Автор: Денис Аветисян
Автоматизация выполнения и диагностики эмпирических социальных исследований позволяет значительно повысить надежность и масштабируемость научных результатов.
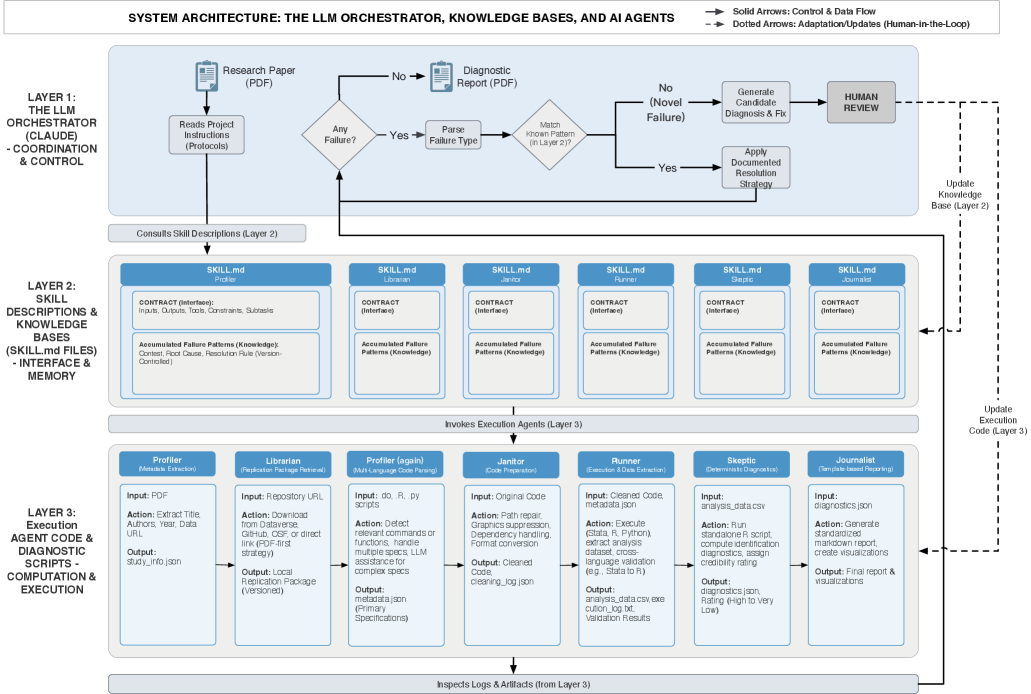
Представлен AI-ассистируемый рабочий процесс для крупномасштабного повторного анализа и проверки надежности исследований в области социальных наук.
Воспроизводимость исследований является краеугольным камнем научной достоверности, однако крупномасштабный переанализ эмпирических данных часто затруднен из-за разнородности пакетов репликации. В работе ‘Scaling Reproducibility: An AI-Assisted Workflow for Large-Scale Reanalysis’ представлен автоматизированный рабочий процесс на основе искусственного интеллекта, позволяющий преодолеть это препятствие при сохранении научной строгости. Система разделяет научное обоснование и вычислительное исполнение, автоматизируя сбор, гармонизацию и запуск материалов для репликации с использованием предварительно определенных, версионированных кодов, и достигает 87% успешного завершения в анализе 92 исследований, включая 67 с подтвержденными результатами двухшаговой наименьших квадратов (2SLS). Сможет ли предложенный подход существенно снизить стоимость выполнения устоявшихся эмпирических протоколов и расширить возможности для масштабного анализа в различных областях социальных наук?
Кризис воспроизводимости в современной науке
Наблюдается тревожная тенденция, подтверждаемая растущим объемом данных: значительная часть опубликованных эмпирических исследований сталкивается с трудностями или оказывается вовсе невоспроизводимой. Это означает, что другие ученые, пытаясь повторить эксперименты и получить аналогичные результаты, часто терпят неудачу. Проблема охватывает широкий спектр научных дисциплин, от психологии и медицины до экономики и биологии, ставя под вопрос надежность накопленных знаний. Неспособность подтвердить первоначальные выводы не обязательно свидетельствует о преднамеренном мошенничестве, но может быть вызвана недостаточной детализацией методологии, статистическими ошибками, или же специфическими условиями проведения эксперимента, которые не были учтены при публикации. Эта ситуация замедляет научный прогресс и требует пересмотра подходов к проведению и верификации исследований.
Традиционные методы верификации научных результатов, зачастую основанные на ручной проверке и повторном проведении экспериментов, становятся серьезным препятствием для развития науки. Данный процесс требует значительных временных затрат и подвержен человеческому фактору, что может приводить к ошибкам в интерпретации данных или неточностям при воспроизведении экспериментальной установки. Эта ручная работа, в условиях растущего объема публикуемых исследований, формирует узкое место, замедляющее темпы научного прогресса и увеличивающее риск распространения недостоверной информации. Необходимость в более эффективных и автоматизированных системах верификации становится все более очевидной для обеспечения надежности и воспроизводимости научных знаний.
Невозможность воспроизведения результатов исследований подрывает доверие к научным утверждениям и препятствует формированию достоверных знаний. Этот кризис воспроизводимости ставит под вопрос надежность накопленного научного багажа и замедляет прогресс в различных областях. Традиционные методы верификации оказываются недостаточными для обеспечения надежности научных выводов, что требует разработки новых, более эффективных подходов к валидации. В частности, возрастает потребность в автоматизированных системах проверки данных, открытом доступе к исходным данным и коду, а также в более строгих стандартах отчетности, чтобы обеспечить прозрачность и возможность независимой проверки научных результатов. Преодоление этого кризиса — ключевая задача для сохранения авторитета науки и обеспечения ее дальнейшего развития.
Агентский рабочий процесс для автоматизированного воспроизведения
Разработанный нами агентский AI-workflow автоматизирует процесс получения пакетов для воспроизведения исследований и выполнения эмпирических анализов. Система позволяет загружать комплекты данных и скрипты, необходимые для повторного проведения анализа, и автоматически запускает их выполнение. Автоматизация охватывает все этапы, от извлечения исходных материалов из репозиториев до запуска аналитических процедур и сбора результатов, что минимизирует ручное вмешательство и потенциальные ошибки, связанные с человеческим фактором. Это позволяет исследователям быстро и надежно проверять и воспроизводить результаты опубликованных исследований, а также проводить собственные анализы на основе стандартизированных протоколов.
В основе разработанного рабочего процесса лежит использование детерминированных агентов, каждый из которых отвечает за конкретный этап анализа воспроизводимости. Детерминированность агентов гарантирует, что при одинаковых входных данных и начальных условиях, агент всегда выдает идентичный результат. Это достигается путем четкого определения логики каждого агента и исключения недетерминированных операций. Разделение процесса анализа на последовательность четко определенных этапов, выполняемых детерминированными агентами, обеспечивает согласованность и воспроизводимость результатов, что критически важно для эмпирических исследований и проверки научных результатов.
Система оркестрируется LLM-оркестратором, который управляет полным жизненным циклом пайплайна воспроизводимости. Этот компонент отвечает за координацию выполнения задач отдельными агентами, обеспечивая последовательное выполнение этапов анализа. В рамках управления пайплайном, LLM-оркестратор также осуществляет мониторинг и обработку потенциальных ошибок, возникающих в процессе выполнения, и реализует механизмы для их устранения или обхода, что позволяет автоматизировать процесс воспроизведения результатов эмпирических исследований с минимальным вмешательством человека.
Описания навыков (Skill Descriptions) представляют собой формальные спецификации, определяющие интерфейсы и базы знаний для каждого агента в системе. Эти описания стандартизируют взаимодействие между агентами, позволяя четко определить входные и выходные данные каждого этапа анализа. Благодаря этому подходу, агенты становятся модульными компонентами, которые можно повторно использовать в различных аналитических пайплайнах. Формализация знаний и интерфейсов облегчает замену или обновление отдельных агентов без необходимости переписывать всю систему, что значительно повышает гибкость и масштабируемость автоматизированного процесса воспроизводимости.
Статистическая строгость благодаря автоматизированной диагностике
В состав рабочего процесса искусственного интеллекта входит набор статистических диагностических инструментов, применяющих установленные статистические тесты для оценки надежности эмпирических результатов. Данные тесты включают проверку на наличие выбросов, оценку нормальности распределения остатков, анализ гетероскедастичности и автокорреляции, а также тесты на стационарность временных рядов. Автоматизация применения этих тестов позволяет систематически оценивать устойчивость полученных результатов к различным нарушениям предположений, что способствует повышению доверия к выводам исследования и обеспечивает возможность выявления потенциальных проблем на ранних этапах анализа.
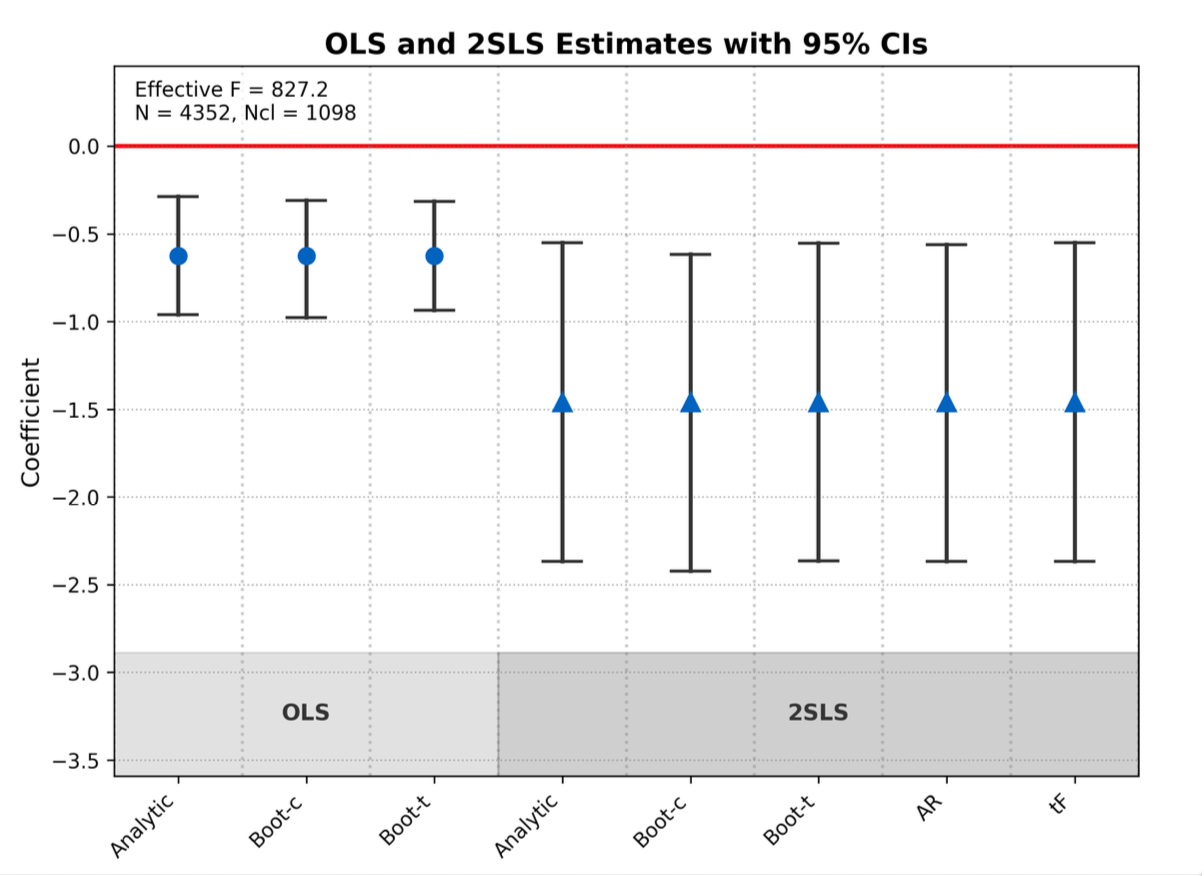
Система включает в себя возможность применения продвинутых статистических оценок, таких как двухшаговый метод наименьших квадратов (2SLS), для решения проблемы эндогенности. Эндогенность возникает, когда независимая переменная коррелирует с ошибкой в модели, что приводит к смещенным и несостоятельным оценкам. 2SLS позволяет получить состоятельные оценки путем использования инструментальных переменных, которые коррелируют с эндогенной переменной, но не коррелируют с ошибкой. Данный метод предполагает построение вспомогательной регрессии для предсказания значений эндогенной переменной, которые затем используются в основной регрессии, обеспечивая корректную оценку параметров модели и минимизируя смещение, вызванное эндогенностью.
Автоматизация статистических тестов позволяет обеспечить последовательное и единообразное применение принципов статистической строгости при анализе данных. В ручном режиме, интерпретация и применение статистических методов могут варьироваться в зависимости от опыта и субъективных оценок исследователя, что приводит к потенциальным искажениям и снижению воспроизводимости результатов. Автоматизированный подход исключает эту вариативность, гарантируя, что каждый анализ проводится по четко определенным и стандартизированным протоколам. Это, в свою очередь, минимизирует влияние человеческого фактора и повышает объективность получаемых выводов, что особенно важно для обеспечения надежности и достоверности эмпирических исследований.
Автоматизированный рабочий процесс продемонстрировал 92.5%-ный уровень успешного воспроизведения эмпирических исследований в области социальных наук. Данный показатель был достигнут на основе анализа корпуса, состоящего из 92 исследований, использующих инструментальные переменные (IV). Успешное воспроизведение определялось как получение сопоставимых результатов статистического анализа, используя автоматизированные процедуры и исходные данные, доступные для каждого исследования. Высокий процент успешного воспроизведения указывает на надежность и стабильность автоматизированного процесса, а также на его потенциал для повышения воспроизводимости научных исследований в социальных науках.
К самообучающейся системе валидации
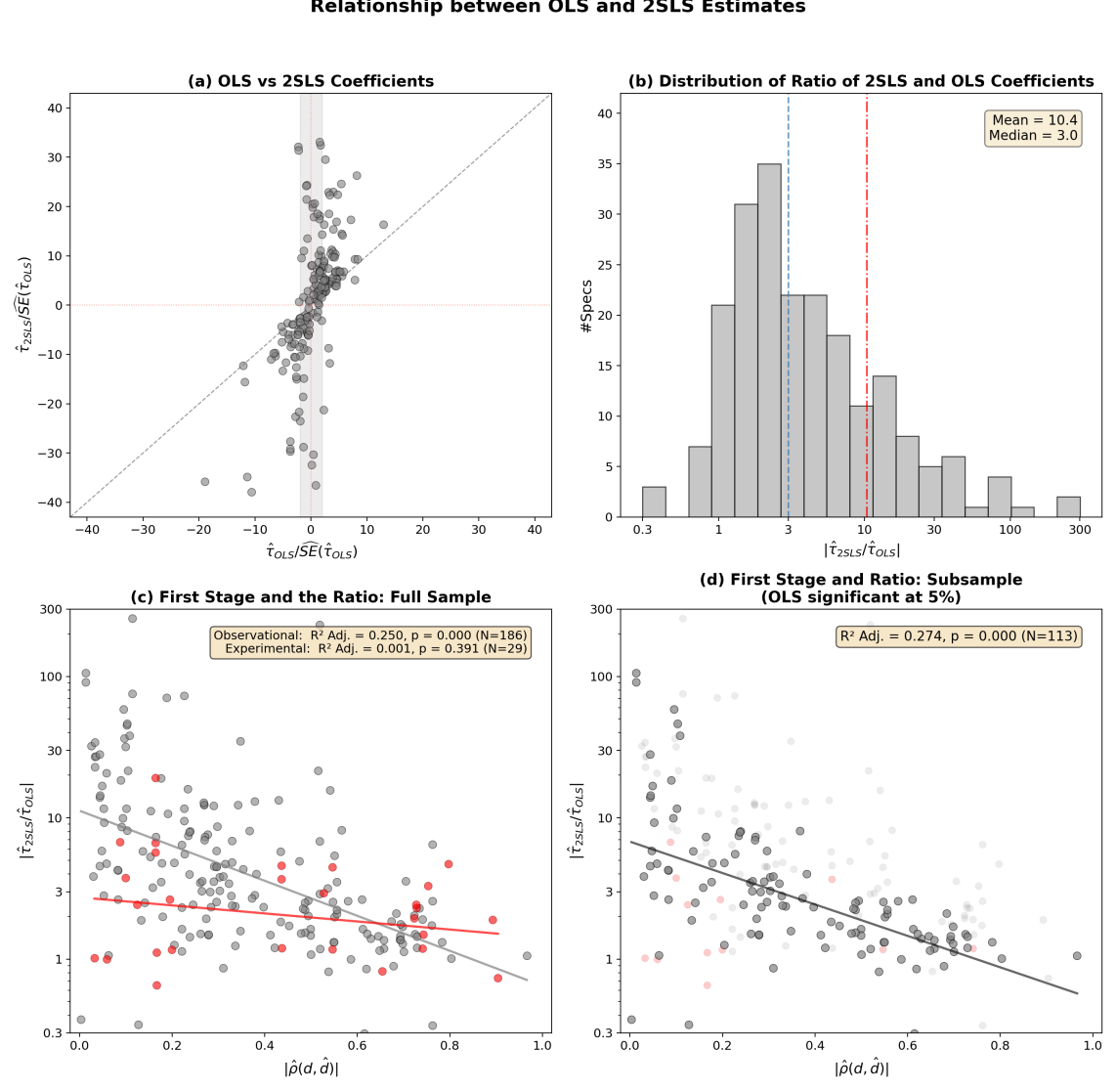
В основе разработанного искусственного интеллекта лежит принцип адаптивного исполнения, позволяющий системе не просто выполнять анализ, но и извлекать уроки из допущенных ошибок. Этот механизм самообучения функционирует следующим образом: при обнаружении несоответствия или неточности, система анализирует причины возникновения проблемы и корректирует собственные алгоритмы, улучшая точность и надежность последующих результатов. В отличие от традиционных систем валидации, требующих постоянного вмешательства человека, данная архитектура позволяет искусственному интеллекту самостоятельно совершенствоваться, повышая эффективность и скорость выявления потенциальных проблем в научных данных. Такой подход к самооптимизации открывает новые возможности для автоматизации и повышения доверия к результатам научных исследований.
Система, благодаря механизму обратной связи, способна к постоянному усовершенствованию методов анализа и более эффективному выявлению потенциальных проблем. В процессе работы, каждое обнаруженное несоответствие или ошибка не просто фиксируется, но и используется для корректировки алгоритмов, лежащих в основе проверки данных. Это позволяет системе адаптироваться к разнообразным вариациям в научных исследованиях и постепенно повышать точность выявления аномалий, которые могли бы остаться незамеченными при традиционных подходах. В результате, система не только проверяет текущие данные, но и учится на предыдущем опыте, обеспечивая непрерывное улучшение качества валидации и повышая надежность научных результатов.
Система успешно выявила и устранила десять различных классов ошибок, возникающих при реализации научных вычислений. Этот каталог охватывает наиболее распространенные вариации, включая неверные единицы измерения, ошибки в порядке операндов, неточности при преобразовании данных, несоответствия в соглашениях об именах, и другие подобные проблемы. Важно отметить, что эта коллекция не является статичной — система постоянно пополняется новыми классами ошибок, обнаруженными в процессе адаптивного анализа. Создание столь полного и динамичного перечня позволяет не только автоматически исправлять существующие проблемы, но и предвидеть потенциальные ошибки в будущих вычислениях, значительно повышая надежность и воспроизводимость научных результатов.
Автоматизация и непрерывное совершенствование процесса валидации призваны восстановить доверие к научным результатам и ускорить темпы открытий. Традиционно, проверка научных данных требует значительных временных и трудовых затрат, что создает узкие места в процессе исследований. Данная система, благодаря адаптивному обучению, способна не только выявлять ошибки, но и совершенствовать собственные методы анализа, уменьшая потребность в ручном вмешательстве. Это позволяет исследователям сосредоточиться на инновациях, а не на рутинной проверке, что в конечном итоге приводит к более быстрому и надежному прогрессу в различных научных областях. Внедрение подобного подхода открывает путь к более эффективной проверке гипотез и повышению воспроизводимости научных результатов, что является ключевым фактором для укрепления научного знания.
Представленная работа демонстрирует стремление к повышению воспроизводимости эмпирических социальных исследований посредством автоматизации и диагностического тестирования. Авторы, по сути, предлагают не просто инструмент, а методологический сдвиг, признавая, что любая модель — это компромисс между знанием и удобством. Как метко заметил Джон Дьюи: «Образование — это не подготовка к жизни; образование — это сама жизнь». В контексте данного исследования, это означает, что процесс воспроизведения результатов не должен быть отдельным этапом, а неотъемлемой частью исследовательского цикла. Внедрение AI-ассистируемого рабочего процесса, описанного в статье, направлено на то, чтобы сделать этот цикл более прозрачным, надежным и, следовательно, более ценным для научного сообщества. Авторы справедливо отмечают необходимость масштабирования воспроизводимости, что особенно важно в эпоху больших данных и сложных моделей.
Куда двигаться дальше?
Представленный здесь автоматизированный рабочий процесс, безусловно, является шагом вперед в решении проблемы воспроизводимости эмпирических социальных наук. Однако, не стоит обольщаться иллюзией полного контроля. Автоматизация, хотя и снижает вероятность банальных ошибок, не устраняет фундаментальную проблему — неадекватность моделей реальности. Данные остаются лишь компромиссом между шумом и моделью, а корреляция, даже подтвержденная автоматизированными тестами, не подразумевает причинно-следственной связи.
Наиболее сложной задачей представляется расширение возможностей диагностики. Автоматизированное выполнение кода — лишь половина дела. Необходимо разработать инструменты, способные оценивать адекватность теоретических предпосылок, выявлять скрытые смещения в данных и оценивать чувствительность результатов к изменениям в спецификации модели. Особое внимание следует уделить развитию методов каузального вывода, поскольку простая статистическая значимость не гарантирует валидности выводов.
В конечном счете, успех этого направления исследований зависит не только от технических инноваций, но и от изменения научной культуры. Необходимо создать систему, в которой воспроизводимость рассматривается не как обременительная процедура, а как неотъемлемая часть научного процесса. И самое главное — помнить, что самая опасная ошибка — красивая корреляция без контекста.
Оригинал статьи: https://arxiv.org/pdf/2602.16733.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Неупорядоченные системы с неэрмитовыми эффектами
- Безопасность генерации изображений: новый вектор управления
- Искусственный интеллект на страже кода: новая оценка качества
2026-02-20 13:37