Автор: Денис Аветисян
Как алгоритмы самообучения с подкреплением позволяют большим моделям лучше понимать 3D-сцены и пространственные взаимосвязи.
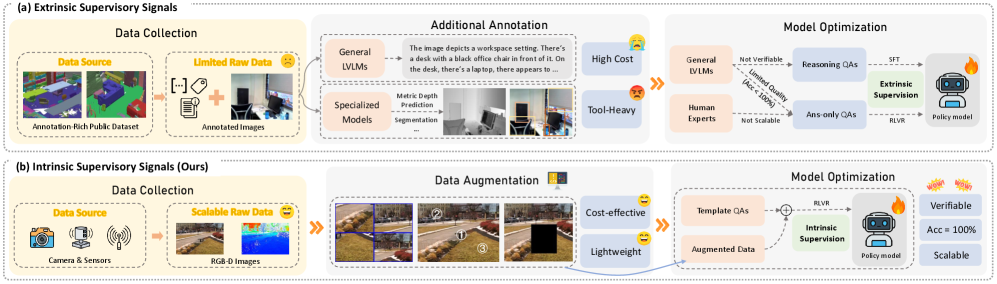
Новый подход Spatial-SSRL использует внутреннюю структуру изображений и проверяемые награды для улучшения пространственного мышления.
Несмотря на значительные успехи, пространственное понимание остаётся слабым местом больших визуально-языковых моделей. В данной работе представлена методология ‘Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning’, использующая самообучающееся обучение с подкреплением для улучшения способности моделей к анализу пространственных взаимосвязей. Разработанный подход Spatial-SSRL автоматически генерирует задачи, основанные на внутренней структуре изображений, обеспечивая проверяемые сигналы без необходимости ручной разметки или специализированных инструментов. Эксперименты на различных бенчмарках демонстрируют, что Spatial-SSRL позволяет добиться существенного прироста точности в задачах пространственного рассуждения, сохранив при этом общие визуальные возможности моделей. Можно ли масштабировать данную парадигму самообучения для создания более интеллектуальных и надёжных систем, способных эффективно взаимодействовать с окружающим миром?
Пространственное Рассуждение: Вызов для Визуально-Языковых Моделей
Крупномасштабные визуально-языковые модели (LVLM) демонстрируют впечатляющие возможности, однако испытывают трудности в задачах, требующих надежного пространственного рассуждения – критически важного компонента общего интеллекта. Отсутствие встроенного понимания пространственных отношений препятствует производительности в сложных визуальных задачах. Модели часто полагаются на корреляции в данных, а не на истинное понимание геометрии и физики окружающего мира. По мере увеличения объема данных, фундаментальное понимание пространства должно быть доказано, а не просто статистически обосновано.

Spatial-SSRL: Самообучение Пространственному Рассуждению
Spatial-SSRL использует самообучение, устраняя необходимость в дорогостоящих размеченных данных. В основе метода лежит обучение с подкреплением (Reinforcement Learning) для LVLM, оптимизируемое на основе проверяемых наград за выполнение самообучающихся задач. Ключевыми задачами являются «Перестановка фрагментов», «Распознавание отраженных фрагментов» и «Восстановление обрезанных фрагментов», которые заставляют модель активно изучать и понимать пространственные отношения.

Проверка Spatial-SSRL на Различных Бенчмарках
Оценка Spatial-SSRL на бенчмарках Spatial457, 3DSRBench и QSpatial-plus продемонстрировала значительное увеличение производительности по сравнению с базовыми моделями. Тестирование на COCO Dataset, DIODE Dataset и MegaDepth Dataset подтвердило устойчивость и обобщающую способность метода. Кроме того, показано, что Spatial-SSRL эффективно расширяется для понимания эгоцентричного видео (VSI-Bench), обеспечивая среднее улучшение точности на 4.63% для модели 3B и 3.89% для модели 7B, в частности, улучшение на 12.37% на Spatial457 и 5.65% на VSI-Bench для модели 3B.

Расширение Горизонтов: Значение и Перспективы Развития
Spatial-SSRL представляет собой принципиально новый подход к обучению LVLM, снижая зависимость от ручной разметки и способствуя созданию более надежных и адаптивных моделей. Развитие способности к пониманию пространственных связей позволяет Spatial-SSRL достигать более высокой точности и надежности при решении сложных визуальных задач, актуальных для робототехники и понимания сцен. Перспективными направлениями являются масштабирование Spatial-SSRL для работы с более крупными моделями, такими как Qwen2.5-VL-7B, а также изучение его потенциала в области мультимодального рассуждения и воплощенного искусственного интеллекта.

Исследование, представленное в данной работе, демонстрирует стремление к фундаментальному пониманию пространственного мышления, что находит отклик в словах Эндрю Ына: «Если мы хотим создавать действительно интеллектуальные системы, нам нужно научить их учиться». Spatial-SSRL, используя самообучение с подкреплением и проверяемые награды, представляет собой попытку построить алгоритм, который не просто «работает на тестах», но и обладает устойчивостью к изменениям и обобщениям. Пусть N стремится к бесконечности — что останется устойчивым? В данном случае, это способность модели к пространственному рассуждению, основанная на внутренней структуре изображения и принципах самообучения. Подход, описанный в статье, не просто улучшает результаты на существующих бенчмарках, но и приближает нас к созданию систем, способных к истинному пониманию окружающего мира.
Что Дальше?
Представленная работа, безусловно, демонстрирует прогресс в области пространственного понимания, однако не следует поддаваться иллюзии полного решения. Достижение «существенных улучшений» на наборе тестов – это лишь приближение к истине, а не её окончательное отражение. Суть проблемы не в увеличении числа правильно отвеченных вопросов, а в создании алгоритма, способного к обоснованному пространственному мышлению, а не просто к сопоставлению образов.
Очевидным направлением дальнейших исследований является переход от эмпирической оценки «наград» к формальному доказательству их соответствия аксиомам геометрии и физики. Использование «внутренней структуры изображения» как источника сигналов – шаг верный, но требует строгого математического обоснования. Необходимо исключить возможность возникновения ложных корреляций, которые могут привести к ошибочным выводам.
В конечном итоге, истинный прогресс заключается не в увеличении масштаба моделей, а в повышении их дедуктивной способности. Создание алгоритма, который может логически обосновать свои пространственные умозаключения, – вот та задача, которая, в случае её решения, действительно заслуживает внимания. Пока же, следует относиться к достигнутым результатам как к промежуточному этапу на пути к этой цели.
Оригинал статьи: https://arxiv.org/pdf/2510.27606.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Динамика в кадре: Как научить ИИ понимать физику видео
- Самообучающиеся модели мира: логика и постоянное совершенствование
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Сердце музыки: открытые модели для создания композиций
- Многоязычны ли современные нейросети на самом деле?
- Музыкальный клип по запросу: Искусственный интеллект берется за режиссуру
- Матричное умножение: новый рекорд эффективности
- Точное моделирование протонной терапии: новый подход к расчетам дозы
- Квантовый свет: Когда лазер перестает быть экспериментом
2025-11-04 00:10