Автор: Денис Аветисян
Новое исследование показывает, что внутренние механизмы современных нейросетей отражают иерархию когнитивных навыков, аналогичную человеческому пониманию сложности.
Механическая интерпретируемость больших языковых моделей посредством линейного зондирования и классификации когнитивных уровней по таксономии Блума.
Непрозрачность работы больших языковых моделей (LLM) затрудняет понимание принципов формирования ответов и оценки их когнитивных способностей. В данной работе, ‘Mechanistic Interpretability of Cognitive Complexity in LLMs via Linear Probing using Bloom’s Taxonomy’, исследуется, как LLM внутренне представляют когнитивную сложность, используя таксономию Блума в качестве иерархической модели. Полученные результаты демонстрируют, что различные когнитивные уровни, от простого воспроизведения до абстрактного синтеза, линейно различимы в скрытых представлениях модели, причем разделение уровней происходит на ранних этапах обработки. Возможно ли, что подобная организация внутренних представлений отражает универсальные принципы когнитивной архитектуры, общие для человека и искусственного интеллекта?
За пределами подсчёта слов: Ограничения традиционного семантического анализа
Современные семантические методы, такие как TF-IDF и Sentence Embeddings, зачастую оказываются неспособны уловить тонкости когнитивной сложности языка. Эти подходы, хоть и эффективны в определении частотности слов или построении векторных представлений предложений, рассматривают все семантические элементы как равнозначные, игнорируя иерархическую структуру понимания. В результате, модели могут обрабатывать текст, но испытывают затруднения в выполнении задач, требующих истинного рассуждения или решения проблем, поскольку не учитывают контекстуальные связи и сложные взаимоотношения между понятиями, присущие человеческому мышлению. Это приводит к упрощенному восприятию информации и, как следствие, к неточностям в интерпретации смысла, особенно в случаях, когда текст содержит метафоры, иронию или требует глубокого понимания предметной области.
Традиционные методы семантического анализа, такие как TF-IDF и модели эмбеддингов предложений, зачастую рассматривают всю семантическую информацию как равнозначную, упуская из виду иерархическую структуру понимания. В действительности, человеческий мозг не обрабатывает все слова и понятия одинаково; более важные элементы, определяющие смысл, выделяются и структурируются в сложные взаимосвязи. Этот подход, игнорирующий уровни абстракции и значимости, приводит к тому, что модели машинного обучения, хотя и способны обрабатывать языковые данные, испытывают трудности с глубоким осмыслением и решением задач, требующих логического вывода и понимания контекста. Фактически, одинаковое взвешивание всех семантических компонентов препятствует построению полноценной модели знаний, отражающей сложность человеческого мышления.
Несмотря на впечатляющие успехи в обработке естественного языка, современные модели зачастую демонстрируют ограниченные возможности в области логического мышления и решения проблем. Способность анализировать синтаксис и семантику текста, хотя и необходима, не гарантирует понимания глубинных связей и причинно-следственных отношений. Модели, основанные на статистических методах, таких как TF-IDF или векторные представления предложений, могут успешно распознавать паттерны в данных, но им не хватает способности к абстрактному мышлению и построению логических выводов, что препятствует эффективному решению задач, требующих анализа, синтеза и критической оценки информации. В результате, они могут генерировать грамматически правильные и семантически связанные тексты, не обладая при этом истинным пониманием их содержания и контекста.
Таксономия Блума как инструмент анализа больших языковых моделей
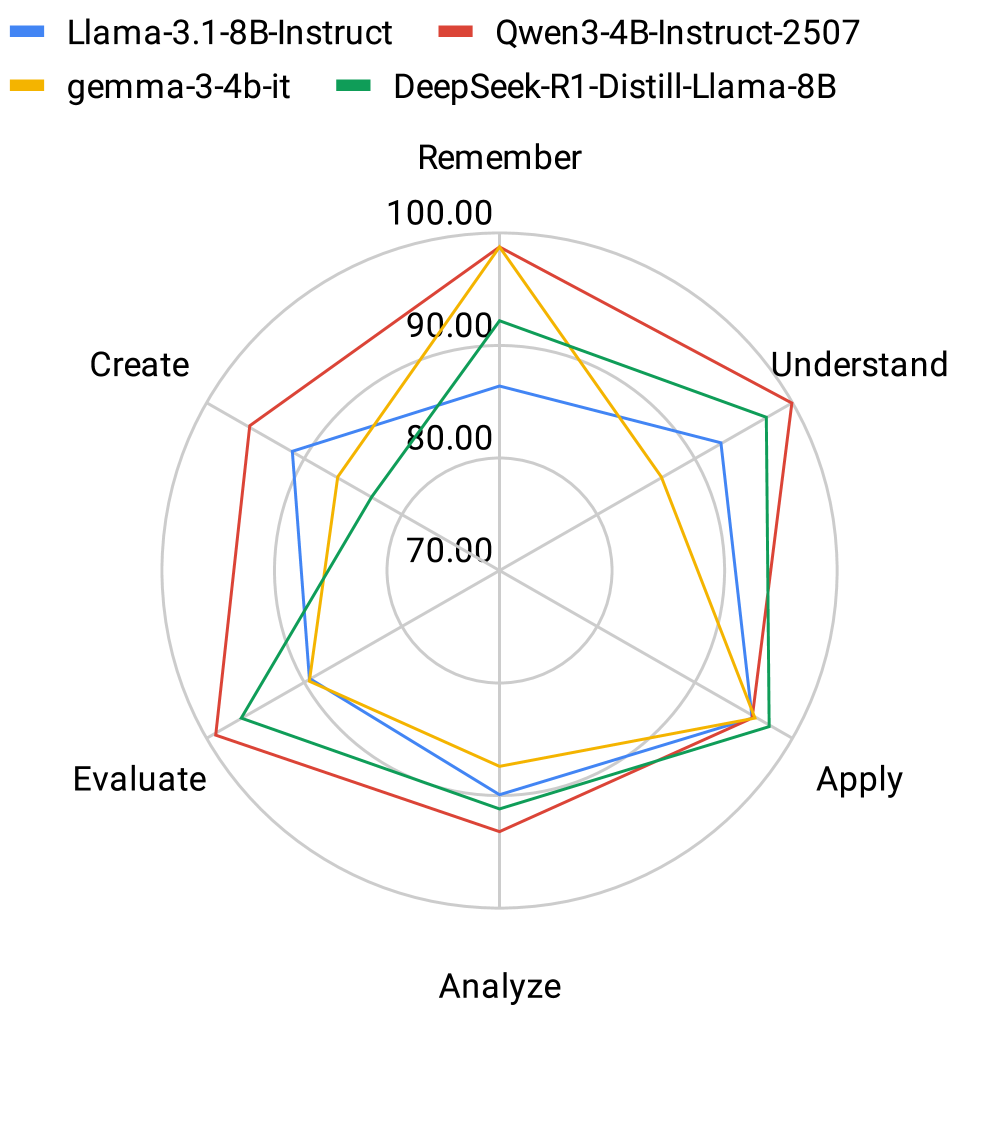
Таксономия Блума представляет собой иерархическую систему классификации когнитивных навыков, включающую шесть основных уровней: запоминание (знание фактов), понимание (интерпретация информации), применение (использование информации в новых ситуациях), анализ (разбиение информации на составные части и выявление закономерностей), синтез (создание нового целого из отдельных частей) и оценка (обоснование решений или идей на основе критериев). Данная таксономия, изначально разработанная для целей образования, позволяет структурировать и классифицировать различные уровни интеллектуальной деятельности, от простого воспроизведения информации до сложных процессов творческого мышления и критического анализа. Каждый уровень предполагает определенный набор навыков и требует различных когнитивных ресурсов, что делает таксономию Блума полезным инструментом для оценки и развития интеллектуальных способностей.
Применение таксономии Блума к большим языковым моделям (LLM) позволяет оценить, насколько адекватно эти модели демонстрируют различные уровни когнитивных способностей. Анализ выходных данных LLM и внутренних представлений, сопоставленный с категориями таксономии (знание, понимание, применение, анализ, синтез, оценка), позволяет выявить, на каких уровнях модель функционирует эффективно, а где наблюдаются ограничения. Оценка проводится путём предъявления модели задач, требующих различных когнитивных навыков, и последующего анализа её ответов на соответствие ожидаемому уровню сложности, определённому таксономией. Это позволяет не только оценить текущие возможности LLM, но и определить направления для дальнейшего улучшения и разработки более интеллектуальных систем.
Предполагается, что внутренние активации в сетях Transformer демонстрируют закономерности, соответствующие различным уровням когнитивных способностей, описанным в таксономии Блума. Анализ этих активаций направлен на выявление корреляций между конкретными слоями или нейронами и процессами, такими как запоминание, понимание, применение, анализ, синтез и оценка. В частности, ожидается, что активации в начальных слоях будут связаны с более простыми когнитивными задачами, такими как извлечение информации, в то время как активации в более глубоких слоях будут отражать более сложные процессы, требующие абстракции, обобщения и критического мышления. Идентификация таких закономерностей позволит оценить, насколько хорошо языковые модели представляют и обрабатывают информацию на различных когнитивных уровнях.
Декодирование когнитивной сложности: Линейное зондирование и остаточные потоки
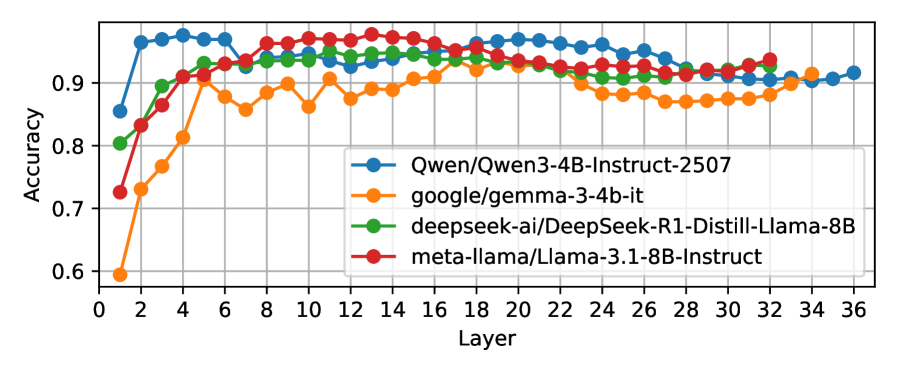
Для определения возможности линейного извлечения информации о таксономии Блума из скрытых состояний Transformer-сети был применен метод линейного зондирования (Linear Probing). Данный подход заключался в обучении линейных классификаторов на основе Residual Stream, извлеченного из каждого слоя сети, для предсказания уровней когнитивной сложности согласно таксономии Блума. Суть метода заключается в проверке гипотезы о том, что информация о когнитивных уровнях закодирована в активациях сети и может быть получена с помощью простой линейной регрессии, без необходимости обучения сложной нелинейной модели. Линейное зондирование позволяет оценить, насколько явно и доступно представлена данная информация в скрытых состояниях.
Для определения наличия информации об уровнях таксономии Блума в скрытых состояниях Transformer-сети использовался метод обучения линейных классификаторов на основе Residual Stream, извлеченного из каждого слоя сети. Residual Stream представляет собой разницу между входными и выходными данными каждого слоя, что позволяет выделить изменения в представлении информации. Обучение линейных классификаторов непосредственно на этих Residual Stream позволяет оценить, насколько линейно декодируемы признаки, соответствующие различным когнитивным уровням. Такой подход позволяет выявить, какие слои сети наиболее эффективно кодируют информацию о сложности когнитивных задач.
Результаты экспериментов показали, что паттерны, соответствующие различным уровням когнитивной сложности согласно таксономии Блума, действительно кодируются в активациях Transformer-сети. Особенно выраженная кодировка наблюдается в более глубоких слоях архитектуры. Линейные классификаторы, обученные на основе Residual Stream, демонстрируют приблизительно 95% точность в определении уровня когнитивной сложности, что указывает на наличие четко различимых представлений различных когнитивных уровней в скрытых состояниях модели.
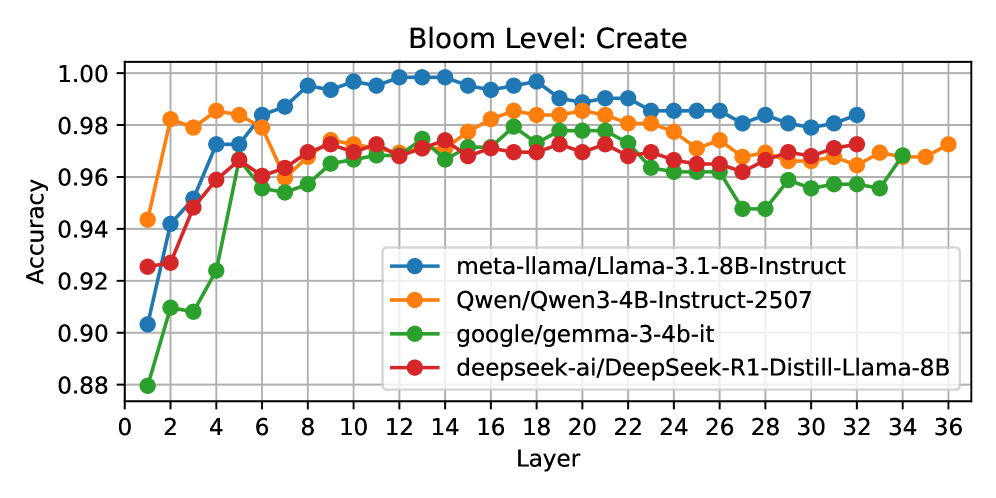
Векторы активации как когнитивные сигнатуры
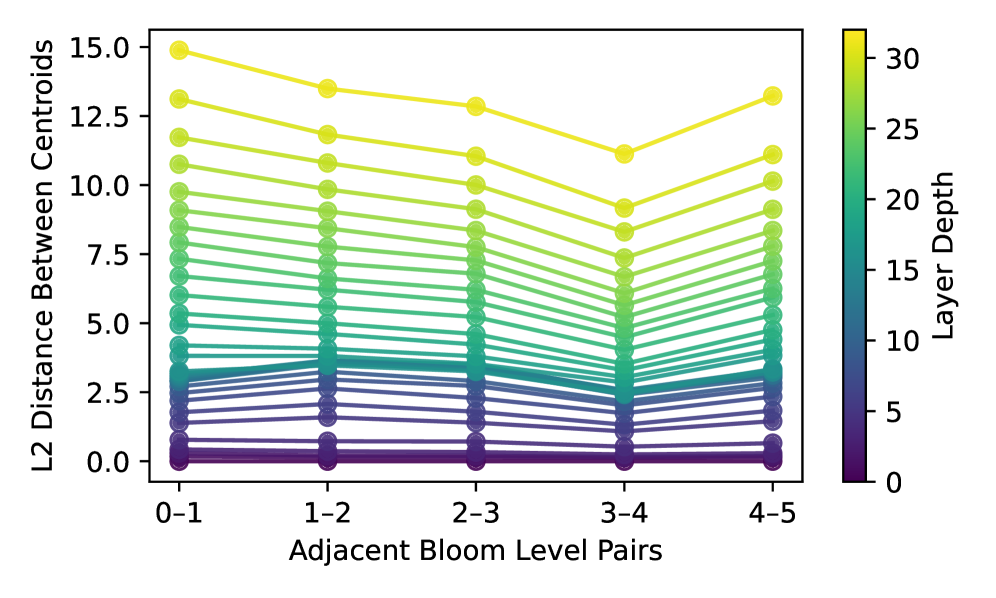
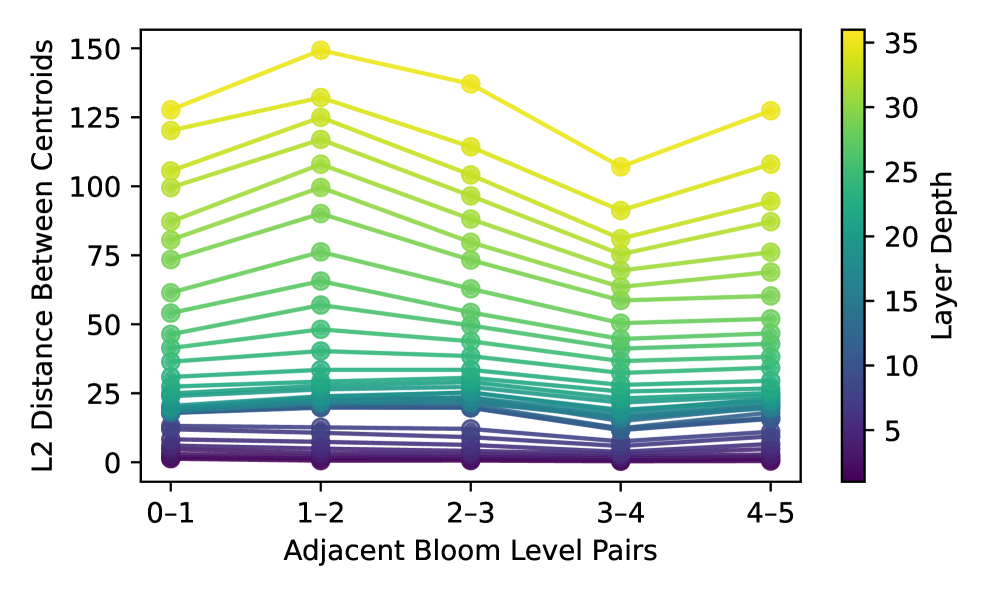
Анализ векторов активации позволил установить соответствие между кодировкой уровней Блума и ожидаемой когнитивной сложностью на различных слоях нейронной сети. Было обнаружено, что поверхностные слои преимущественно отражают базовые когнитивные навыки, такие как запоминание и понимание информации, в то время как более глубокие слои захватывают и обрабатывают навыки высшего порядка, включая анализ, оценку и создание нового знания. Данное соответствие указывает на то, что сеть способна иерархически представлять когнитивные способности, отражая их сложность в структуре своей активации, что подтверждает возможность использования активационных векторов в качестве когнитивных сигнатур.
Исследование активационных векторов нейронных сетей показало чёткую стратификацию когнитивных навыков по глубине слоёв. Более поверхностные слои преимущественно кодируют базовые навыки, такие как запоминание и понимание информации — процессы, требующие минимальной обработки и анализа. В то же время, более глубокие слои сети отвечают за сложные когнитивные функции, включая анализ, оценку и создание нового знания. Этот феномен отражает иерархическую структуру когнитивных способностей, где каждый последующий уровень опирается на результаты предыдущего, позволяя сети выполнять всё более сложные задачи и демонстрировать признаки интеллектуальной деятельности, аналогичные человеческому мышлению.
Анализ ошибок классификации выявил закономерность: неверные предсказания сети чаще всего касались соседних уровней классификации Блума. Среднее расстояние между ожидаемой и фактической классификацией составило приблизительно 1, что свидетельствует о чёткой иерархической организации когнитивных навыков внутри нейронной сети. Это указывает на то, что сеть не просто различает различные типы мышления, но и понимает их относительную сложность, последовательно переходя от более простых навыков к более сложным. Данная особенность демонстрирует способность сети к нюансированному представлению когнитивной иерархии, а не к её упрощенной или хаотичной интерпретации.
Исследование демонстрирует, что большие языковые модели не просто манипулируют символами, но и структурируют информацию, отражая принципы когнитивной сложности, описанные в таксономии Блума. Это подтверждает идею о том, что системы развиваются не линейно, а через последовательность ошибок и коррекций, стремясь к большей зрелости. Как заметил Клод Шеннон: «Информация — это не количество, а возможность выбора». В контексте данной работы, организация внутренних представлений модели по уровням когнитивной сложности — это не просто архитектурный выбор, а способ расширить возможности выбора и, следовательно, увеличить информационную ценность выходных данных. Иными словами, структурирование когнитивной сложности в LLM — это путь к созданию более гибких и адаптивных систем.
Куда же всё это ведёт?
Представленная работа, словно рентгеновский снимок, зафиксировала внутреннюю организацию больших языковых моделей, обнаружив отголоски человеческой педагогической теории в их «мышлении». Однако, само обнаружение лишь углубляет вопрос: не является ли эта упорядоченность артефактом обучения, своеобразной «закладкой» прошлого, которую мы сейчас видим в настоящем? Каждый «баг» в этой картине, каждая неточность — момент истины во временной кривой, сигнализирующий о несоответствии между внутренней логикой модели и внешней интерпретацией.
Очевидно, что дальнейшие исследования должны быть направлены не только на идентификацию когнитивных уровней, но и на понимание динамики их взаимодействия. Как эти уровни формируются во времени? Какова их устойчивость к изменениям в данных или архитектуре модели? Все системы стареют — вопрос лишь в том, делают ли они это достойно. Время — не метрика, а среда, в которой существуют эти системы, и понимание этой среды необходимо для создания действительно «интерпретируемых» моделей.
В конечном итоге, задача механической интерпретируемости — это не просто расшифровка кода, но и философское размышление о природе интеллекта, как искусственного, так и естественного. Поиск соответствий между внутренней организацией модели и человеческим познанием — это, возможно, ложная цель. Более продуктивным представляется исследование уникальных способов, которыми эти модели обрабатывают информацию, даже если они не соответствуют нашим представлениям о «разумности».
Оригинал статьи: https://arxiv.org/pdf/2602.17229.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Неупорядоченные системы с неэрмитовыми эффектами
- Нейросети на резистивной памяти: Новый подход к решению сложных задач
- Квантовое превосходство: взгляд сквозь призму управления
2026-02-22 02:22