Автор: Денис Аветисян
Исследователи представили SLA2 — механизм разреженного линейного внимания, позволяющий значительно повысить скорость работы диффузионных моделей без потери качества генерируемых изображений и видео.
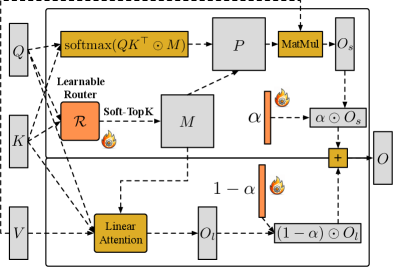
SLA2 использует обучаемый маршрутизатор, декомпозицию и квантизацию с учетом обучения для достижения высокой эффективности и сохранения качества.
Несмотря на успехи разреженных и линейных механизмов внимания в ускорении диффузионных моделей, их эффективность часто ограничивается эвристическими подходами к распределению вычислений. В данной работе, посвященной разработке ‘SLA2: Sparse-Linear Attention with Learnable Routing and QAT’, предложен новый механизм, сочетающий в себе разреженное и линейное внимание с обучаемым маршрутизатором и оптимизацией с учетом квантования. Ключевым результатом является достижение 97% разреженности внимания и 18.6-кратного ускорения вычислений при сохранении качества генерируемых видео. Возможно ли дальнейшее повышение эффективности и качества диффузионных моделей за счет более гибкого управления разреженностью и квантованием внимания?
Внимание: Предел масштабируемости полного внимания
Традиционные механизмы «полного внимания», несмотря на свою эффективность, сталкиваются с проблемой квадратичной сложности. Это означает, что объем вычислений и потребность в памяти растут пропорционально квадрату длины обрабатываемой последовательности. В результате, при увеличении длины текста или разрешении изображения, время обработки и требуемые ресурсы экспоненциально возрастают, что становится серьезным препятствием для применения этих механизмов в задачах, требующих анализа больших объемов данных. Например, обработка длинных текстов или изображений высокого разрешения может оказаться непосильной задачей для стандартных моделей, использующих «полное внимание», из-за чрезмерных вычислительных затрат и ограничений по памяти. Данное ограничение стимулирует поиск альтернативных, более эффективных механизмов внимания, способных масштабироваться для работы с большими объемами информации.
Вычислительная нагрузка, обусловленная квадратичной сложностью механизма полного внимания, представляет собой существенное препятствие для масштабирования трансформаторов при решении сложных задач. Обработка изображений высокого разрешения или анализ длинных текстовых последовательностей требуют огромного объема вычислений, которые быстро становятся непосильными для стандартных реализаций. Эта проблема ограничивает возможности трансформаторов в областях, где важна обработка больших объемов данных, таких как детальный анализ медицинских изображений, расшифровка генома или создание связных и длинных текстов. Вследствие этого, разработка более эффективных механизмов внимания становится ключевой задачей для дальнейшего развития и применения трансформаторов в различных областях науки и техники.
Развитие более эффективных механизмов внимания является ключевым фактором для раскрытия полного потенциала трансформаторных моделей. Существующие подходы, требующие квадратичных вычислительных затрат при обработке длинных последовательностей, становятся серьезным препятствием для применения в задачах, требующих анализа больших объемов данных, таких как высококачественная обработка изображений или глубокий анализ текста. Оптимизация внимания позволит значительно снизить вычислительную нагрузку, открывая возможности для создания более мощных и масштабируемых моделей, способных решать сложные задачи, ранее недоступные из-за ограничений ресурсов. Дальнейшие исследования в этой области направлены на разработку инновационных подходов, которые позволят сохранить высокую точность при значительном снижении вычислительной сложности, что станет важным шагом на пути к созданию искусственного интеллекта нового поколения.
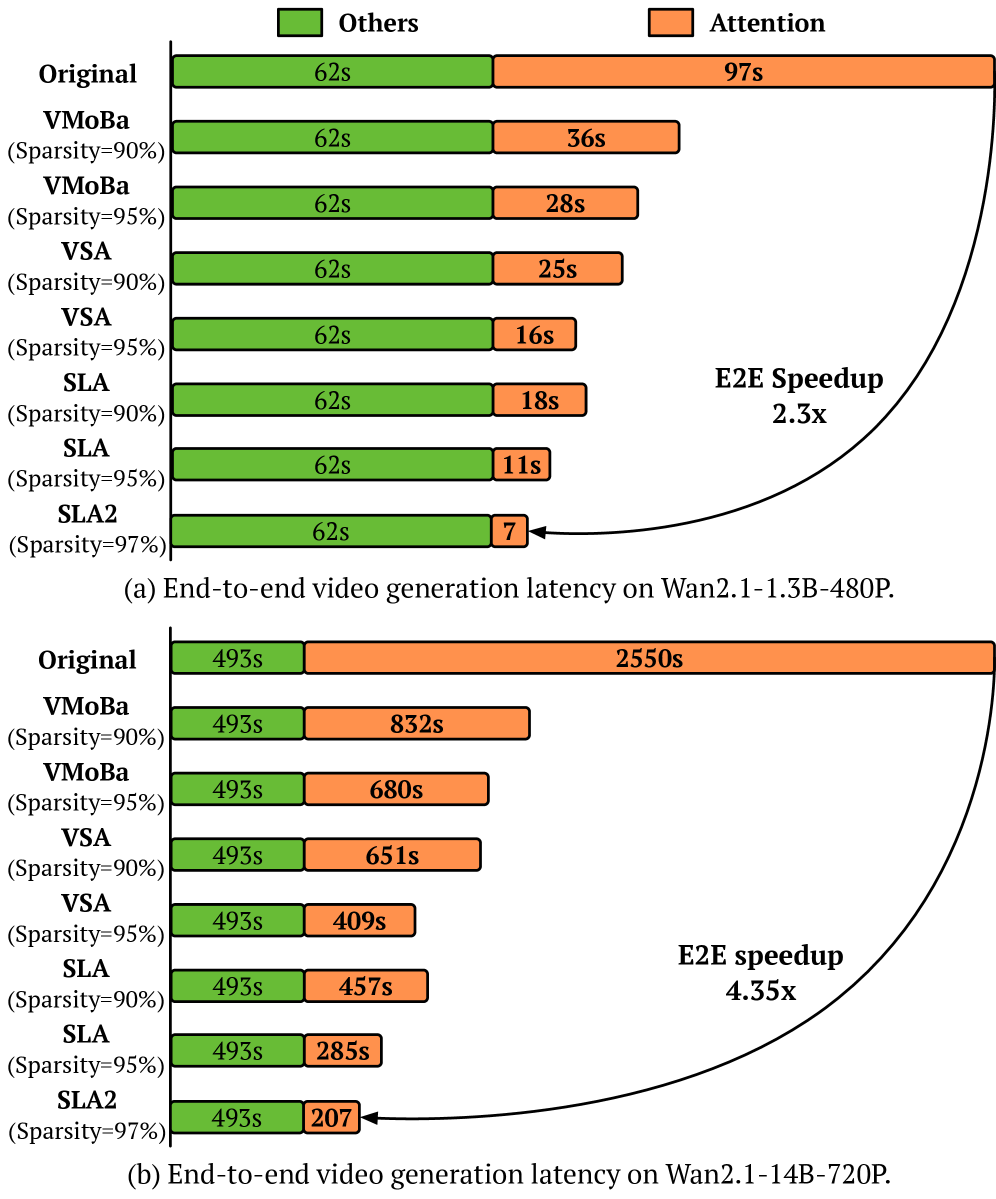
Разреженность как решение: К обучаемому разреженному вниманию
Методы обучаемого разреженного внимания (Trainable Sparse Attention) направлены на снижение вычислительных затрат за счет концентрации на наиболее релевантных связях внутри последовательности. В стандартном механизме внимания вычисления производятся для каждой пары элементов последовательности, что приводит к квадратичной сложности O(n^2), где n — длина последовательности. Обучаемые методы разреженного внимания, напротив, динамически определяют подмножество связей, требующих вычислений, игнорируя менее значимые. Это достигается посредством введения маски или весов, которые определяют, какие связи сохраняются, а какие отбрасываются. Выбор этих связей происходит в процессе обучения модели на основе данных, позволяя адаптироваться к специфике задачи и повысить эффективность вычислений, особенно для длинных последовательностей.
В отличие от методов разреженной связи с фиксированными паттернами, обучаемые методы разреженной связи динамически определяют значимые соединения в процессе тренировки модели. Это достигается за счет введения параметров, оптимизируемых вместе с остальными весами нейронной сети, что позволяет модели самостоятельно выявлять наиболее важные зависимости между элементами последовательности. В результате, модель адаптируется к конкретным данным и задаче, демонстрируя более высокую эффективность по сравнению с подходами, где паттерн разреженности задается заранее и остается неизменным на протяжении всего обучения. Такой подход позволяет более гибко использовать вычислительные ресурсы и улучшить обобщающую способность модели.
Методы разреженного внимания, основанные на интеллектуальной обрезке наименее значимых связей, позволяют существенно снизить требования к памяти и ускорить вычисления без значительной потери точности. Обрезка осуществляется путем определения и исключения из рассмотрения связей между элементами последовательности, которые вносят минимальный вклад в итоговый результат. В результате, уменьшается количество операций, необходимых для обработки последовательности, а также объем памяти, требуемый для хранения промежуточных результатов и весов модели. Эффективность данного подхода подтверждается экспериментальными данными, демонстрирующими снижение вычислительной сложности и потребления памяти при сохранении или даже улучшении метрик качества модели.
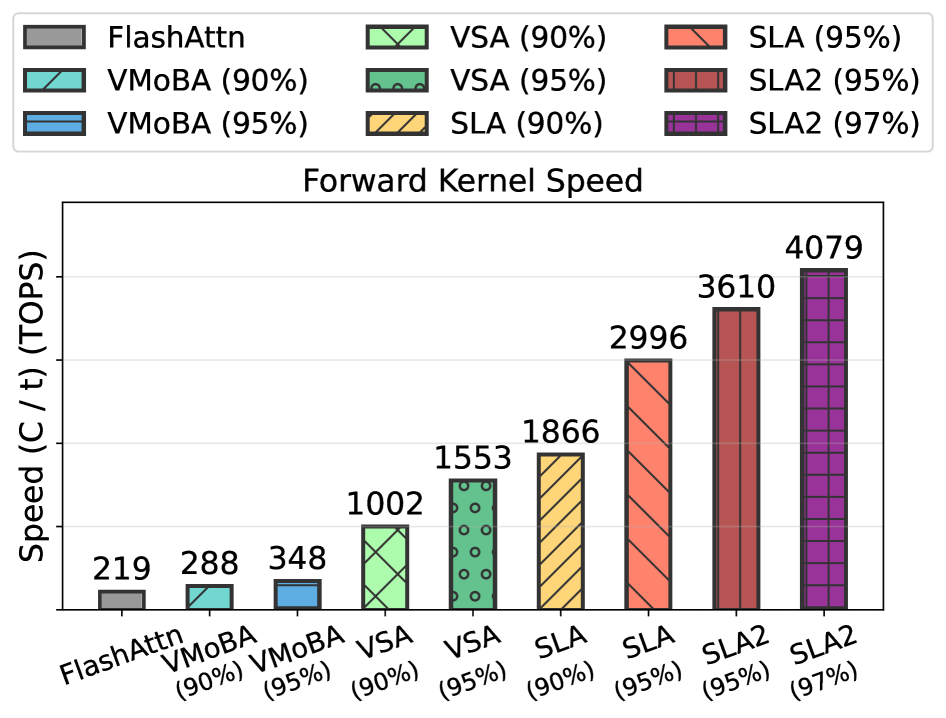
SLA2: Уточненный механизм разреженно-линейного внимания
Механизм SLA2 использует обучаемую разреженную маску внимания для динамического выбора релевантных связей, что является усовершенствованием по сравнению с более ранними методами разреженного внимания. В отличие от статических масок, которые фиксированно определяют структуру разреженности, обучаемая маска позволяет модели адаптировать паттерны внимания к конкретным входным данным. Это достигается путем обучения параметров маски в процессе тренировки, что позволяет SLA2 идентифицировать и усиливать наиболее важные связи между токенами, игнорируя менее значимые. Динамическая природа этой маски позволяет более эффективно использовать вычислительные ресурсы и снижает сложность вычислений внимания, сохраняя при этом высокую точность модели.
Механизм SLA2 использует декомпозицию внимания для анализа паттернов связей между элементами последовательности. Этот процесс позволяет выявить наиболее значимые зависимости, что, в свою очередь, способствует формированию более целенаправленных и эффективных соединений. Декомпозиция позволяет разложить матрицу внимания на компоненты, отражающие различные аспекты взаимосвязей, что обеспечивает более глубокое понимание структуры данных и, как следствие, оптимизацию процесса вычисления внимания. В результате, SLA2 способен фокусироваться на релевантных соединениях, минимизируя вычислительные затраты и повышая производительность.
Механизм SLA2 достигает 97% разреженности внимания, что позволяет существенно снизить вычислительные затраты и потребление памяти. Эксперименты показали, что SLA2 обеспечивает 18,6-кратное ускорение времени работы механизма внимания по сравнению с базовыми методами. Для дальнейшей оптимизации производительности SLA2 интегрирует такие техники, как FlashAttention, позволяющую минимизировать обращения к памяти, и low-bit attention, снижающую вычислительную сложность за счет использования низкоточных вычислений. Сочетание высокой разреженности и применения передовых методов оптимизации позволяет SLA2 значительно повысить эффективность обработки последовательностей.

Влияние и применение: Ускорение диффузионных моделей
Эффективность, демонстрируемая SLA2, особенно ярко проявляется при решении ресурсоемких задач, таких как обучение диффузионных моделей. Эти модели, активно используемые в генерации изображений, звука и других данных, требуют огромных вычислительных мощностей и больших объемов памяти. SLA2, оптимизируя процесс вычислений внимания, значительно снижает эту нагрузку, позволяя обучать более крупные и сложные диффузионные модели, ранее недоступные из-за ограничений ресурсов. Это открывает возможности для создания более реалистичных и детализированных генераций, а также ускоряет процесс обучения, делая передовые технологии машинного обучения более доступными и эффективными.
Снижение вычислительной нагрузки на механизм внимания, обеспечиваемое SLA2, открывает новые возможности для обучения диффузионных моделей, ранее ограничивавшихся ресурсами. Традиционно, вычислительные затраты, связанные с вниманием, становились узким местом при масштабировании моделей и увеличении их сложности. SLA2 позволяет преодолеть это ограничение, давая возможность исследователям создавать более крупные и детализированные модели, способные генерировать изображения и другие данные с беспрецедентным уровнем реалистичности и детализации. Это, в свою очередь, стимулирует прогресс в таких областях, как генеративное искусство, медицинская визуализация и разработка виртуальной реальности, где требуются сложные и высококачественные модели для создания убедительных и правдоподобных результатов.
В процессе обучения диффузионных моделей применение методов отбора, таких как Soft Top-k Selection и Top-k Selection, оказывает существенное влияние на стабильность и качество генерируемых результатов. Эти техники позволяют фокусироваться на наиболее значимых элементах данных, отсекая менее важные, что снижает вычислительную нагрузку и предотвращает переобучение. В частности, Soft Top-k Selection обеспечивает более плавный переход между элементами, смягчая резкие изменения в процессе обучения, в то время как Top-k Selection позволяет жестко ограничить количество рассматриваемых элементов, что способствует более быстрой сходимости и повышению точности. В результате, модели, обученные с использованием этих методов, демонстрируют улучшенную способность генерировать реалистичные и детализированные изображения, а также обладают повышенной устойчивостью к различным входным данным.

Исследование, представленное в данной работе, демонстрирует стремление к глубокому пониманию и переосмыслению базовых принципов работы систем внимания в диффузионных моделях. Авторы, подобно исследователям, вскрывающим сложный механизм, стремятся не просто оптимизировать существующие решения, но и выявить фундаментальные ограничения и возможности. Как однажды заметил Кен Томпсон: «Я думаю, что если бы люди понимали, как работают программы, они бы могли делать более интересные вещи с компьютерами». Это высказывание отражает суть представленной работы: детальное изучение и модификация механизма внимания (SLA2) для достижения значительных улучшений в скорости и эффективности, сохраняя при этом качество генерируемого видео. Внедрение разреженного внимания и обучение маршрутизатора — это не просто технические усовершенствования, но и попытка раскрыть скрытый потенциал алгоритмов.
Что дальше?
Представленная работа, по сути, лишь очередная попытка расшифровки исходного кода реальности. SLA2 демонстрирует, что даже в, казалось бы, отлаженных системах, таких как диффузионные модели, всегда найдется место для оптимизации — для выявления и устранения избыточности. Однако, стоит признать, что достигнутая экономия вычислительных ресурсов — это не столько фундаментальный прорыв, сколько грамотная эксплуатация существующих уязвимостей. Вопрос в том, насколько далеко можно зайти, используя подобные трюки, прежде чем столкнуться с принципиальными ограничениями самой архитектуры.
Очевидным направлением дальнейших исследований представляется поиск способов динамической адаптации разреженности внимания — не просто отбрасывание «ненужных» связей, а создание системы, способной в реальном времени определять наиболее критичные участки входных данных. Более того, пока что большинство работ, включая данную, фокусируются на оптимизации вычислений, игнорируя энергопотребление памяти. Реальное снижение стоимости вычислений требует комплексного подхода, учитывающего все аспекты аппаратного обеспечения.
В конечном счете, задача состоит не в том, чтобы заставить существующие модели работать быстрее, а в том, чтобы создать принципиально новые архитектуры, способные более эффективно моделировать сложность окружающего мира. SLA2 — это шаг в этом направлении, но до полного прочтения исходного кода еще очень далеко. И, вероятно, именно в этом и заключается вся прелесть.
Оригинал статьи: https://arxiv.org/pdf/2602.12675.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусство по запросу: Как нейросети учатся понимать ваш вкус
- Квантовые алгоритмы для суперкомпьютеров: стоит ли игра свеч?
- Искусство синтеза: Новая модель для объединения текста и изображений
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Квантовые Загадки: От Теории к Реальности
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Диффузия и обучение с подкреплением: новый подход к масштабированию
2026-02-19 20:45