Автор: Денис Аветисян
Новый подход позволяет агентам создавать интерпретируемые представления об окружающей среде, непрерывно адаптируясь и повышая эффективность обучения.
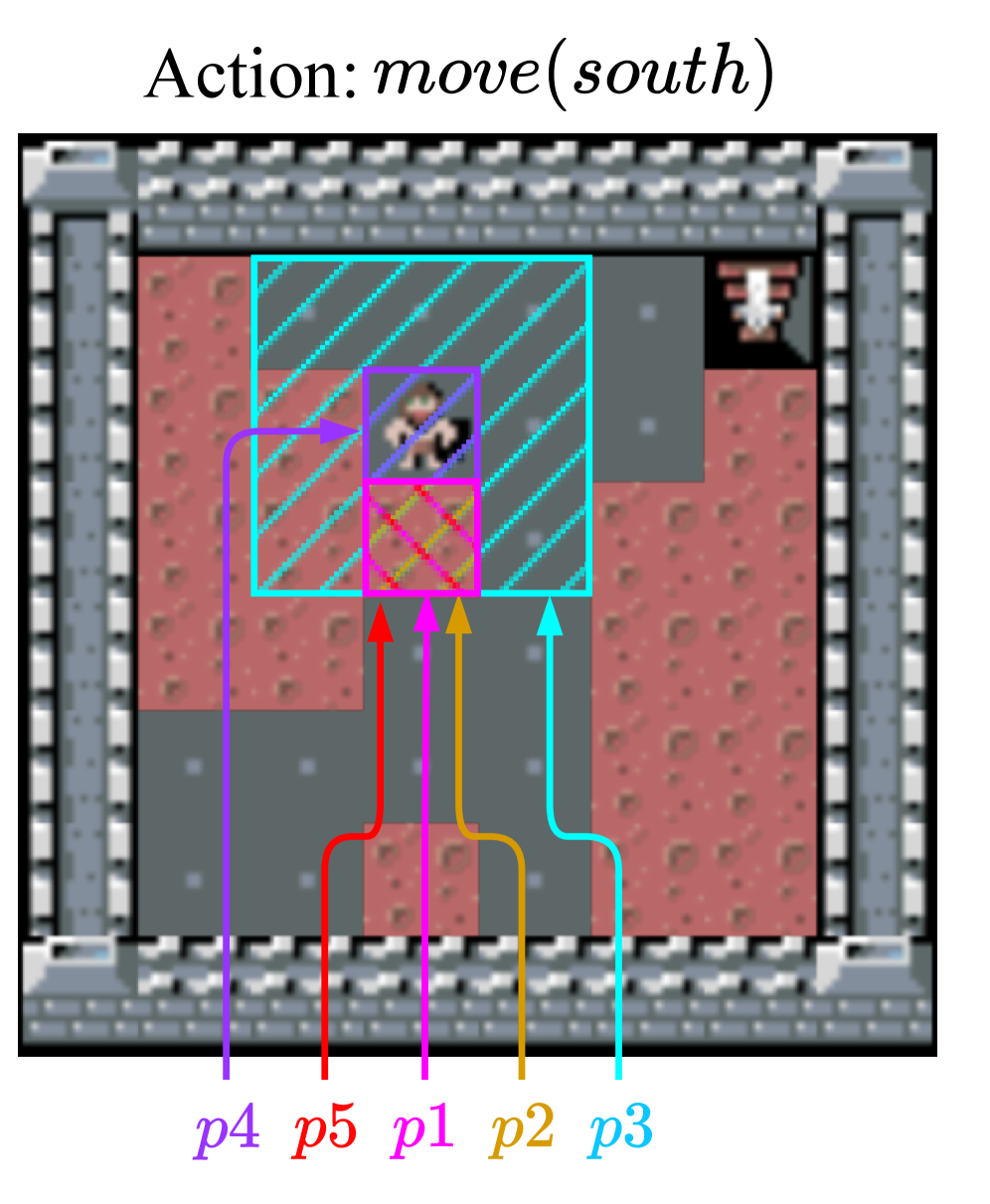
Представлена самообучающаяся система для построения символических моделей мира, использующая логическое программирование и динамическое изобретение предикатов для постоянного улучшения и исправления моделей.
Эффективное обучение агентов сложным средам требует не только усвоения логики окружающего мира, но и способности адаптироваться к новым ситуациям. В данной работе, посвященной ‘Continual learning and refinement of causal models through dynamic predicate invention’, предложен фреймворк для построения символических причинно-следственных моделей, способный к непрерывному обучению и самосовершенствованию за счет динамического изобретения предикатов. Предложенный подход объединяет логическое программирование с непрерывным восстановлением модели, позволяя агенту создавать иерархию понятных и переиспользуемых абстракций. Сможет ли подобный метод преодолеть ограничения существующих подходов и обеспечить более эффективное и прозрачное обучение в сложных, динамичных средах?
За пределами масштабирования: Ограничения традиционного обучения с подкреплением
Традиционные алгоритмы обучения с подкреплением, такие как PPO, часто демонстрируют ограниченную эффективность при решении сложных задач, требующих планирования на длительном горизонте. Это связано с тем, что для достижения удовлетворительных результатов им требуется колоссальное количество данных для обучения — порядок величины может исчисляться миллионами или даже миллиардами взаимодействий со средой. Такая зависимость от больших объемов данных не только замедляет процесс обучения, но и делает применение этих алгоритмов затруднительным в реальных сценариях, где сбор данных может быть дорогостоящим, трудоемким или даже невозможным. В частности, PPO, как и другие алгоритмы, основанные на оценке функции ценности, сталкивается с проблемой экспоненциального роста неопределенности при увеличении длительности эпизода, что требует еще больше данных для поддержания стабильности и точности обучения. Поэтому, преодоление этой зависимости от больших данных является ключевой задачей для развития обучения с подкреплением и расширения его применимости к более сложным и реалистичным задачам.
Обобщающая способность традиционных алгоритмов обучения с подкреплением часто ограничена конкретной средой, в которой они были обучены, что существенно снижает их применимость в реальном мире. Проблема заключается в том, что агенты, оптимизированные для выполнения задач в узко определенных условиях, испытывают трудности при адаптации к незначительным изменениям в окружающей среде или при переносе знаний на новые, но схожие задачи. Например, робот, обученный собирать объекты в контролируемой лаборатории, может оказаться неспособным функционировать эффективно в динамичной и непредсказуемой обстановке реального производства. Эта неспособность к обобщению требует значительных усилий по переобучению или тонкой настройке агента для каждой новой ситуации, что делает развертывание таких систем дорогостоящим и трудоемким.
Существенная проблема в обучении с подкреплением заключается в сложности формирования устойчивого и понятного представления о динамике окружающей среды. Алгоритмы часто сталкиваются с трудностями при моделировании сложных взаимосвязей между действиями и их последствиями, особенно в долгосрочной перспективе. Неспособность точно предсказать, как состояние среды изменится в результате определенного действия, приводит к неэффективным стратегиям и замедляет процесс обучения. Более того, такое представление должно быть не только точным, но и интерпретируемым, чтобы можно было понять, почему алгоритм принимает те или иные решения, что критически важно для отладки, улучшения и обеспечения безопасности системы. Разработка методов, позволяющих алгоритмам эффективно извлекать и использовать информацию о динамике среды, является ключевым направлением исследований, способным значительно расширить возможности обучения с подкреплением в реальных условиях.
Символьная динамика: Фреймворк для обучения мировым моделям
Представляется агент Online MIL — самообучающийся фреймворк, предназначенный для построения символической модели окружающей среды. В его основе лежит принцип обучения без учителя, что позволяет агенту самостоятельно извлекать закономерности и взаимосвязи из поступающих данных. Этот подход позволяет агенту формировать внутреннее представление об окружении в виде набора символов и правил, определяющих его состояние и динамику. Ключевой особенностью является способность агента к адаптации и обучению в реальном времени, без необходимости предварительной разметки данных или явного программирования правил.
Агент использует логику первого порядка (First-Order Logic) для представления состояния окружающей среды и последствий действий. Это позволяет моделировать сложные взаимосвязи и зависимости между объектами и событиями. В частности, объекты описываются предикатами, а действия — как правила, изменяющие эти предикаты. Такое представление обеспечивает возможность композиционного рассуждения, то есть вывода новых знаний из существующих фактов и правил, что необходимо для эффективного планирования и решения задач в динамичной среде. Использование логики первого порядка позволяет представлять универсальные утверждения о свойствах объектов и отношениях между ними, что расширяет возможности обобщения и переноса знаний на новые ситуации.
Построение наиболее общей логической программы (most general logic program) обеспечивает эффективное определение пространства поиска для обучения динамике окружающей среды. Этот подход позволяет представить все возможные логические следствия, исходя из наблюдаемых данных, и, таким образом, значительно сократить объем пространства состояний, подлежащего исследованию. Вместо перебора всех возможных правил и фактов, алгоритм фокусируется на наиболее общих, что позволяет быстро идентифицировать релевантные закономерности и строить компактную модель динамики. Эффективность достигается за счет использования логического программирования, которое позволяет представлять знания в декларативном виде и автоматически выводить новые факты на основе заданных правил и наблюдений. Такой подход особенно важен в сложных средах, где количество возможных состояний и действий велико, поскольку позволяет значительно снизить вычислительные затраты на обучение.
Цикл «Предсказание-Проверка-Уточнение»: Итеративное уточнение модели
В основе данной архитектуры лежит итеративный цикл «Предсказание-Проверка-Уточнение», в рамках которого агент формирует прогноз следующего состояния системы, сопоставляет его с фактическим состоянием для выявления расхождений, и на основе этих расхождений корректирует свою модель. Процесс начинается с генерации предсказания, которое затем сравнивается с наблюдаемой реальностью. Разница между предсказанным и фактическим состояниями служит сигналом для обновления внутренней модели агента, что позволяет повысить точность последующих предсказаний и улучшить общую производительность системы. Данный цикл повторяется непрерывно, обеспечивая адаптацию модели к изменяющимся условиям и повышая ее надежность.
Цикл «Предсказание-Проверка-Уточнение» использует принцип инерции для упрощения процесса верификации. Вместо полной проверки текущего состояния системы, фокус смещается на анализ изменений состояния. Это позволяет агенту идентифицировать только те аспекты, которые претерпели изменения, значительно снижая вычислительную сложность и ускоряя процесс проверки предсказаний. Такой подход предполагает, что большинство аспектов состояния остаются неизменными между последовательными шагами, что позволяет эффективно отслеживать только отклонения от ожидаемых значений.
Уточнение гипотез в процессе обучения модели осуществляется путем анализа как ложноположительных, так и ложноотрицательных результатов. Ложноположительные результаты — это случаи, когда модель предсказывает событие, которого на самом деле не произошло, что требует пересмотра критериев принятия решений. Ложноотрицательные результаты — это случаи, когда модель не обнаруживает произошедшее событие, что указывает на необходимость расширения охвата модели и повышения ее чувствительности. Идентификация и корректировка обоих типов ошибок критически важны для обеспечения как точности, так и полноты модели, что позволяет ей адекватно отражать реальность и избегать систематических искажений.
Масштабируемое абстрагирование: Обучение за пределами идентичности объектов
Агент способен к изобретению предикатов — новых способов описания окружающего мира, что позволяет ему строить иерархические абстракции и представлять сложные взаимосвязи. Вместо того, чтобы просто запоминать конкретные объекты, система формирует общие понятия, определяющие их свойства и отношения. Например, вместо запоминания каждого отдельного «красного кубика», агент изобретает предикат «быть красным», который может быть применен к любому объекту. Этот процесс позволяет ему обобщать информацию и эффективно оперировать с большим объемом данных, поскольку сложные сцены разбиваются на более простые, абстрактные элементы, что значительно упрощает процесс планирования и принятия решений.
Агент, использующий динамику «поднятого» уровня, способен рассуждать об отношениях между объектами, а не об их индивидуальных идентификаторах. Это позволяет значительно повысить масштабируемость системы, поскольку вместо запоминания и обработки информации о каждом конкретном объекте, агент оперирует общими закономерностями и связями. Например, вместо того, чтобы узнавать каждый отдельный кубик, система может понимать концепцию «куча кубиков» и оперировать ею как единым целым. Такой подход особенно важен при решении сложных задач, требующих долгосрочного планирования и рассуждений об абстрактных понятиях, поскольку он снижает вычислительную сложность и позволяет агенту эффективно обобщать полученный опыт на новые, ранее не встречавшиеся ситуации.
Способность к обобщению, выходящему за рамки конкретных экземпляров, является ключевым фактором при решении сложных задач с горизонтом планирования, требующих понимания абстрактных концепций. Вместо запоминания отдельных объектов и их свойств, система способна выявлять общие закономерности и отношения между ними, что позволяет эффективно оперировать с принципиально новыми ситуациями. Такой подход значительно расширяет возможности агента в динамичной среде, где предсказать все возможные сценарии невозможно. По сути, речь идет о переходе от реакций на конкретные стимулы к формированию внутренней модели мира, основанной на абстрактных представлениях, что открывает путь к более гибкому и адаптивному поведению, особенно в задачах, требующих долгосрочного планирования и принятия решений.
Оценка и будущие направления: К обобщенному интеллекту
Исследования в среде MiniHack продемонстрировали, что разработанная система значительно превосходит традиционные алгоритмы обучения с подкреплением по эффективности использования данных. В частности, система требует существенно меньше взаимодействий со средой для достижения заданного уровня производительности, что особенно важно в сложных и динамичных условиях. Это улучшение связано с использованием символьного представления, позволяющего агенту обобщать полученные знания и быстрее адаптироваться к новым ситуациям, минимизируя потребность в длительном и дорогостоящем процессе обучения на большом количестве примеров. Подобная эффективность открывает перспективы для создания интеллектуальных агентов, способных к быстрому освоению новых задач и адаптации к изменяющимся условиям окружающей среды.
Агент, использующий символьное представление, демонстрирует не только повышенную эффективность обучения, но и значительное преимущество в плане интерпретируемости и способности к переносу знаний. В отличие от традиционных подходов, где стратегии обучения часто остаются «черным ящиком», символьное представление позволяет понять логику действий агента, поскольку оно оперирует с абстрактными понятиями и взаимосвязями. Это, в свою очередь, существенно упрощает адаптацию к новым задачам и средам, поскольку агент способен использовать уже усвоенные знания, перенося их на незнакомые ситуации. Например, понимание концепции «предмет» или «действие» позволяет агенту быстрее осваивать новые игровые сценарии, не требуя повторного обучения с нуля. Такой подход открывает перспективы создания более гибких и универсальных интеллектуальных систем, способных к обобщению опыта и эффективному решению широкого круга задач.
В ходе экспериментов в виртуальной среде MiniHack, разработанный символический агент продемонстрировал впечатляющую способность к обучению за один эпизод в сложной лавовой локации. В отличие от алгоритма PPO, которому для успешного прохождения потребовалось около 128 попыток, предложенный агент решил задачу с первого раза. Это свидетельствует о значительном повышении эффективности обучения и способности к быстрой адаптации к новым, незнакомым ситуациям, что является важным шагом на пути к созданию действительно обобщенного искусственного интеллекта, способного решать задачи без обширного обучения.
Исследование, представленное в статье, неизбежно сталкивается с прагматичной реальностью: даже самые элегантные модели мира, построенные на основе логического программирования и непрерывного исправления, рано или поздно потребуют упрощения. Стремление к интерпретируемости, хоть и благородно, часто упирается в необходимость компромиссов ради практической реализации. Как метко заметил Г.Х. Харди: «Математика — это наука о том, что невозможно». В данном случае, создание полностью самообучающейся и самовосстанавливающейся модели мира, способной к динамическому изобретению предикатов, — задача, близкая к этой невозможности. Неизбежно, в процессе эксплуатации, даже самая изящная теоретическая конструкция будет подвергаться «техническому долгу», требующему постоянных доработок и упрощений для обеспечения стабильной работы.
Куда же всё это ведёт?
Представленный подход, безусловно, элегантен. Построение символических моделей мира, способных к самообучению и коррекции, — это шаг в правильном направлении. Однако, если внимательно присмотреться, становится ясно: каждая новая возможность самообучения порождает новые, ещё более изощрённые способы поломки. В конце концов, даже самая изящная логика рухнет под напором реальности, где данные всегда шумные, неполные и противоречивые. Мы не создаём интеллект — мы просто оставляем комментарии для будущих археологов, пытающихся понять, почему система стабильно падает.
Очевидным направлением для дальнейших исследований является масштабируемость. Текущие методы, вероятно, столкнутся с проблемами при работе с действительно сложными, многомерными пространствами состояний. “Cloud-native” решения, конечно, помогут развернуть всё это на большем количестве серверов, но, как известно, это всего лишь тот же самый подход, только дороже. Истинным вызовом остаётся создание систем, способных к эффективному обобщению и переносу знаний — то есть, к обучению не только конкретным фактам, но и принципам.
В конечном итоге, вся эта работа — ещё один шаг к созданию систем, которые будут казаться умными. Но не стоит забывать: каждая «революционная» технология завтра станет техдолгом. И если система стабильно падает, значит, она хотя бы последовательна. Поэтому, прежде чем строить воздушные замки, стоит убедиться, что фундамент достаточно прочен.
Оригинал статьи: https://arxiv.org/pdf/2602.17217.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Неупорядоченные системы с неэрмитовыми эффектами
- Глубокое обучение: Математический фундамент
- Иллюзии понимания: Как правильно оценивать объяснимые модели
2026-02-20 23:49