Автор: Денис Аветисян
В статье описывается практическая реализация системы автоматического определения кодов ТН ВЭД на основе машинного обучения и бессерверной архитектуры для упрощения процедур международной торговли.
Разработка и внедрение конвейера машинного обучения для автоматической классификации товаров с использованием бессерверной архитектуры и решения проблем дисбаланса данных.
Несмотря на растущую потребность в автоматизации процессов международной торговли, классификация товаров по гармонизированной системе (HS) остается сложной задачей из-за неоднозначности описаний и необходимости постоянного обновления моделей. В данной работе, озаглавленной ‘Operationalization of Machine Learning with Serverless Architecture: An Industrial Operationalization of Machine Learning with Serverless Architecture: An Industrial Implementation for Harmonized System Code Prediction’, представлена бессерверная MLOps-платформа для автоматической классификации HS-кодов, обеспечивающая высокую точность и масштабируемость. Разработанное решение, использующее глубокое обучение и текстовые встраивания, достигло 98% точности, одновременно обеспечивая воспроизводимость, аудит и соответствие SLA. Возможно ли создание универсальной бессерверной архитектуры для операционализации моделей машинного обучения в различных областях, требующих высокой надежности и экономической эффективности?
Точность в деталях: вызовы классификации товаров
Точная классификация товаров по Гармонизированной системе (ГС) является краеугольным камнем международной торговли, однако традиционные методы зачастую оказываются неэффективными при работе с детальными и неоднозначными описаниями продукции. Сложность заключается в том, что описание товара, даже составленное профессионалами, может содержать тонкие нюансы, которые трудно однозначно отнести к определенной категории ГС. Ручная классификация требует значительных временных затрат и подвержена человеческому фактору, что повышает риск ошибок. В результате, даже незначительные неточности в кодировке могут привести к задержкам при таможенном оформлении, увеличению транспортных расходов и потенциальным проблемам с соблюдением нормативных требований, что подчеркивает необходимость более точных и автоматизированных решений.
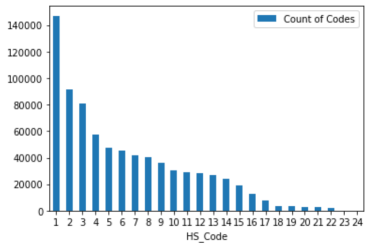
Постоянно растущий объем и сложность данных о товарах, циркулирующих в международной торговле, требуют внедрения автоматизированных решений для классификации по Гармонизированной системе (HS). Однако существующие методы машинного обучения сталкиваются с существенными ограничениями. Неравномерное распределение данных, когда одни категории товаров представлены гораздо чаще других, приводит к смещенным результатам и низкой точности классификации менее распространенных позиций. Кроме того, динамичное изменение характеристик товаров и появление новых продуктов со временем — явление, известное как “смещение данных” — снижает эффективность моделей, требуя постоянной переподготовки и адаптации. В результате, автоматизированные системы классификации, не учитывающие эти факторы, могут выдавать ошибочные результаты, что негативно сказывается на эффективности таможенного оформления и международной торговли.
Неточности в классификации товаров по Гармонизированной системе (HS) приводят к ощутимым негативным последствиям для участников международной торговли. Задержки в таможенном оформлении, вызванные неправильным кодированием, увеличивают сроки доставки и приводят к дополнительным расходам на хранение и логистику. Помимо этого, неверная классификация может повлечь за собой штрафы и санкции со стороны таможенных органов, а также возникновение проблем с соблюдением нормативных требований. В связи с этим, разработка надежной и адаптивной системы классификации, способной оперативно реагировать на изменения в ассортименте товаров и учитывать нюансы их описания, представляется крайне важной задачей для обеспечения бесперебойности и эффективности международной торговли.
Архитектура интеллектуальной классификации: от модели к решению
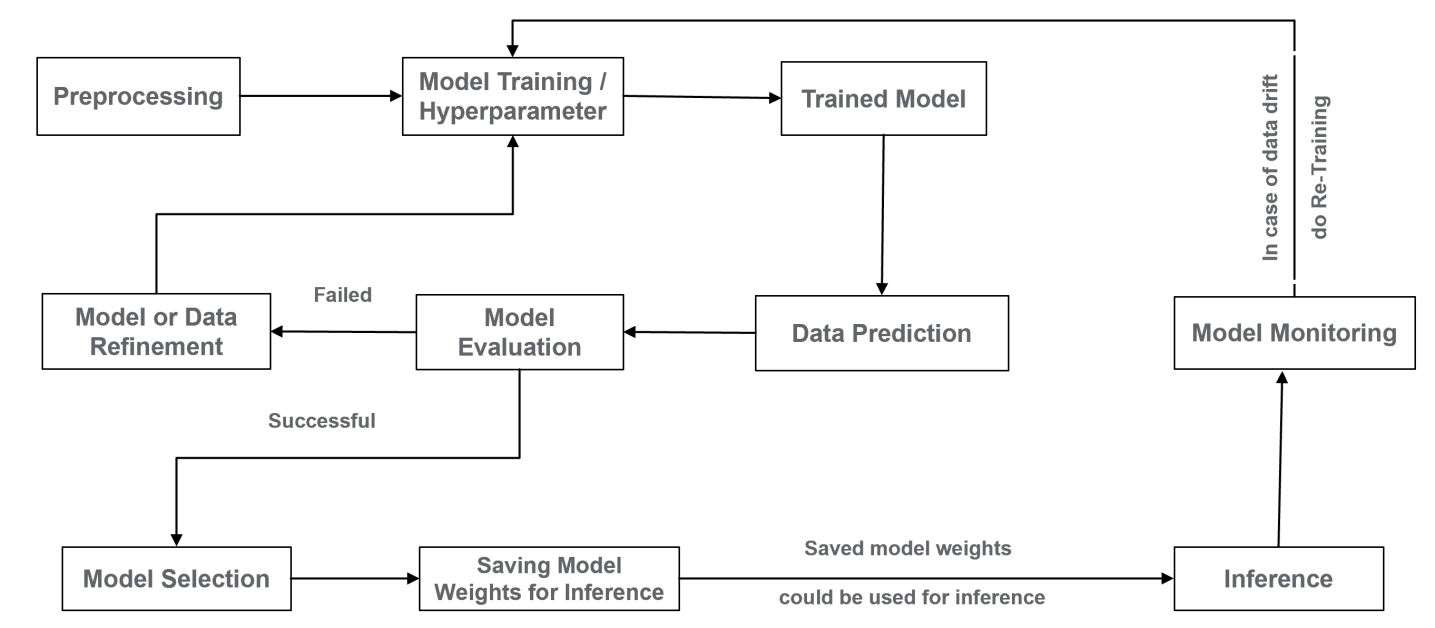
Для автоматической классификации товарных позиций по Гармонизированной системе (HS) используется машинное обучение, в частности, модели глубокого обучения. В процессе анализа текстовых данных о товарах применяются архитектуры Text-CNN, LSTM и DNN. Text-CNN использует сверточные нейронные сети для извлечения признаков из текста, LSTM — рекуррентные нейронные сети для обработки последовательностей, а DNN — полносвязные нейронные сети для классификации на основе полученных признаков. Применение данных моделей позволяет автоматизировать процесс, ранее требующий ручной экспертизы, и повысить скорость и точность определения кодов ТН ВЭД.
Для решения проблемы дисбаланса классов при обучении моделей классификации HS кодов, применяется метод стратифицированной выборки с дублированием примеров миноритарных классов. Этот подход позволяет создать более репрезентативный обучающий набор данных, где каждый класс представлен пропорционально своей доле в реальном распределении. Дублирование примеров миноритарных классов увеличивает их вклад в процесс обучения, что позволяет модели более эффективно изучать характеристики этих классов и снижает риск предвзятости в сторону доминирующих классов. Стратифицированная выборка гарантирует, что доля каждого класса в обучающем наборе соответствует его доле в исходном наборе данных, что повышает обобщающую способность модели.
В ходе экспериментов модель Text-CNN продемонстрировала точность классификации кодов ТН ВЭД до 98%. Модели LSTM и DNN, после применения метода повышения репрезентативности миноритарных классов (up-sampling), достигли показателей точности в 97% и 95% соответственно. Полученные результаты свидетельствуют о высокой эффективности всех трех моделей глубокого обучения для автоматической классификации товаров по кодам ТН ВЭД, при этом Text-CNN демонстрирует незначительное превосходство в точности.

Настройка и оптимизация: путь к стабильной производительности
Тонкая настройка гиперпараметров является критически важным этапом для достижения максимальной точности выбранных моделей. Этот процесс включает в себя итеративное изменение параметров, не определяемых в процессе обучения, таких как скорость обучения, размер пакета и количество слоев, с целью оптимизации производительности на независимом валидационном наборе данных. Валидационный набор данных используется для оценки обобщающей способности модели и предотвращения переобучения, позволяя выявить оптимальную конфигурацию гиперпараметров, обеспечивающую наилучшие результаты на новых, ранее не встречавшихся данных. Эффективная настройка гиперпараметров позволяет существенно повысить точность и надежность модели, а также снизить вероятность ошибок классификации.
Для обеспечения непрерывного улучшения и выявления наиболее эффективных конфигураций моделей, внедрено A/B-тестирование. Данный процесс предполагает сравнение различных версий моделей в реальных условиях эксплуатации, с анализом ключевых метрик производительности на живом трафике. Результаты A/B-тестирования позволяют объективно оценить влияние изменений в моделях на показатели точности, скорости обработки и другие важные параметры, что, в свою очередь, позволяет принимать обоснованные решения о внедрении новых версий и откате к предыдущим в случае необходимости. Систематическое проведение A/B-тестирования является неотъемлемой частью процесса оптимизации и поддержания высокой надежности системы классификации.
Результаты тестирования показали, что модель Text-CNN, после применения метода повышения выборки (up-sampling), классифицирует до 20 из 23 кодов ТН ВЭД (HS codes) с высокой точностью, превышающей 90%. Данный показатель демонстрирует надежность и стабильность системы классификации, подтверждая ее способность к эффективной обработке и категоризации данных в реальных условиях. Использование up-sampling позволило улучшить способность модели к обобщению и снизить количество ложных срабатываний при классификации.
Масштабируемая инфраструктура для непрерывной работы
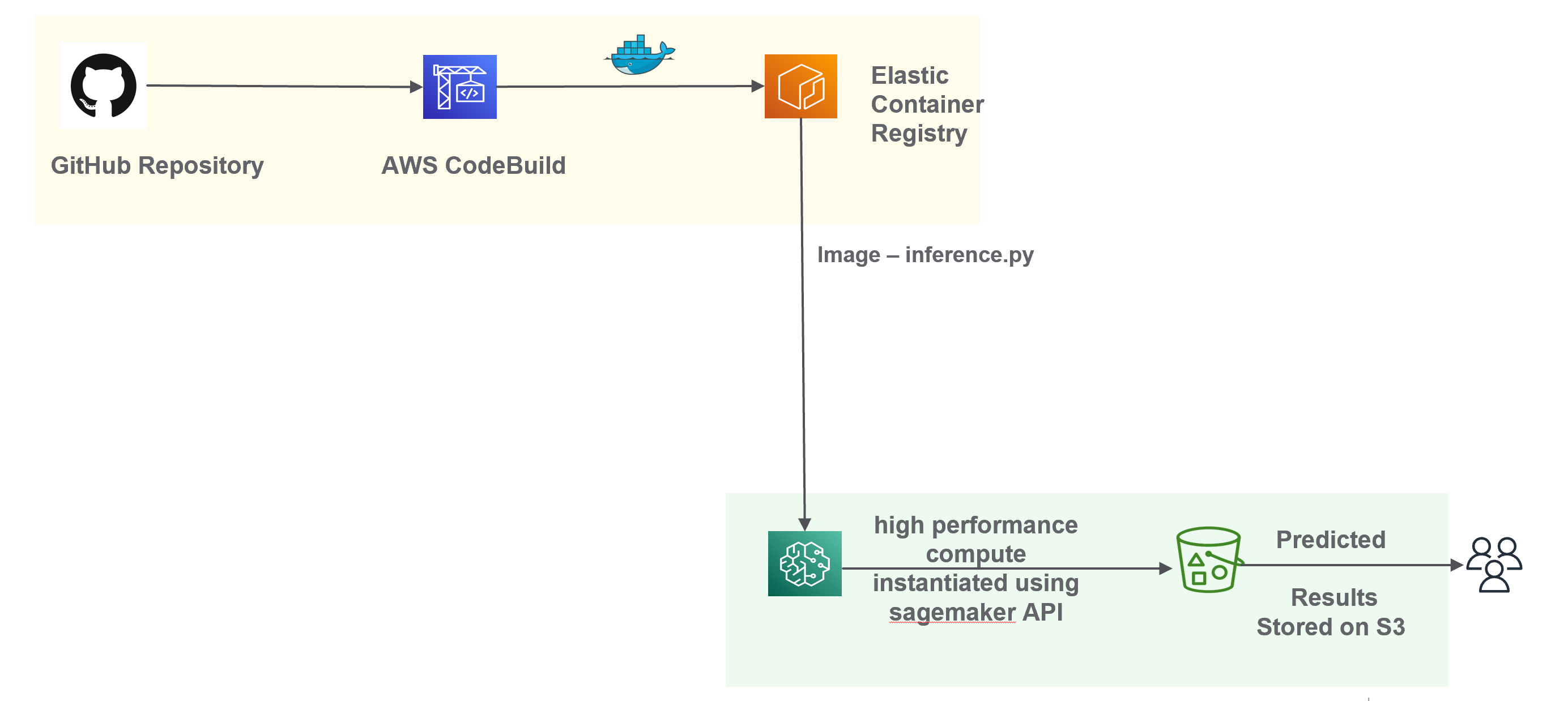
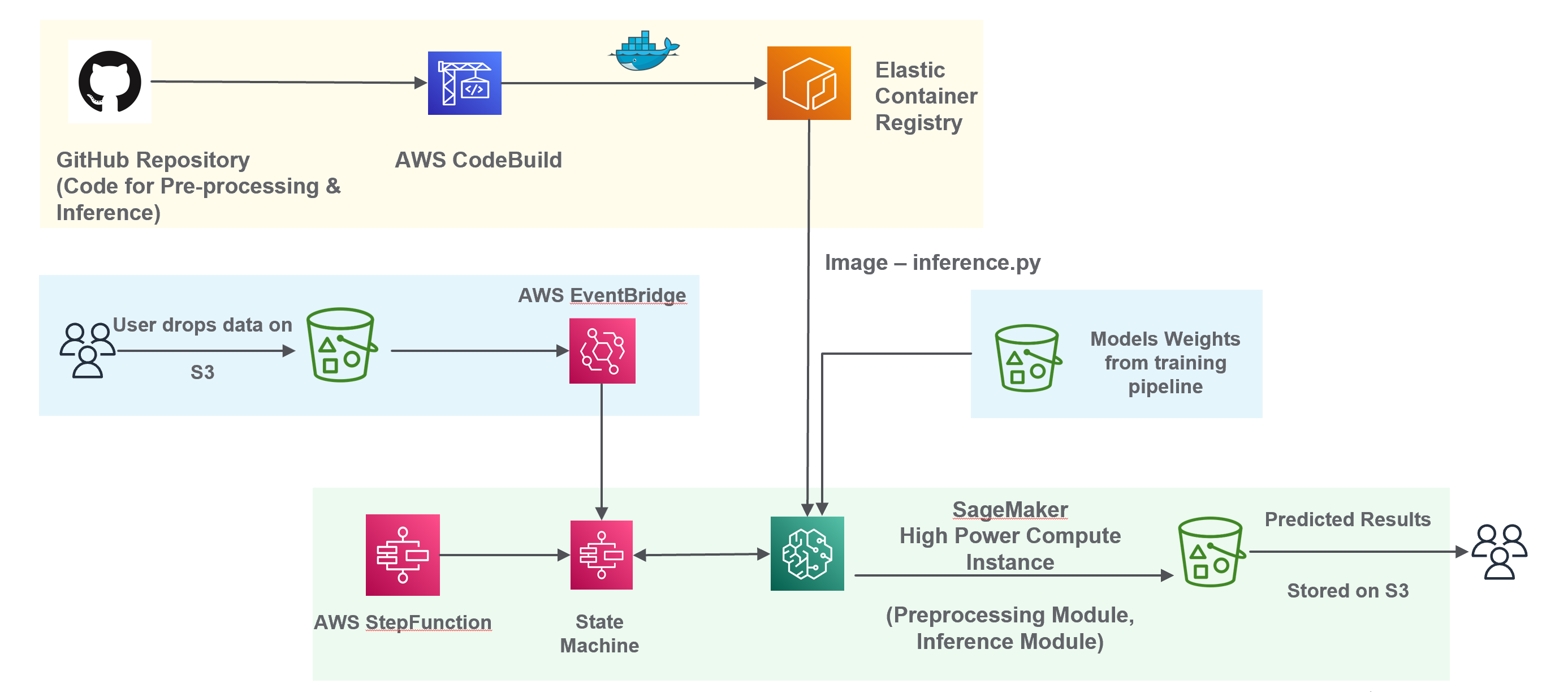
Внедрение бессерверной архитектуры, основанной на сервисах AWS S3, AWS CodeBuild, AWS ECR и AWS Step Functions, позволило создать экономически эффективное и масштабируемое решение для развертывания и управления конвейером машинного обучения. Такой подход устраняет необходимость в постоянном управлении серверами, автоматически масштабируя ресурсы в зависимости от нагрузки. AWS S3 выступает в роли хранилища данных и моделей, CodeBuild автоматизирует сборку и тестирование кода, ECR предоставляет безопасное хранилище образов контейнеров, а Step Functions оркестрирует весь процесс, обеспечивая надежное и последовательное выполнение задач. Это не только снижает операционные расходы, но и значительно повышает гибкость и отказоустойчивость системы, позволяя оперативно реагировать на изменения в данных и требованиях бизнеса.
Инфраструктура, построенная на базе серверных технологий, обеспечивает непрерывную интеграцию и доставку (CI/CD) обновлений моделей машинного обучения. Автоматизация процессов сборки, тестирования и развертывания позволяет оперативно внедрять улучшения и исправления, минимизируя время простоя и обеспечивая стабильную работу системы. Данный подход позволяет не только ускорить цикл разработки, но и снизить вероятность ошибок, связанных с ручным вмешательством, что особенно важно для критически важных приложений, требующих высокой надежности и точности классификации, например, в задачах определения кодов ТН ВЭД.
Внедренная система демонстрирует высокую точность классификации кодов ТН ВЭД, достигая 98% благодаря использованию модели Text-CNN. Это позволяет автоматизировать процесс определения товарных позиций с высокой степенью надежности. Более того, архитектура системы обеспечивает устойчивость к изменениям данных и непрерывное совершенствование модели. Автоматизированный цикл переобучения и развертывания позволяет оперативно адаптировать систему к новым данным и поддерживать ее актуальность, гарантируя стабильно высокую производительность в долгосрочной перспективе и минимизируя необходимость ручного вмешательства.
Исследование демонстрирует, как тщательно продуманная структура серверной архитектуры становится основой для эффективного функционирования системы классификации HS-кодов. Авторы подчеркивают важность целостного подхода к разработке, где каждая зависимость оценивается с точки зрения её влияния на общую производительность и надежность. В этом контексте, особенно актуально высказывание Блеза Паскаля: «Все великие проблемы имеют простые решения». Применение серверной архитектуры, как показано в статье, упрощает сложность развертывания и масштабирования модели, позволяя сосредоточиться на решении основной задачи — повышении точности классификации и, следовательно, упрощении процессов таможенного соответствия. Продуманная структура позволяет избежать ненужных сложностей и обеспечить стабильную работу системы даже при наличии дисбаланса данных.
Что дальше?
Представленная работа, хотя и демонстрирует работоспособность автоматизированного определения кодов товарной номенклатуры ТН ВЭД, лишь приоткрывает завесу над сложностью системы. Проблема, как всегда, кроется в границах ответственности: чья задача — обеспечить качество данных, чья — адаптировать модель к меняющимся правилам таможенного оформления, и чья — нести ответственность за ошибки? Недостаточно просто построить алгоритм; необходимо спроектировать всю экосистему, предвидя точки отказа и зоны повышенной уязвимости. Очевидно, что текущая архитектура, хоть и масштабируема, требует дальнейшего развития в части мониторинга и автоматической адаптации к дрейфу данных — иначе, кажущаяся автоматизация обернется лишь более быстрым распространением ошибок.
Перспективы развития очевидны: интеграция с системами управления цепочками поставок, использование методов активного обучения для снижения потребности в ручной разметке данных, и, что наиболее важно, разработка метрик, отражающих не только точность предсказания, но и экономический эффект от автоматизации. Слишком часто, в погоне за технологическими новшествами, упускается из виду простой факт: хорошая система — это не просто набор сложных алгоритмов, а живой организм, способный к саморегуляции и адаптации. Иначе, даже самая элегантная архитектура рано или поздно даст трещину.
В конечном счете, успех автоматизации кодов ТН ВЭД зависит не столько от совершенства алгоритмов, сколько от понимания того, что любая система ограничена. Прогнозировать и смягчать последствия этих ограничений — вот истинная задача исследователя. Иначе, неизбежно столкнемся с тем, что всё ломается — именно там, где никто не ожидал.
Оригинал статьи: https://arxiv.org/pdf/2602.17102.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Распознавание смыслов: новый подход к классификации документов
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сверхпроводящая логика: управление магнитным полем
- Квантовый скачок в многомасштабном моделировании
- От миллиметровых волн к кубитному управлению: единый подход
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Тонкости настройки: как научить нейросети понимать сложные предпочтения
- Ожившие Истории: Искусственный Интеллект, Создающий и Редактирующий Аудио
- Алгоритмы рассказывают истории: новые горизонты повествования
2026-02-22 14:16