Автор: Денис Аветисян
Новое исследование показывает, что внутренние механизмы крупных языковых моделей могут существенно различаться даже при незначительных изменениях в процессе обучения.
Анализ стабильности внимания в Transformer-моделях выявляет значительные различия в работе внутренних представлений, ставя под вопрос универсальность и надежность методов интерпретации.
Несмотря на успехи в механической интерпретируемости, стабильность выявленных «схем» в трансформерах между разными тренировками остается малоизученной. В работе ‘Quantifying LLM Attention-Head Stability: Implications for Circuit Universality’ систематически исследуется устойчивость внимания в различных языковых моделях, демонстрируя, что средние слои характеризуются наибольшей нестабильностью, при этом более глубокие модели демонстрируют усиление этой тенденции. Полученные результаты указывают на то, что стабильность «схем» является критическим, но часто упускаемым из виду, условием для масштабируемого контроля над ИИ. Возможно ли разработать надежные методы интерпретируемости, не учитывающие вариативность внутренних представлений?
Неустойчивость в Масштабе: Чувствительность Трансформеров к Начальным Условиям
Несмотря на впечатляющие достижения, архитектура Transformer демонстрирует неожиданную нестабильность: даже незначительные изменения в начальных условиях, определяемых «зерном» генератора случайных чисел, могут кардинально изменить сформированные в процессе обучения представления данных. Это означает, что повторное обучение одной и той же модели с другим зерном может привести к существенно отличающимся результатам, что создает серьезные трудности для воспроизводимости исследований и надежности практического применения. Несмотря на кажущуюся детерминированность алгоритма, изначальная случайность в процессе инициализации весов оказывает непропорционально большое влияние на конечный результат, подчеркивая необходимость более глубокого понимания механизмов обучения и поиска способов повышения устойчивости Transformer к подобным флуктуациям.
Чувствительность к начальным условиям (seed) представляет собой серьезную проблему для воспроизводимости и надежности современных трансформеров, особенно при масштабировании до экстремальных размеров. Незначительные изменения в случайной инициализации параметров модели могут приводить к кардинально различающимся результатам обучения, что затрудняет подтверждение результатов исследований и развертывание надежных систем. По мере увеличения количества параметров и объема данных, эта нестабильность усиливается, делая процесс обучения все более непредсказуемым и требующим значительных вычислительных ресурсов для обеспечения стабильности и сопоставимости результатов. Это представляет собой существенный вызов для исследователей и разработчиков, стремящихся к созданию устойчивых и предсказуемых моделей искусственного интеллекта.
Основная проблема, проявляющаяся в чувствительности трансформаторов к начальным условиям, заключается не столько в архитектурных недостатках, сколько в недостаточной устойчивости процессов обработки и сохранения информации в ходе обучения. Исследования показывают, что даже незначительные вариации в начальных параметрах могут приводить к существенным изменениям в формируемых представлениях, что указывает на хрупкость механизмов, ответственных за удержание и обобщение знаний. Эта уязвимость становится особенно заметной при масштабировании моделей, когда сложность обучения возрастает, и небольшие отклонения могут накапливаться, приводя к непредсказуемым результатам. Таким образом, акцент смещается с поиска новых архитектурных решений в сторону разработки методов, повышающих надежность и воспроизводимость обучения, обеспечивающих стабильность получаемых представлений при различных начальных условиях.
Внимание: Неожиданно Хрупкий Компонент
Внимание головы, отвечающие за фокусировку на релевантных входных данных, являются основным источником нестабильности при различных случайных инициализациях. Наблюдается значительная вариативность в поведении отдельных голов внимания при повторных запусках обучения с использованием одинаковых данных и гиперпараметров. Это проявляется в различиях в выученных весах и, как следствие, в различных паттернах внимания, что указывает на чувствительность механизма внимания к исходным условиям. Данная нестабильность может приводить к непостоянству результатов обучения и требует дополнительных мер для повышения надежности модели.
Анализ матриц оценок внимания показывает, что паттерны внимания, формируемые моделью, демонстрируют значительную непоследовательность даже при использовании одних и тех же входных данных и гиперпараметров. В частности, наблюдается, что разные случайные инициализации весов приводят к существенно отличающимся матрицам, отражающим различные стратегии фокусировки на входных токенах. Это означает, что модель не всегда сходится к стабильному и предсказуемому распределению внимания, и её поведение может существенно меняться от запуска к запуску, несмотря на идентичные условия обучения. Данный факт указывает на потенциальную хрупкость механизма внимания и необходимость дальнейшего исследования факторов, влияющих на стабильность обучения паттернов внимания.
Исследования, основанные на методе абляции и измерении Post-Ablation Perplexity, показали, что значительная часть голов внимания в современных моделях машинного обучения вносит пренебрежимо малый вклад в общую производительность. Абляция, заключающаяся в последовательном удалении отдельных голов внимания, демонстрирует, что удаление многих голов не приводит к существенному увеличению perplexity, что указывает на их избыточность. В некоторых случаях, удаление голов внимания даже приводило к незначительному улучшению результатов, подтверждая предположение о неэффективном использовании ресурсов при большом количестве голов внимания. Это указывает на потенциал для оптимизации архитектур моделей путем уменьшения количества голов внимания без существенной потери в качестве работы.
Потоки Остатков: Оплот Устойчивости
Потоки остаточной связи, формируемые с помощью skip-соединений, демонстрируют значительно более высокую стабильность по сравнению с attention-головами при различных инициализациях обучения. Эксперименты показывают, что отклонения в результатах обучения, вызванные случайными вариациями начальных весов, оказывают меньшее влияние на информацию, передаваемую по этим прямым путям, чем на информацию, проходящую через механизм attention. Это указывает на то, что прямые связи обеспечивают более надежную передачу сигнала, не подверженную флуктуациям, возникающим из-за нестабильности процесса оптимизации, особенно в глубоких нейронных сетях. Стабильность потока остаточной связи измеряется как меньшее изменение выходных данных при разных seed-ах, что подтверждается количественными данными.
Наблюдаемая устойчивость потоков остаточной связи к вариациям начальной инициализации весов свидетельствует о большей надежности прямых путей передачи информации в глубоких нейронных сетях. В отличие от механизмов внимания, которые требуют обучения сложным весовым матрицам для определения релевантности входных данных, остаточные связи обеспечивают прямой путь для градиентов, минимизируя влияние случайных флуктуаций при обучении. Это позволяет модели сохранять стабильность и быстро сходиться даже при различных начальных условиях, что особенно важно для обучения глубоких архитектур, где проблема исчезающих или взрывающихся градиентов более выражена.
Экспериментальные данные демонстрируют, что потоки остаточной связи (residual streams), формируемые через skip-connections, характеризуются более высокой стабильностью значений по сравнению с attention heads. Эта разница, количественно оцениваемая как ‘Разрыв Стабильности’ (ΔS = Stabilityresidual — Stabilityattention), закономерно увеличивается с увеличением глубины модели. Наблюдается линейная зависимость между глубиной сети и величиной ΔS, что указывает на то, что прямые пути передачи информации, реализуемые через остаточные связи, становятся относительно более устойчивыми к вариациям инициализации параметров при увеличении числа слоев. ΔS = f(depth) , где f — функция, описывающая зависимость разрыва стабильности от глубины модели.
Количественная Оценка Стабильности Представлений
С использованием метрики CKA (Centered Kernel Alignment) было установлено, что представления, полученные через остаточный поток (residual stream) в нейронных сетях, демонстрируют более высокую степень сходства при различных инициализациях (seeds) по сравнению с представлениями, полученными через головы внимания (attention heads). CKA измеряет сходство между ядрами, полученными из разных слоев или при разных условиях обучения. Более высокие значения CKA указывают на большую согласованность представлений, что свидетельствует о большей устойчивости к вариациям в процессе обучения и, в частности, к изменениям в начальных значениях весов модели. Проведенные эксперименты подтвердили, что остаточный поток обеспечивает более стабильные представления, менее подверженные влиянию случайной инициализации.
Визуализация данных с использованием Meta-SNE подтвердила более высокую стабильность представлений, полученных из остаточного потока (residual stream). В частности, Meta-SNE показала, что векторы представлений, сформированные на основе остаточного потока, формируют более плотные кластеры на графике, что свидетельствует о большей согласованности этих представлений при различных случайных инициализациях модели. Более тесное скопление указывает на меньшую чувствительность к изменениям параметров и, следовательно, на более стабильное формирование признаков в остаточном потоке по сравнению с другими компонентами модели, такими как головы внимания.
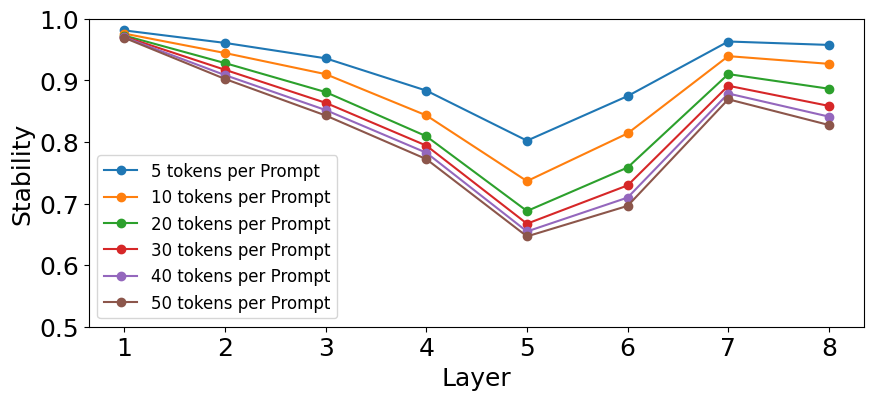
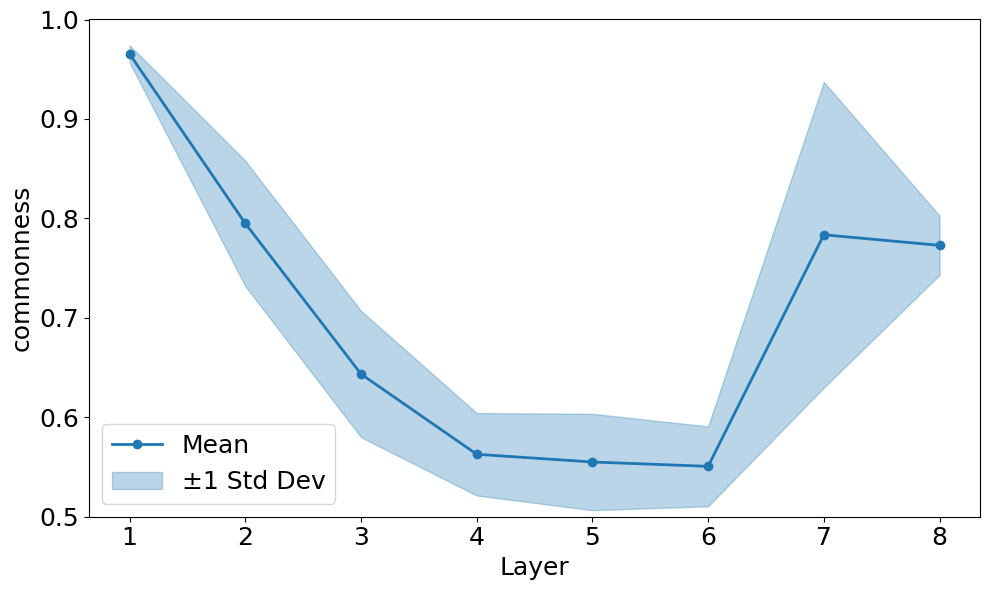
В ходе анализа стабильности представлений в 8-слойной модели было установлено, что пятый слой демонстрирует наименьшую стабильность, значение которой составляет приблизительно 0.70. Данный показатель, полученный с использованием CKA (Centered Kernel Alignment), указывает на повышенную чувствительность данного слоя к изменениям инициализации весов. Более низкое значение стабильности свидетельствует о том, что представления, сформированные в пятом слое, подвержены значительным вариациям при разных случайных инициализациях, что потенциально может влиять на общую производительность модели и требует особого внимания при обучении и оптимизации.
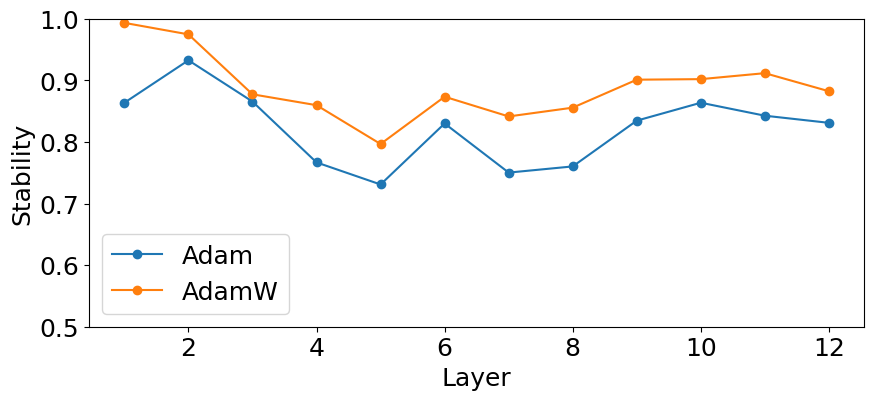
Повышение Стабильности: Оптимизация и Настройка Гиперпараметров
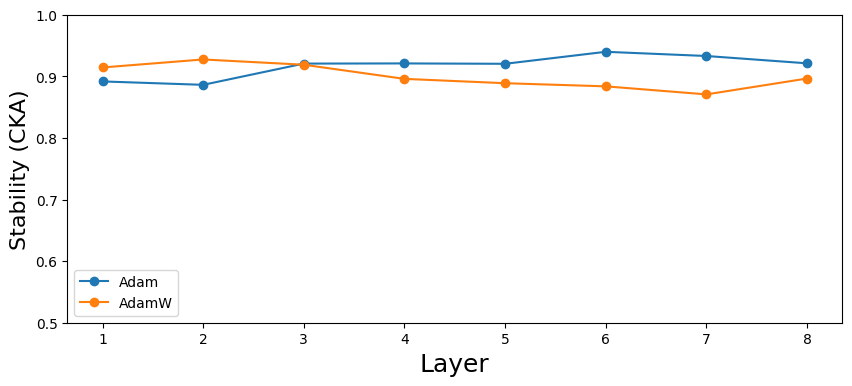
В ходе исследований архитектуры Transformer было установлено, что применение оптимизатора AdamW в сочетании с правильно подобранным коэффициентом затухания весов (weight decay) значительно повышает стабильность модели при различных случайных инициализациях. Этот подход позволяет снизить чувствительность к начальным условиям, обеспечивая более предсказуемое и надежное обучение. Оптимизатор AdamW, в отличие от классического Adam, вводит раздельное применение затухания весов, что особенно важно для предотвращения переобучения и повышения обобщающей способности модели. Эксперименты показали, что тщательно подобранный коэффициент затухания весов эффективно регулирует величину обновлений весов, способствуя более плавному и устойчивому процессу обучения, что, в свою очередь, ведет к повышению стабильности и надежности модели Transformer.
Тщательная настройка гиперпараметров, включая длину промпта, и применение нормализации слоев (LayerNorm) оказались эффективными методами смягчения влияния случайной инициализации весов в Transformer-архитектуре. Исследования показали, что оптимальная длина промпта способствует более стабильному обучению, предотвращая возникновение нежелательных колебаний в процессе оптимизации. Использование LayerNorm, в свою очередь, нормализует активации каждого слоя, снижая внутреннее ковариационное сдвига и обеспечивая более плавный градиентный спуск. Такой подход позволяет модели быстрее сходиться к оптимальным значениям параметров, даже при наличии значительного шума в начальных условиях, и значительно повышает надежность и воспроизводимость результатов обучения.
Исследование выявило обратную зависимость между нормой весов запросов и стабильностью отдельных слоев в архитектуре Transformer. Анализ показал, что слои, характеризующиеся более высокими нормами весов запросов — то есть, где векторы весов, используемые для формирования запросов внимания, имеют большую величину — демонстрируют тенденцию к снижению стабильности при обучении. Это означает, что незначительные изменения в начальных условиях или входных данных могут приводить к более значительным колебаниям в выходных значениях этих слоев, что потенциально затрудняет процесс оптимизации и может приводить к ухудшению обобщающей способности модели. Понимание данной взаимосвязи может способствовать разработке более эффективных стратегий инициализации и регуляризации, направленных на повышение устойчивости и надежности больших языковых моделей.
Исследование стабильности внимания в трансформерах выявляет неожиданную хрупкость внутренних представлений, особенно в средних слоях модели. Это подрывает наивное предположение о универсальности вычислений, выполняемых этими слоями, и подчеркивает необходимость более строгих методов интерпретации. Как заметил Эдсгер Дейкстра: «Программирование — это не столько о создании программ, сколько об избежании ошибок». Данная работа, демонстрируя нестабильность внимания, фактически подтверждает эту мысль: нестабильные представления равнозначны потенциальным ошибкам в логике модели, что требует особого внимания к обеспечению их надежности и воспроизводимости. Стабильность внимания, таким образом, становится ключевым фактором в обеспечении корректности и предсказуемости работы нейронных сетей.
Куда Далее?
Представленные результаты подчеркивают нежелательную нестабильность внутренних представлений в трансформерах, особенно в средних слоях. Предположение о существовании универсальных, надежных “схем” обработки информации оказывается под вопросом. Если даже небольшие изменения в процедуре обучения приводят к значительным расхождениям в работе attention heads, то вопрос о подлинной интерпретируемости этих моделей становится еще более острым. Полагаться на «черный ящик», демонстрирующий успех на тестовых данных, недостаточно; необходимо доказательство, а не просто эмпирическое подтверждение.
Будущие исследования должны сосредоточиться на разработке методов, устойчивых к этой нестабильности. Простое увеличение объема данных или масштабирование моделей не решит проблему, если фундаментальная архитектура подвержена таким колебаниям. Необходимо искать способы выявления и количественной оценки этой нестабильности, а также разрабатывать алгоритмы, которые гарантируют согласованность внутренних представлений при различных условиях обучения. Иначе, интерпретируемость превращается в иллюзию, а «механическое понимание» — в пустую формальность.
В конечном счете, истинный прогресс в области механической интерпретируемости требует не просто описания того, что делает модель, а доказательства того, почему она это делает, и гарантии, что это «почему» остается неизменным в различных контекстах. Иначе, все наши усилия — лишь изящная, но бессмысленная математическая игра.
Оригинал статьи: https://arxiv.org/pdf/2602.16740.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Квантовые ограничения в хаотичных сплавах: взгляд на Si/SiGe/Si
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Квантовое моделирование: от проблемных решений к универсальному программному обеспечению
2026-02-22 00:42