Автор: Денис Аветисян
Новый метод динамической адаптации разрешения латентного пространства позволяет существенно повысить скорость работы Diffusion Transformers без потери качества генерируемых изображений и видео.
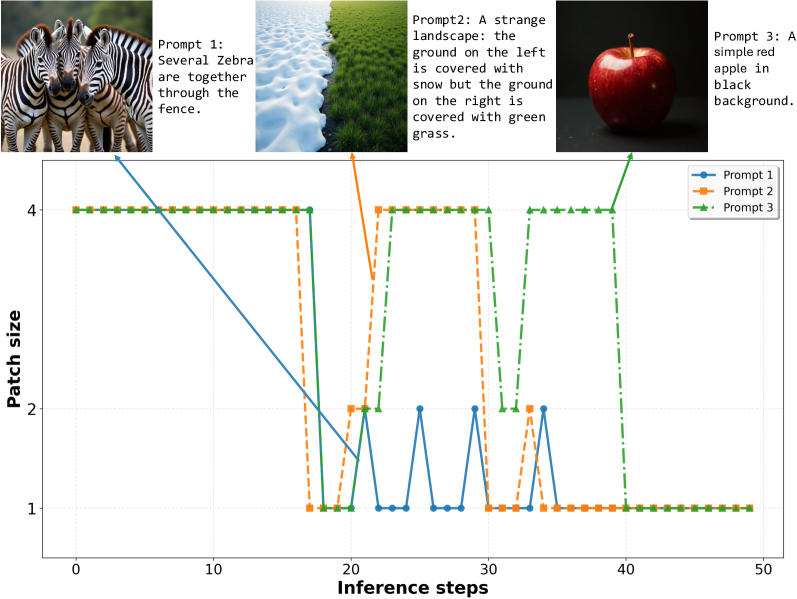
В статье представлен DDiT — подход к динамическому изменению размера патчей в процессе шумоподавления Diffusion Transformers, обеспечивающий значительное повышение вычислительной эффективности.
Несмотря на впечатляющие результаты, современные диффузионные трансформаторы (DiT) требуют значительных вычислительных ресурсов, особенно при генерации изображений и видео. В данной работе, посвященной методу ‘DDiT: Dynamic Patch Scheduling for Efficient Diffusion Transformers’, предлагается динамическое изменение размера патчей в процессе денойзинга для повышения эффективности. Ключевая идея заключается в адаптации детализации латентного представления к сложности контента и стадии шумоподавления, что позволяет добиться ускорения до 3.52\times и 3.2\times на FLUX-1.Dev и Wan 2.1 соответственно, без потери качества генерируемых изображений. Сможет ли предложенный подход стать стандартом для оптимизации DiT и расширить возможности генеративных моделей в условиях ограниченных вычислительных ресурсов?
Шёпот Хаоса: Ограничения Диффузионных Трансформеров
Диффузионные трансформеры демонстрируют впечатляющие возможности в создании контента, однако их применение к задачам, требующим обработки длинных последовательностей, сталкивается с существенными вычислительными ограничениями. Несмотря на выдающиеся результаты в генерации изображений и коротких текстов, потребность в значительных ресурсах памяти и процессорного времени становится критическим фактором при работе с более объемными данными. Это препятствует созданию, например, детализированных повествований, сложных музыкальных композиций или высококачественных видеороликов, поскольку вычислительные затраты быстро становятся непомерно высокими. Таким образом, эффективность этих моделей в генерации контента напрямую связана с длиной генерируемой последовательности, что ограничивает их потенциал в задачах, требующих работы с длинным контекстом и сложными зависимостями.
Вычислительная сложность Diffusion Transformers обусловлена необходимостью обработки информации в латентном пространстве, что требует значительных объемов памяти и вычислительной мощности. В отличие от традиционных моделей, работающих непосредственно с пикселями или другими исходными данными, Diffusion Transformers оперируют с представлениями данных в сжатом, но многомерном латентном пространстве. Каждая операция, будь то преобразование, фильтрация или генерация, выполняется над этими латентными представлениями, а их размерность и сложность быстро растут с увеличением разрешения и детализации генерируемого контента. В результате, даже относительно небольшие изображения или последовательности требуют значительных ресурсов для обработки, что становится серьезным препятствием для масштабирования и применения Diffusion Transformers к задачам, требующим генерации длинных или высококачественных данных.
Попытки ускорить работу Diffusion Transformers посредством традиционных методов, таких как отсечение признаков и статическое снижение размерности, демонстрируют ограниченную эффективность. Эти подходы, хоть и способны незначительно снизить вычислительную нагрузку, не затрагивают фундаментальные причины неэффективности, связанные с обработкой информации в латентном пространстве. Существующие методы оперируют с фиксированными параметрами и не адаптируются к динамике процесса генерации, что приводит к избыточности вычислений и не позволяет в полной мере использовать возможности Diffusion Transformers для создания длинных и сложных последовательностей. Несмотря на кажущуюся простоту реализации, эти техники оказываются недостаточными для преодоления узкого места, связанного с высокой вычислительной стоимостью, и требуют разработки принципиально новых подходов к оптимизации обработки данных в латентном пространстве.
Для полной реализации потенциала Diffusion Transformers требуется адаптивный подход к обработке информации в латентном пространстве. Существующие методы оптимизации, направленные на статическое уменьшение вычислительной нагрузки, оказываются недостаточно эффективными, поскольку не учитывают динамическую природу процесса генерации. Исследования показывают, что эффективность обработки существенно различается в зависимости от сложности генерируемого контента и стадии генерации. Адаптивные методы, способные динамически регулировать объем вычислений в латентном пространстве в зависимости от этих факторов, могут значительно снизить потребность в вычислительных ресурсах без ущерба для качества генерируемого результата. Это позволит Diffusion Transformers создавать более длинные и сложные произведения, открывая новые возможности в области искусственного творчества и контент-генерации.
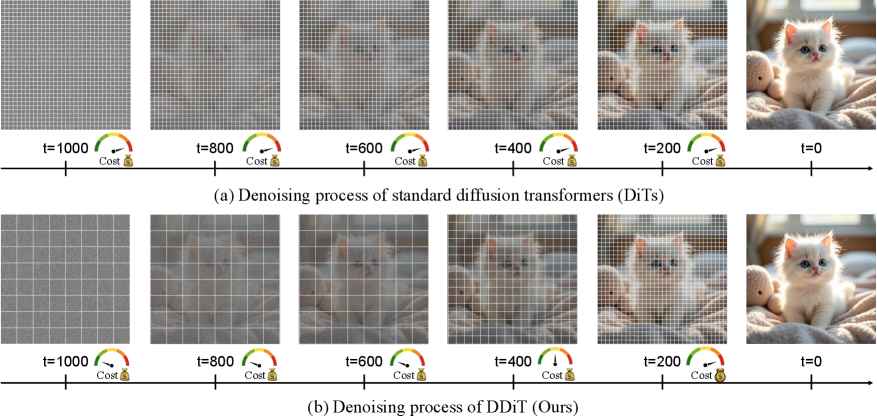
Адаптивная Обработка Латентного Пространства с DDiT
DDiT использует динамическую стратегию планирования патчей, позволяющую изменять гранулярность обработки информации в латентном пространстве в зависимости от сложности контента. Вместо использования фиксированного размера патчей, DDiT адаптирует их размер и распределение, концентрируя вычислительные ресурсы на областях, требующих более детальной обработки. Это достигается путем анализа сложности контента и соответствующей корректировки размера патчей, что позволяет эффективно использовать вычислительные ресурсы и снижать общую стоимость обработки, особенно для изображений с высокой степенью детализации или сложными структурами. Более мелкие патчи применяются к сложным областям, а более крупные — к однородным, обеспечивая оптимальный баланс между точностью и эффективностью.
Механизм адаптивной обработки в DDiT реализуется посредством мониторинга скорости эволюции латентного многообразия. Данный процесс заключается в отслеживании изменений в латентном пространстве, что позволяет выявлять области, требующие более детальной проработки. Ускоренная эволюция латентного многообразия в определенной области указывает на высокую информативность или сложность этой области, и, следовательно, необходимость увеличения разрешения обработки именно в этой части латентного пространства. Это позволяет динамически перераспределять вычислительные ресурсы, концентрируя их на наиболее значимых участках и оптимизируя общую производительность.
DDiT использует динамическое планирование патчей в сочетании с методами, такими как LoRA (Low-Rank Adaptation), для повышения эффективности тонкой настройки и адаптации модели. LoRA позволяет вносить изменения в веса предварительно обученной модели, обучая лишь небольшое количество дополнительных параметров, что существенно снижает вычислительные затраты и потребность в памяти. Динамическое планирование патчей, управляемое LoRA, позволяет DDiT фокусировать вычислительные ресурсы на наиболее значимых областях латентного пространства, обеспечивая более быструю и экономичную адаптацию модели к новым данным или задачам, чем при использовании стандартных методов тонкой настройки.
Технология DDiT значительно снижает вычислительные затраты за счет динамического распределения ресурсов, концентрируясь на наиболее информативных областях латентного пространства. Эксперименты на FLUX-1.dev показали, что данный подход позволяет достичь ускорения обработки до 2.18x по сравнению с базовыми методами. Это достигается за счет адаптивной обработки патчей, позволяющей более эффективно использовать вычислительные мощности и снижать общую стоимость вычислений без потери качества результатов.

Валидация и Прирост Производительности на Различных Бенчмарках
Проведенная оценка DDiT на стандартных наборах данных, включая COCO, DrawBench и VBench, показала значительное улучшение производительности по сравнению с существующими методами. Результаты тестов демонстрируют, что DDiT превосходит альтернативные подходы в задачах генерации и редактирования изображений, что подтверждается количественными показателями и визуальной оценкой качества сгенерированных образцов. Использование данных наборов COCO, DrawBench и VBench позволило обеспечить всестороннюю оценку возможностей DDiT в различных сценариях и условиях.
В ходе оценки DDiT показал передовые результаты по ключевым метрикам, включая FID Score, CLIP Score, SSIM и LPIPS. Достигнутые значения свидетельствуют о значительном улучшении качества генерируемых изображений и их соответствия заданным условиям. В частности, более низкий показатель FID Score указывает на повышенную реалистичность изображений, а более высокий CLIP Score — на улучшенную семантическую согласованность между изображением и текстовым описанием. Метрики SSIM и LPIPS подтверждают улучшение визуального качества и восприятия с точки зрения человеческого зрения.
В ходе оценки DDiT показал значительное увеличение скорости работы без ухудшения качества генерируемых изображений. В частности, при использовании с TeaCache наблюдается ускорение в 3.52 раза, а на платформе Wan 2.1 — 3.2 раза. Данные улучшения были подтверждены как метриками оценки качества изображений, так и результатами пользовательской оценки, что свидетельствует о сохранении высокого уровня визуального восприятия сгенерированного контента.
Метод конечных разностей третьего порядка используется для оценки скорости эволюции латентного многообразия, что обеспечивает точную и надежную адаптацию модели. В отличие от методов первого или второго порядка, использование разностей третьего порядка позволяет более точно аппроксимировать производную, снижая погрешность и повышая стабильность процесса адаптации. Это особенно важно при работе с комплексными латентными пространствами, где даже небольшие ошибки в оценке скорости эволюции могут привести к значительным искажениям генерируемых изображений или снижению качества выходных данных. Применение данного метода позволяет более эффективно отслеживать изменения в латентном пространстве и адаптировать модель к новым данным или задачам с высокой точностью и надежностью.

К Эффективному и Масштабируемому Созданию Контента
Технология DDiT открывает новые возможности для создания контента с высоким разрешением и увеличенной продолжительностью, при этом значительно снижая требования к вычислительным ресурсам. Данный подход позволяет генерировать сложные изображения и видео, которые ранее требовали значительных затрат времени и энергии. В основе лежит оптимизация процесса диффузии, позволяющая достичь высокого качества изображения, используя меньше вычислительных шагов. Это особенно важно для приложений, где ресурсы ограничены, например, для мобильных устройств или облачных сервисов, стремящихся к масштабируемости. Благодаря DDiT, создание детализированного и продолжительного контента становится более доступным и эффективным, расширяя горизонты для творчества и инноваций в различных областях.
Значительный прогресс в области генеративных моделей, представленный технологией DDiT, открывает широкие перспективы для различных областей применения. В частности, это касается создания видеоконтента, где ранее высокие вычислительные затраты ограничивали возможность генерации длинных и детализированных роликов. Технология позволяет значительно снизить эти затраты, делая создание высококачественного видео более доступным. Кроме того, DDiT имеет потенциал для революции в сфере виртуальной реальности, обеспечивая генерацию более реалистичных и детализированных виртуальных сред в режиме реального времени. Не менее важным является применение в научной визуализации, где DDiT позволяет создавать сложные трехмерные модели и визуализации данных с высокой детализацией и точностью, что существенно облегчает анализ и интерпретацию результатов исследований.
Разработка DDiT существенно снижает разрыв между вычислительными затратами и качеством генерируемого контента, открывая новые возможности для создания более доступных и масштабируемых генеративных моделей. Традиционно, получение высококачественных изображений или видео требовало огромных вычислительных ресурсов, что ограничивало возможности исследователей и создателей контента. DDiT, благодаря инновационному подходу к диффузионным моделям, позволяет достигать сопоставимого или даже превосходящего качества при значительно меньших затратах. Это делает передовые технологии генерации контента более демократичными, позволяя использовать их в широком спектре приложений, от разработки виртуальной реальности и научных визуализаций до создания персонализированного контента для широкой аудитории. Такой прогресс способствует расширению возможностей для творчества и инноваций, делая генеративные модели более практичными и эффективными для повседневного использования.
Для полного раскрытия потенциала генерации контента на основе диффузионных моделей, дальнейшее изучение адаптивных стратегий, подобных DDiT, представляется критически важным. Исследования в этом направлении направлены на оптимизацию процесса генерации, позволяя достигать высокого качества контента при минимальных вычислительных затратах. Углубленное понимание механизмов адаптации позволит создавать более эффективные и масштабируемые модели, способные генерировать сложные изображения, видео и другие типы данных с беспрецедентной скоростью и детализацией. Перспективные направления включают разработку алгоритмов, динамически адаптирующих сложность генерации к доступным ресурсам, и изучение новых методов обучения, позволяющих моделям эффективно использовать ограниченные вычислительные мощности. Развитие адаптивных стратегий станет ключевым фактором в демократизации доступа к технологиям генерации контента и расширении области их применения.
![В ходе тестирования на DrawBench наша методика продемонстрировала устойчивые результаты даже при обработке сложных запросов, требующих глубокого понимания семантического содержания, превосходя базовый уровень и TaylorSeer[62].](https://arxiv.org/html/2602.16968v1/x8.png)
Исследование представляет собой попытку усмирить хаос данных, не путём их очистки, а путём адаптации к их изменчивости. Как и любое заклинание, предложенный метод DDiT, динамически изменяя размер патчей, стремится оптимизировать вычислительные затраты, не жертвуя качеством генерируемого изображения. Он словно алхимик, варьирующий пропорции ингредиентов, чтобы получить эликсир совершенства. Геффри Хинтон однажды заметил: «Данные — это не цифры, а шёпот хаоса. Их нельзя понять, только уговорить». И DDiT, по сути, и есть попытка уговорить данные, заставить их подчиниться воле создателя, используя гибкость латентного пространства.
Куда же дальше?
Представленная работа, словно удачно примененное заклинание, демонстрирует, как можно обуздать неумолимый поток вычислений в диффузионных трансформаторах. Однако, не стоит обманываться кажущейся эффективностью. Ускорение, достигнутое за счет динамического изменения размера патчей, — это лишь временное затишье перед бурей растущих объемов данных и усложняющихся моделей. Истинный вопрос заключается не в том, как быстрее генерировать изображения, а в том, что мы хотим с помощью этих изображений сказать. И, главное, услышит ли кто-нибудь.
Очевидно, что динамическая адаптация гранулярности представления — лишь один из инструментов в арсенале исследователя. Следующим шагом видится не просто оптимизация существующих архитектур, а поиск принципиально новых способов кодирования и декодирования информации. Вместо того, чтобы гнаться за «точностью», возможно, стоит обратить внимание на «интересность» или «осмысленность» генерируемых результатов. Ведь данные — это лишь тени, а модели — лишь способы измерить темноту.
В конечном счете, успех этого направления исследований будет зависеть не от скорости вычислений, а от способности видеть за случайными флуктуациями латентного пространства проблески подлинного творчества. Иначе все эти оптимизации — лишь красивая иллюзия, обреченная раствориться в хаосе реальности.
Оригинал статьи: https://arxiv.org/pdf/2602.16968.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Диффузия и обучение с подкреплением: новый подход к масштабированию
- Квантовые алгоритмы против нейросетей: есть ли смысл в переходе?
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
- Квантовый код: Слияние классики и управления
- Пишущий разум: Как ИИ меняет процесс создания текстов
- Эко-интеллект: Как сделать ИИ более экологичным
- Квантовый транспорт в сложных системах: новый подход к моделированию
2026-02-20 06:45