Автор: Денис Аветисян
Исследователи предлагают новый подход к разработке лекарств, используя возможности больших языковых моделей и поиска по базам данных для генерации перспективных молекулярных структур.
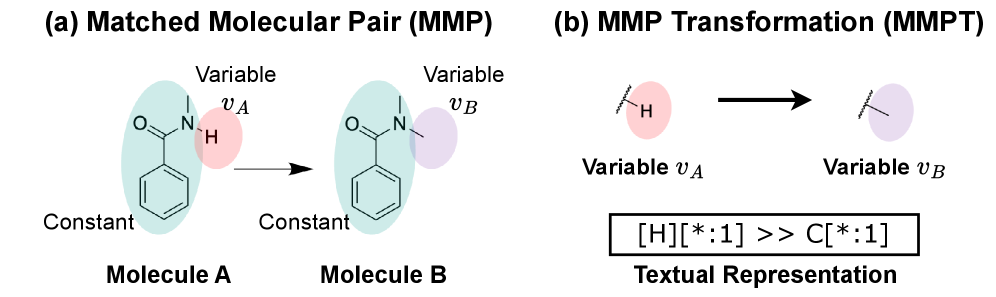
Предложен фреймворк, использующий генерацию с дополнением извлечением (Retrieval-Augmented Generation) и трансформации пар сопоставленных молекул (Matched Molecular Pair Transformations) для улучшения процесса создания новых лекарственных соединений.
Разработка новых лекарственных средств часто затруднена необходимостью генерировать молекулярные аналоги с заданными свойствами. В работе, посвященной теме ‘Retrieval-Augmented Foundation Models for Matched Molecular Pair Transformations to Recapitulate Medicinal Chemistry Intuition’, предложен новый подход, основанный на обучении фундаментальной модели трансформации молекулярных пар (MMPT) с использованием механизма расширенного поиска. Этот метод позволяет эффективно генерировать разнообразные и контролируемые аналоги, учитывая как общие химические закономерности, так и специфические данные о целевых сериях соединений. Способны ли подобные системы значительно ускорить процесс открытия новых лекарств и снизить затраты на разработку?
Вызов молекулярных инноваций
Традиционные подходы к генерации молекулярных аналогов зачастую опираются на жестко заданные правила или трудоемкий скрининг огромного количества соединений, что существенно ограничивает возможности исследования химического пространства. Данные методы, хотя и проверены временем, не позволяют эффективно генерировать принципиально новые структуры, выходящие за рамки известных шаблонов. Вместо свободного поиска оптимальных решений, исследователи вынуждены оперировать ограниченным набором модификаций, что снижает вероятность открытия соединений с уникальными и улучшенными свойствами. Этот консервативный подход особенно критичен в современных задачах, требующих создания молекул с заданными характеристиками для фармацевтики, материаловедения и других передовых областей науки.
Эффективный поиск жизнеспособных молекулярных модификаций, осуществляемый посредством так называемых matched molecular pair transformations (преобразований пар согласованных молекул), имеет первостепенное значение для инноваций в химии, однако сопряжен со значительными вычислительными трудностями. Данный подход предполагает систематическое изменение химической структуры молекулы и оценку влияния каждого изменения на ее свойства, что требует огромных ресурсов. Сложность заключается в экспоненциальном росте числа возможных модификаций с увеличением размера и сложности молекулы. Для преодоления этих трудностей разрабатываются новые алгоритмы и методы машинного обучения, направленные на прогнозирование влияния структурных изменений и сокращение объема необходимых вычислений. Успешная реализация этих подходов позволит значительно ускорить процесс открытия новых лекарственных средств и материалов с заданными свойствами, открывая новые горизонты в области молекулярных инноваций.
Сложность химической структуры молекул обуславливает необходимость применения интеллектуальных методов для исследования огромного пространства возможных соединений. Каждый атом, каждая связь и пространственная конфигурация вносят вклад в уникальные свойства вещества, создавая экспоненциально растущее количество комбинаций даже для относительно простых молекул. Традиционные подходы, основанные на переборе вариантов, становятся непрактичными из-за вычислительных ограничений и огромных временных затрат. Поэтому, современные исследования направлены на разработку алгоритмов, способных прогнозировать свойства молекул, идентифицировать перспективные структуры и эффективно отбирать наиболее интересные соединения для дальнейшего изучения. Эти методы включают в себя машинное обучение, искусственные нейронные сети и другие инструменты, позволяющие «прочесывать» химическое пространство с высокой скоростью и точностью, открывая путь к инновационным материалам и лекарственным препаратам.

MMPT-FM: Основа для молекулярного дизайна
Модель MMPT-FM представляет собой фундаментальную модель, обученную на обширных данных о вариативных заменах в молекулярных структурах. Этот подход позволяет ей предсказывать и генерировать реалистичные модификации молекул, основываясь на изученных паттернах. Обучение на большом объеме данных вариативных замен обеспечивает способность модели к обобщению и созданию новых, правдоподобных молекулярных структур, отличающихся от тех, которые непосредственно присутствовали в обучающем наборе. Данная возможность особенно ценна в задачах молекулярного дизайна и оптимизации свойств соединений.
Модель MMPT-FM базируется на архитектуре Transformer, зарекомендовавшей себя в задачах обработки последовательностей, и инициализирована с использованием предварительно обученной модели ChemT5. Это позволяет MMPT-FM эффективно использовать знания, полученные при обучении на больших объемах текстовых данных, адаптированные для представления и обработки химических структур. Использование ChemT5 в качестве отправной точки обеспечивает модели сильные возможности языкового моделирования, необходимые для предсказания и генерации правдоподобных молекулярных модификаций, что существенно ускоряет процесс обучения и повышает качество генерируемых результатов.
В процессе инференса модель MMPT-FM использует алгоритм Beam Search для исследования множества возможных замен в молекулярной структуре. Вместо выбора единственной наиболее вероятной замены на каждом шаге, Beam Search поддерживает несколько гипотез (пучков), ранжируя их по вероятности достижения желаемых свойств. Это позволяет модели исследовать более широкий спектр модификаций, увеличивая вероятность генерации молекул с оптимальными характеристиками. Количество гипотез в пучке (ширина луча) является гиперпараметром, влияющим на баланс между скоростью инференса и качеством результата. Алгоритм оценивает каждую гипотезу на основе вероятности последовательности и, при необходимости, дополнительных критериев, определяющих целевые свойства молекулы.
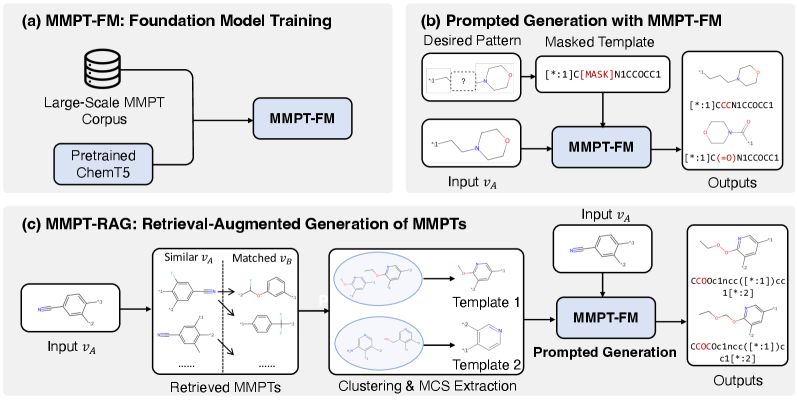
MMPT-RAG: Расширение генерации с помощью контекста
MMPT-RAG представляет собой расширение модели MMPT-FM посредством интеграции фреймворка Retrieval-Augmented Generation (RAG), что позволяет использовать внешние базы данных в качестве источника контекстной информации. В отличие от генерации, основанной исключительно на внутренних параметрах модели, MMPT-RAG извлекает релевантные примеры из заданного набора данных молекулярных структур, используя их в качестве условия для генерации новых соединений. Данный подход позволяет модели учитывать более широкий спектр химических знаний и контекста, что приводит к улучшению качества, разнообразия и химической достоверности сгенерированных аналогов, а также повышает способность к генерации соединений, не представленных в обучающем наборе данных.
Для эффективного поиска релевантных молекулярных контекстов в рамках Retrieval-Augmented Generation, MMPT-RAG использует алгоритм HNSW (Hierarchical Navigable Small World). HNSW позволяет построить иерархический индекс ближайших соседей, обеспечивая быстрый и масштабируемый поиск. В отличие от полного перебора, HNSW организует данные в многослойную сеть, где каждый слой представляет собой граф ближайших соседей. Это позволяет алгоритму быстро сужать область поиска, переходя от верхних слоев (грубая аппроксимация) к нижним (более точное соответствие), значительно сокращая время, необходимое для извлечения наиболее похожих молекул из внешней базы данных.
Для точного поиска релевантных молекулярных контекстов в рамках системы MMPT-RAG используются два метода представления молекулярных структур: отпечатки Моргена (Morgan Fingerprints) и анализ максимального общего подструктурного соответствия (Maximum Common Substructure, MCS). Отпечатки Моргена представляют молекулу в виде битового вектора, кодирующего наличие определенных фрагментов, что позволяет быстро оценивать сходство между молекулами. Анализ MCS идентифицирует наибольшую общую подструктуру двух молекул, обеспечивая более точное определение структурного подобия, особенно в случаях, когда молекулы имеют значительные различия в размерах или функциональных группах. Комбинация этих двух подходов повышает эффективность и точность поиска наиболее подходящих молекулярных примеров для аугментации генерации.
Использование полученных из внешних источников примеров в качестве условия для генерации позволяет MMPT-RAG повысить качество, разнообразие и химическую достоверность генерируемых аналогов. В ходе экспериментов по генерации соединений на основе патентной информации, MMPT-RAG достиг показателя recall до 46.81%, что является одним из лучших результатов в данной области. Данное улучшение обусловлено тем, что модель, ориентируясь на релевантные примеры, более эффективно избегает генерации неправдоподобных или нежелательных структур, одновременно расширяя пространство возможных аналогов.
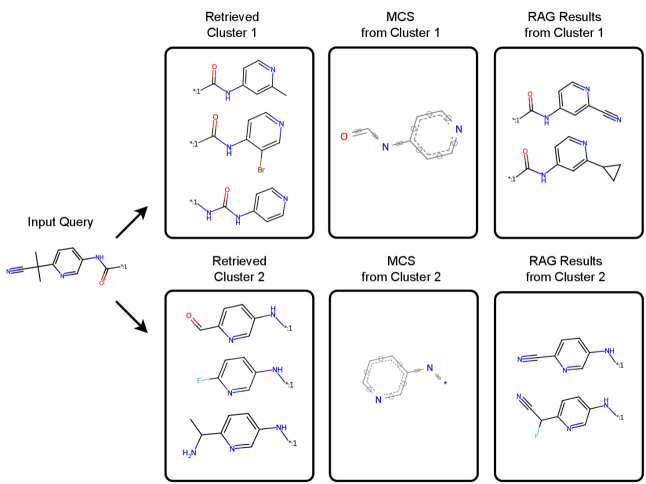
Влияние и перспективы дальнейших исследований
Разработка модели MMPT-RAG значительно ускоряет процесс генерации аналогов химических соединений, открывая новые возможности для быстрого исследования химического пространства. Вместо традиционных методов, требующих значительных временных затрат на синтез и тестирование, данная модель позволяет оперативно создавать и оценивать большое количество потенциальных молекул. Это ускорение особенно ценно в областях, где требуется быстрая итерация и оптимизация, например, при разработке лекарственных препаратов и новых материалов, позволяя исследователям эффективнее выявлять перспективные соединения и сокращать время, необходимое для достижения желаемых результатов. Повышенная скорость генерации аналогов, обеспечиваемая MMPT-RAG, способствует более эффективному использованию ресурсов и снижению затрат на исследования.
Разработанная модель демонстрирует значительное повышение эффективности в областях поиска новых лекарственных средств и разработки материалов благодаря способности генерировать структурно разнообразные и химически корректные соединения. В ходе тестирования на задачах, соответствующих тренировочным данным, модель достигла показателя воспроизводимости в 82.1%, что свидетельствует о высокой точности и надежности генерируемых молекулярных структур. Это позволяет исследователям значительно ускорить процесс поиска перспективных кандидатов, сократить время и затраты на синтез и тестирование, а также расширить возможности для создания инновационных материалов с заданными свойствами. Повышенная эффективность генерации открывает новые перспективы для решения сложных задач в химии и материаловедении.
Дальнейшие исследования направлены на расширение возможностей модели MMPT-RAG путем интеграции более сложных ограничений и целевых показателей. В частности, планируется учитывать такие критически важные параметры, как сродство связывания с целевой молекулой и свойства ADMET (абсорбция, распределение, метаболизм, выведение и токсичность). Включение этих факторов позволит создавать соединения не только структурно разнообразные и химически валидные, но и обладающие оптимальными фармакокинетическими характеристиками и безопасностью, что существенно повысит эффективность процесса разработки новых лекарственных препаратов и материалов с заданными свойствами. Такой подход позволит перейти от простого генерирования молекул к созданию соединений, обладающих предсказуемым и желаемым воздействием.
Дальнейшее расширение обучающего набора данных и усовершенствование механизмов поиска представляется ключевым фактором для повышения эффективности и применимости разработанной системы. Текущие показатели, демонстрирующие Recall-o (вне обучающего набора) в 12.99% и уровень новизны в 30.1%, указывают на значительный потенциал для улучшения способности модели генерировать соединения, не представленные в исходных данных, и, следовательно, открывать новые возможности в областях, требующих поиска инновационных молекул. Оптимизация алгоритмов поиска позволит более эффективно использовать имеющуюся информацию и находить соединения с заданными свойствами, что особенно важно для решения сложных задач в химии и материаловедении.
Исследование, представленное в данной работе, демонстрирует закономерную эволюцию подходов к генерации молекулярных аналогов. Авторы, по сути, переосмысливают процесс как последовательность трансформаций, что напоминает естественное старение и адаптацию систем. Как однажды заметил Эдсгер Дейкстра: «Программирование — это не столько о создании программ, сколько об управлении сложностью». В контексте генеративной химии, сложность заключается в огромном химическом пространстве и необходимости находить оптимальные пути трансформаций. Применение Retrieval-Augmented Generation (RAG) позволяет не только ускорить поиск, но и обеспечить более осознанный и направленный процесс, подобно тому, как опытный химик интуитивно выбирает наиболее перспективные модификации молекул. Очевидно, что улучшения в области генеративной химии будут стареть быстрее, чем мы успеваем их понять, поэтому важно фокусироваться на фундаментальных принципах и долгосрочной устойчивости подходов.
Куда же дальше?
Представленная работа, как и любая попытка обуздать сложность химического пространства, лишь обозначает горизонт, за которым простираются нерешенные вопросы. Версионирование моделей, подобно архивам молекулярных превращений, неизбежно накапливает устаревшие знания. Стрела времени всегда указывает на необходимость рефакторинга, переосмысления представленных трансформаций в свете новых данных и открытий. Эффективность извлечения релевантной информации из постоянно растущих баз данных молекулярных пар остается критической точкой, требующей дальнейшей оптимизации.
Особого внимания заслуживает вопрос о генерализации. Способность модели экстраполировать полученные знания на новые, невидимые ранее химические структуры — мерило ее истинной ценности. Текущие подходы, фокусирующиеся наMatched Molecular Pairs (MMPs), могут оказаться недостаточными для решения задач, требующих радикального изменения молекулярного каркаса. Поиск новых способов представления химических трансформаций, возможно, основанных на более абстрактных понятиях, представляется перспективным направлением.
В конечном счете, вся система стареет — вопрос лишь в том, насколько достойно она это делает. Успех подобного подхода будет зависеть не только от вычислительной мощности и алгоритмической изысканности, но и от способности уловить тонкую грань между предсказуемостью и инновацией, между воспроизведением известного и открытием нового.
Оригинал статьи: https://arxiv.org/pdf/2602.16684.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусство по запросу: Как нейросети учатся понимать ваш вкус
- Квантовые алгоритмы для суперкомпьютеров: стоит ли игра свеч?
- Знания в графах: как улучшить ответы больших языковых моделей
- Искусство синтеза: Новая модель для объединения текста и изображений
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Квантовые Загадки: От Теории к Реальности
- Оптимизация запросов: Новый подход для сложных рабочих процессов
2026-02-19 20:51