Автор: Денис Аветисян
Новая модель искусственного интеллекта демонстрирует способность к планированию и прогнозированию в сложной игровой среде StarCraft II, значительно превосходя стандартные алгоритмы.
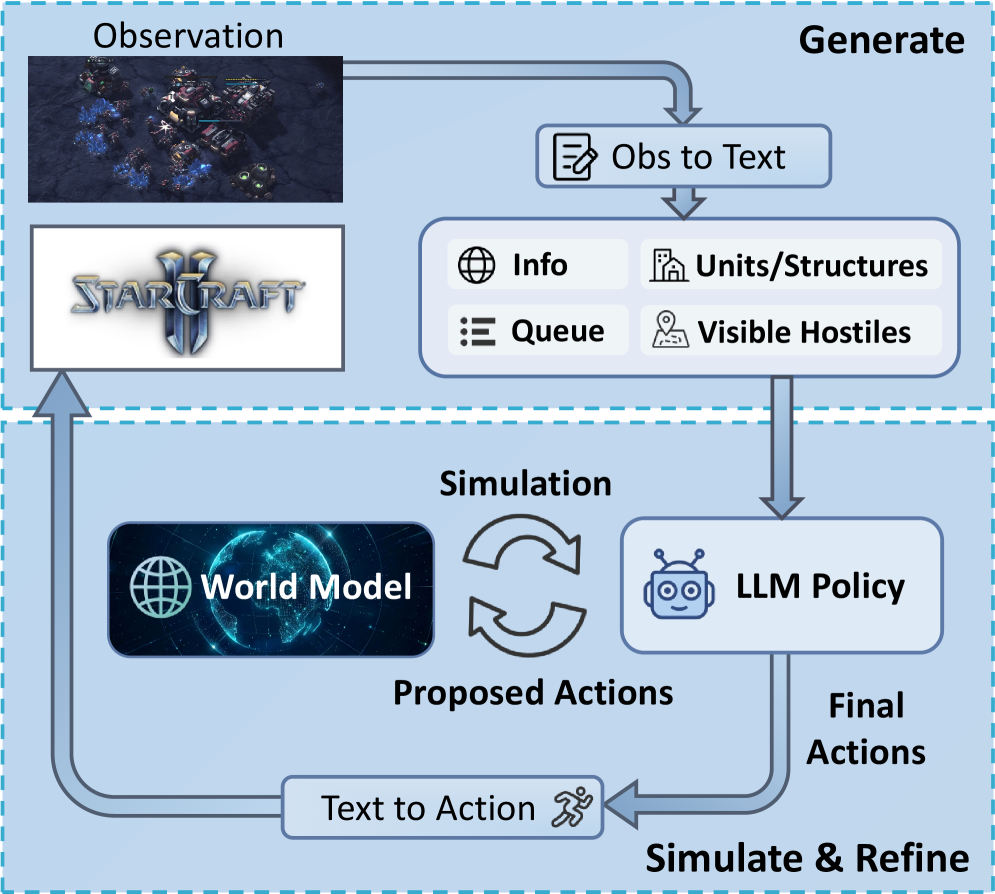
В статье представлена StarWM — первая в своем роде модель мира для StarCraft II, использующая принцип «сгенерировать-смоделировать-уточнить» для улучшения процесса принятия решений и повышения эффективности против встроенного ИИ.
Несмотря на впечатляющие успехи больших языковых моделей (LLM) в различных областях, их применение в качестве стратегий принятия решений в сложных, частично наблюдаемых средах, таких как StarCraft II, остается недостаточно изученным. В данной работе, ‘World Models for Policy Refinement in StarCraft II’, представлена StarWM — первая в своем роде модель мира для SC2, позволяющая прогнозировать будущие наблюдения и интегрироваться в контур принятия решений посредством итеративного процесса «генерация-симуляция-уточнение». Эксперименты демонстрируют значительное улучшение производительности StarWM как в оффлайн-оценке точности прогнозирования, так и в онлайн-играх против встроенного ИИ, достигая прироста винрейта до 30% на различных уровнях сложности. Способна ли подобная архитектура, основанная на предсказании динамики среды, открыть новые горизонты для создания более интеллектуальных и адаптивных агентов в сложных игровых и реальных сценариях?
Преодолевая Ограничения: Моделирование Сложности StarCraft II
Традиционные методы обучения с подкреплением испытывают значительные трудности применительно к сложным играм, таким как StarCraft II, из-за необходимости планирования на длительный горизонт и работы с неполной информацией. В отличие от задач, где агент может мгновенно оценить последствия своих действий, в StarCraft II принятое решение может иметь отложенные и непредсказуемые последствия, требуя прогнозирования на многие шаги вперёд. Кроме того, игрок не имеет полного доступа к информации о противнике — позиции юнитов, ресурсы, планы — что создает условия неопределенности. В результате, стандартные алгоритмы обучения с подкреплением часто оказываются неспособными эффективно исследовать пространство возможных стратегий и адаптироваться к динамично меняющейся игровой обстановке, что ограничивает их способность достигать высоких результатов в столь сложной среде.
Для успешной навигации в сложной среде StarCraft II, агентам требуется не просто реагировать на текущие события, но и формировать устойчивую модель игровой динамики. Простые реактивные стратегии, основанные на непосредственном отклике на стимулы, оказываются недостаточными для достижения долгосрочных целей в игре, где важны предвидение и планирование. Способность агента к внутреннему моделированию позволяет ему предсказывать последствия своих действий, оценивать вероятные ходы противника и адаптировать свою стратегию, значительно превосходя по эффективности системы, ограниченные лишь немедленным откликом. Такое моделирование включает в себя понимание не только видимой информации, но и скрытых факторов, определяющих игровой процесс, что позволяет агенту действовать разумно даже в условиях неопределенности.
Игровая среда StarCraft II характеризуется неполной наблюдаемостью и необходимостью долгосрочного планирования, что делает её идеальной площадкой для проверки алгоритмов искусственного интеллекта. Частично наблюдаемые марковские процессы принятия решений (POMDP) позволяют формально описать эту сложность, моделируя ситуацию, когда агент имеет лишь частичную информацию о состоянии игры. В рамках данной модели, успешное функционирование агента требует не просто реакции на текущие события, а способности оценивать вероятности различных состояний игры и принимать решения, учитывая неопределённость. Таким образом, POMDP подчёркивает важность разработки агентов, способных к рассуждениям в условиях неполной информации и эффективному планированию действий на основе вероятностных оценок, что является ключевым шагом к созданию действительно интеллектуальных игровых систем.
StarWM: Мировая Модель для Дальновидного Планирования
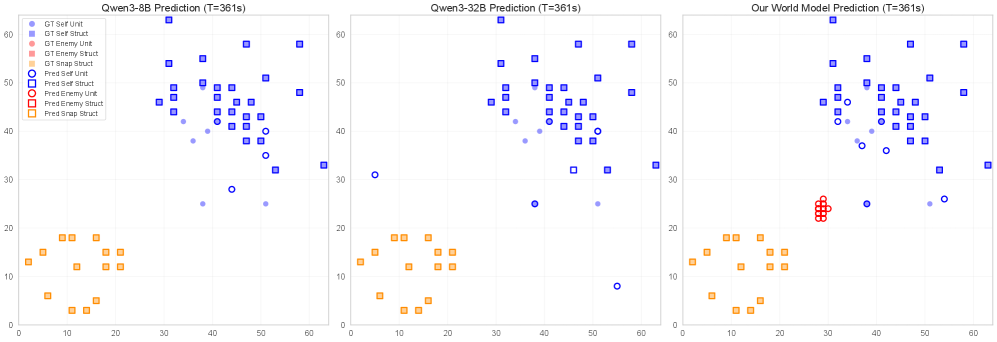
StarWM представляет собой новый подход к принятию решений агентами, основанный на интеграции обучаемой модели переходов, зависящей от действий. Данная модель прогнозирует будущие состояния игры, учитывая текущее состояние и выбранное действие. В отличие от традиционных методов, использующих непосредственное обучение политике, StarWM позволяет агенту моделировать динамику игры и предвидеть последствия своих действий на несколько шагов вперед. Обучение модели осуществляется путем прогнозирования следующего состояния игры, учитывая текущее состояние и действие, предпринятое агентом или противником. Это позволяет агенту строить внутреннюю репрезентацию мира и использовать ее для планирования и принятия оптимальных решений в сложных ситуациях.
В основе функционирования StarWM лежит метод представления наблюдений в StarCraft II посредством текстового представления наблюдений (Textual Observation Representation). Этот метод структурирует информацию об игровом состоянии в виде семантических модулей, что позволяет агенту более эффективно обрабатывать и понимать входящие данные. Каждый модуль представляет собой конкретный аспект игровой ситуации, например, информацию о юнитах, ресурсах или структуре местности. Такое модульное представление позволяет агенту акцентировать внимание на релевантных деталях и игнорировать несущественную информацию, упрощая процесс принятия решений и планирования действий.
Архитектура StarWM обучается на наборе данных SC2Dynamics50k, содержащем 50 тысяч эпизодов игрового процесса StarCraft II. Этот датасет включает в себя последовательности состояний игры, действий игрока и соответствующих переходов между состояниями. Использование SC2Dynamics50k позволяет агенту выучить сложные зависимости между действиями и их последствиями в динамичной игровой среде, формируя детализированное представление о игровой механике и стратегиях. Набор данных охватывает широкий спектр игровых ситуаций и действий, обеспечивая обобщающую способность модели при планировании и прогнозировании.
Основной принцип подхода StarWM заключается в наделении агентов способностью предвидеть последствия своих действий, что позволяет существенно улучшить долгосрочное планирование. Это достигается за счет обучения модели предсказания будущих состояний игры, обусловленной действиями агента. Агент, моделируя вероятные исходы, может оценивать различные стратегии и выбирать оптимальную с учетом долгосрочных целей. Такой механизм позволяет не просто реагировать на текущую ситуацию, но проактивно формировать благоприятные условия для достижения поставленных задач, повышая эффективность принятия решений в динамичной игровой среде.

StarWM_Agent: Интеграция Дальновидности в Действие
Агент StarWM_Agent использует конвейер «Генерация-Симуляция-Уточнение» (Generate-Simulate-Refine) для использования предсказательных возможностей мировой модели StarWM. На этапе генерации агент создает набор потенциальных действий, основанных на текущем состоянии игры. Затем, для каждого действия, конвейер запускает симуляцию развития событий в игровой среде, используя StarWM для прогнозирования результатов. Полученные результаты оцениваются, и агент уточняет свою стратегию, выбирая действия, которые, согласно симуляции, приводят к наиболее благоприятным исходам. Этот процесс позволяет агенту не просто реагировать на происходящее, но и планировать свои действия, учитывая их долгосрочные последствия.
Агент StarWM_Agent использует симуляцию потенциальных действий для оценки их последствий и последующей оптимизации стратегии. В рамках этого процесса, перед выполнением действия, агент генерирует несколько возможных сценариев развития событий, основанных на текущем состоянии игрового мира и предсказываемых реакциях других агентов. Каждый сценарий оценивается на основе заданных критериев, таких как достижение целей, минимизация рисков и максимизация вознаграждения. На основании анализа результатов симуляции, агент выбирает действие, которое, по прогнозам, приведет к наиболее благоприятному исходу, тем самым повышая эффективность и стратегическую глубину своей игры.
В отличие от традиционных реактивных методов, основанных на немедленном отклике на текущую ситуацию, StarWM_Agent использует прогностический подход, позволяющий ему формировать состояние игры. Реактивные агенты действуют исключительно на основе текущего кадра, в то время как StarWM_Agent, благодаря моделированию возможных сценариев развития событий, способен предвидеть последствия своих действий и выбирать оптимальную стратегию для достижения долгосрочных целей. Это позволяет агенту не просто реагировать на происходящее, а активно влиять на ход игры, создавая благоприятные условия для себя и изменяя игровую среду в соответствии со своими потребностями.
Использование конвейера «Generate-Simulate-Refine» позволяет агенту StarWM_Agent оценивать отдаленные последствия своих действий, выходя за рамки немедленной реакции на текущую ситуацию. В процессе симуляции, агент предсказывает развитие событий на несколько шагов вперед, анализируя влияние каждого действия на долгосрочную стратегическую позицию. Это позволяет выбирать действия, максимизирующие вероятность достижения целей в перспективе, а не только оптимизирующие текущий игровой момент. В результате, игровой процесс становится более продуманным и эффективным, поскольку агент способен предвидеть и избегать потенциальных проблем, а также использовать возможности, которые могут проявиться в будущем.
Количественная Оценка: Многомерные Метрики Эффективности
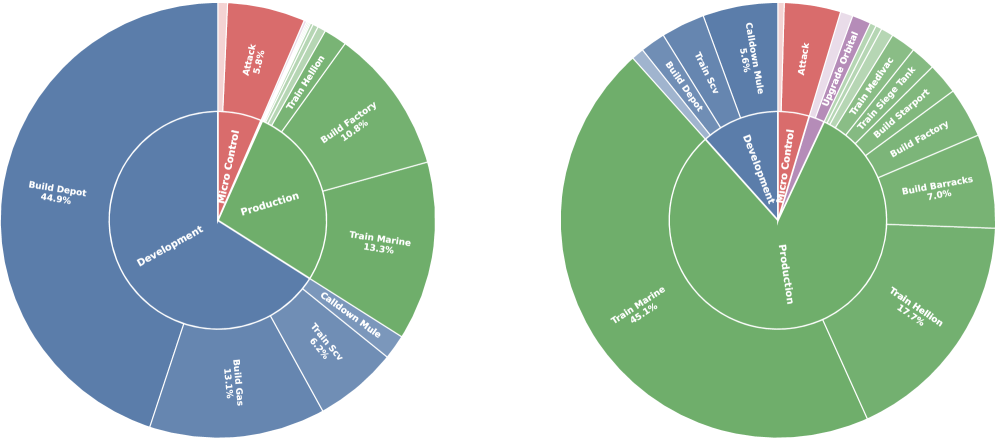
Для всесторонней оценки эффективности агента StarWM была разработана многомерная система оценки, охватывающая как стратегические, так и экономические аспекты его деятельности. Данный подход, известный как MultiDimensionalOfflineEvaluation, позволил комплексно проанализировать поведение агента в различных игровых ситуациях, выходя за рамки простой статистики побед и поражений. Оценка проводилась по ряду ключевых показателей, включая скорость накопления ресурсов, эффективность боевых действий и способность блокировать поставки противника, что позволило получить детальное представление о сильных и слабых сторонах агента и выявить области для дальнейшей оптимизации. Использование многомерного подхода гарантирует, что оценка не ограничивается одним аспектом игры, а учитывает комплексное взаимодействие различных факторов, определяющих успех в StarCraft II.
Для всесторонней оценки эффективности разработанного агента использовался комплекс ключевых метрик, позволяющих получить полную картину его возможностей. Показатель WinRate, отражающий процент выигранных сражений, дополнялся оценкой ResourceConversionRate — эффективности преобразования ресурсов в военную мощь. Важным индикатором являлся KillLossRatio, демонстрирующий соотношение уничтоженной вражеской техники к потерям собственной, а также SupplyBlockRate — способность агента эффективно блокировать поставки ресурсов противнику. Совокупность этих метрик позволила получить объективную оценку стратегических и экономических навыков агента, выявив сильные стороны и области для дальнейшей оптимизации.
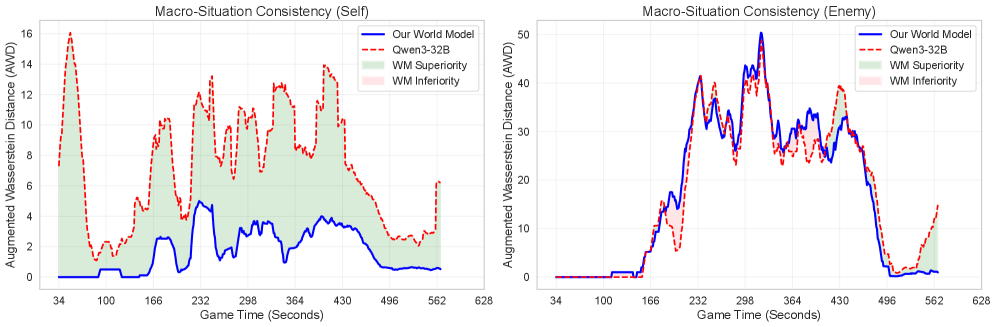
Агент StarWM продемонстрировал значительное улучшение результативности в игровых сражениях, достигнув 30% повышения процента побед против оппонентов седьмого уровня при использовании 32-бильной модели. Этот результат свидетельствует о существенном прогрессе в способности агента к планированию и принятию решений, основанных на прогнозировании развития событий. Улучшение демонстрирует, что модель эффективно использует информацию о будущем состоянии игры для выбора оптимальных стратегий, что позволяет ей превосходить противников в долгосрочной перспективе и достигать более высоких результатов.
В ходе онлайн-тестирования зафиксировано заметное улучшение ключевых показателей эффективности агента. В частности, наблюдается повышение коэффициента конверсии ресурсов, что свидетельствует о более рациональном использовании имеющихся средств для достижения поставленных целей. Кроме того, улучшился показатель Kill-Loss Ratio, указывающий на более эффективное ведение боевых действий и снижение потерь. Наконец, зафиксировано увеличение Supply Block Rate, демонстрирующее способность агента эффективно блокировать поставки ресурсов противнику и нарушать его экономическую деятельность. Эти улучшения в совокупности подтверждают высокую эффективность и конкурентоспособность разработанного агента в реальных условиях игры.
Агент, использующий модель StarWM, продемонстрировал значительное улучшение в предсказании ресурсов, достигнув прироста в 60% по сравнению с базовыми моделями, работающими без предварительного обучения. Такой существенный прогресс в точности предсказания позволяет агенту более эффективно планировать стратегию, оптимизировать сбор ресурсов и принимать взвешенные решения в динамичной игровой среде. Повышенная способность прогнозировать доступность ресурсов является ключевым фактором, влияющим на общую эффективность агента, позволяя ему предвидеть потенциальные ограничения и адаптироваться к изменяющимся условиям, что, в свою очередь, приводит к более стабильным и успешным результатам в игровых сценариях.
Исследование, представленное в статье, демонстрирует стремление к созданию систем, способных к глубокому пониманию игровой среды StarCraft II. Авторы, разрабатывая StarWM, фактически стремятся к построению детерминированной модели мира, позволяющей предсказывать последствия действий и оптимизировать стратегию. Этот подход созвучен принципам математической строгости, ведь корректность алгоритма должна быть доказана, а не просто эмпирически подтверждена. Как однажды заметил Пол Эрдеш: «Математика — это искусство предвидеть последствия.». В данном случае, способность StarWM к генерации, симуляции и уточнению стратегии является прямым воплощением этого предвидения, позволяя агенту принимать обоснованные решения в условиях неполной информации — ключевой особенностью частично наблюдаемых марковских процессов принятия решений (POMDP).
Куда же дальше?
Представленная работа, хотя и демонстрирует возможность построения модели мира для StarCraft II, лишь открывает врата в лабиринт нерешенных вопросов. Элегантность алгоритма не измеряется количеством побед над встроенным ИИ, но строгостью математической гарантии его корректности. Текущие модели мира, будучи полезными, остаются уязвимыми к непредсказуемости реальной игровой среды и ограничены в способности к экстраполяции. Истинный прогресс требует не просто генерации симуляций, а разработки формальных методов верификации этих симуляций, доказательства их адекватности.
Следующим шагом представляется не увеличение вычислительных ресурсов для усложнения модели мира, а поиск принципиально новых подходов к представлению знаний. Существующие методы, опирающиеся на аппроксимации, неизбежно сталкиваются с проблемой накопления ошибок. Более перспективным представляется исследование возможностей использования формальных логических систем и методов символьной регрессии для построения компактных и доказуемо корректных моделей игровой среды.
В конечном итоге, создание по-настоящему интеллектуального агента для StarCraft II требует не просто эффективной стратегии, а глубокого понимания принципов принятия решений в условиях неопределенности. Задача заключается не в том, чтобы «обмануть» противника, а в том, чтобы предвидеть его действия и адаптироваться к меняющейся обстановке. И, возможно, в этом поиске мы найдем не только ключ к победе в игре, но и более общее понимание природы интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.14857.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Неупорядоченные системы с неэрмитовыми эффектами
- Глубокое обучение: Математический фундамент
- Иллюзии понимания: Как правильно оценивать объяснимые модели
2026-02-21 14:44