Автор: Денис Аветисян
Новый подход к разработке интеллектуальных агентов демонстрирует, что небольшие языковые модели могут эффективно решать сложные промышленные задачи.
В статье рассматривается применение фреймворков навыков агентов с использованием малых языковых моделей для повышения эффективности и снижения требований к объему видеопамяти.
Несмотря на растущую популярность больших языковых моделей, их применение в промышленных сценариях часто ограничено соображениями безопасности данных и бюджетными рамками. В данной работе, посвященной ‘Agent Skill Framework: Perspectives on the Potential of Small Language Models in Industrial Environments’, исследуется возможность повышения эффективности малых языковых моделей (SLM) за счет использования фреймворка Agent Skill. Полученные результаты демонстрируют, что умеренно большие SLM (около 12-30 млрд параметров) значительно выигрывают от применения данного подхода, приближаясь по производительности к закрытым моделям при меньших затратах ресурсов VRAM, особенно при использовании моделей, специализирующихся на коде. Какие перспективы открываются для дальнейшей оптимизации и адаптации фреймворка Agent Skill для различных промышленных задач и специфических требований к безопасности данных?
Пределы Контекста: Когда Большие Модели Становятся Заложниками Своих Размеров
Современные большие языковые модели демонстрируют впечатляющие возможности в обработке и генерации текста, однако их эффективность напрямую зависит от объёма предоставляемого контекста. Увеличение «окна контекста» — количества информации, которое модель может учитывать при обработке запроса — требует экспоненциального роста вычислительных ресурсов. Это связано с тем, что внимание модели должно быть распределено по всем элементам контекста, что приводит к квадратичному увеличению сложности вычислений с ростом длины входных данных. Таким образом, хотя расширение контекстного окна позволяет модели учитывать больше информации, это создаёт значительные трудности для масштабирования и практического применения, особенно в задачах, требующих обработки длинных документов или сложных диалогов. Преодоление этих вычислительных ограничений является ключевой задачей в развитии больших языковых моделей.
Традиционные методы конструирования контекста, такие как генерация с расширением извлечением (Retrieval-Augmented Generation), сталкиваются с растущими трудностями по мере увеличения объема предоставляемой информации. Несмотря на кажущуюся простоту подхода — предоставление модели релевантных фрагментов данных для улучшения ответов — сохранение когерентности и актуальности становится серьезной проблемой. По мере роста длины контекста, модель все сложнее выделяет действительно важные сведения, что приводит к снижению точности, появлению противоречий и затруднениям в выполнении сложных рассуждений. Вместо того чтобы эффективно использовать расширенный контекст, модель зачастую «теряется» в избыточной информации, что негативно сказывается на качестве генерируемых ответов и способности решать задачи, требующие глубокого понимания и анализа.
Фреймворк Навыков Агента: Новый Взгляд на Контекстное Мышление
Фреймворк навыков агента преодолевает ограничения, связанные со статическими окнами контекста, переходя к динамической системе навыков. Каждый навык инкапсулирует в себе определенную функциональную возможность, представляя собой специализированный модуль обработки информации. В отличие от традиционных подходов, где контекст передается как единый блок, здесь информация структурируется и обрабатывается через последовательное применение релевантных навыков. Это позволяет агенту адаптироваться к различным задачам и динамически формировать необходимый контекст, избегая избыточности и повышая эффективность обработки данных.
В основе данной структуры лежит принцип обучения в контексте (In-Context Learning), однако он реализован через архитектуру, основанную на навыках. Это позволяет эффективно декомпозировать сложные задачи на более простые, управляемые компоненты, каждый из которых представлен отдельным навыком. Реализация навыков как отдельных модулей обеспечивает возможность повторного использования накопленных знаний и опыта в различных задачах, что снижает потребность в постоянной переподготовке и повышает общую эффективность системы. Такой подход позволяет агенту адаптироваться к новым задачам, комбинируя существующие навыки и быстро обучаясь новым, без необходимости полной перестройки всей системы.
В рамках данной архитектуры, активное управление контекстом посредством применения специализированных навыков позволяет минимизировать избыточность информации и максимизировать релевантность данных, используемых для решения задачи. Это достигается за счет динамического выбора и применения навыков, которые извлекают и обрабатывают только необходимую информацию из входных данных, избегая обработки ненужных фрагментов. В результате, снижается объем вычислений, уменьшается потребность в вычислительных ресурсах и повышается общая производительность системы, а также скорость ответа. Такой подход особенно важен при обработке больших объемов данных и выполнении сложных задач, требующих высокой точности и эффективности.
Формализация Интеллекта: POMDP и Взаимозависимость Навыков
Основа фреймворка «Агентские навыки» — формализация в рамках частично наблюдаемых марковских процессов принятия решений (POMDP). Это позволяет строго математически описать поведение агента при поиске информации. В POMDP состояние агента не полностью наблюдаемо, а определяется вероятностью, учитывающей как предыдущие действия, так и наблюдения. Формализация через POMDP позволяет представить процесс принятия решений как поиск оптимальной политики \pi : S \rightarrow A , максимизирующей ожидаемую суммарную награду, при этом учитывая неопределенность окружения и ограниченность информации. Использование POMDP обеспечивает возможность формального анализа и оптимизации стратегий поиска информации агентом, а также верификации их корректности и эффективности.
В рамках предложенной архитектуры, взаимодействие между навыками моделируется посредством Механизма Ссылок на Навыки, формализуемого как марковское ядро. Данный механизм позволяет представить зависимости между навыками в виде вероятностных переходов, описывающих, как информация, полученная в результате выполнения одного навыка, влияет на выбор и выполнение других. Формализация в виде марковского ядра K(s, a, s', a') позволяет точно определить вероятность перехода из состояния s в состояние s' при выполнении действия a, учитывая информацию, полученную от других навыков a'. Это способствует композиционному рассуждению, позволяя системе разбивать сложные задачи на последовательность взаимосвязанных навыков и эффективно использовать накопленный опыт.
В основе структуры системы лежит использование чётко определенных описателей навыков (Skill Descriptors) и политик управления навыками (Skill Policies). Описатели навыков формализуют требования к входным данным, ожидаемые результаты и ограничения для каждого отдельного навыка. Политики управления, в свою очередь, определяют, как эти навыки вызываются и координируются для достижения сложных целей. Такая формализация позволяет проводить автоматическую верификацию корректности поведения системы, подтверждая соответствие навыков заданным спецификациям. Кроме того, наличие чётких описаний и политик обеспечивает возможность автоматической оптимизации сложных поведенческих стратегий, например, путем поиска наиболее эффективных последовательностей вызовов навыков или настройки параметров выполнения для достижения максимальной производительности. \text{Оптимизация} = f(\text{Skill Descriptors}, \text{Skill Policies})
Эффективность и Адаптивность: Оптимизация для Реального Развертывания
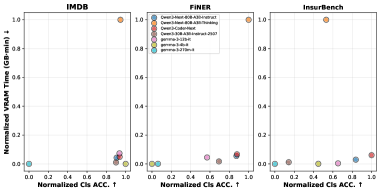
Разработанный Агентский Фреймворк Навыков демонстрирует существенный прирост эффективности использования видеопамяти (VRAM) по сравнению с традиционными подходами, применяемыми в больших языковых моделях. Этот прогресс достигается за счет оптимизации архитектуры и алгоритмов обработки данных, что позволяет значительно снизить потребность в вычислительных ресурсах. В результате, фреймворк становится особенно привлекательным для развертывания в средах с ограниченными ресурсами, таких как мобильные устройства или системы с низкой пропускной способностью памяти. Такая адаптивность открывает возможности для использования передовых языковых моделей в более широком спектре приложений и сценариев, где ранее это было затруднительно из-за ограничений аппаратного обеспечения.
Архитектура данной системы отличается высокой гибкостью благодаря модульному дизайну, позволяющему интегрировать различные типы больших языковых моделей (LLM). В частности, возможно использование как моделей, настроенных на следование инструкциям, так и специализированных моделей, предназначенных для работы с кодом. Такой подход позволяет оптимизировать производительность системы под конкретные задачи, причем модели, специализирующиеся на коде, демонстрируют наименьшее время использования видеопамяти (VRAM). Данная особенность особенно важна для развертывания системы в условиях ограниченных ресурсов, обеспечивая эффективную работу даже на менее мощном оборудовании и открывая возможности для широкого спектра практических применений.
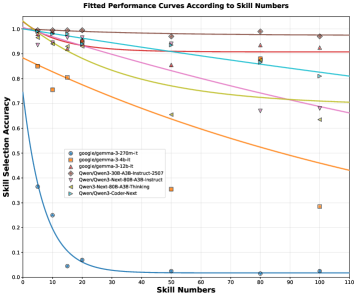
Исследования с использованием LangChain DeepAgent продемонстрировали высокую эффективность предложенного подхода. В ходе экспериментов точность выбора навыков (Skill Selection Accuracy) достигла 100% при решении сложных задач, что свидетельствует о способности системы адекватно оценивать и применять необходимые инструменты. Особенно примечательны результаты, полученные с моделью Qwen3-80B-Instruct на датасете FiNER, где достигнут показатель 0.654 — значительное улучшение по сравнению с результатом 0.198, полученным без использования навыков агента. Данные результаты подтверждают, что применение специализированных навыков существенно повышает производительность и точность работы системы в задачах обработки естественного языка.
Перспективы Развития: Масштабирование Интеллекта с Динамическими Навыками
Исследования демонстрируют перспективность интеграции небольших языковых моделей в рамках архитектуры Agent Skill Framework. Такой подход позволяет значительно снизить вычислительные затраты, не уступая при этом в эффективности более крупным моделям. В ходе экспериментов было установлено, что оптимизированные небольшие языковые модели способны достигать сопоставимых результатов с их более громоздкими аналогами, сохраняя при этом существенное преимущество в скорости обработки и потреблении ресурсов. Данный подход открывает возможности для создания более доступных и энергоэффективных интеллектуальных агентов, способных решать широкий спектр задач без необходимости использования дорогостоящего оборудования и больших объемов энергии.
Внедрение иерархических многоагентных систем в существующую структуру открывает перспективы для решения задач повышенной сложности за счет коллективного подхода к решению проблем. Такая архитектура предполагает распределение ответственности между специализированными агентами, каждый из которых обладает определенным набором навыков и компетенций. Взаимодействие между агентами, организованное по иерархическому принципу, позволяет эффективно координировать действия и находить оптимальные решения, недостижимые для отдельных агентов. Данный подход имитирует принципы коллективного интеллекта, наблюдаемые в природе, и создает основу для разработки действительно интеллектуальных систем, способных адаптироваться к меняющимся условиям и эффективно решать сложные задачи, требующие сочетания различных навыков и знаний.
Исследования показали, что модели, превышающие 12 миллиардов параметров, демонстрируют стабильно высокую точность выбора навыков даже при увеличении их количества до 100. В отличие от них, модели меньшего размера быстро теряют точность при расширении набора навыков, что указывает на важность масштабирования для создания действительно адаптивных и интеллектуальных агентов. Данный результат подчеркивает потенциал развития систем, способных к непрерывному обучению и инновациям, посредством увеличения вычислительных ресурсов и оптимизации процессов выбора навыков. Возможность поддерживать высокую точность при большом количестве доступных инструментов открывает перспективы для создания агентов, способных эффективно решать сложные и многогранные задачи в динамично меняющейся среде.
Исследование демонстрирует, что даже небольшие языковые модели, при грамотном применении фреймворков навыков агентов, способны достигать производительности, сопоставимой с более крупными моделями. Это особенно заметно при использовании моделей, специализирующихся на коде, что открывает возможности для оптимизации использования VRAM. Как заметила Барбара Лисков: «Хорошее проектирование — это когда система справляется с изменениями без изменений». В данном контексте, гибкость фреймворка навыков агентов позволяет системе адаптироваться к различным задачам и ограничениям, таким как объем VRAM, без необходимости переработки всей архитектуры. Такой подход к проектированию систем является ключом к созданию надежных и масштабируемых решений в промышленных условиях.
Куда же дальше?
Представленная работа лишь слегка приоткрывает завесу над истинным потенциалом малых языковых моделей. Очевидно, что «реальность» — это открытый исходный код, который мы ещё не прочитали, и каждая оптимизация, каждая эффективная архитектура — это лишь попытка декомпилировать небольшой фрагмент. Особенно интересно, что специализированные модели, заточенные под код, демонстрируют сопоставимую производительность с более громоздкими аналогами. Это наводит на мысль: возможно, дело не в размере, а в точности инструментария.
Однако, остаются вопросы. Как масштабировать эти «навыки агента» на более сложные, неструктурированные среды? Как обеспечить устойчивость к «шуму» и непредсказуемости реального мира, где «правила» часто игнорируются? И, самое главное, как преодолеть ограничения VRAM, которые, как известно, всегда находятся на шаг впереди наших амбиций? Простое увеличение эффективности — это лишь временное решение; требуется принципиально новый подход к обработке и представлению информации.
В перспективе, следует ожидать экспериментов с гибридными моделями, сочетающими преимущества малых языковых моделей с другими формами искусственного интеллекта. Поиск оптимального баланса между вычислительной эффективностью и способностью к обобщению — это задача, которая потребует нестандартного мышления и, возможно, даже некоторого «взлома» существующих парадигм. Иначе говоря, пора перестать верить в «черный ящик» и начать разбирать его по винтикам.
Оригинал статьи: https://arxiv.org/pdf/2602.16653.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Квантовый код: Слияние классики и управления
- Пишущий разум: Как ИИ меняет процесс создания текстов
- Эко-интеллект: Как сделать ИИ более экологичным
- Квантовый транспорт в сложных системах: новый подход к моделированию
- Погода под контролем: Квантово-классическое моделирование для точного прогнозирования
- Квантовый щит для искусственного интеллекта
- Квантовый Монте-Карло: Моделирование рождения электрон-позитронных пар
2026-02-19 22:36