на жестком коде. Способность к ‘performative prediction’, то есть предсказанию, которое само влияет на поведение других, является ключевым элементом, позволяющим агентам ‘взламывать’ систему взаимодействия и достигать равновесия, не требуя централизованного управления.
Что дальше?
Представленная работа демонстрирует, что кооперация может возникать как побочный эффект предсказания поведения других агентов, минуя необходимость в явном формировании стратегий взаимодействия. Однако, этот «побочный эффект» пока что проявляется в строго контролируемой среде. Следующим шагом представляется исследование устойчивости подобного поведения в условиях неполной информации, динамически меняющихся правил, и, что наиболее важно, в присутствии агентов, не обученных принципам предсказания. Ведь каждое исправление — это философское признание несовершенства.
Особый интерес представляет вопрос о масштабируемости. С увеличением числа агентов, сложность моделирования их поведения экспоненциально возрастает. Возможно, ключ к решению лежит не в более точных моделях, а в принципиально новых подходах к агрегации информации и принятию решений, возможно, основанных на принципах самоорганизации и emergent behavior. Правила существуют, чтобы их проверять.
В конечном счёте, успех подобного подхода зависит от способности системы адаптироваться к непредсказуемости. Понимание системы — значит взломать её, умом или руками. И пусть каждый «патч» — это признание несовершенства, именно в этом поиске, в этом непрерывном реверс-инжиниринге реальности, и заключается истинная ценность подобного рода исследований.
Оригинал статьи: https://arxiv.org/pdf/2602.16301.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Диффузия и обучение с подкреплением: новый подход к масштабированию
- Квантовые алгоритмы против нейросетей: есть ли смысл в переходе?
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
- Квантовый код: Слияние классики и управления
- Пишущий разум: Как ИИ меняет процесс создания текстов
- Эко-интеллект: Как сделать ИИ более экологичным
- Квантовый транспорт в сложных системах: новый подход к моделированию
2026-02-19 10:40