Автор: Денис Аветисян
Представлена система DataJoint 2.0, объединяющая данные, структуру и вычислительные процессы в единую, масштабируемую среду для надежной и воспроизводимой работы.
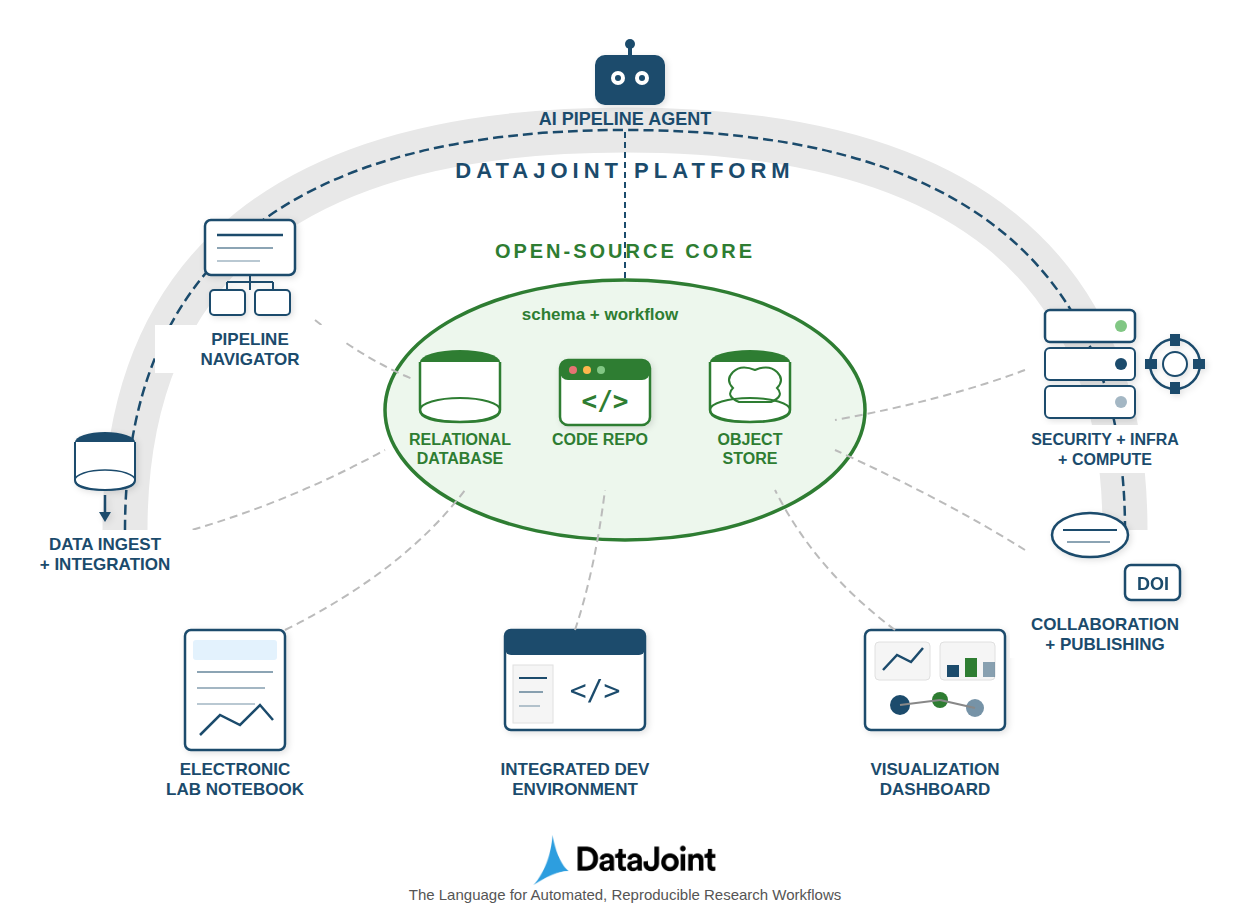
DataJoint 2.0: Реляционная модель рабочих процессов для организации и контроля научных данных и вычислений.
Несмотря на растущую сложность научных исследований, обеспечение надежности и воспроизводимости данных остается серьезной проблемой. В статье ‘DataJoint 2.0: A Computational Substrate for Agentic Scientific Workflows’ представлена система DataJoint 2.0, основанная на реляционной модели рабочих процессов, объединяющая структуру данных, сами данные и вычислительные преобразования в единую, доступную для запросов структуру. Этот подход позволяет создавать надежную основу для SciOps, где агенты могут участвовать в научных рабочих процессах без риска повреждения данных и гарантируя прослеживаемость происхождения данных. Какие перспективы открывает унификация данных и вычислений для автоматизации научных открытий и повышения эффективности исследований?
Поток Данных и Вызовы Управления в Научных Исследованиях
Современная научная деятельность характеризуется экспоненциальным ростом объемов генерируемых данных, что создает серьезные трудности для традиционных систем управления информацией. Это связано с развитием высокопроизводительных технологий, таких как геномика, астрономия и климатология, а также с повсеместным использованием автоматизированных измерительных приборов и симуляций. Традиционные файловые системы и базы данных зачастую не способны эффективно обрабатывать, хранить и анализировать такие массивы данных, что приводит к замедлению исследований, ошибкам и потере ценной информации. Необходимость в новых подходах к управлению данными становится все более острой, поскольку научные открытия напрямую зависят от способности исследователей эффективно работать с постоянно растущим потоком информации.
Традиционные системы управления научными данными, основанные на файлах, сталкиваются с серьезными трудностями при обработке постоянно растущих объемов информации и сложности современных аналитических задач. Простое хранение данных в виде файлов не обеспечивает надежной защиты от ошибок и повреждений, что ставит под угрозу целостность результатов исследований. Воспроизводимость научных экспериментов оказывается под вопросом, поскольку отслеживание изменений в файлах и зависимостей между ними затруднено. Более того, современные научные задачи часто требуют обработки больших массивов данных и использования сложных алгоритмов, что выходит за рамки возможностей стандартных файловых систем и требует более гибких и масштабируемых решений. Поэтому, возникает необходимость в разработке новых подходов к управлению научными данными, обеспечивающих их целостность, воспроизводимость и возможность эффективной обработки.
В эпоху экспоненциального роста объемов научных данных, потребность в надежной, масштабируемой и верифицируемой системе управления данными и рабочими процессами становится первостепенной задачей. Традиционные подходы, основанные на файловых системах, зачастую не справляются с обеспечением целостности данных, воспроизводимости результатов и сложностью современных аналитических задач. Необходима платформа, способная не только хранить и обрабатывать огромные массивы информации, но и отслеживать все этапы исследования, гарантируя прозрачность и возможность проверки каждого шага. Подобная система позволит исследователям сосредоточиться на научном открытии, а не на рутинных операциях с данными, значительно ускоряя темпы прогресса в различных областях науки и техники. Гарантия корректности и воспроизводимости научных результатов приобретает все большее значение для доверия к научным открытиям и их практическому применению.
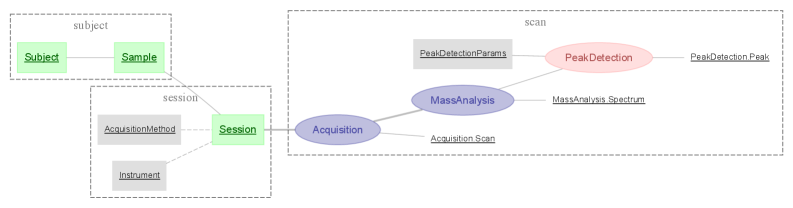
Реляционная Модель Рабочего Процесса: Новый Подход
Реляционная модель рабочего процесса представляет этапы процесса в виде таблиц, где каждая строка соответствует конкретному артефакту, проходящему через этот этап. Последовательность выполнения определяется посредством внешних ключей, связывающих строки в разных таблицах. Эта абстракция позволяет точно отслеживать состояние каждого артефакта на каждом этапе процесса, а также эффективно выполнять запросы для анализа истории артефакта или статуса процесса в целом. Использование внешних ключей обеспечивает целостность данных и позволяет легко реконструировать полный путь артефакта через последовательность этапов, что существенно упрощает отладку и мониторинг.
Нормализация рабочего процесса обеспечивает целостность данных и упрощает сложные аналитические задачи за счет представления сущностей на конкретных этапах их обработки. Этот подход предполагает декомпозицию данных, связанных с рабочим процессом, на отдельные таблицы, каждая из которых отражает состояние сущности на определенном этапе. Такая организация позволяет избежать избыточности данных и гарантирует, что каждое изменение состояния сущности отражается только в соответствующей таблице. В результате, анализ данных становится более точным и эффективным, поскольку позволяет легко отслеживать историю изменений сущности и выявлять закономерности в ее обработке. Кроме того, нормализация облегчает интеграцию данных с другими системами и инструментами анализа.
Данный подход использует преимущества реляционных баз данных SQL и объектных хранилищ, предоставляя знакомую и масштабируемую основу для построения рабочих процессов. Базы данных SQL обеспечивают надежное хранение метаданных о состоянии и истории артефактов, а также позволяют эффективно выполнять запросы и анализировать данные о ходе выполнения процессов. Объектные хранилища, в свою очередь, оптимизированы для хранения больших объемов неструктурированных данных, представляющих сами артефакты, что обеспечивает высокую производительность и экономичность хранения. Комбинация этих технологий позволяет создавать системы, способные обрабатывать значительные объемы данных и легко масштабироваться при увеличении нагрузки.
DataJoint: Соединяя Разрозненные Данные в Единое Целое
DataJoint использует реляционную модель рабочего процесса, дополненную объектно-ориентированной схемой, что позволяет создать единое представление данных, хранящихся в различных системах. В отличие от традиционных систем управления базами данных, схема DataJoint не ограничивается структурой таблиц, а позволяет определять типы данных как объекты, что упрощает работу со сложными данными, такими как изображения или временные ряды. Это обеспечивает унифицированный доступ к данным, независимо от их физического местоположения или формата хранения, будь то файлы на диске, реляционные базы данных или облачные хранилища. Объектно-ориентированная схема также позволяет определять зависимости между данными, что является ключевым для автоматизации рабочих процессов и обеспечения воспроизводимости результатов.
Автоматизированное управление заданиями в DataJoint основано на зависимостях, определенных схемой данных. Это означает, что порядок выполнения задач определяется не произвольно, а автоматически, исходя из связей между таблицами и сущностями в схеме. Система анализирует эти зависимости и формирует граф выполнения, гарантируя, что каждая задача будет выполнена только после завершения всех необходимых ей входных данных. Такой подход позволяет избежать ошибок, связанных с неправильным порядком обработки, и оптимизировать использование ресурсов, поскольку задачи выполняются только тогда, когда для этого есть все условия. Автоматическое управление также включает в себя параллельное выполнение независимых задач, что значительно повышает общую производительность системы.
Семантическое сопоставление в DataJoint обеспечивает надежную валидацию данных путем проверки соответствия типов и значений между различными сущностями и таблицами. В результате этого процесса формируется граф происхождения данных (Lineage Graph), который фиксирует все зависимости между данными и операциями, выполняемыми над ними. Этот граф позволяет отследить путь данных от исходного источника до конечного результата, обеспечивая полную прослеживаемость и воспроизводимость экспериментов и анализов. Автоматическое построение и поддержание графа происхождения критически важно для аудита данных, выявления ошибок и обеспечения достоверности научных исследований и инженерных разработок.
К SciOps и Автономным Рабочим Процессам
Система DataJoint обеспечивает эффективную организацию и анализ сложных наборов данных благодаря поддержке концепции “главный-часть” (Master-Part Relationships). Этот подход позволяет разбить большие массивы информации на логически связанные компоненты, где “главные” записи содержат метаданные и ссылки на соответствующие “части” — фактические данные. Такая структура не только упрощает навигацию и поиск, но и существенно повышает производительность при обработке и анализе, поскольку позволяет фокусироваться на релевантных данных и избегать ненужной загрузки. В результате, исследователь может более эффективно исследовать взаимосвязи в данных и получать ценные результаты из сложных экспериментов, даже при работе с огромными объемами информации.
Система расширяемых типов, лежащая в основе DataJoint, обеспечивает бесшовную интеграцию с данными, представленными в специализированных форматах, характерных для различных научных дисциплин. Это позволяет исследователям работать непосредственно с исходными данными, не прибегая к сложным и трудоемким преобразованиям, что значительно повышает гибкость и масштабируемость аналитических процессов. Вместо жесткой привязки к определенным структурам данных, система адаптируется к потребностям конкретного исследования, позволяя эффективно обрабатывать гетерогенные наборы данных и поддерживать сложные научные эксперименты. Такая адаптивность особенно важна в областях, где форматы данных постоянно эволюционируют, и позволяет гарантировать долгосрочную совместимость и воспроизводимость результатов.
В основе представленной работы лежит реляционная модель рабочих процессов, реализованная в DataJoint 2.0. Данный подход обеспечивает не только структурированное хранение и анализ данных, но и гарантирует их целостность благодаря транзакционным операциям. Каждая операция с данными выполняется как единое неделимое действие; в случае сбоя система автоматически откатывает изменения, предотвращая возникновение повреждений или несоответствий. Такой механизм критически важен для научных исследований, где достоверность и воспроизводимость результатов имеют первостепенное значение. Внедрение транзакционных гарантий в DataJoint 2.0 позволяет исследователям сосредоточиться на научном анализе, не беспокоясь о потенциальных ошибках, связанных с повреждением данных, и обеспечивает надежную основу для построения сложных, воспроизводимых рабочих процессов.
Представленная работа демонстрирует стремление к созданию не просто системы управления данными, но и к построению целостной вычислительной среды, где структура данных, сами данные и процессы их обработки неразрывно связаны. Этот подход, в духе глубокого понимания систем, перекликается со словами Дональда Кнута: «Прежде чем оптимизировать код, убедитесь, что он работает правильно». В данном контексте, оптимизация заключается в создании масштабируемых и надёжных научных рабочих процессов, а «правильная работа» — в обеспечении целостности данных и воспроизводимости результатов, что является ключевым элементом представленной Relational Workflow Model. Акцент на data provenance и объектно-ориентированную схему подчеркивает стремление к созданию системы, способной к самоанализу и выявлению потенциальных ошибок, что соответствует философии взлома системы с целью её улучшения.
Куда Ведет Эта Дорога?
Представленная система, стремясь объединить данные, структуру и вычислительные процессы в единую, запросимую основу, неизбежно наталкивается на вопрос: что дальше? Вместо поиска окончательного решения, она, скорее, открывает пространство для новых вопросов. Автоматизация научных рабочих процессов — это не просто оптимизация скорости, но и переосмысление самой природы научного поиска. Проблема, однако, заключается не в скорости, а в контроле над хаосом. Данные, даже структурированные, всегда несут в себе потенциал для неожиданных корреляций и ложных выводов.
Очевидным направлением является интеграция с системами машинного обучения, но тут возникает парадокс: доверие к алгоритму, который сам нуждается в проверке. Задача заключается не в создании «самообучающейся науки», а в разработке инструментов, позволяющих ученым эффективно контролировать и интерпретировать результаты, полученные с помощью этих алгоритмов. Интересно, как подобная система будет справляться с неполнотой данных или противоречивыми результатами — вопросами, которые часто являются ключевыми в реальных научных исследованиях.
В конечном счете, ценность подобного подхода заключается не в создании идеальной системы, а в предоставлении исследователям инструментов для систематического изучения и взлома самой структуры научного знания. Ошибки неизбежны, и именно в их анализе кроется истинный прогресс. Возможно, настоящая цель — не автоматизировать науку, а создать среду, в которой ошибки становятся отправной точкой для новых открытий.
Оригинал статьи: https://arxiv.org/pdf/2602.16585.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусство синтеза: Новая модель для объединения текста и изображений
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Квантовые Загадки: От Теории к Реальности
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Диффузия и обучение с подкреплением: новый подход к масштабированию
- Квантовые алгоритмы против нейросетей: есть ли смысл в переходе?
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
2026-02-20 03:37