Автор: Денис Аветисян
Новое исследование рассматривает, как проектировать системы отслеживания действий, чтобы пользователи могли эффективно проверять результаты работы интеллектуальных агентов, не тратя время на микроменеджмент.
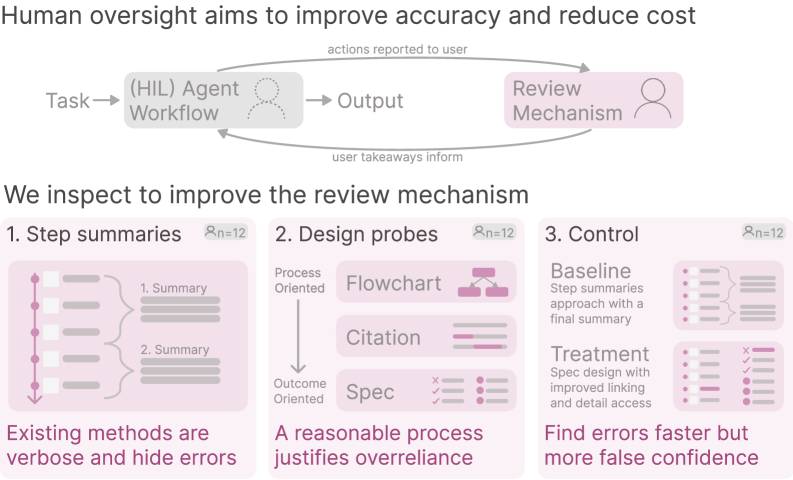
Исследование фокусируется на балансе между детализацией и абстракцией в системах трассировки для повышения точности и уверенности пользователей в работе человеко-машинных систем.
Постоянный контроль за сложными агентами искусственного интеллекта практически невозможен, но и полное отсутствие надзора чревато ошибками. В рамках исследования ‘Overseeing Agents Without Constant Oversight: Challenges and Opportunities’ были изучены способы повышения эффективности верификации действий агентов посредством оптимизации отображаемых «следов» их работы. Полученные результаты показывают, что баланс между детализацией и абстракцией в этих «следах» критически важен для повышения скорости обнаружения ошибок, хотя и не всегда гарантирует повышение общей точности верификации. Какие когнитивные и интерфейсные решения позволят в будущем обеспечить надежный и эффективный контроль над все более автономными системами искусственного интеллекта?
Постановка Проблемы: Недоверие к Автономным Агентам
Всё чаще автономные агенты внедряются в сложные сферы деятельности, требуя тесного взаимодействия с человеком. От автоматизированных систем поддержки принятия решений в медицине до роботизированных помощников в промышленности и транспорта, эти агенты призваны расширять возможности человека и повышать эффективность работы. Однако, для успешной реализации этого потенциала необходимо не просто наличие интеллектуальной системы, но и налаженное сотрудничество между человеком и машиной. Это взаимодействие предполагает не только передачу задач агенту, но и возможность эффективного обмена информацией, взаимного контроля и совместного решения проблем, что делает вопрос о надежном и продуктивном человеко-машинном взаимодействии ключевым для развития данной области.
В современных системах искусственного интеллекта, где агенты все чаще привлекаются к решению сложных задач, недостаточная прозрачность их внутренних процессов представляет серьезную проблему. Пользователи, не имея возможности понять, как агент пришел к определенному выводу или решению, испытывают трудности с формированием доверия. Отсутствие понимания логики рассуждений агента затрудняет оценку надежности его работы и своевременное вмешательство для исправления возможных ошибок. Это, в свою очередь, снижает эффективность взаимодействия человека и искусственного интеллекта, поскольку пользователь вынужден либо слепо доверять системе, либо постоянно контролировать ее действия, что сводит на нет преимущества автоматизации.
Отсутствие прозрачности в работе автономных агентов создает значительные трудности для пользователя при определении границ доверия и необходимости вмешательства. Когда логика принятия решений агентом остается «черным ящиком», сложно оценить надежность его результатов и понять, в каких ситуациях полагаться на автоматизированный вывод, а в каких — требовать корректировки или перепроверки. Это особенно критично в областях, где ошибки могут иметь серьезные последствия, поскольку пользователь лишается возможности адекватно оценивать риски и контролировать процесс выполнения задачи. Без понимания причин, лежащих в основе действий агента, невозможно сформировать обоснованное доверие и эффективно сотрудничать с ним, что снижает общую эффективность системы и ограничивает возможности ее применения.
![Интерфейс Magentic-UI позволяет пользователям вводить задачи, совместно планировать и адаптироваться к ошибкам в процессе выполнения, отслеживая план в виде шагов [B], визуальный трейс действий [C, F] и скриншоты, а также взаимодействовать с чатом [H] и одновременно выполнять несколько задач [G] для повышения эффективности верификации.](https://arxiv.org/html/2602.16844v1/x2.png)
Освещение Рассуждений Агента посредством Визуализации Трассировки
Для обеспечения прозрачности работы агента и облегчения понимания его действий, внедрен комплекс методов визуализации трассировки рассуждений. Эти методы позволяют пользователю наблюдать за последовательностью логических шагов, предпринятых агентом для достижения цели. Визуализация включает в себя отображение потока обработки данных, источников информации, на которых основываются решения, и четкое определение исходных требований и допущений, влияющих на процесс рассуждений. Данный подход направлен на раскрытие внутренней логики агента и предоставление пользователю возможности отследить путь от входных данных к конечному результату.
Визуализация процесса рассуждений агента осуществляется посредством комплекса инструментов, включающего в себя блок-схемы, отражающие последовательность действий и логические переходы; систему цитирования, выделяющую ключевую информацию, на которой основываются решения агента; и спецификации, детализирующие требования и допущения, принятые в процессе работы. Блок-схемы обеспечивают наглядное представление алгоритма принятия решений, цитирования позволяют проследить источник данных и обоснованность выводов, а спецификации обеспечивают прозрачность в отношении ограничений и условий, влияющих на поведение агента.
Визуализация логики работы агента направлена на преодоление разрыва между его действиями и пониманием этих действий пользователем. Это достигается путем представления внутреннего процесса принятия решений в наглядной форме, позволяющей проследить последовательность шагов, которые привели к конкретному результату. Такой подход обеспечивает прозрачность работы агента, облегчая верификацию его логики и выявление потенциальных ошибок или нежелательного поведения. Предоставление пользователю возможности отслеживать ход рассуждений агента способствует повышению доверия к системе и облегчает взаимодействие с ней.
MagneticUI: Совместный Интерфейс для Верификации
Интерфейс ‘MagneticUI’ использует визуализации для организации совместного процесса верификации. Он позволяет нескольким пользователям одновременно просматривать и анализировать данные, выделяя области, требующие внимания или подтверждения. Визуализации служат общей точкой отсчета, облегчая коммуникацию и координацию между участниками процесса верификации, что повышает эффективность выявления и исправления ошибок. Данный подход позволяет объединить сильные стороны как автоматических агентов, так и экспертов-людей, обеспечивая более надежный и точный результат.
В ходе тестирования интерфейса MagneticUI было зафиксировано снижение времени обнаружения ошибок на -0.65 для корректно идентифицированных случаев. Данный показатель соответствует среднему размеру эффекта, что указывает на статистически значимое улучшение эффективности работы пользователей при поиске ошибок с использованием данного интерфейса. Полученные результаты свидетельствуют о возможности ускорения процесса верификации и повышения производительности специалистов, работающих с системой.
Интерфейс MagneticUI обеспечивает целенаправленный человеческий контроль над работой агента, что положительно сказывается как на точности его результатов, так и на уровне доверия пользователя к его возможностям. Возможность фокусировки внимания на конкретных аспектах работы агента позволяет выявлять и исправлять ошибки, которые могли быть пропущены автоматическими системами. Повышение точности и предсказуемости работы агента, в свою очередь, укрепляет уверенность пользователя в его надежности и компетентности, способствуя более эффективному взаимодействию и принятию решений на основе его выводов.
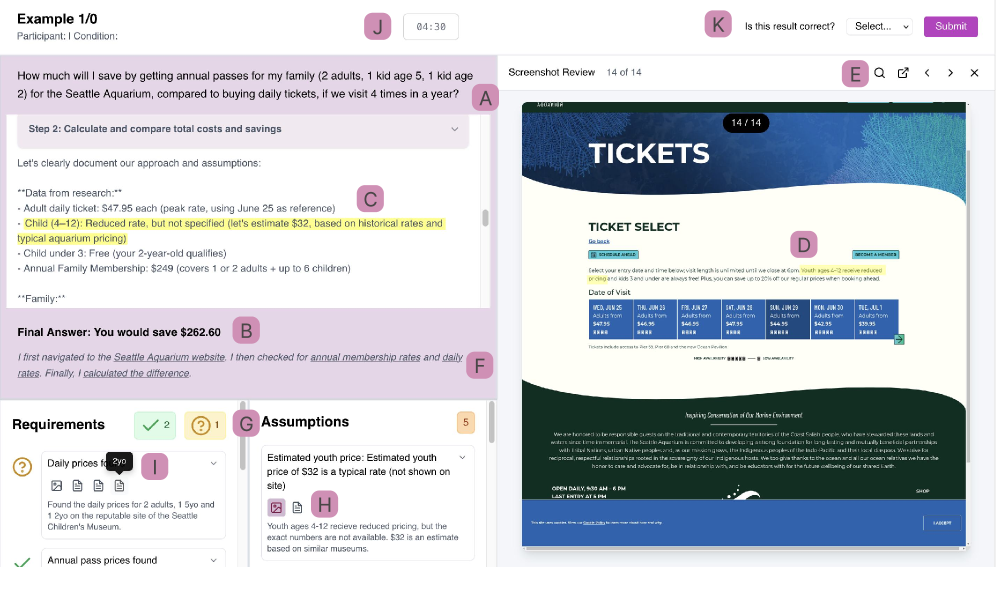
![Интерфейс исследования дизайна предоставляет участникам задание [A], его результат [B] и один из трех дизайн-зондов [C], при нажатии на который отображаются соответствующие скриншоты с выделенными аннотациями [D, E], а также оригинальный лог Magnetic-UI для дополнительного анализа [F], после чего участники отвечают на вопросы о корректности результата и его обосновании [G].](https://arxiv.org/html/2602.16844v1/x4.png)
Масштабирование Доверия: Влияние и Перспективы
Исследование показало, что обеспечение прозрачности процесса рассуждений агента, реализованное посредством интерфейса MagneticUI, заметно повышает уверенность пользователей и снижает количество ошибок, особенно при решении сложных задач. В ходе работы было установлено, что возможность отслеживать логику действий искусственного интеллекта способствует более адекватному восприятию результатов и позволяет пользователям своевременно выявлять потенциальные неточности. Это особенно важно в ситуациях, когда требуется критическая оценка предоставленной информации или принятие ответственных решений на основе предложений агента, поскольку прозрачность действий позволяет пользователю лучше понимать ограничения системы и контролировать процесс взаимодействия.
Несмотря на то, что общая статистическая значимость повышения точности ответов не была подтверждена (Hedges’ gg: 0.18), исследование выявило заметный средний эффект увеличения уверенности участников (0.85) в тех случаях, когда они ошибочно признавали неверный ответ правильным. Данный результат указывает на то, что прозрачность рассуждений агента, даже при сохранении погрешностей, способствует формированию у пользователей ложной уверенности в правильности решения. Это подчеркивает важность дальнейшего изучения механизмов, способных не только повысить точность, но и адекватно оценить степень надежности предоставляемой информации, предотвращая тем самым ошибочные заключения и способствуя более критическому восприятию результатов работы искусственного интеллекта.
Дальнейшие исследования направлены на адаптацию разработанных методов прозрачного обоснования действий агентов к более широкому спектру архитектур искусственного интеллекта. Особое внимание будет уделено автоматизации процесса выявления ошибок в рассуждениях агентов, что позволит создавать системы, способные самостоятельно корректировать неточности и повышать надежность принимаемых решений. Разработка автоматизированных механизмов обнаружения ошибок позволит значительно расширить применимость данной технологии, снизить потребность в ручном контроле и повысить эффективность работы интеллектуальных агентов в различных областях, от автоматизации задач до поддержки принятия решений в критически важных ситуациях.
![В контрольном исследовании интерфейс, практически идентичный используемому в основной группе, отображает задачу [A], окончательный ответ [B], описание действий [C], краткое заключение [D], а также функцию увеличения [F], предоставляя участникам пять минут [G] для оценки корректности вывода [H].](https://arxiv.org/html/2602.16844v1/x10.png)
Исследование способов контроля над агентами без постоянного вмешательства подчеркивает необходимость математической строгости в проектировании систем взаимодействия человек-агент. Как справедливо заметил Андрей Колмогоров: «Математика — это искусство открывать закономерности в хаосе». В данном контексте, создание эффективных трасс (записей действий) для верификации работы агентов требует не просто интуитивного понимания, а четкого, доказуемого алгоритма, обеспечивающего баланс между детализацией и абстракцией. Только в этом случае возможно достичь надежного контроля и уверенности в результатах работы сложных систем, избежав ошибок, возникающих из-за недостаточной прозрачности или избыточности информации.
Что Дальше?
Представленное исследование, хоть и демонстрирует важность продуманного дизайна трасс для верификации действий агентов, лишь касается поверхности фундаментальной проблемы. Доказательство корректности сложной системы — задача, принципиально отличающаяся от простой проверки на тестовых данных. Элегантность алгоритма не измеряется количеством пройденных тестов, а строгостью математического обоснования. Недостаточно лишь «удобства» трасс; требуется формальная гарантия, что они действительно отражают внутреннюю логику агента, а не маскируют ошибки.
Будущие работы должны сместить фокус с эмпирической оценки «удобства» на разработку формальных методов верификации. Необходимо исследовать возможность автоматического генерирования трасс, доказуемо покрывающих все значимые сценарии работы агента. При этом, необходимо помнить, что полное покрытие — утопия. Вопрос в том, как разработать алгоритмы, позволяющие выявлять наиболее критические ошибки при минимальном объеме проверяемой информации.
В конечном итоге, задача состоит не в создании «удобных» интерфейсов для наблюдения за агентами, а в разработке агентов, требующих минимального надзора. Истинная элегантность — в самодостаточности, в способности системы доказывать свою корректность, а не полагаться на бдительность человека. Любая система, требующая постоянного контроля, по определению, несовершенна.
Оригинал статьи: https://arxiv.org/pdf/2602.16844.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Неупорядоченные системы с неэрмитовыми эффектами
- Глубокое обучение: Математический фундамент
- Иллюзии понимания: Как правильно оценивать объяснимые модели
2026-02-21 08:09