Автор: Денис Аветисян
Статья представляет видение создания комплексной экосистемы, в которой искусственный интеллект станет неотъемлемой частью всех этапов экспериментальных исследований в области физики частиц.
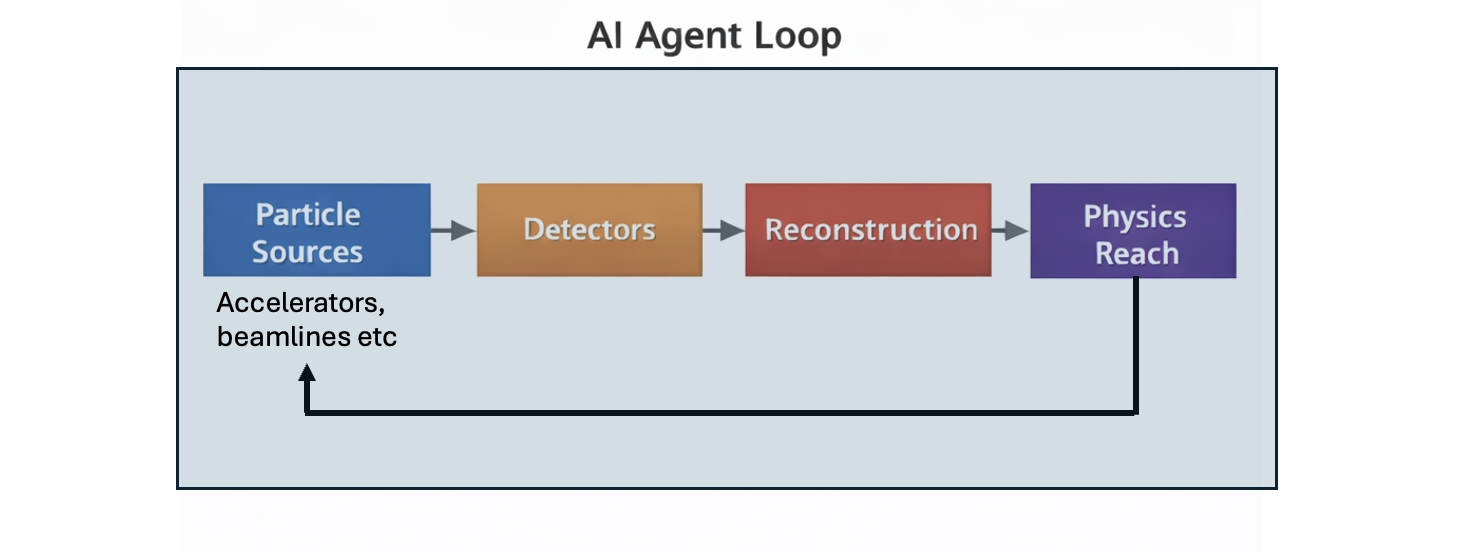
Разработка инфраструктуры и интеграция методов машинного обучения для ускорения научных открытий и повышения эффективности экспериментов.
Несмотря на впечатляющий прогресс в физике элементарных частиц, анализ огромных объемов данных, генерируемых современными экспериментами, остается серьезной проблемой. Данная статья, ‘Building an AI-native Research Ecosystem for Experimental Particle Physics: A Community Vision’, предлагает комплексное видение интеграции искусственного интеллекта (ИИ) во все аспекты исследований, от сбора и обработки данных до проектирования будущих установок. Ключевой идеей является создание самодостаточной исследовательской экосистемы, способной значительно ускорить научные открытия и расширить границы нашего понимания фундаментальных законов природы. Сможем ли мы построить такую экосистему, чтобы в полной мере использовать потенциал будущих экспериментов, таких как HL-LHC, DUNE и FCC-ee?
Лавина Данных: Вызовы Современной Экспериментальной Науки
Современные эксперименты, особенно в таких областях как геномика, астрономия и физика высоких энергий, генерируют данные с невиданной ранее скоростью. Объемы информации растут экспоненциально, превосходя возможности традиционных методов анализа и обработки. Если раньше ученые могли вручную просматривать и интерпретировать результаты, то сейчас речь идет о петабайтах и эксабайтах данных, требующих автоматизированных и высокопроизводительных систем. Эта лавина информации создает серьезные проблемы: от хранения и передачи данных до их эффективной обработки и извлечения полезных знаний. Неспособность справиться с этим потоком информации замедляет темпы научных открытий и требует разработки принципиально новых подходов к анализу данных, основанных на алгоритмах машинного обучения, облачных вычислениях и параллельной обработке.
Современный научный прогресс характеризуется экспоненциальным ростом объемов собираемых данных, что требует принципиально новых подходов к их обработке и интерпретации. Традиционные методы анализа зачастую оказываются неспособными эффективно извлекать полезную информацию из этого потока, что приводит к задержкам в научных открытиях. Для преодоления этой проблемы исследователи активно разрабатывают алгоритмы машинного обучения, методы визуализации больших данных и инструменты автоматизированного анализа, позволяющие выявлять скрытые закономерности и зависимости, которые ранее оставались незамеченными. Акцент делается на разработку самообучающихся систем, способных адаптироваться к различным типам данных и автоматически выявлять значимые тенденции, что открывает новые возможности для исследования сложных явлений и процессов.
Современные методы анализа данных, разработанные для более скромных объемов информации, зачастую оказываются неспособны эффективно обрабатывать экспоненциально растущие потоки, генерируемые передовыми экспериментами. Это приводит к существенному замедлению темпов научных открытий, поскольку исследователи тратят все больше времени и ресурсов на обработку и интерпретацию данных, а не на саму научную работу. Необходимость в инновационных решениях для управления данными становится критически важной, требуя разработки новых алгоритмов, инструментов и инфраструктур, способных не только хранить и обрабатывать большие объемы информации, но и извлекать из них ценные знания и закономерности. Без таких решений потенциал современных экспериментов остается нереализованным, а прогресс науки замедляется.
Эффективное управление данными в современных экспериментах перестало быть простой задачей логистики; оно стало критическим препятствием на пути к новым знаниям. Огромные объемы информации, генерируемые передовыми исследованиями, требуют не только хранения, но и быстрой обработки, анализа и интерпретации. Задержки в этих процессах, вызванные недостаточной эффективностью систем управления данными, напрямую замедляют темпы научных открытий. Исследователи сталкиваются с ситуацией, когда время, затрачиваемое на организацию и обработку данных, сопоставимо со временем, потраченным на само проведение экспериментов. Таким образом, развитие инновационных подходов к управлению данными — это не просто техническая необходимость, а фундаментальное условие для прогресса в любой научной области, позволяющее извлечь максимальную пользу из ценных экспериментальных результатов.
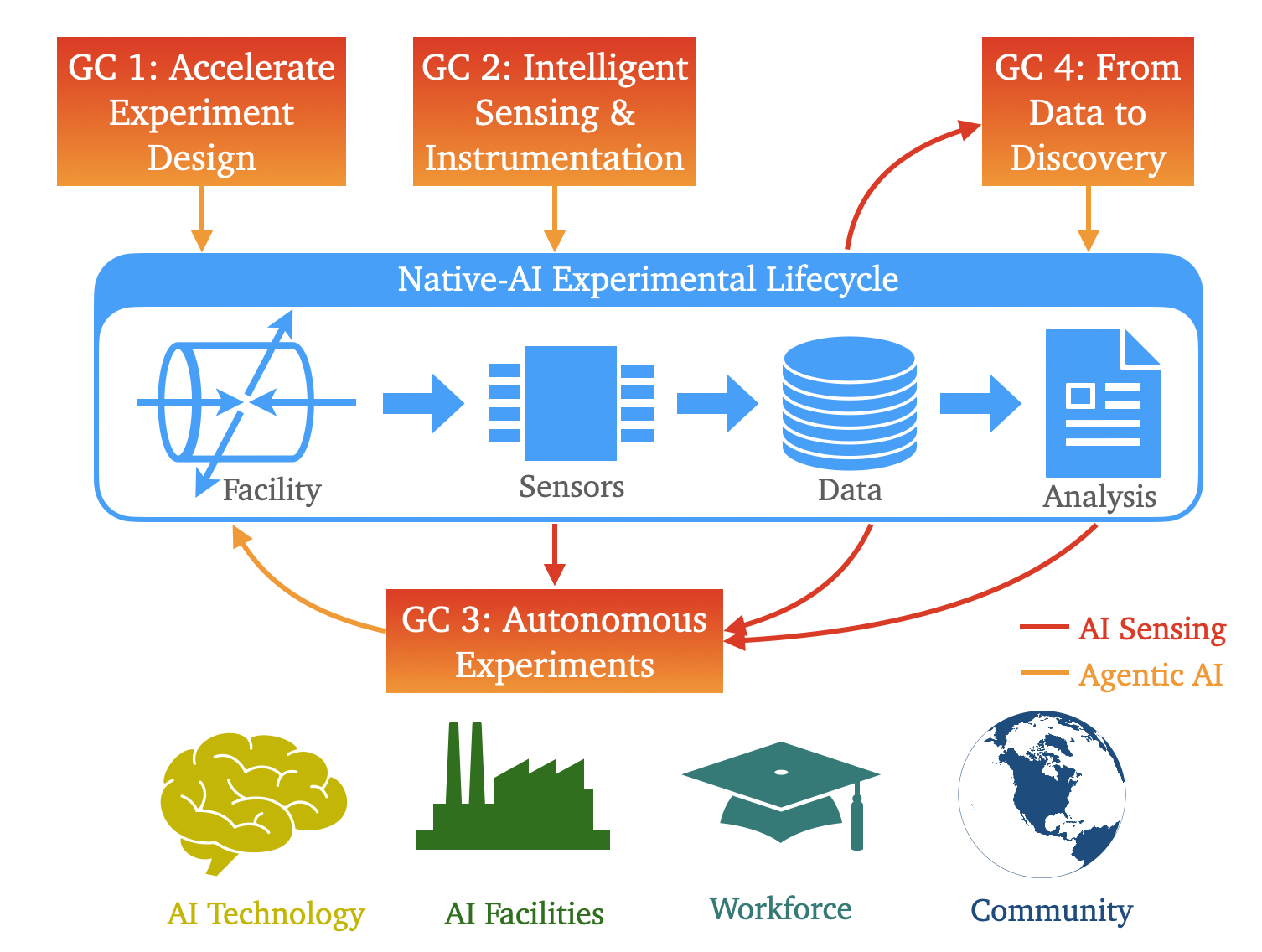
Искусственный Интеллект на Службе Науки: Ускорение Анализа Данных
Традиционные методы анализа данных часто сталкиваются с ограничениями при работе с неполными, зашумленными или высокоразмерными наборами данных, особенно в таких областях, как материаловедение, биология и физика. Использование методов моделирования и реконструкции на основе искусственного интеллекта позволяет преодолеть эти ограничения, восстанавливая недостающие данные и создавая более полные и точные представления о исследуемых системах. Эти техники включают в себя алгоритмы машинного обучения, способные выявлять закономерности и взаимосвязи в данных, экстраполировать информацию и создавать модели, которые более точно отражают реальность, чем это возможно при использовании только традиционных статистических методов. В частности, AI-методы позволяют эффективно обрабатывать данные, полученные в результате сложных экспериментов или симуляций, и получать из них значимые результаты, которые могут быть использованы для дальнейшего анализа и принятия решений.
Использование базовых моделей (Foundation Models) позволяет создавать адаптивные методы реконструкции и физического моделирования, что способствует извлечению более глубоких знаний из сложных данных. В отличие от традиционных подходов, требующих специализированных моделей для каждой задачи, базовые модели, предварительно обученные на огромных объемах данных, могут быть адаптированы для решения широкого спектра задач реконструкции и моделирования, включая обработку изображений, анализ сигналов и прогнозирование физических процессов. Такая адаптивность достигается за счет тонкой настройки (fine-tuning) базовой модели на специфических данных, что значительно сокращает время и ресурсы, необходимые для разработки новых моделей. Возможность интеграции физических принципов непосредственно в процесс обучения базовых моделей позволяет получать более точные и интерпретируемые результаты, а также повышает устойчивость моделей к шумам и неполноте данных.
Дифференцируемое моделирование интегрирует процессы моделирования в рамки искусственного интеллекта, позволяя осуществлять оптимизацию и анализ с беспрецедентной эффективностью. Традиционно, симуляции и методы машинного обучения функционировали как отдельные этапы в научном процессе. Дифференцируемое моделирование устраняет это разделение, позволяя вычислять градиенты сквозь симуляции. Это означает, что параметры симуляции могут быть оптимизированы с использованием тех же алгоритмов, что и параметры нейронных сетей, например, градиентного спуска. Такой подход позволяет автоматически настраивать модели, находить оптимальные решения и проводить анализ чувствительности, значительно ускоряя процесс научных исследований и открытий. Это особенно полезно в областях, где прямые измерения затруднены или невозможны, позволяя извлекать информацию из симуляций, как если бы они были реальными данными.
Быстрое генерирование данных является критически важным для эффективного обучения и валидации моделей искусственного интеллекта, используемых в научных исследованиях. Недостаток достаточного объема размеченных данных часто ограничивает возможности обучения, особенно в задачах, требующих высокой точности и надежности. Использование методов, таких как синтез данных и генеративные модели, позволяет создавать большие объемы данных для обучения, обходя ограничения, связанные со сбором и аннотированием реальных данных. Процесс валидации, включающий оценку производительности модели на независимом наборе данных, требует значительного объема проверочных данных для обеспечения статистической значимости результатов и предотвращения переобучения. Автоматизация процесса генерации данных позволяет значительно ускорить цикл разработки и тестирования моделей, снижая затраты и повышая общую эффективность научных исследований.
![Схема демонстрирует автоматизированный и оптимизируемый процесс анализа данных, основанный на методике, представленной в [11].](https://arxiv.org/html/2602.17582v1/images/Analysis_Diagram_summary.png)
Автономные Эксперименты: Новое Поколение Научных Установок
Использование AI-Native экспериментального дизайна предполагает применение алгоритмов искусственного интеллекта для оптимизации параметров эксперимента и расположения детекторов. Этот подход позволяет максимизировать научную отдачу за счет автоматического поиска оптимальных конфигураций, учитывающих множество факторов и ограничений. В отличие от традиционных методов, основанных на ручном подборе или эвристических правилах, AI-Native дизайн использует методы машинного обучения для анализа данных, прогнозирования результатов и итеративной оптимизации экспериментальной установки. Это позволяет значительно повысить эффективность экспериментов, сократить время, необходимое для получения значимых данных, и выявить закономерности, которые могли бы остаться незамеченными при использовании традиционных подходов.
Автономные эксперименты, основанные на агентных системах и цифровых двойниках, обеспечивают автоматизацию рутинных операций, калибровки оборудования и контроля качества данных. Агентные системы, представляющие собой программные агенты, способные самостоятельно принимать решения и действовать в соответствии с заданными целями, управляют экспериментальным процессом. Цифровые двойники, являющиеся виртуальными копиями физических систем, используются для моделирования, оптимизации и предсказания поведения оборудования, что позволяет проводить предварительное тестирование и повышать надежность экспериментов. Автоматизация данных процессов минимизирует человеческий фактор, сокращает время проведения экспериментов и повышает точность получаемых результатов.
Интеллектуальные сенсоры и измерительные приборы позволяют оптимизировать сбор данных и их сжатие, существенно уменьшая объём генерируемой информации без потери значимых деталей. Это достигается за счет применения алгоритмов обработки сигналов в реальном времени, адаптивной дискретизации и интеллектуальной фильтрации шумов. Современные системы способны выявлять и отбрасывать избыточные или нерелевантные данные, сохраняя при этом критически важные характеристики сигнала, необходимые для дальнейшего анализа и научных исследований. Использование таких технологий снижает требования к пропускной способности каналов связи и объёму хранилищ данных, что особенно актуально для крупномасштабных научных установок.
Автоматизация рутинных задач в экспериментальных установках позволяет ученым переключить фокус на генерацию гипотез и интерпретацию полученных данных, что повышает эффективность исследований. Данная инициатива направлена на поддержку национальной цели США по подготовке 100 тысяч специалистов в области искусственного интеллекта, предоставляя им практический опыт в применении ИИ для автоматизации научных процессов и анализа больших объемов данных, что способствует развитию кадрового потенциала в критически важной области.
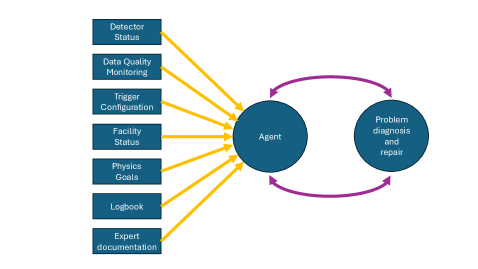
Американское Научное Облако: Национальная Инфраструктура для Научных Открытий
Американское Научное Облако предоставляет критически важную инфраструктуру для поддержки исследований, основанных на искусственном интеллекте, в масштабах всей страны. Это не просто вычислительные мощности, а комплексная экосистема, включающая хранилища данных, инструменты для анализа и платформы для совместной работы, позволяющие ученым эффективно использовать возможности машинного обучения и глубокого обучения. Облако спроектировано для обработки огромных объемов данных, генерируемых современными научными экспериментами, и автоматизации сложных процессов моделирования и симуляции. Такая инфраструктура существенно ускоряет темпы научных открытий, позволяя исследователям проводить анализ, который ранее был невозможен из-за ограничений в вычислительных ресурсах и объеме доступных данных, а также способствует развитию новых, прорывных технологий.
Концепция “Рабочие процессы как услуга” (Workflow as a Service) в рамках American Science Cloud обеспечивает возможность динамического выделения вычислительных ресурсов и запуска сложных научных симуляций. Это позволяет исследователям не тратить время на настройку и администрирование инфраструктуры, а сосредоточиться непосредственно на анализе данных и проверке гипотез. Такой подход значительно ускоряет процесс научных открытий, поскольку позволяет быстро масштабировать вычислительные мощности в соответствии с потребностями конкретного проекта. Вместо того, чтобы ждать доступности ресурсов, симуляции запускаются практически мгновенно, что существенно сокращает время от постановки задачи до получения результатов и, как следствие, стимулирует инновации в различных областях науки.
Опыт сообщества физики высоких энергий (HEP) остается незаменимым элементом успешной реализации проектов, использующих искусственный интеллект в научных исследованиях. Эксперты в данной области обладают уникальными знаниями, необходимыми для корректной интерпретации результатов, полученных с помощью алгоритмов машинного обучения, и для их последующей верификации. Они способны выявлять и устранять потенциальные ошибки в моделях, а также адаптировать их к специфическим требованиям конкретных экспериментов и задач. Этот домен-специфический опыт позволяет не только повысить точность и надежность научных открытий, но и эффективно направлять развитие и совершенствование самих AI-моделей, обеспечивая их соответствие реальным потребностям исследовательского сообщества.
Планируемый научно-исследовательский комплекс, построенный на базе национальной научной облачной инфраструктуры, призван кардинально изменить подходы к проведению экспериментов и стимулировать инновации. Предполагается, что в течение пяти лет он обеспечит рабочие места для приблизительно 120 штатных сотрудников, а общее число участников проекта достигнет двухсот человек. Помимо проведения передовых исследований, инициатива ставит перед собой важную образовательную задачу: в течение десяти лет планируется подготовить около 2000 аспирантов и 20000 студентов бакалавриата, предоставляя им доступ к современным инструментам и технологиям в области искусственного интеллекта и научных вычислений. Это позволит сформировать новое поколение ученых, способных эффективно использовать возможности искусственного интеллекта для решения сложнейших научных задач.

В стремлении создать самообучающуюся экосистему для анализа данных, описанную в документе, легко увидеть закономерность, знакомую любому, кто долго работает с системами. Авторы предлагают использовать возможности искусственного интеллекта на всех этапах — от сбора данных до проектирования установок. Однако, за этим оптимизмом скрывается неизбежный компромисс. Как верно заметил Блез Паскаль: «Все великие дела требуют времени». Попытки ускорить научные открытия посредством ИИ — это, безусловно, прогресс, но не стоит забывать, что даже самые передовые модели требуют тщательной проверки и адаптации к реальным условиям. В конечном итоге, архитектура любой системы — это не идеальный план, а последовательность компромиссов, выживших после внедрения.
Что дальше?
Предложенная концепция «AI-native» экосистемы, как и большинство «революционных» идей, неизбежно столкнётся с суровой реальностью. Заманчивые перспективы ускорения научных открытий, вероятно, потребуют колоссальных инвестиций в инфраструктуру, которая, как известно, имеет свойство устаревать ещё до ввода в эксплуатацию. Если система стабильно падает под нагрузкой, значит, она хотя бы последовательна. Идея использования «foundation models» выглядит привлекательно, но кто гарантирует, что эти модели не начнут выдавать красивые, но абсолютно бесполезные результаты, которые придётся долго и мучительно отлаживать?
Основная проблема, как всегда, заключается не в алгоритмах, а в данных. В физике высоких энергий объёмы данных растут экспоненциально, а качество — не всегда. Автоматическое обнаружение аномалий — это прекрасно, но кто будет разбираться в тех редких случаях, когда аномалия — это не ошибка, а открытие? В конечном итоге, вся эта «cloud-native» архитектура — это просто тот же самый код, только дороже и с большим количеством точек отказа.
Можно с уверенностью сказать, что через десять лет большая часть этих «инноваций» будет восприниматься как должное, а новые проблемы потребуют ещё более изощрённых решений. И, возможно, будущие археологи, копающиеся в этих кодовых базах, поймут, что мы не писали код — мы просто оставляли комментарии для них.
Оригинал статьи: https://arxiv.org/pdf/2602.17582.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусство синтеза: Новая модель для объединения текста и изображений
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Квантовые Загадки: От Теории к Реальности
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Диффузия и обучение с подкреплением: новый подход к масштабированию
- Квантовые алгоритмы против нейросетей: есть ли смысл в переходе?
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
2026-02-20 06:51