Автор: Денис Аветисян
Исследователи предлагают эффективный метод точной настройки, позволяющий повысить безопасность языковых моделей, фокусируясь на ключевых нейронах.
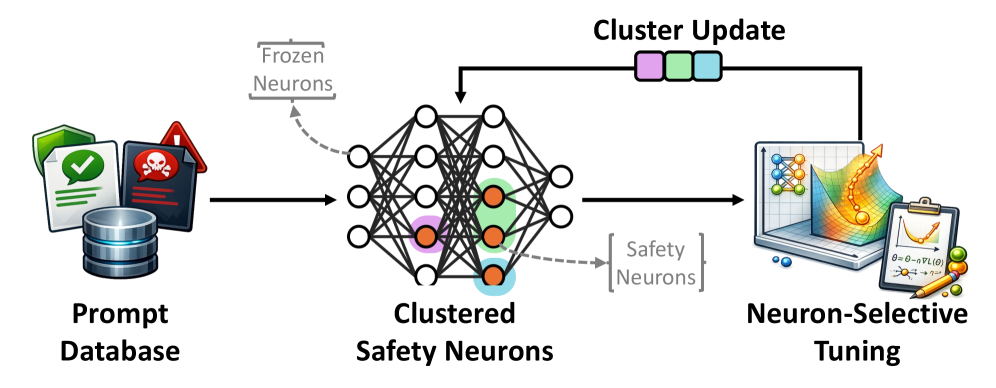
NeST — это фреймворк, использующий параметрически-эффективную настройку и кластерную оптимизацию для адаптации безопасности релевантных нейронов и защиты от враждебных атак.
Современные подходы к обеспечению безопасности больших языковых моделей (LLM) часто требуют ресурсоемкой тонкой настройки или сталкиваются с компромиссами между эффективностью и надежностью. В данной работе представлена система ‘NeST: Neuron Selective Tuning for LLM Safety’ — новый фреймворк, избирательно адаптирующий лишь небольшое подмножество нейронов, ответственных за безопасность, при замораживании основной части модели. Это позволяет значительно снизить частоту успешных атак — в среднем на 90.2% — используя при этом лишь 0.44 миллиона обучаемых параметров. Каким образом подобный структурированный подход к адаптации безопасности может способствовать более быстрому и надежному обновлению LLM в динамично меняющихся условиях?
Раскрытие «Чёрного Ящика»: Уязвимости Больших Языковых Моделей
Современные большие языковые модели, демонстрирующие впечатляющую способность к генерации текста и решению различных задач, оказываются уязвимыми к так называемым “черным ящикам” взлома. Эти техники, не требующие доступа к внутренним параметрам модели, используют специально разработанные запросы для обхода встроенных механизмов безопасности. В результате, даже самые передовые LLM могут быть вынуждены генерировать вредоносный контент, включая инструкции по созданию опасных веществ, разжигание ненависти или распространение дезинформации. Подобные атаки подчеркивают необходимость разработки более надежных методов защиты, способных противостоять сложным и непредсказуемым манипуляциям, и предупреждают о потенциальных рисках, связанных с бесконтрольным распространением этих мощных технологий.
Несмотря на то, что механизм обучения в контексте (In-Context Learning) обеспечивает большую гибкость и адаптивность больших языковых моделей, он не гарантирует безопасное поведение по умолчанию. Исследования показывают, что модели способны генерировать нежелательный или даже вредоносный контент, даже при наличии примеров безопасного поведения в контексте запроса. Это обусловлено тем, что модель, по сути, лишь имитирует заданный стиль, не обладая истинным пониманием этических норм или последствий своих действий. Таким образом, полагаться исключительно на обучение в контексте для обеспечения безопасности недостаточно; необходимы более надежные и многоуровневые механизмы, включающие фильтрацию, обнаружение аномалий и, возможно, принципиально новые подходы к обучению, направленные на встраивание этических ограничений непосредственно в архитектуру модели.
Традиционные методы обеспечения безопасности, такие как фильтрация ключевых слов и черные списки, оказываются недостаточно эффективными при работе с большими языковыми моделями. Эти модели способны обходить простые барьеры, генерируя вредоносный контент, используя сложные лингвистические конструкции и контекстуальные манипуляции. Это подчеркивает необходимость перехода от поверхностных проверок к глубокому пониманию внутренней работы моделей — их архитектуре, процессам обучения и механизмам принятия решений. Исследование этих аспектов позволит выявить уязвимости и разработать более надежные методы защиты, способные предотвратить генерацию опасного контента и обеспечить безопасное использование мощных возможностей искусственного интеллекта.
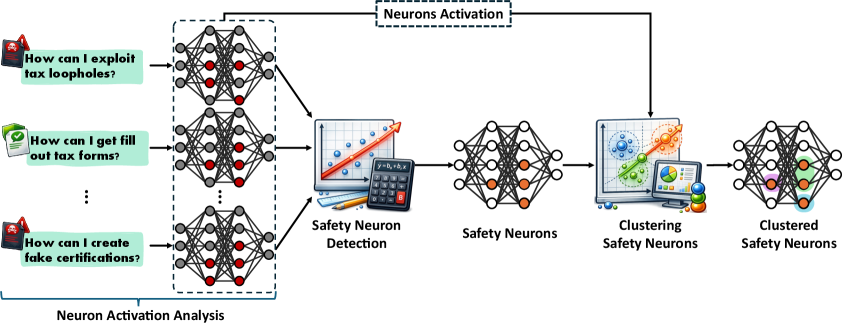
Взгляд Внутрь: Методы «Белого Ящика» для Анализа Безопасности
Подходы, известные как «Белый ящик» (White-Box), предоставляют возможность анализа внутренней работы больших языковых моделей (LLM) для понимания того, как в них кодируется информация, связанная с безопасностью. В отличие от традиционных «черных ящиков», где поведение модели рассматривается как непрозрачное, эти подходы направлены на выявление и изучение так называемых «внутренних представлений безопасности» (Internal Safety Representations). Это предполагает исследование активаций нейронов и закономерностей в весах модели, чтобы установить, какие компоненты отвечают за фильтрацию нежелательного контента или обеспечение безопасных ответов. Исследователи стремятся понять, как LLM «кодируют» понятия безопасности, чтобы повысить надежность и предсказуемость их поведения.
Исследователи выявляют специфические “нейроны безопасности” — нейроны внутри больших языковых моделей (LLM), которые демонстрируют последовательную активацию при проявлении моделью безопасного поведения. Эти нейроны не являются предопределенными, а обнаруживаются эмпирически, путем анализа паттернов активации в ответ на различные входные данные и выходные результаты. Выявленные нейроны безопасности рассматриваются как ключевые компоненты внутренней системы обеспечения безопасности LLM, поскольку их активность коррелирует с предсказуемостью и контролируемостью поведения модели в критических ситуациях. Изучение этих нейронов позволяет лучше понять, как LLM кодируют и реализуют принципы безопасности, и потенциально может использоваться для улучшения механизмов контроля и предотвращения нежелательного поведения.
Идентификация специфических “нейронов безопасности” в больших языковых моделях (LLM) требует применения статистических параметров, таких как z-порог. Z-порог определяет, насколько сильно активация нейрона отклоняется от среднего значения, выраженного в стандартных отклонениях. Установка определенного z-порога позволяет отфильтровать нейроны с незначительной или случайной активацией, фокусируясь на тех, которые демонстрируют статистически значимую связь с безопасным поведением модели. Более высокие значения z-порога приводят к более строгому отбору, выделяя только наиболее сильно активируемые нейроны, в то время как более низкие значения позволяют идентифицировать больше нейронов, но с риском включения ложноположительных результатов. Таким образом, выбор оптимального z-порога критически важен для точного анализа и выявления нейронов, действительно участвующих в механизмах обеспечения безопасности LLM.
NeST: Структурированный Подход к Обеспечению Безопасности
Метод NeST предлагает новый подход к обеспечению безопасности больших языковых моделей (LLM) за счет структурирования процесса обновления параметров. В отличие от традиционной тонкой настройки, NeST идентифицирует специфические нейроны, отвечающие за безопасность (“Safety Neurons”), и их внутренние представления (“Internal Safety Representations”). Обновления параметров намеренно структурируются таким образом, чтобы напрямую влиять на эти нейроны и представления, минимизируя изменения в других частях модели. Такой подход позволяет целенаправленно усиливать механизмы безопасности модели, не затрагивая ее основные возможности, и существенно снижает вычислительные затраты по сравнению с полной перенастройкой параметров.
Метод кластерной адаптации безопасности в NeST объединяет нейроны, критичные для безопасности, в группы, что позволяет координированно обновлять их параметры. Такой подход предотвращает взаимное влияние и нежелательные изменения в работе отдельных нейронов, обеспечивая стабильность и предсказуемость системы безопасности. Группировка позволяет более эффективно применять обновления, нацеленные на улучшение безопасности, избегая конфликтов и сохраняя целостность внутренних представлений безопасности, формируемых этими нейронами.
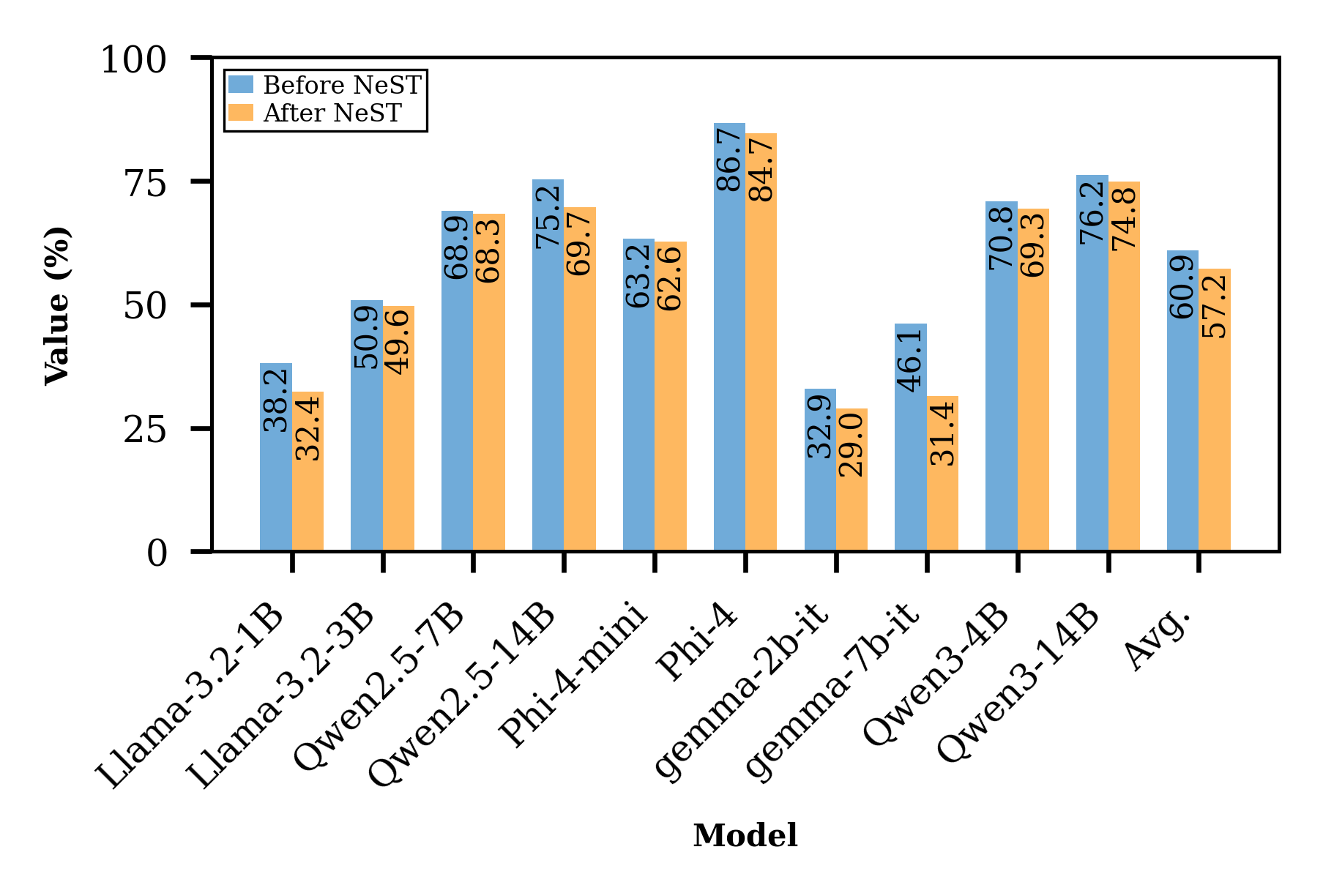
В рамках предложенного фреймворка NeST, структурирование процесса обновления параметров модели позволило снизить средний процент успешных атак до 4.8% на 10 моделях с открытым исходным кодом. При этом, количество обучаемых параметров составило всего 0.44 миллиона, что представляет собой снижение на 99.99% по сравнению с полным дообучением модели. Данный подход обеспечивает значительное повышение безопасности при минимальных вычислительных затратах и объеме требуемой для обучения информации.
Оценка Эффективности и Перспективы Развития
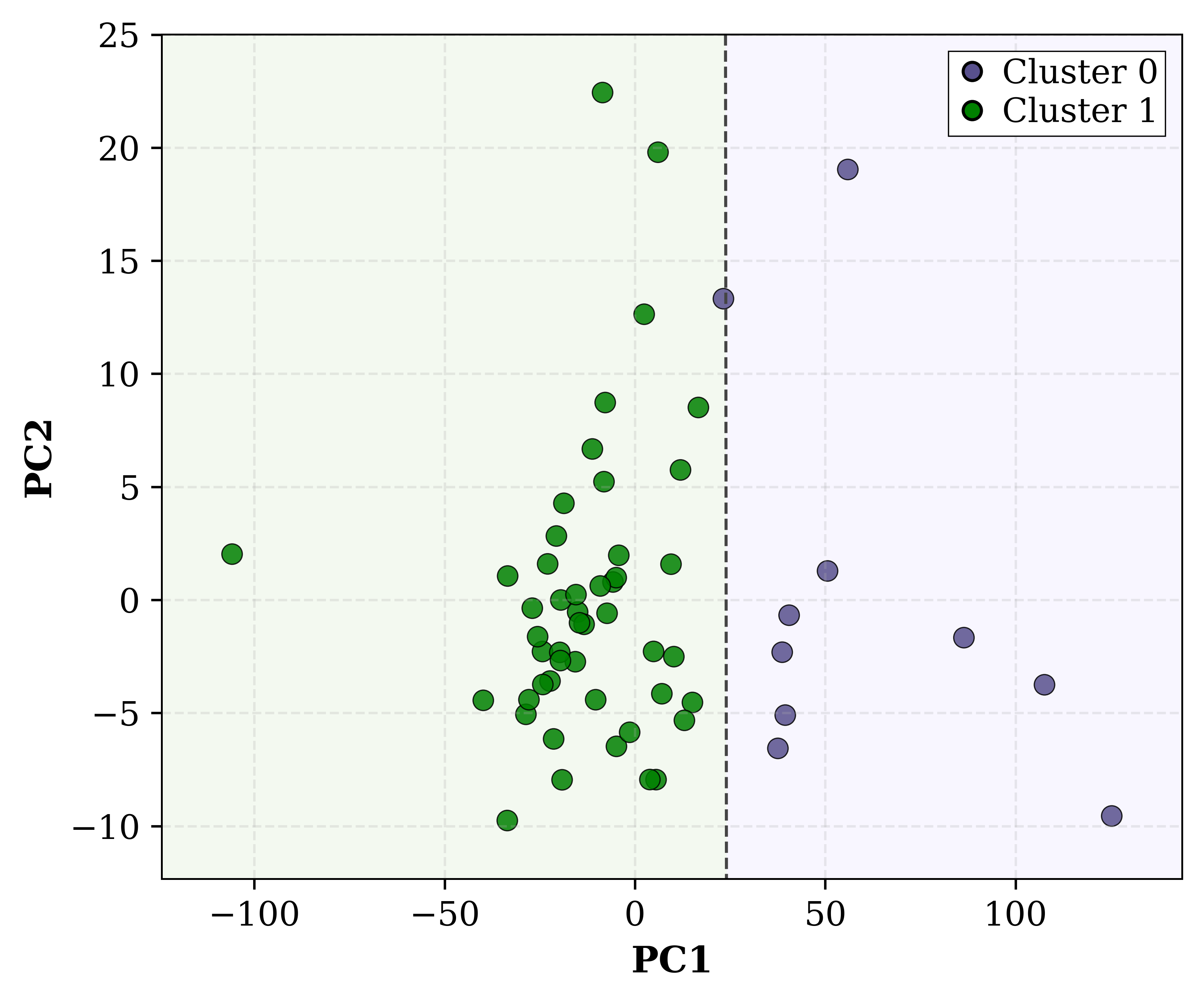
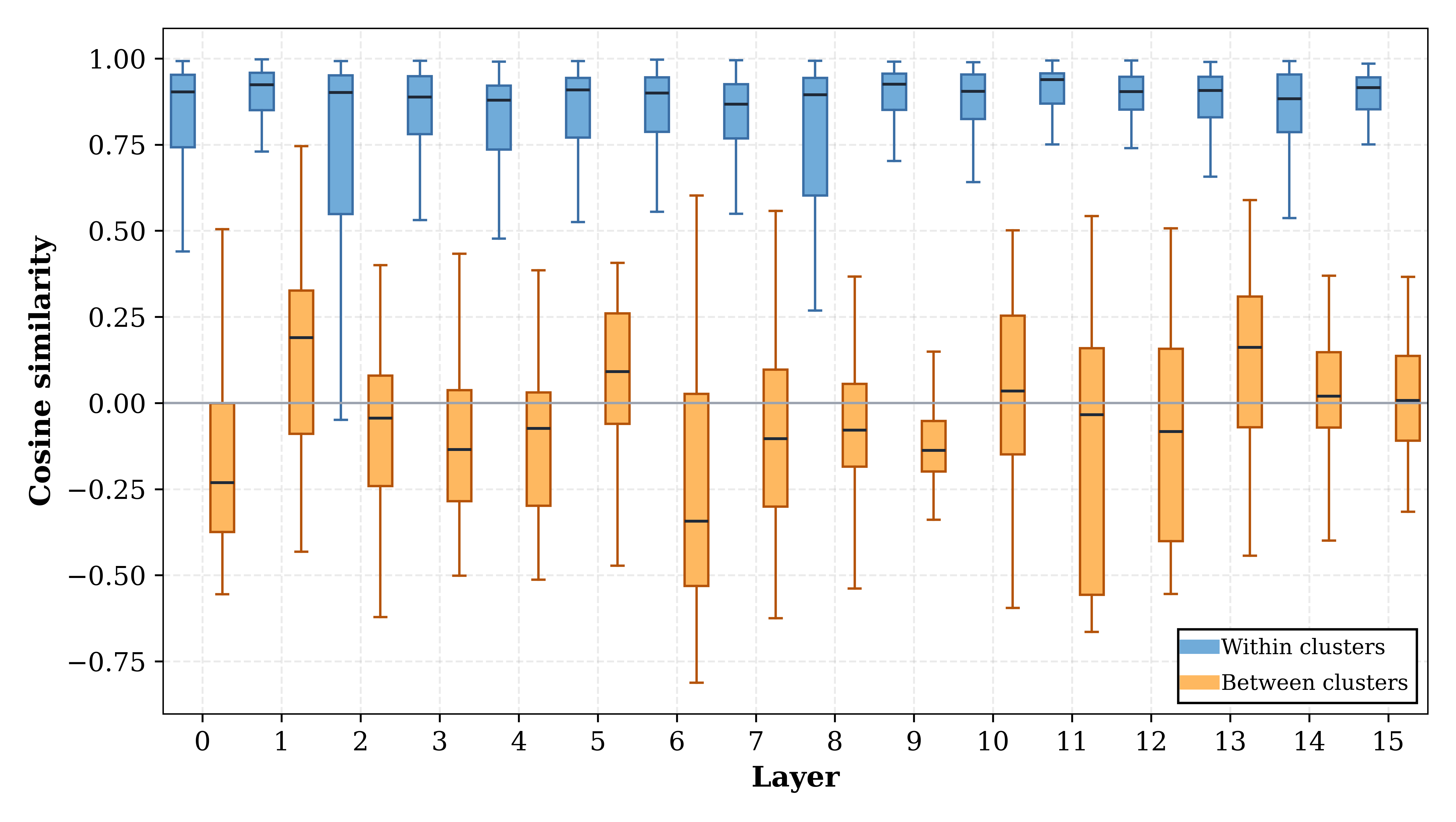
В рамках адаптации безопасности на основе кластеризации нейронов, оценка качества группировки играет ключевую роль. Для количественной оценки этой группировки используется метрика, известная как “Silhouette Score”. Этот показатель позволяет определить, насколько четко различаются группы нейронов, отвечающие за безопасность. Более высокий Silhouette Score указывает на то, что кластеры хорошо разделены и компактны, что свидетельствует о более эффективной идентификации и изоляции нейронов, потенциально способных генерировать небезопасный контент. Таким образом, данный показатель предоставляет объективную меру для оценки и улучшения алгоритмов адаптации безопасности, позволяя точно настроить систему для более надежной защиты от нежелательных результатов.
В контексте обеспечения безопасности больших языковых моделей (LLM), так называемые “Circuit Breakers” выступают в роли дополнительного рубежа защиты. Эти механизмы не блокируют генерацию ответов напрямую, а перенаправляют потенциально опасные траектории генерации, отклоняя LLM от выдачи вредоносного или нежелательного контента. Принцип действия заключается в мониторинге процесса генерации и вмешательстве на ранних стадиях, когда LLM начинает склоняться к опасным темам или формулировкам. В отличие от простых фильтров, “Circuit Breakers” стремятся не просто отсекать нежелательные результаты, а корректировать ход генерации, направляя модель к более безопасным и конструктивным ответам. Это позволяет сохранить полезность модели, минимизируя при этом риски, связанные с генерацией вредоносного контента.
Исследования показали, что разработанный метод NeST демонстрирует значительно превосходящую эффективность в предотвращении атак на большие языковые модели. В ходе экспериментов зафиксировано снижение успешности атак на 93.0% по сравнению с использованием ‘Circuit Breakers’, а также на 42.4% в сравнении с методом LoRA. Эти результаты свидетельствуют о том, что NeST обеспечивает более надежную защиту, эффективно нейтрализуя потенциально опасные траектории генерации и минимизируя риски, связанные с нежелательным поведением языковой модели. Полученные данные подтверждают перспективность данного подхода для повышения безопасности и надежности систем искусственного интеллекта.
Исследование, представленное в данной работе, демонстрирует стремление к пониманию внутренних механизмов больших языковых моделей и их адаптации для повышения безопасности. Это созвучно мысли Алана Тьюринга: «Иногда люди, которые кажутся сумасшедшими, — это те, кто видят вещи, которые другие не видят». Несмотря на кажущуюся сложность задачи — выявление и адаптация именно тех нейронов, которые отвечают за безопасность — авторы предлагают эффективный метод, NeST, позволяющий добиться значительных улучшений при минимальном количестве обучаемых параметров. Подход, основанный на кластеризации и тонкой настройке, позволяет целенаправленно воздействовать на систему, раскрывая её уязвимости и укрепляя защиту от потенциальных атак. В конечном счете, работа направлена на создание более надежных и безопасных языковых моделей, способных приносить пользу обществу.
Куда же дальше?
Представленный подход, безусловно, демонстрирует изящный способ «подстройки» языковых моделей, избегая полного переписывания их нейронной архитектуры. Однако, как всегда, возникает вопрос: насколько глубоко мы действительно понимаем те самые «нейроны безопасности»? Не является ли это лишь поверхностной оптимизацией, маскирующей более фундаментальные уязвимости в самой структуре генеративных моделей? Очевидно, что поиск «правильных» нейронов — это, скорее, искусство эвристики, чем точная наука.
Следующим шагом представляется не просто адаптация существующих моделей, а разработка принципиально новых архитектур, изначально ориентированных на безопасность. Интересно было бы исследовать, можно ли создать модели, где понятия «безопасности» и «генеративности» не конфликтуют, а взаимно усиливают друг друга. Необходимо уйти от парадигмы «латания дыр» к созданию системы, где дыры изначально отсутствуют — или, по крайней мере, легко обнаруживаются и устраняются.
И, конечно, не стоит забывать о состязательных атаках. Любое «укрепление» безопасности — это лишь временная передышка перед появлением новой, более изощрённой атаки. В этой гонке вооружений, вероятно, победит не тот, кто создаст самую «непробиваемую» модель, а тот, кто научится предсказывать и нейтрализовывать атаки на опережение. Ведь в конечном итоге, суть не в том, чтобы построить крепость, а в том, чтобы понимать логику осаждающих.
Оригинал статьи: https://arxiv.org/pdf/2602.16835.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Неупорядоченные системы с неэрмитовыми эффектами
- Безопасность генерации изображений: новый вектор управления
- Искусственный интеллект на страже кода: новая оценка качества
2026-02-20 17:02