Автор: Денис Аветисян
Исследователи представили XrayVisual — модель, способную эффективно обрабатывать изображения и видео в огромных объемах данных из социальных сетей.
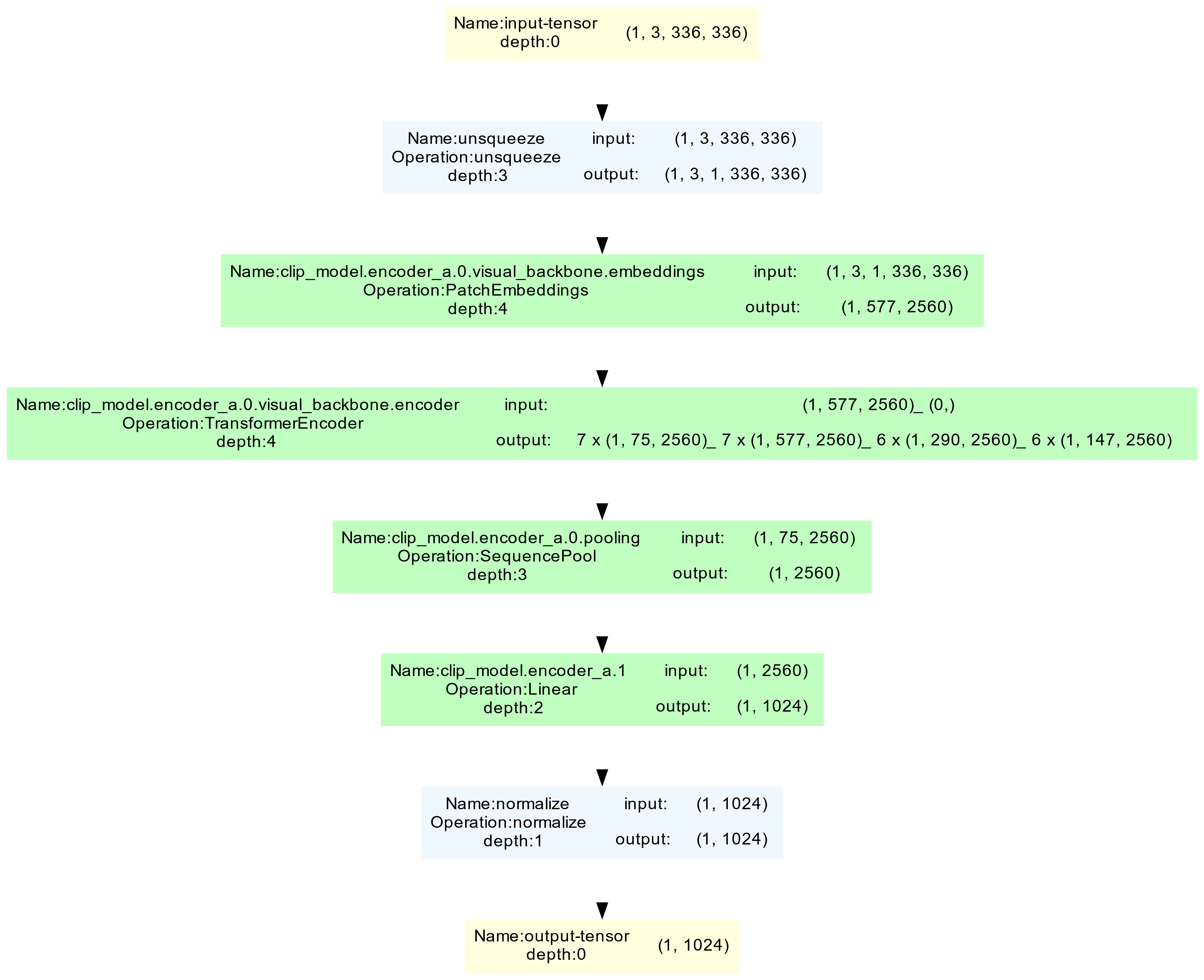
Новая архитектура и трехэтапный процесс обучения позволяют достичь передовых результатов в области мультимодального обучения и повысить эффективность использования данных.
Несмотря на значительные успехи в области компьютерного зрения, масштабирование моделей для обработки огромных объемов неструктурированных данных остается сложной задачей. В данной работе, представленной под названием ‘Xray-Visual Models: Scaling Vision models on Industry Scale Data’, предлагается архитектура Xray-Visual — унифицированная модель для анализа изображений и видео, обученная на масштабных данных социальных сетей. Модель демонстрирует передовые результаты на различных бенчмарках, благодаря трехэтапной стратегии обучения и инновационной архитектуре, основанной на Vision Transformer с эффективной реорганизацией токенов. Сможет ли Xray-Visual стать основой для создания новых, более эффективных и масштабируемых систем мультимодального анализа в реальных условиях?
Визуальные Трансформеры и Самообучение: Новые Горизонты
Архитектура Vision Transformer (ViT) произвела революцию в обработке изображений, предложив альтернативу сверточным нейронным сетям. Однако, для достижения высокой производительности, ViT требует предварительного обучения на огромных наборах данных, что связано со значительными вычислительными затратами и необходимостью сбора и аннотации больших объемов информации. В отличие от сверточных сетей, которые могут эффективно обучаться на относительно небольших датасетах благодаря локальным связям, ViT полагается на механизм внимания, требующий более глобального понимания визуальных закономерностей, что возможно только при наличии достаточного количества обучающих примеров. Этот факт делает предварительное обучение критически важным этапом для успешного применения ViT в различных задачах компьютерного зрения, но одновременно создает определенные трудности в контексте ограниченных ресурсов и доступности данных.
Самообучающееся обучение, в особенности контрастивные методы, такие как SimCLR и MAE, представляет собой эффективное решение проблемы нехватки размеченных данных для обучения моделей компьютерного зрения. Вместо использования ручной разметки, эти подходы позволяют моделям самостоятельно извлекать полезные признаки из неразмеченных изображений, анализируя сходства и различия между различными представлениями одного и того же изображения. Благодаря этому, модели способны формировать устойчивые и обобщенные визуальные представления, которые могут быть успешно использованы в различных задачах, таких как классификация, обнаружение объектов и сегментация, даже при ограниченном количестве размеченных данных. Такой подход позволяет значительно расширить возможности применения моделей компьютерного зрения в ситуациях, когда получение большого объема размеченных данных является сложной или дорогостоящей задачей.
В основе современных методов самообучения визуальных представлений лежит принцип выявления сходств и различий между признаками изображений. Алгоритмы, такие как SimCLR и MAE, строят векторные представления, где близкие изображения оказываются в непосредственной близости друг от друга в многомерном пространстве, а отдаленные — далеко. Для повышения эффективности этого процесса активно применяются методы, основанные на подавлении шума — Denoising Loss. Суть заключается в том, что модель обучается восстанавливать исходное изображение из его зашумленной версии, что заставляет её выделять наиболее значимые и устойчивые признаки, игнорируя случайные помехи. Это не только улучшает качество полученных представлений, но и делает модель более робастной к различным искажениям и изменениям в изображениях, повышая её способность к обобщению и адаптации к новым данным.
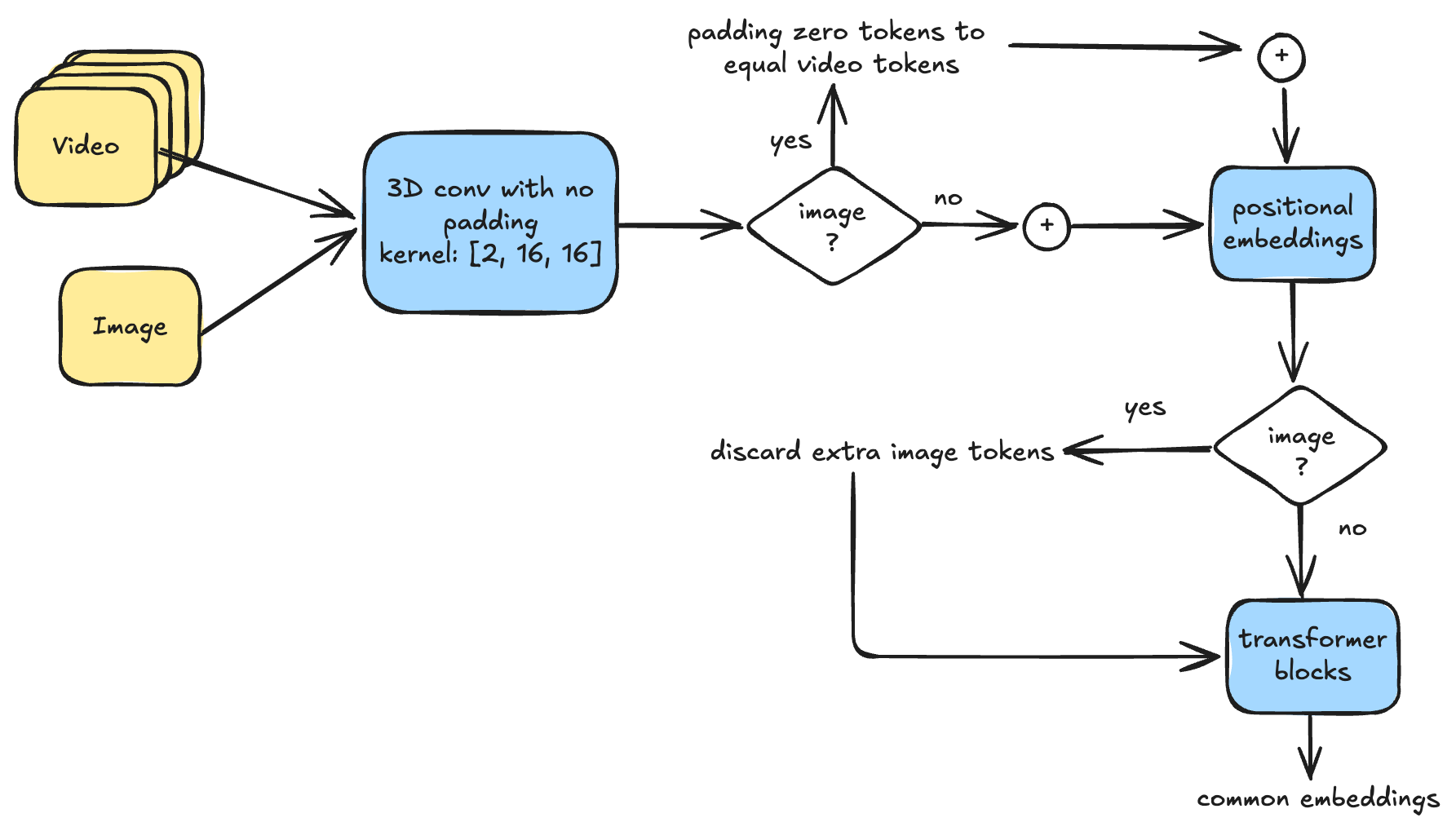
Согласование Визуального и Текстового: Новый Взгляд
CLIP (Contrastive Language-Image Pre-training) использует метод контрастного обучения для создания согласованных векторных представлений изображений и текста. Этот подход позволяет сопоставлять визуальные и текстовые данные в едином многомерном пространстве, где семантически близкие изображения и текстовые описания располагаются ближе друг к другу. В результате, модель способна выполнять классификацию изображений по новым категориям, не требуя предварительного обучения на этих категориях — то есть, демонстрирует возможность переноса обучения в режиме zero-shot. Эффективность достигается за счет обучения на больших объемах данных, где модель учится сопоставлять изображения с соответствующими текстовыми описаниями, формируя общее понимание визуальных концепций.
Согласование визуальных и текстовых представлений в CLIP достигается посредством обучения на масштабных наборах данных, таких как ImageNet и MSCOCO. Эти наборы данных содержат миллионы изображений, аннотированных текстовыми описаниями, что позволяет модели установить соответствие между визуальными особенностями и их лингвистическими эквивалентами. В процессе обучения модель учится представлять изображения и текст в общем векторном пространстве, где близкие векторы соответствуют визуальным и текстовым описаниям, обозначающим схожие концепции. Благодаря этому, CLIP приобретает способность понимать взаимосвязь между визуальными объектами и их названиями, что является основой для выполнения задач переноса обучения без необходимости дополнительной тонкой настройки.
Использование мощной языковой модели, такой как LLaMA, в качестве текстового кодировщика является критически важным для достижения точного и нюансированного представления текста в системе CLIP. LLaMA обеспечивает более глубокое семантическое понимание текстовых описаний, что позволяет эффективно сопоставлять их с визуальными данными. Способность модели LLaMA улавливать тонкие различия в значениях слов и фраз значительно повышает точность классификации изображений, особенно в задачах, требующих распознавания сложных сцен или объектов. В отличие от более простых моделей, LLaMA способна генерировать контекстуально-зависимые векторные представления текста, что позволяет CLIP более эффективно извлекать релевантную информацию из текстовых запросов.
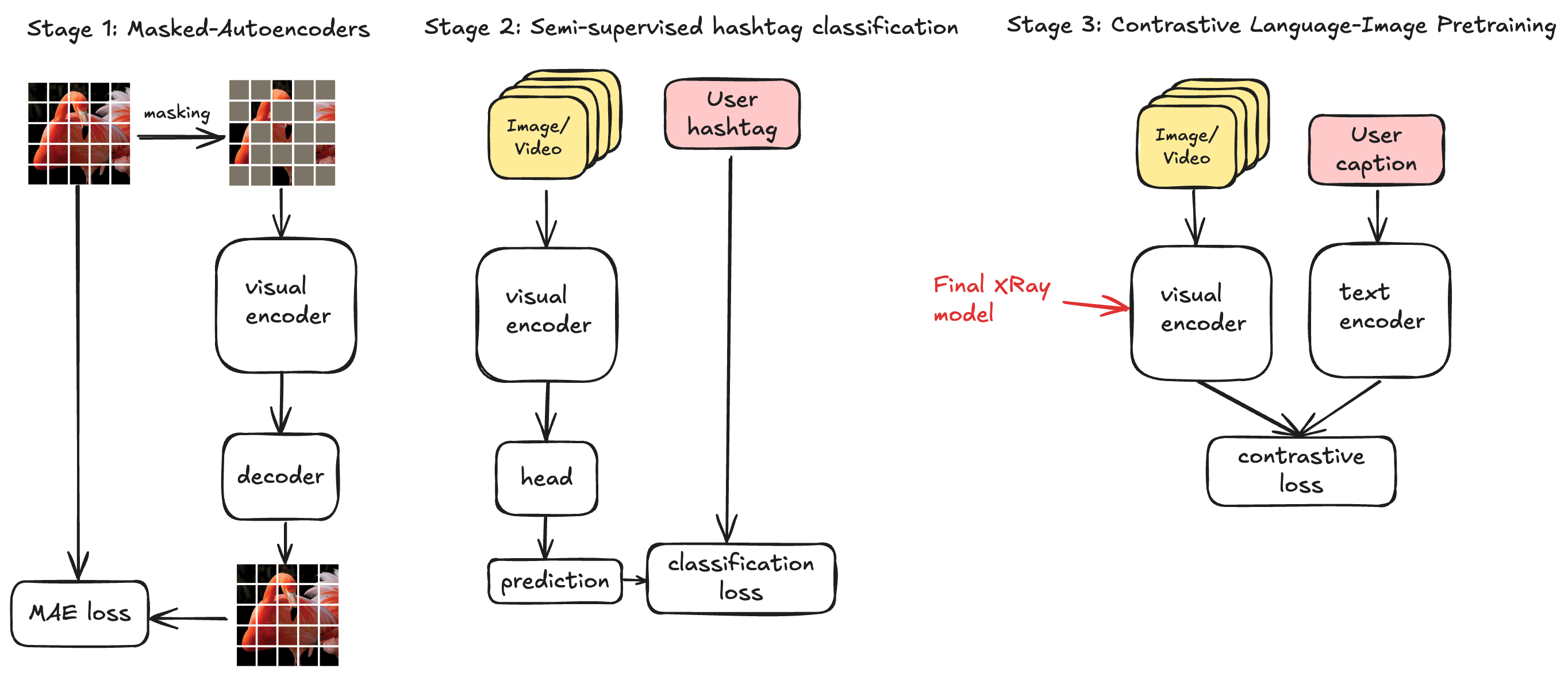
Масштабирование Мультимодального Обучения: Подтверждение Эффективности
Обучение модели CLIP на крупномасштабных, реальных наборах данных, таких как ViSE и URV Dataset, демонстрирует значительное повышение производительности в различных задачах, связанных с визуально-текстовым анализом. В отличие от традиционных эталонных наборов, ViSE и URV Dataset, собранные из социальных медиа, обеспечивают более широкое и репрезентативное представление визуального контента, что позволяет моделям лучше обобщать и адаптироваться к новым, ранее не встречавшимся данным. Это приводит к улучшению результатов в задачах извлечения информации и классификации, подтвержденному достижением точности ImageNet Top-1 в 89.3% и Kinetics Top-1 в 78.1%.
Наборы данных, собранные с социальных медиа-платформ, обеспечивают более широкий и репрезентативный охват визуального контента по сравнению с традиционными эталонными наборами. Это обусловлено тем, что социальные сети отражают разнообразие реального мира, включая различные стили съемки, условия освещения, объекты и сцены, которые редко встречаются в контролируемых лабораторных условиях или специализированных наборах данных. В отличие от тщательно отобранных изображений в традиционных бенчмарках, данные из социальных сетей представляют собой более естественную и непредвзятую выборку, что позволяет моделям лучше обобщать и адаптироваться к реальным условиям. Большой объем данных, доступный на социальных платформах, также способствует повышению надежности и устойчивости моделей, обученных на этих данных.
Обученные модели демонстрируют выдающиеся результаты в задачах zero-shot обучения и обобщения на различных сценариях поиска и классификации. В частности, достигнута рекордная точность Top-1 на датасете ImageNet, составившая 89.3%, и точность Top-1 на датасете Kinetics, равная 78.1%. Эти показатели подтверждают способность моделей эффективно адаптироваться к новым, ранее не встречавшимся данным и решать широкий спектр задач без дополнительной настройки.
Для валидации производительности моделей на проприетарных и специализированных наборах данных используются внутренние метрики поиска. Результаты показали улучшение на 2% по сравнению с моделью PE-L и значительное увеличение точности на 10.8% в задаче поиска релевантной рекламы для Reels (коротких видеороликов). Эти показатели демонстрируют эффективность новых подходов к обучению в контексте конкретных бизнес-задач и внутренних данных компании.
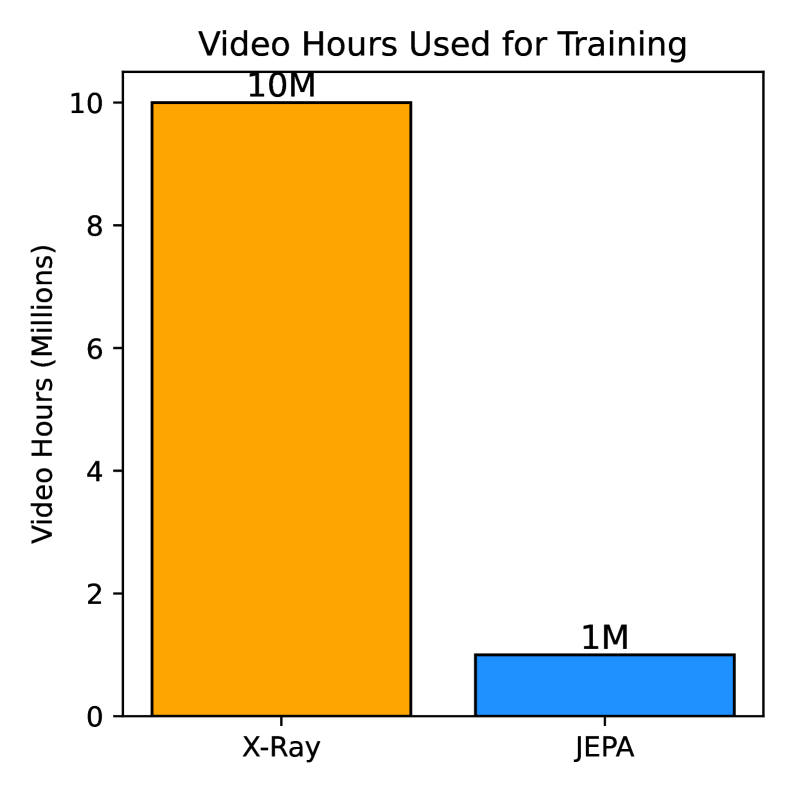
Эффективные Архитектуры и Стратегии Обучения: Новые Возможности
Архитектура EViT, развиваясь на основе Vision Transformer (ViT), вносит значительные улучшения в вычислительную эффективность без потери качества обработки изображений. В отличие от стандартного ViT, EViT перестраивает последовательность токенов и отбрасывает те, которые демонстрируют низкую значимость для анализа — так называемые “невнимательные” токены. Этот процесс оптимизации позволяет значительно сократить объем вычислений, необходимых для обработки каждого изображения, что особенно важно при работе с большими объемами данных и ограниченными вычислительными ресурсами. В результате, модель сохраняет высокую точность, но требует существенно меньше вычислительной мощности, открывая возможности для более быстрого обучения и развертывания на различных платформах.
В архитектуре EViT особое внимание уделяется повышению устойчивости модели к нетипичным данным и шуму. Для этого в последовательность токенов, обрабатываемую трансформером, добавляются специальные “регистры” — дополнительные токены, которые служат своеобразными “ловушками” для аномальных признаков. Эти регистры не несут информации о самом изображении, но эффективно захватывают выбросы и редкие паттерны, которые могли бы нарушить работу основной части модели. Таким образом, регистры позволяют EViT более надежно обрабатывать изображения с артефактами или в сложных условиях, обеспечивая повышенную робастность и точность распознавания.
Для оптимизации процесса обучения и снижения вычислительных затрат используется подход прогрессивного разрешения и объединения токенов. Суть заключается в постепенном увеличении разрешения входных изображений в ходе обучения, начиная с низкого разрешения и последовательно переходя к более высоким. Одновременно с этим, происходит объединение токенов — соседние токены, представляющие схожие признаки, объединяются в один, что уменьшает длину последовательности и, следовательно, вычислительную сложность. Такая стратегия позволяет модели сначала освоить общие признаки на низком разрешении, а затем уточнять детали на более высоких разрешениях, значительно ускоряя сходимость и снижая потребность в вычислительных ресурсах, что особенно важно при работе с большими объемами данных и сложными задачами визуального анализа.
Внедрение предложенных архитектурных и тренировочных стратегий позволило значительно расширить возможности обучения на масштабных наборах данных и достичь передовых результатов в задачах, требующих сложного визуального анализа. Достигнутое четырехкратное увеличение вычислительной эффективности по сравнению с существующими моделями открывает новые перспективы для обработки изображений. В частности, модель продемонстрировала впечатляющую точность в 89.1% при линейном зондировании на датасете ImageNet, причем это достигнуто без использования каких-либо дополнительных методов аугментации данных, что подчеркивает ее высокую производительность и устойчивость.
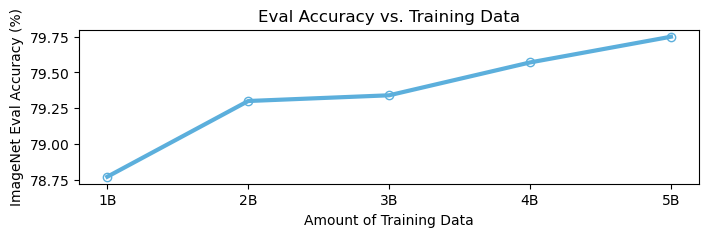
Исследование, представленное в данной работе, демонстрирует значительный прогресс в области vision-language моделей, а именно, в повышении эффективности использования данных благодаря инновационной трехэтапной схеме обучения. Этот подход, как и любая сложная система, требует глубокого понимания внутренних закономерностей. Как однажды заметил Джеффри Хинтон: «Иногда лучший способ узнать, как работает система, — это попытаться её сломать.» Данное утверждение перекликается с методом, используемым в XrayVisual, где тщательный анализ и оптимизация архитектуры позволили добиться значительных результатов, особенно в контексте обучения на масштабных социальных медиа данных. Понимание принципов контрастивного обучения и самообучения, реализованных в модели, раскрывает возможности для дальнейшего развития в данной области.
Что дальше?
Представленная работа, демонстрируя возможности масштабирования моделей компьютерного зрения на данных из социальных сетей, неизбежно ставит вопрос о границах применимости подобных подходов. Успех, достигнутый благодаря трехстадийному процессу обучения и архитектурным улучшениям, не отменяет необходимости критической оценки качества и предвзятости исходных данных. Необходимо внимательно проверять границы данных, чтобы избежать ложных закономерностей и не укоренять существующие социальные предубеждения в алгоритмах. Иначе, мы рискуем получить не инструменты понимания мира, а его искажённое отражение.
Перспективы дальнейших исследований лежат в плоскости повышения устойчивости моделей к шуму и неполноте данных, а также в разработке методов интерпретации принимаемых ими решений. Достаточно ли контрастивного обучения для создания действительно «понимающих» моделей, или необходимы принципиально новые подходы, имитирующие когнитивные процессы? Интересно, как подобные модели будут вести себя в условиях, существенно отличающихся от тех, на которых они обучались — в условиях, где визуальная информация ограничена или искажена.
В конечном счёте, масштаб не является самоцелью. Понимание системы — это исследование её закономерностей, а не просто накопление данных. Будущие исследования должны быть направлены на поиск этих закономерностей, на создание моделей, способных не только распознавать объекты, но и понимать их взаимосвязи и контекст. Иначе, все усилия по масштабированию окажутся бессмысленными.
Оригинал статьи: https://arxiv.org/pdf/2602.16918.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Квантовые ограничения в хаотичных сплавах: взгляд на Si/SiGe/Si
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Квантовое моделирование: от проблемных решений к универсальному программному обеспечению
2026-02-21 21:28