Автор: Денис Аветисян
Исследователи разработали метод, позволяющий роботам лучше понимать окружающую среду и планировать свои действия, используя возможности диффузионных моделей и визуально-языкового обучения.
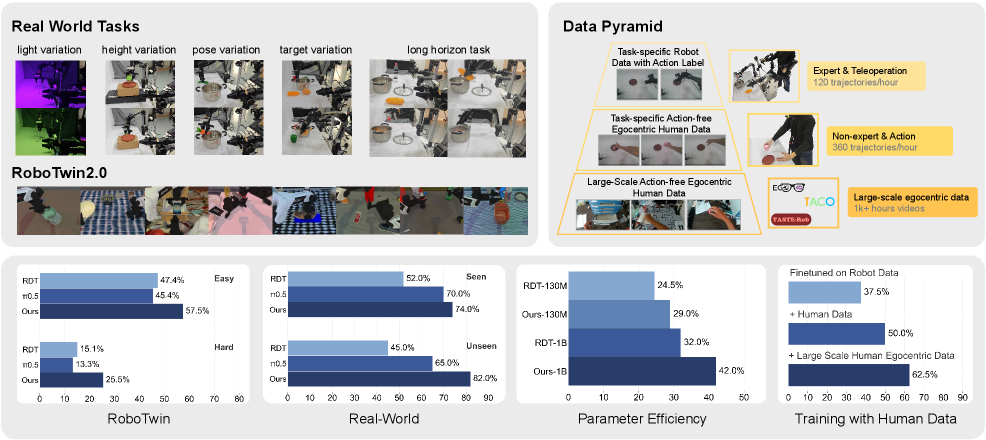
FRAPPE: схема обучения, улучшающая согласование визуально-языковых представлений и параллельное масштабирование в диффузионных моделях для робототехники, позволяющая эффективно использовать данные, собранные от первого лица.
Несмотря на успехи в обучении роботов, предсказание динамики окружающей среды и обобщение опыта остаются сложной задачей. В данной работе, посвященной методу ‘FRAPPE: Infusing World Modeling into Generalist Policies via Multiple Future Representation Alignment’, предлагается новый подход к обучению моделей мирового моделирования, основанный на выравнивании представлений будущего и параллельном расширении вычислительной нагрузки. Предложенная схема обучения FRAPPE значительно повышает эффективность и масштабируемость, позволяя использовать данные, не размеченные вручную, и улучшать способность роботов к пониманию окружающей среды. Возможно ли дальнейшее развитие FRAPPE для создания действительно автономных роботов, способных адаптироваться к любым условиям и задачам?
Преодоление Разрыва Между Симуляцией и Реальностью: К Сути Воплощенного Искусственного Интеллекта
Традиционно обучение роботов часто осуществляется в симулированных средах, что создает заметный разрыв между виртуальной реальностью и сложностями реального мира. Эти симуляции, хотя и удобны для экспериментов и отладки, не могут в полной мере учесть непредсказуемость, шум и тонкие нюансы, присущие физическому взаимодействию. В результате роботы, обученные исключительно в симуляции, часто демонстрируют неустойчивое поведение и испытывают трудности при адаптации к реальным условиям, сталкиваясь с проблемами, вызванными несоответствием между ожидаемыми и фактическими сенсорными данными, а также неточностями в моделях физики. Данное несоответствие, известное как «разрыв между симуляцией и реальностью», является серьезным препятствием на пути к созданию надежных и гибких робототехнических систем, способных эффективно функционировать в неструктурированных и динамичных окружениях.
Существующий разрыв между симуляцией и реальностью требует от робототехники перехода к обучению непосредственно на основе богатого опыта взаимодействия с людьми. Традиционные методы, полагающиеся на виртуальные среды, зачастую не способны обеспечить надежное и адаптивное поведение роботов в реальном мире, где присутствуют непредсказуемые факторы и шум. Изучение человеческих действий, демонстраций и реакций позволяет роботам осваивать сложные навыки и стратегии, которые трудно запрограммировать напрямую. Такой подход, имитирующий обучение через наблюдение, позволяет создавать системы, способные к более гибкому и эффективному решению задач в динамичной окружающей среде, приближая их к уровню человеческой адаптивности и интуиции.
Для успешного преодоления разрыва между симуляцией и реальностью в обучении роботов, все большее значение приобретают крупномасштабные наборы данных, содержащие демонстрации действий, выполненных людьми. Однако, использование таких данных представляет собой серьезную проблему для алгоритмов машинного обучения, особенно в области представления данных. Сложность заключается в том, что человеческие демонстрации часто содержат избыточность, шум и разнообразие в способах выполнения одной и той же задачи. Для эффективного обучения роботов необходимо разрабатывать методы, способные извлекать значимую информацию из этих сложных данных, улавливать общие закономерности и игнорировать несущественные детали, что требует инновационных подходов к представлению и обработке информации, позволяющих создавать надежные и адаптивные системы искусственного интеллекта.
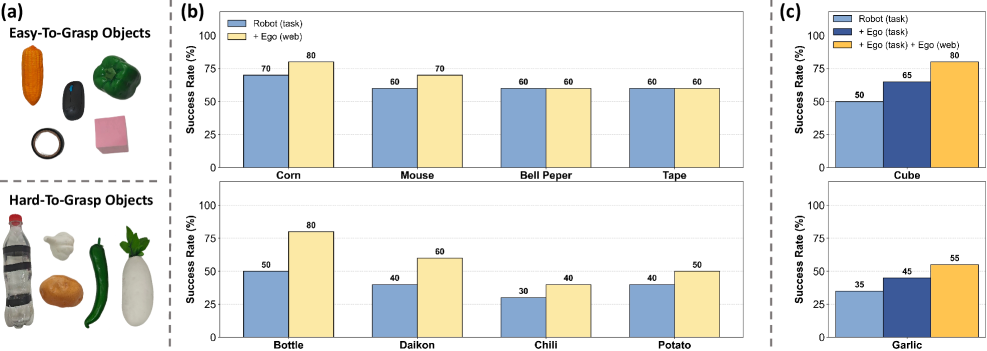
FRAPPE: Выравнивание Представлений для Надежной Робототехники
Метод FRAPPE представляет собой схему обучения, направленную на улучшение моделей Визуального Языка и Действий (VLA) посредством выравнивания визуальных представлений с будущими наблюдениями. В отличие от традиционных подходов, которые фокусируются на текущем состоянии, FRAPPE обучает модель прогнозировать и учитывать последующие визуальные данные. Это достигается путем использования будущих кадров в качестве целей обучения, что позволяет модели формировать более надежные и контекстуально-обоснованные представления окружающей среды. Выравнивание визуальных представлений с будущими наблюдениями повышает способность модели к предвидению и планированию действий в динамических условиях, улучшая общую производительность и устойчивость робота.
Ключевым элементом FRAPPE является использование параллельного масштабирования, позволяющего увеличить вычислительную мощность за счет применения множества экспертных сетей. Данный подход предполагает распределение вычислительной нагрузки между несколькими независимыми нейронными сетями, каждая из которых специализируется на определенной части задачи. За счет параллельной обработки данных, общая скорость обучения и вывода модели значительно возрастает. Использование нескольких экспертных сетей позволяет эффективно использовать доступные вычислительные ресурсы, особенно в условиях ограниченной памяти GPU или при обработке больших объемов данных. Параллельное масштабирование в FRAPPE позволяет модели обрабатывать более сложные сценарии и быстрее адаптироваться к новым условиям, улучшая общую производительность системы.
В схеме обучения FRAPPE используется эффективная стратегия обновления параметров, основанная на комбинации методов Prefix-tuning и LoRA (Low-Rank Adaptation). Prefix-tuning позволяет вводить обучаемые параметры в начале слоев трансформера, влияя на поведение модели без изменения исходных весов. LoRA, в свою очередь, замораживает предобученные веса и обучает низкоранговые матрицы, добавляемые к слоям трансформера. Сочетание этих двух подходов позволяет FRAPPE использовать преимущества каждого из них: гибкость Prefix-tuning и эффективность LoRA с точки зрения использования памяти и вычислительных ресурсов, что особенно важно при обучении больших моделей визуального языка и действий (VLA).
В условиях ограниченного объема обучающих данных, разработанный метод FRAPPE демонстрирует улучшение общей производительности на 10-15% по сравнению с базовым подходом, основанным исключительно на дистанционном управлении (телеоперации). Данное улучшение подтверждается экспериментальными результатами, показывающими, что FRAPPE эффективно использует доступные данные для обучения робота выполнению задач, превосходя производительность системы, полагающейся только на прямые команды оператора в сценариях с дефицитом обучающих примеров. Повышение производительности оценивалось по совокупности метрик, характеризующих успешность выполнения заданий и точность следования инструкциям.
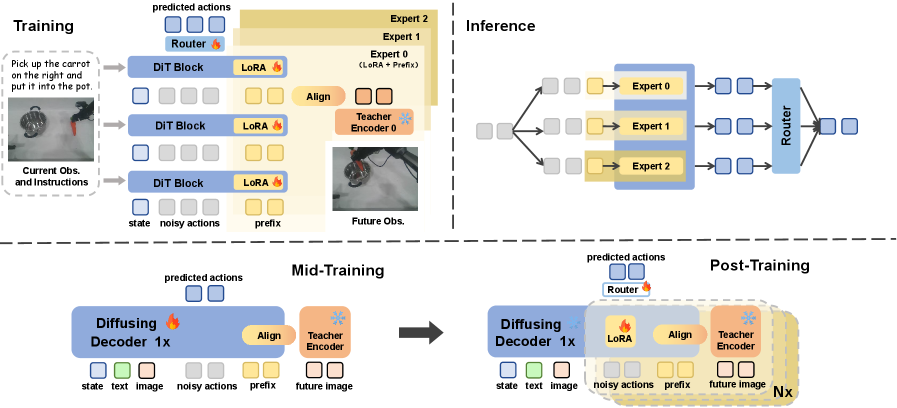
Роботизированный Диффузионный Трансформер: Основа для Интеллектуальной Манипуляции
Роботизированный диффузионный трансформер (RDT) использует диффузионные модели для генерации реалистичных и разнообразных действий робота. В отличие от традиционных подходов, основанных на детерминированных политиках или ограниченных наборах движений, RDT обучается модели вероятностного распределения действий. Это достигается путем постепенного добавления шума к целевым действиям во время обучения, а затем обучения модели обратного процесса — удаления шума для генерации новых действий. Такой подход позволяет RDT генерировать широкий спектр возможных действий, адаптируясь к различным сценариям и неопределенностям в окружающей среде, что обеспечивает более гибкое и надежное поведение робота.
Роботизированный диффузионный трансформер (RDT) использует механизмы перекрестного внимания (cross-attention) для эффективной интеграции визуальной и языковой информации, что способствует улучшению понимания задач. В архитектуре RDT перекрестное внимание позволяет модели соотносить признаки, полученные из визуальных данных (например, изображения с камеры робота), с текстовыми инструкциями или описаниями целей. Этот процесс обеспечивает более точное сопоставление между наблюдаемой обстановкой и желаемым поведением робота, что критически важно для выполнения сложных манипуляций и достижения поставленных задач. Механизмы перекрестного внимания позволяют модели динамически взвешивать вклад различных визуальных признаков в зависимости от контекста языковой инструкции, обеспечивая гибкость и адаптивность к изменяющимся условиям.
Архитектура Robotic Diffusion Transformer (RDT) использует мощные энкодеры для обработки визуальной и текстовой информации. В частности, для обработки изображений применяется энкодер SigLIP, демонстрирующий высокую эффективность в задачах визуального понимания. Для обработки текстовых инструкций используется энкодер T5, представляющий собой модель на основе архитектуры Transformer, обученную на большом корпусе текстовых данных. Комбинация SigLIP и T5 позволяет RDT эффективно интегрировать визуальные данные и языковые инструкции, необходимые для выполнения сложных манипулятивных задач.
Конкретная реализация, RDT-1B, представляет собой масштабируемую архитектуру, состоящую из 1 миллиарда параметров. Обучение проводилось на большом объеме данных, включающем 70 тысяч демонстраций робототехнических задач и 3 миллиона пар изображений с текстовыми описаниями. Эксперименты показали, что RDT-1B превосходит базовые модели RDT в сложных задачах манипулирования, демонстрируя способность к обобщению и адаптации к новым сценариям. Масштабируемость архитектуры позволяет эффективно использовать вычислительные ресурсы для обучения более сложных моделей и решения более широкого спектра задач.
В ходе тестирования на сложной задаче с долгосрочным планированием, модель Robotic Diffusion Transformer (RDT) продемонстрировала 20%-ный уровень успешного выполнения. Для сравнения, базовая версия RDT не смогла успешно выполнить задачу ни в одном из случаев, показав 0%-ный результат. Данный показатель свидетельствует о значительном улучшении способности RDT к планированию и выполнению комплексных манипуляций в условиях, требующих долгосрочного предвидения и адаптации к изменяющейся обстановке.

Обучение на Данных: Масштабирование с Помощью Пирамиды Данных
В основе подхода лежит концепция “Пирамиды данных”, позволяющая эффективно использовать разнородные источники информации для обучения роботов. Эта структура предполагает иерархическое использование данных, начиная с огромного объема пассивных наблюдений, полученных от первого лица — например, видеозаписи действий человека без необходимости активного взаимодействия с окружающей средой. Такие “бездейственные” данные, хотя и не содержат информации о конкретных действиях, позволяют модели сформировать базовое понимание мира, его визуальных особенностей и закономерностей. Использование этих данных в сочетании с более ограниченным объемом размеченных данных, описывающих конкретные действия и их результаты, значительно повышает эффективность обучения и позволяет создавать более надежные и адаптивные системы, способные успешно функционировать в сложных реальных условиях.
В робототехнике, получение большого количества размеченных данных для обучения зачастую является сложной и дорогостоящей задачей. Предложенная структура данных, основанная на принципах пирамиды, позволяет эффективно обучать роботов даже при ограниченном объеме размеченных примеров. Используя иерархический подход к обработке информации, система способна извлекать полезные знания из неразмеченных данных, дополняя и усиливая обучение на основе размеченных примеров. Такой подход значительно снижает зависимость от дорогостоящей ручной разметки данных, открывая возможности для обучения роботов в условиях ограниченных ресурсов и расширяя сферу их применения в реальном мире.
Обучение на обширном датасете TASTE-Rob позволило продемонстрировать перспективность переноса приобретенных навыков в реальные условия. Этот набор данных, включающий разнообразные сценарии взаимодействия робота с объектами, стал основой для создания модели, способной адаптироваться к новым, ранее не встречавшимся ситуациям. Эксперименты показали, что робот, обученный на TASTE-Rob, успешно выполняет задачи в условиях, отличающихся от тех, в которых проходило обучение, что подтверждает эффективность предложенного подхода к обобщению знаний. Такой перенос навыков имеет решающее значение для широкого внедрения робототехники в повседневную жизнь, позволяя создавать более гибкие и автономные системы, способные функционировать в непредсказуемой среде.
Базовая модель, лежащая в основе системы, выходит за рамки простого распознавания и реагирования, благодаря интеграции с так называемой “мировой моделью”. Эта модель позволяет системе предсказывать последствия собственных действий и внешних событий, фактически обеспечивая своего рода “прогнозирование будущего”. Благодаря этому, робот способен не просто выполнять команды, но и планировать последовательность действий для достижения цели, учитывая потенциальные препятствия и изменяющиеся условия. Использование мировой модели дает возможность переходить от реактивного поведения к проактивному планированию, что критически важно для работы в сложных и динамичных средах, требующих адаптации и предвидения.
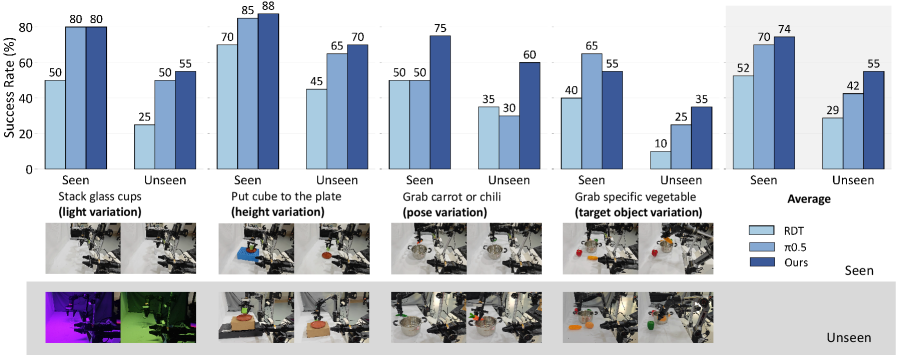
В сложных и требовательных условиях эксплуатации, разработанная модель демонстрирует значительное превосходство над существующими передовыми решениями (State-of-the-Art, SOTA). Это превосходство подтверждается стабильными результатами в задачах, характеризующихся высокой степенью неопределенности и необходимостью адаптации к меняющимся условиям. Полученные данные указывают на повышенную устойчивость модели к шумам, помехам и неполноте информации, что позволяет ей эффективно функционировать даже в тех ситуациях, где другие системы терпят неудачу. Такая повышенная надежность делает данную модель особенно привлекательной для применения в критически важных областях, где требуется безотказная работа и предсказуемое поведение.
Представленная работа демонстрирует стремление к упрощению сложных систем, что находит отклик в философии Дональда Дэвиса. Он говорил: «Простота — это высшая степень изысканности». FRAPPE, предлагая метод выравнивания множественных представлений будущего, стремится к созданию более понятных и эффективных моделей для робототехники. Подход, ориентированный на визуальное и языковое выравнивание, позволяет сократить избыточность и повысить плотность смысла в обучении моделей, что соответствует принципу «ненужное — это насилие над вниманием». Особое внимание к использованию эгоцентричных данных усиливает эту тенденцию, фокусируясь на наиболее релевантной информации для обучения робота.
Что дальше?
Представленная работа, сосредоточившись на выстраивании согласованности между различными представлениями будущего, не решает, а лишь обнажает фундаментальную сложность моделирования мира. Улучшение визуально-языкового соответствия, безусловно, полезно, но оно напоминает полировку фасада здания, основа которого все еще требует тщательного изучения. Истинный прогресс потребует не просто более эффективных диффузионных моделей, а принципиально нового взгляда на природу представления знаний и их воплощения в действии.
Особый интерес вызывает использование эгоцентричных данных. Однако, остается неясным, как преодолеть присущую им субъективность и предвзятость, не создавая при этом моделей, отражающих лишь ограниченный набор перспектив. Проблема масштабируемости, хоть и смягчена параллельным обучением, все еще требует более элегантных решений. Недостаточно просто увеличить вычислительные ресурсы; необходимо найти способы более компактного и эффективного кодирования информации.
В конечном итоге, ценность FRAPPE заключается не в достигнутых результатах, а в четко обозначенных вопросах. Поиск совершенства — это процесс постоянного удаления лишнего, а не добавления нового. Истинное будущее робототехники и искусственного интеллекта заключается не в создании все более сложных систем, а в поиске простоты и ясности в принципах, лежащих в их основе.
Оригинал статьи: https://arxiv.org/pdf/2602.17259.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Неупорядоченные системы с неэрмитовыми эффектами
- Безопасность генерации изображений: новый вектор управления
- Искусственный интеллект на страже кода: новая оценка качества
2026-02-20 15:15