Автор: Денис Аветисян
Новое исследование демонстрирует, как современные процессоры расширяют возможности глубокого обучения, но сталкиваются с фундаментальными ограничениями масштабируемости.
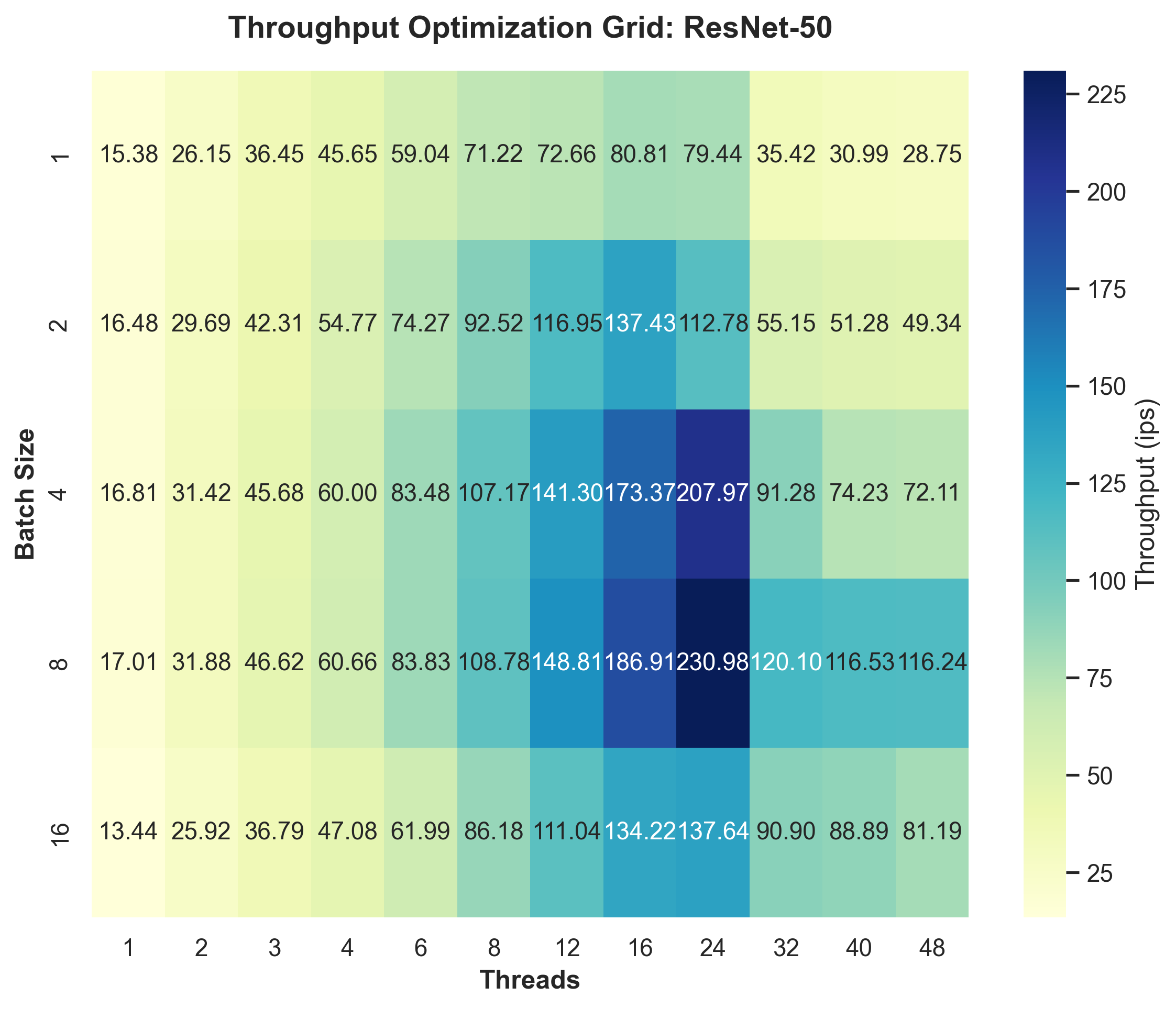
Оценка масштабирования производительности CPU в задачах глубокого обучения за десятилетие аппаратной эволюции, с анализом узких мест и пределов эффективности.
Несмотря на растущую популярность специализированных ускорителей, значительная часть задач глубокого обучения по-прежнему выполняется на центральных процессорах, особенно в устаревших центрах обработки данных. В работе ‘GDEV-AI: A Generalized Evaluation of Deep Learning Inference Scaling and Architectural Saturation’ проведена всесторонняя оценка масштабируемости CPU-инференса, сравнивающая производительность моделей ResNet на процессорах Intel Xeon E5-2403 v2 и Intel Xeon 6 «Granite Rapids». Полученные результаты демонстрируют, что современные процессоры, использующие Intel Advanced Matrix Extensions (AMX), значительно превосходят устаревшие, однако дальнейшая перегрузка сверх физического количества ядер приводит к увеличению задержек и снижению общей производительности. Каковы оптимальные стратегии масштабирования CPU-инференса в гетерогенных вычислительных средах и как эффективно использовать преимущества современных архитектур?
Пределы Производительности: Ограничения Устаревших Систем
Современные задачи инференса, особенно при использовании таких моделей, как ResNet-18 и ResNet-50, предъявляют значительно возросшие требования к вычислительным ресурсам. Эти нейронные сети, предназначенные для анализа изображений и других данных, требуют огромного количества операций для обработки каждого запроса. Увеличение сложности моделей и рост объемов обрабатываемых данных приводят к экспоненциальному увеличению нагрузки на серверы. В результате, даже относительно небольшие задачи могут потребовать значительных вычислительных мощностей, а обработка больших объемов данных становится узким местом для многих систем. Подобная тенденция диктует необходимость постоянного обновления инфраструктуры и поиска новых методов оптимизации для обеспечения приемлемой производительности и масштабируемости.
Существующая серверная инфраструктура, на примере процессора Intel Xeon E5-2403 v2, зачастую демонстрирует ограниченную пропускную способность при обработке современных задач машинного обучения. Исследования показывают, что при использовании популярной модели ResNet-50, скорость обработки составляет приблизительно 7.33 изображения в секунду. Данный показатель свидетельствует о существенных ограничениях в текущих системах, не позволяющих эффективно справляться с возрастающими требованиями к скорости и объему обрабатываемых данных, что критически важно для приложений, требующих обработки изображений в реальном времени.
Ограничения производительности современных систем для задач машинного обучения зачастую связаны с узкими местами в вычислительной мощности и пропускной способности памяти. В частности, обработка больших объемов данных, необходимых для работы нейронных сетей, требует одновременного доступа к значительным объемам информации. Недостаточная скорость процессора и ограниченная пропускная способность оперативной памяти приводят к задержкам в передаче данных между этими компонентами, что существенно снижает общую производительность системы. Эта проблема особенно актуальна при работе со сложными моделями, такими как ResNet-50, где высокая скорость обработки данных критически важна для обеспечения необходимой пропускной способности и минимизации задержек. В результате, даже при наличии достаточного количества вычислительных ресурсов, узкие места в памяти могут стать определяющим фактором, ограничивающим скорость обработки и общую эффективность системы.
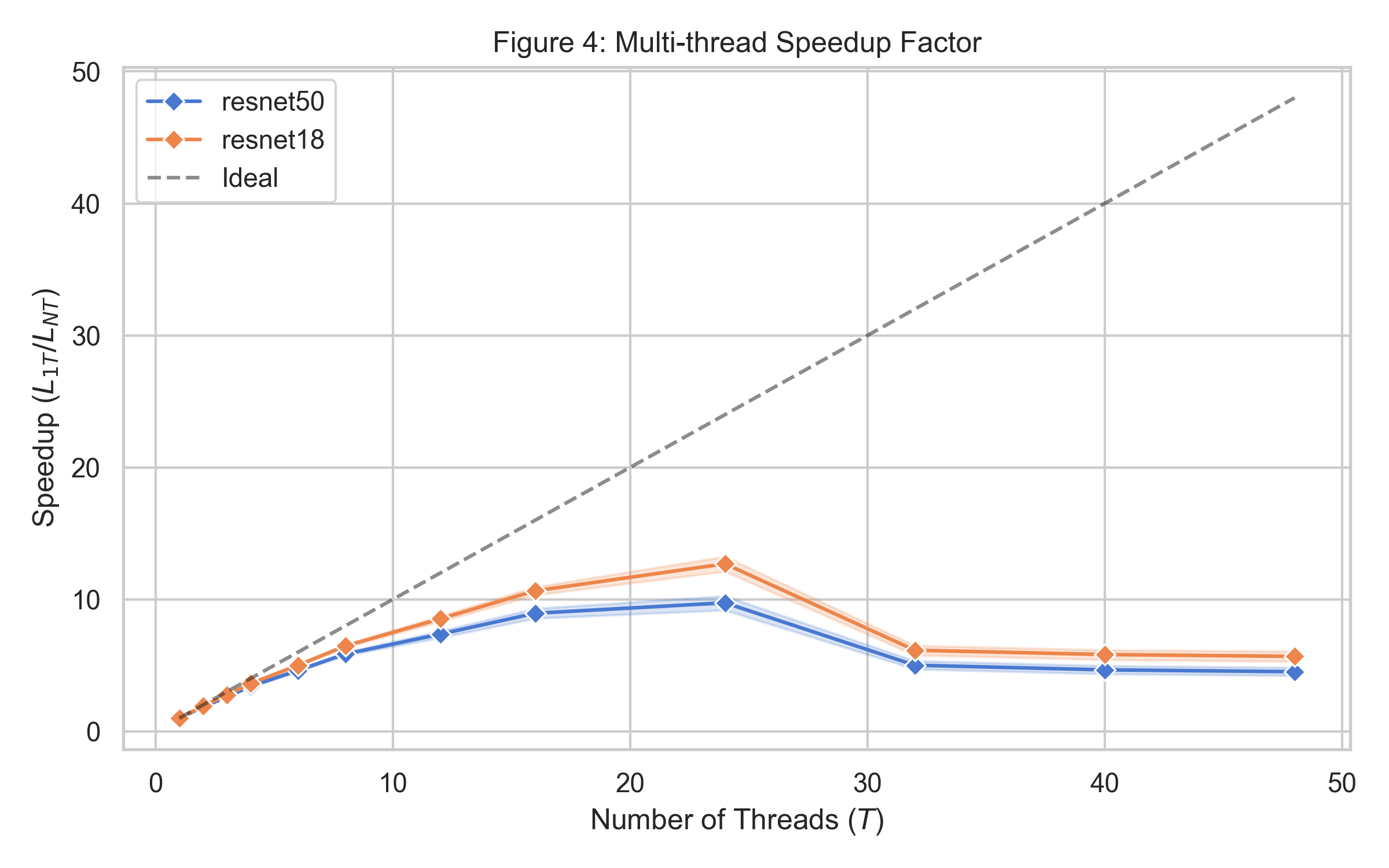
Современная Архитектура: Intel Xeon Granite Rapids и DDR5
Процессор Intel Xeon Granite Rapids демонстрирует значительное повышение вычислительных возможностей благодаря внедрению расширенного набора инструкций AVX-512. Данный набор позволяет выполнять векторные операции над 512-битными регистрами, что существенно увеличивает производительность в задачах, интенсивно использующих операции с плавающей точкой и обработку больших объемов данных. Поддержка AVX-512 обеспечивает ускорение в приложениях, таких как машинное обучение, научное моделирование и анализ данных, за счет параллельной обработки данных и повышения эффективности вычислений.
Платформа, использующая процессоры Intel Xeon Granite Rapids в сочетании с оперативной памятью DDR5, обеспечивает существенное увеличение пропускной способности памяти по сравнению с предыдущими поколениями. Переход на DDR5 позволяет достичь скорости передачи данных до 5600 МТ/с и выше, что более чем в два раза превышает максимальную пропускную способность, доступную в системах DDR4. Увеличенная пропускная способность позволяет значительно ускорить обработку больших объемов данных, критически важных для таких задач, как машинное обучение, анализ данных и высокопроизводительные вычисления. Помимо увеличения скорости передачи, DDR5 также предлагает повышенную плотность модулей памяти, что позволяет устанавливать больший объем оперативной памяти в серверных системах.
Наши результаты демонстрируют, что комбинация процессора Intel Xeon Granite Rapids и памяти DDR5 обеспечивает 32-кратное увеличение пропускной способности при выполнении операций инференса. Данный прирост производительности обусловлен значительным увеличением пропускной способности памяти и улучшенными возможностями обработки данных процессором. Измерения показывают существенное сокращение времени, необходимого для выполнения операций инференса, что критически важно для приложений, требующих обработки больших объемов данных в реальном времени, таких как машинное обучение и анализ данных.
Оптимизация Инференса: Стратегии Параллелизма и Пакетной Обработки
Исследования показали, что ключевые параметры инференса, такие как размер пакета (Batch Size) и количество потоков (Thread Count), оказывают существенное влияние на пропускную способность (Inference Throughput) и задержку (Inference Latency). Увеличение размера пакета позволяет обрабатывать несколько входных данных параллельно, что повышает пропускную способность, но может увеличивать задержку из-за суммарного времени обработки. В свою очередь, увеличение количества потоков позволяет более эффективно использовать многоядерные процессоры, но при превышении оптимального значения может приводить к накладным расходам, связанным с переключением контекста, и снижению общей производительности. Оптимальные значения этих параметров зависят от аппаратной конфигурации и характеристик модели.
Эффективное использование параметров, таких как размер пакета (Batch Size) и количество потоков (Thread Count), позволяет распараллеливать вычисления, что существенно увеличивает пропускную способность (Inference Throughput) и снижает задержку (Inference Latency). Распараллеливание достигается путем разделения задачи инференса на несколько независимых частей, которые могут выполняться одновременно на различных ядрах CPU или GPU. Максимизация использования аппаратных ресурсов достигается за счет оптимального выбора этих параметров, позволяющего избежать простоев и обеспечить высокую загрузку процессора или графического ускорителя, что особенно важно при обработке больших объемов данных или требовании высокой скорости отклика.
Использование утилиты Taskset для привязки процессов к конкретным ядрам CPU позволяет повысить стабильность производительности при инференсе. Привязка процессов к фиксированным ядрам снижает вероятность перемещения процессов между ядрами, что, в свою очередь, уменьшает накладные расходы, связанные с переключением контекста и кэшированием данных. Это особенно важно для моделей, требующих больших вычислительных ресурсов, поскольку минимизирует задержки, вызванные перемещением данных между разными ядрами и уровнями кэша, обеспечивая более предсказуемое время отклика и высокую пропускную способность.
Анализ Узких Мест Производительности с Использованием Roofline Модели
Анализ с использованием Roofline модели показал прямую зависимость между Операционной Интенсивностью (Operational Intensity) и достижимой Пропускной Способностью при выводе (Inference Throughput). Операционная Интенсивность, определяемая как количество операций с плавающей точкой (FLOPs) на байт переданных данных, является ключевым показателем эффективности использования вычислительных ресурсов. Высокая Операционная Интенсивность указывает на то, что вычисления требуют относительно небольшого объема доступа к памяти, и производительность ограничена вычислительной мощностью процессора. И наоборот, низкая Операционная Интенсивность указывает на то, что производительность ограничена пропускной способностью памяти. Таким образом, анализ Roofline позволяет определить, является ли узким местом производительности вычислительная мощность или пропускная способность памяти, что критически важно для оптимизации производительности моделей машинного обучения.
Анализ с использованием Roofline модели позволил установить, является ли ограничением производительности вычислительная мощность или пропускная способность памяти. При анализе производительности модели машинного обучения, мы определяли, насколько эффективно используются доступные вычислительные ресурсы по сравнению с объемом перемещаемых данных. Если производительность ограничена вычислительной мощностью, увеличение тактовой частоты или использование более мощных вычислительных блоков может улучшить результаты. Если же ограничением является пропускная способность памяти, необходимо оптимизировать доступ к данным, уменьшить объем перемещаемых данных или использовать более быструю память. Выявление конкретного ограничения позволяет целенаправленно применять методы оптимизации для достижения максимальной производительности.
Анализ данных показал, что на платформе Granite Rapids «гребень» (Ridge Point) модели производительности находится на уровне 8.0 FLOPs/byte, что значительно выше показателя в 3.6 FLOPs/byte, зафиксированного на устаревшей системе. Данное различие указывает на то, что для достижения максимальной производительности на Granite Rapids требуется более высокая вычислительная интенсивность — то есть, больше операций с плавающей точкой на каждый байт переданных данных — по сравнению с предыдущей архитектурой. Это означает, что приложения, недостаточно использующие вычислительные ресурсы на байт данных, будут ограничены пропускной способностью памяти на Granite Rapids.
Перспективы Развития: Максимизация Эффективности Инференса
Полученные результаты подчеркивают критическую важность совместной разработки аппаратного и программного обеспечения для достижения оптимальной производительности при выводе данных. Традиционный подход, при котором аппаратное обеспечение и программное обеспечение разрабатываются независимо, часто приводит к неэффективному использованию ресурсов и ограничению общей производительности. Совместное проектирование позволяет учитывать особенности архитектуры процессора и памяти на этапе разработки программного обеспечения, а также адаптировать аппаратную часть под специфические требования алгоритмов машинного обучения. Это обеспечивает максимальную эффективность использования пропускной способности памяти, оптимизацию вычислительных операций и, как следствие, значительное увеличение скорости вывода и снижение задержек. Особенно актуально данное направление в контексте постоянно растущих требований к производительности систем искусственного интеллекта и необходимости обработки больших объемов данных в реальном времени.
Дальнейшие исследования должны быть направлены на изучение инновационных моделей доступа к памяти и организации данных, с целью максимального использования пропускной способности памяти. Эффективное использование памяти является критически важным фактором для повышения производительности нейронных сетей, особенно при работе с большими объемами данных. Разработка новых алгоритмов, оптимизирующих последовательность чтения и записи данных, а также переосмысление структуры хранения данных в памяти, позволит существенно снизить задержки и увеличить скорость обработки информации. Особое внимание следует уделить адаптации этих моделей к различным архитектурам аппаратного обеспечения и специфическим требованиям конкретных задач машинного обучения, что позволит добиться оптимальной производительности и энергоэффективности.
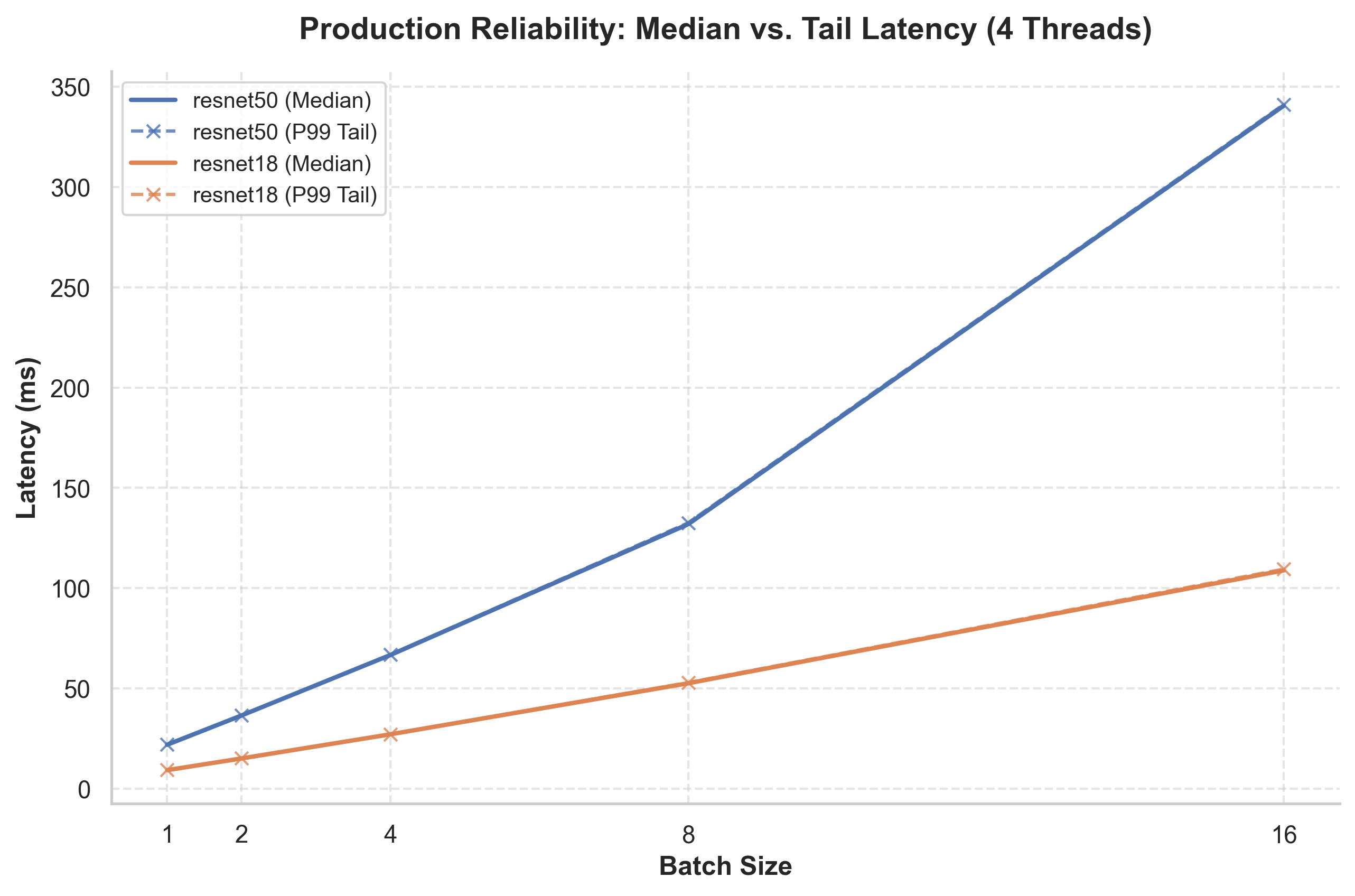
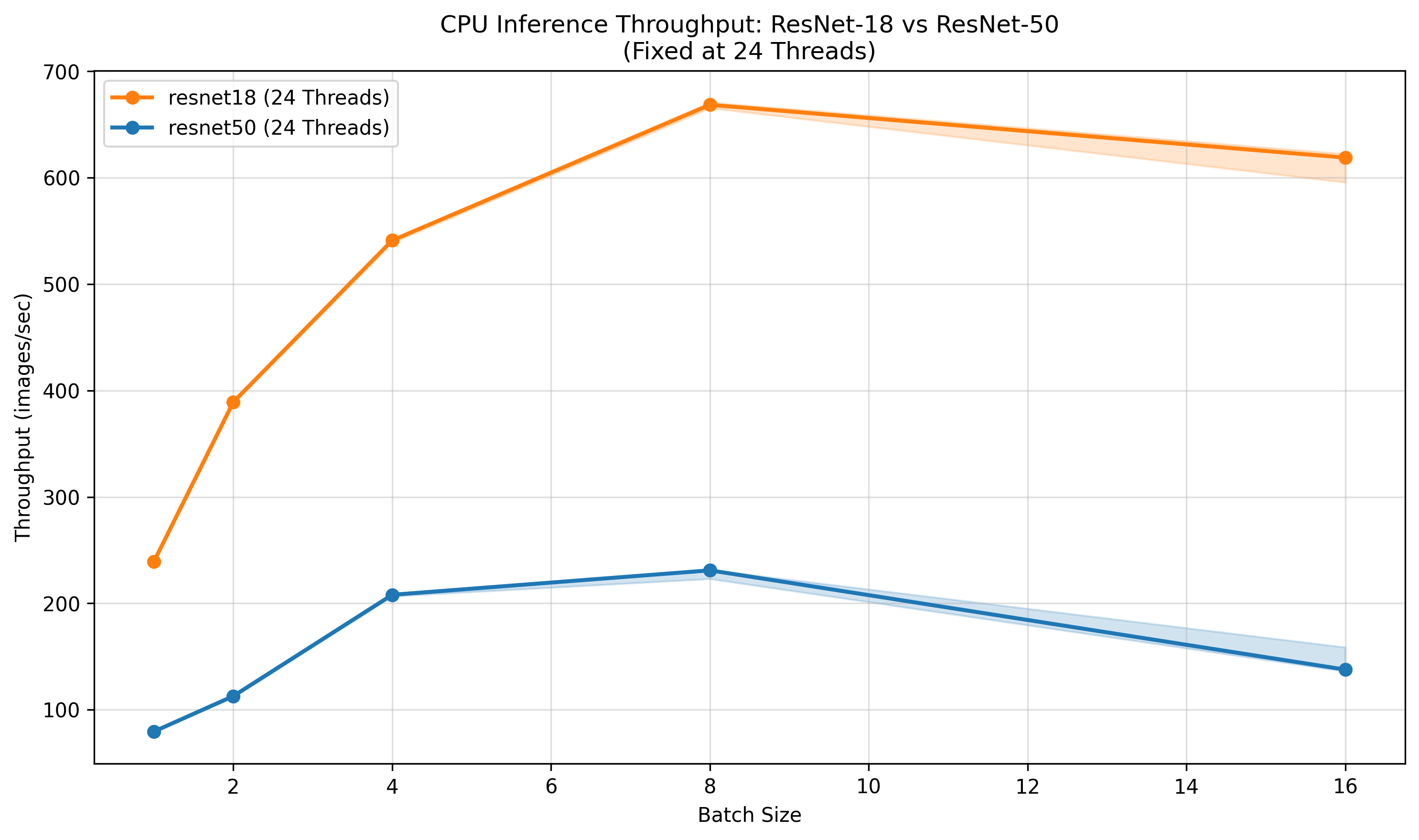
В ходе исследований, с использованием процессора Intel Xeon Granite Rapids, удалось достичь пиковой производительности в обработке изображений, составившей 668.58 кадров в секунду для модели ResNet-18 и 230.98 кадров в секунду для ResNet-50. Задержка обработки, измеренная для ResNet-50 при размере пакета в 8 изображений, составила приблизительно 35 миллисекунд. Эти показатели демонстрируют значительный потенциал аппаратного обеспечения для ускорения задач глубокого обучения и обработки изображений в реальном времени, открывая новые возможности для приложений, требующих высокой пропускной способности и минимальной задержки.
Исследование, представленное в статье, демонстрирует, что современная аппаратная архитектура, такая как Granite Rapids, значительно улучшает производительность CPU-инференса глубокого обучения. Однако, анализ показывает, что масштабирование производительности ограничено физическим количеством ядер и пропускной способностью памяти. Этот факт находит отражение в словах Винтона Серфа: «Интернет — это просто сеть сетей». Подобно тому, как интернет зависит от взаимосвязей между отдельными сетями, производительность глубокого обучения ограничена взаимосвязью между вычислительными ресурсами. Статья убедительно доказывает, что дальнейший прогресс требует не только увеличения мощности отдельных ядер, но и оптимизации архитектуры для эффективного использования доступных ресурсов.
Куда же дальше?
Представленное исследование, хотя и демонстрирует значительный прогресс в оптимизации CPU-инференса глубоких нейронных сетей, не решает фундаментальную проблему: насыщение архитектурных возможностей. Увеличение числа ядер и пропускной способности памяти, безусловно, приносит выгоды, но асимптотически эти улучшения неизбежно замедляются. Вопрос не в том, как «выжать» больше из существующих ресурсов, а в том, как переосмыслить саму парадигму инференса. До тех пор, пока алгоритмы остаются зависимыми от последовательных вычислений, их масштабирование будет ограничено физическими пределами кремния.
Очевидным направлением является поиск алгоритмических решений, способных эффективно распараллеливаться на уровне отдельных операций, а не только на уровне батчей. Иными словами, необходимо стремиться к алгоритмам, инвариантным к размеру батча, и к архитектурам, способным динамически адаптироваться к изменяющимся требованиям вычислительной мощности. Предлагаемые решения должны быть не просто «рабочими», а доказуемо оптимальными, с четкой оценкой их вычислительной сложности и потребления памяти.
В конечном счете, истинный прогресс потребует отхода от эмпирических тестов и возвращения к математической строгости. До тех пор, пока алгоритмы рассматриваются как «черные ящики», оптимизация будет оставаться искусством, а не наукой. Необходимо разработать формальные модели, позволяющие предсказывать производительность алгоритмов в различных аппаратных конфигурациях, и доказать их корректность и оптимальность. Лишь тогда можно будет говорить об истинной элегантности и эффективности решений.
Оригинал статьи: https://arxiv.org/pdf/2602.16858.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Квантовые ограничения в хаотичных сплавах: взгляд на Si/SiGe/Si
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Квантовое моделирование: от проблемных решений к универсальному программному обеспечению
2026-02-21 08:14