Автор: Денис Аветисян
Исследователи представили DeepVision-103K — обширный и разнообразный набор данных, призванный улучшить способность искусственного интеллекта решать математические задачи, опираясь на визуальную информацию.
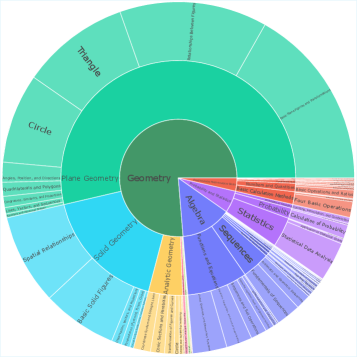
DeepVision-103K — это масштабный, проверенный и многогранный датасет для мультимодального обучения, предназначенный для развития математических и визуальных навыков у больших языковых моделей.
Несмотря на успехи больших мультимодальных моделей, их способность к визуальному рассуждению и решению математических задач остается ограниченной из-за недостатка качественных данных. В данной работе представлена база данных DeepVision-103K: A Visually Diverse, Broad-Coverage, and Verifiable Mathematical Dataset for Multimodal Reasoning, включающая 103 тысячи примеров, охватывающих широкий спектр математических тем и визуальных элементов. Обучение моделей на этой базе данных демонстрирует улучшение навыков визуального восприятия и рассуждений, а также повышение эффективности решения математических задач. Какие новые горизонты откроются в области мультимодального обучения благодаря созданию более полных и разнообразных наборов данных?
Разоблачение узких мест мультимодального интеллекта
Современные большие языковые модели (LLM) демонстрируют значительные трудности при решении сложных задач, требующих мультимодального рассуждения — то есть обработки и интеграции информации из различных источников, таких как текст и изображения. Для достижения приемлемых результатов в подобных задачах, LLM нуждаются в огромных объемах данных и колоссальных вычислительных ресурсах. Это связано с тем, что модели испытывают затруднения при установлении логических связей между различными модальностями, что приводит к неточностям и ошибкам в рассуждениях. Несмотря на впечатляющий прогресс в области обработки естественного языка, способность к комплексному анализу и синтезу информации из разных источников остается серьезным вызовом для современных LLM, требующим дальнейших исследований и разработки новых алгоритмов.
Существующие наборы данных для обучения мультимодальных систем искусственного интеллекта зачастую страдают от недостаточной разносторонности и сложности структурирования, что препятствует развитию надежного визуального и математического понимания. В большинстве случаев эти наборы данных содержат изображения и соответствующие текстовые описания, однако им не хватает детализированных связей между визуальными элементами и математическими концепциями, а также логических цепочек, необходимых для решения сложных задач. Отсутствие структурированной информации, отражающей причинно-следственные связи и позволяющей модели выводить новые знания на основе представленных данных, ограничивает ее способность к обобщению и решению задач, выходящих за рамки заученных примеров. Более того, существующие наборы данных часто не охватывают весь спектр возможных визуальных сценариев и математических задач, что приводит к предвзятости и низкой производительности модели в реальных условиях. Разработка наборов данных, включающих в себя разнообразные визуальные представления, сложные математические задачи и четко определенные логические связи, является ключевым шагом к созданию действительно интеллектуальных мультимодальных систем.
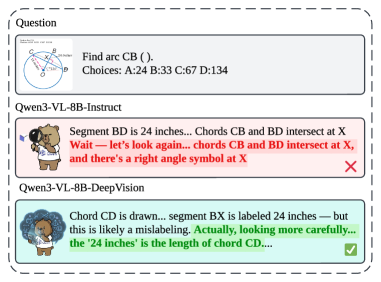
Отсутствие четких, верифицируемых сигналов вознаграждения в процессе обучения существенно ограничивает развитие надежных способностей к рассуждению у мультимодальных моделей. В отличие от задач, где правильность ответа может быть однозначно определена, сложные мультимодальные рассуждения часто требуют оценки промежуточных шагов и контекстуального понимания. Если модель не получает точной обратной связи о корректности каждого этапа логической цепочки, она склонна к генерации правдоподобных, но ошибочных ответов. Это особенно актуально при решении задач, требующих интеграции визуальной информации и математических операций, где даже незначительная ошибка в интерпретации данных может привести к неверному конечному результату. Разработка методов, позволяющих предоставлять модели измеримые и достоверные вознаграждения за каждый шаг логического вывода, является ключевой задачей для повышения надежности и точности мультимодальных систем искусственного интеллекта.
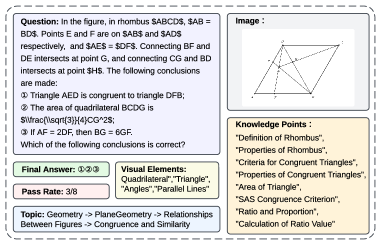
DeepVision-103K: Платформа для верифицируемого мышления
DeepVision-103K представляет собой масштабный мультимодальный набор данных, состоящий из разнообразных математических задач и задач визуальной логики. Он специально разработан для обучения с подкреплением (Reinforcement Learning) и характеризуется наличием проверяемых наград (verifiable rewards). Набор данных включает в себя широкий спектр типов задач, предназначенных для оценки и улучшения способностей моделей к логическому мышлению и решению проблем, а также для обеспечения возможности автоматической проверки правильности полученных ответов в процессе обучения. Объем и разнообразие данных в DeepVision-103K призваны способствовать повышению обобщающей способности обученных моделей и их эффективности в решении сложных задач.
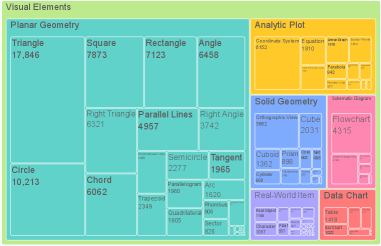
Набор данных DeepVision-103K отличается широким разнообразием визуальных элементов, включающих геометрические фигуры, аналитические графики, диаграммы и изображения реальных объектов. Такое разнообразие специально разработано для повышения способности моделей к обобщению, то есть к успешной работе с задачами, которые отличаются от тех, на которых они были обучены. Использование различных типов визуальных представлений позволяет алгоритмам машинного обучения развивать более устойчивые и гибкие стратегии решения задач, не ограничиваясь конкретным типом входных данных. Это особенно важно для систем, предназначенных для работы в реальных условиях, где входные данные могут значительно варьироваться.
Набор данных DeepVision-103K охватывает широкий спектр математических дисциплин, включая алгебру, геометрию, тригонометрию, математический анализ и статистику. Визуальные задачи включают интерпретацию графиков функций, диаграмм, геометрических фигур и анализ изображений реальных объектов. Это разнообразие обеспечивает всестороннее обучение моделей, позволяя им развивать навыки решения задач в различных областях математики и визуального мышления, а также повышает устойчивость к обобщению на новые, ранее не встречавшиеся типы задач. Включение широкого спектра сложностей в каждой категории также способствует развитию более надежных и универсальных систем искусственного интеллекта.
Включение верифицируемых наград в DeepVision-103K позволяет алгоритмам обучения с подкреплением (Reinforcement Learning) извлекать уроки как из правильных, так и из неправильных ответов. Это достигается за счет предоставления четкой обратной связи о корректности решения каждой задачи, что позволяет агенту оптимизировать свою стратегию обучения. В отличие от традиционных методов, где обратная связь может быть неточной или отсутствовать, верифицируемые награды обеспечивают надежный сигнал для улучшения точности рассуждений и повышения эффективности обучения в задачах, требующих логического вывода и анализа визуальной информации. Такой подход способствует более быстрому схождению алгоритма и достижению более высоких показателей производительности в задачах визуального мышления и решения математических задач.
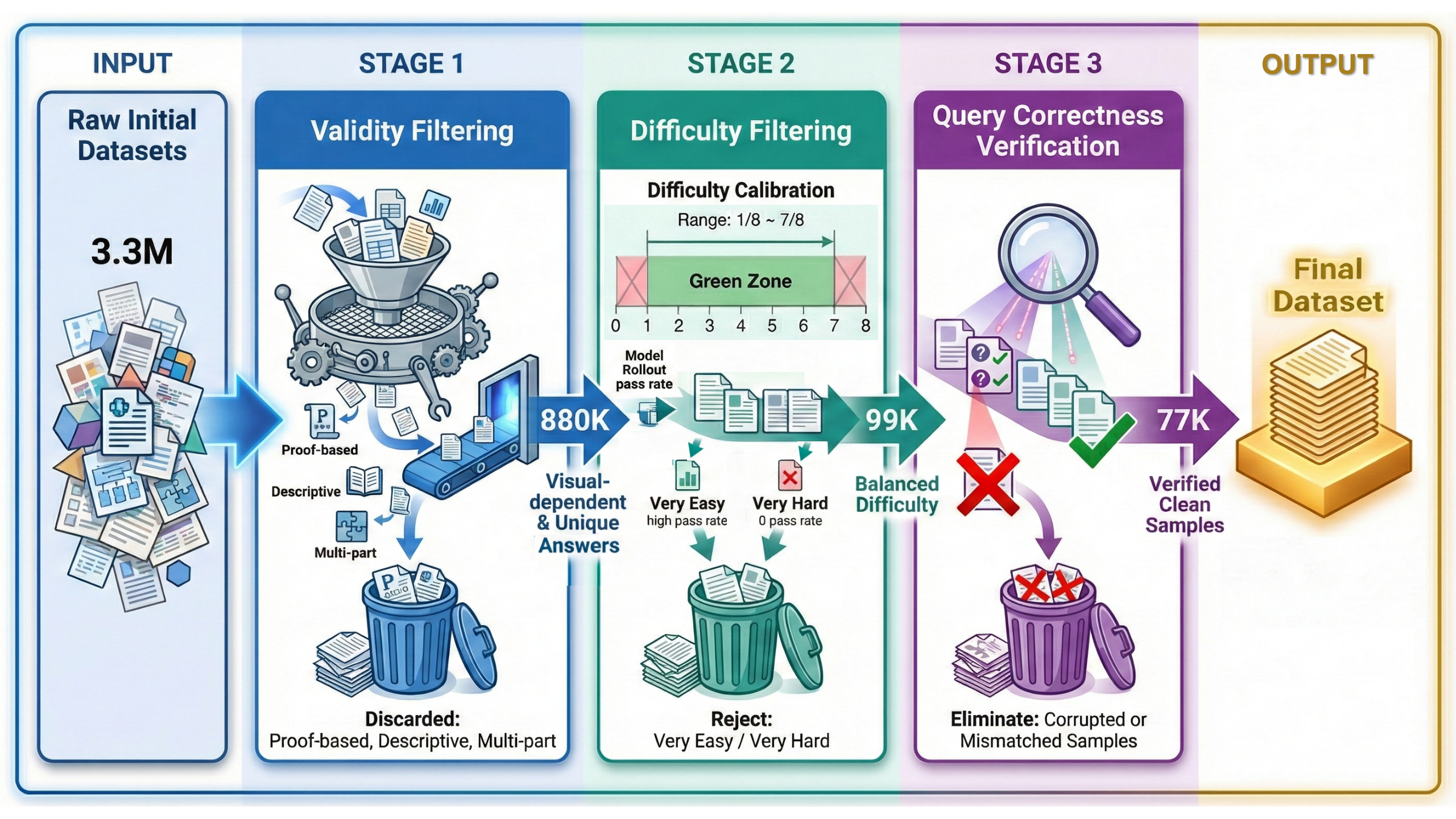
Автоматизированная курация: Гарантия целостности данных
Набор данных DeepVision-103K формируется с использованием автоматизированного конвейера, включающего фильтрацию валидности, стратификацию по проходному коэффициенту и проверку корректности. Этот процесс обеспечивает высокое качество и надежность данных. Фильтрация валидности отсеивает неподходящие задачи, гарантируя, что набор данных содержит только четко сформулированные и решаемые примеры. Стратификация по проходному коэффициенту калибрует сложность примеров на основе производительности моделей, создавая сбалансированный и сложный набор данных. Проверка корректности, использующая модели, такие как Gemini-3-Flash, подтверждает точность вопросов и ответов, повышая общую надежность данных.
Процесс фильтрации валидности в DeepVision-103K предназначен для исключения нерелевантных или некорректно сформулированных задач, обеспечивая включение в датасет только четко определенных и решаемых проблем. Данный этап подразумевает автоматизированную проверку задач на соответствие заданным критериям, таким как синтаксическая корректность, отсутствие двусмысленности и наличие необходимой информации для решения. Задачи, не соответствующие этим критериям, автоматически отбрасываются, что позволяет повысить качество и надежность всего датасета, а также упростить процесс обучения моделей машинного обучения.
Стратификация по показателям успешности калибрует сложность примеров на основе производительности модели. Этот процесс предполагает анализ ответов предварительно обученной модели на каждый пример в наборе данных и последующее разделение примеров на группы в зависимости от процента успешных ответов. Примеры с высоким процентом успешных ответов формируют более легкую группу, а примеры с низким процентом — более сложную. Такая стратификация обеспечивает сбалансированное распределение сложности в конечном наборе данных, предотвращая доминирование слишком простых или слишком сложных задач и обеспечивая эффективное обучение моделей машинного обучения.
Проверка корректности в DeepVision-103K осуществляется с использованием моделей, таких как Gemini-3-Flash, для автоматической оценки точности вопросов и ответов. Этот процесс включает в себя сопоставление сгенерированных ответов с эталонными данными и выявление несоответствий или ошибок. Модель Gemini-3-Flash используется для оценки логической последовательности вопросов и ответов, а также для обнаружения фактических неточностей. Автоматизированная проверка позволяет значительно повысить надежность данных, минимизируя влияние человеческого фактора и обеспечивая соответствие вопросов и ответов установленным критериям качества.
Эмпирическая валидация и производительность модели
Модели MiMo-VL и Qwen3-VL, обученные на датасете DeepVision-103K с использованием обучения с подкреплением и алгоритма GSPO, демонстрируют передовые результаты на стандартных бенчмарках, включая WeMath, MathVerse и LogicVista. Эти модели показали способность эффективно решать задачи, требующие визуального и логического мышления, что подтверждается их высокими показателями на специализированных тестовых наборах. Обучение с использованием GSPO позволило оптимизировать модели для достижения максимальной производительности в задачах, требующих сложных рассуждений и анализа визуальной информации.
Структура набора данных DeepVision-103K обеспечивает эффективное обучение больших мультимодальных моделей (LMM). В частности, организация данных позволяет моделям устанавливать четкие связи между визуальной информацией и логическими рассуждениями, что критически важно для задач, требующих верифицируемого мышления. Это достигается за счет тщательно разработанной аннотации и структурирования примеров, что позволяет LMM более эффективно извлекать и обобщать знания из мультимодальных входных данных, приводя к повышению способности к решению сложных задач, требующих логического вывода и анализа.
В ходе экспериментов было зафиксировано значительное улучшение результатов на используемых бенчмарках — до 8.56% по сравнению с базовыми моделями. Данное улучшение было достигнуто благодаря применению разработанного подхода к обучению и структуре датасета DeepVision-103K, что подтверждает эффективность предложенной методики в задачах мультимодального анализа и рассуждений. Полученные данные свидетельствуют о существенном прогрессе в области повышения производительности моделей машинного обучения на специализированных наборах данных.
В ходе экспериментов достигнута точность в 85.11% на бенчмарке WeMath и 65.62% на LogicVista, что является наилучшим результатом на момент публикации. Дополнительно, зафиксировано улучшение показателей до 7.0% на общих мультимодальных бенчмарках, что подтверждает эффективность предложенного подхода к обучению и высокую производительность разработанных моделей в задачах, требующих комплексного анализа визуальной и текстовой информации.
Результаты экспериментов демонстрируют, что датасет DeepVision-103K эффективно способствует развитию навыков проверяемого рассуждения у мультимодальных моделей искусственного интеллекта. Обучение моделей, таких как MiMo-VL и Qwen3-VL, на данном датасете с использованием обучения с подкреплением GSPO, позволило достичь передовых результатов на бенчмарках WeMath, MathVerse и LogicVista, а также улучшить общую производительность на стандартных мультимодальных тестах до 7.0%. Достигнутая точность в 85.11% на WeMath и 65.62% на LogicVista подтверждает эффективность DeepVision-103K в повышении способности моделей к логическим выводам и решению задач, требующих верификации.
Влияние и перспективы развития
Набор данных DeepVision-103K представляет собой ценный ресурс для научного сообщества, способствуя значительному прогрессу в области мультимодального рассуждения и искусственного интеллекта. Содержащий более ста тысяч визуальных задач, требующих интеграции зрительной информации и логического вывода, этот набор позволяет исследователям разрабатывать и тестировать новые алгоритмы, превосходящие существующие модели в решении сложных проблем. Особенностью DeepVision-103K является акцент на задачах, требующих не просто распознавания объектов, а понимания их взаимосвязей и применения логических правил для достижения цели, что открывает возможности для создания более интеллектуальных и надежных систем искусственного интеллекта. Предоставляя богатую и разнообразную платформу для экспериментов, DeepVision-103K способствует ускорению исследований в таких областях, как робототехника, автоматизированное принятие решений и создание интеллектуальных помощников.
В дальнейшем планируется существенное расширение набора данных DeepVision-103K за счет включения более сложных и многогранных задач, требующих не только визуального восприятия, но и глубокого логического анализа. Параллельно с этим, исследователи намерены изучить и внедрить новые алгоритмы обучения с подкреплением, которые позволят системе самостоятельно находить оптимальные стратегии решения этих задач, повышая её адаптивность и эффективность. Особое внимание будет уделено разработке алгоритмов, способных к обобщению знаний и переносу опыта на принципиально новые ситуации, что является ключевым шагом к созданию действительно интеллектуальных и автономных систем искусственного интеллекта.
Предполагается, что данная технология окажет значительное влияние на широкий спектр областей. В сфере образования она может быть использована для создания персонализированных обучающих систем, адаптирующихся к индивидуальным потребностям каждого ученика. В области научных исследований — для автоматизации анализа данных и выдвижения новых гипотез, ускоряя тем самым процесс открытия. Кроме того, развитие систем автоматического решения проблем позволит оптимизировать различные процессы — от логистики и производства до диагностики и принятия решений в критических ситуациях. Перспективы применения простираются от помощи в сложных вычислениях до создания интеллектуальных помощников, способных решать задачи, требующие логического мышления и анализа информации.
Разработка надёжных и верифицируемых способностей к рассуждению является ключевым фактором для создания действительно интеллектуальных и заслуживающих доверия систем искусственного интеллекта. Отсутствие прозрачности в процессах принятия решений ИИ вызывает обоснованные опасения, особенно в критически важных областях, таких как здравоохранение и финансы. Возможность не только получить результат, но и проследить логику, приведшую к нему, позволяет оценить обоснованность и корректность действий системы, а также выявить потенциальные ошибки и предвзятости. Повышение уровня проверяемости алгоритмов рассуждения позволит преодолеть существующие ограничения и откроет путь к созданию ИИ, способного не только решать задачи, но и объяснять свои решения, что является необходимым условием для широкого внедрения и доверия к данной технологии.
Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных не просто оперировать информацией, но и проверять её достоверность. Авторы, создавая DeepVision-103K, по сути, предлагают новую парадигму обучения, где модели вознаграждаются за верифицируемые решения, а не за простое воспроизведение шаблонов. Как заметил Кен Томпсон: «Всегда есть еще один уровень.» Эта фраза отражает суть подхода, представленного в статье — постоянное стремление к углублению понимания и проверке каждой детали, что особенно важно при обучении моделей сложным задачам, требующим как визуального, так и математического мышления. Создание такого датасета позволяет расширить границы возможного в области мультимодального обучения и приблизить нас к созданию действительно разумных систем.
Куда Ведет Этот Путь?
Представленный датасет, DeepVision-103K, — не просто набор изображений и уравнений, а, скорее, приглашение к взлому системы. Он демонстрирует, что даже кажущиеся неразрешимыми задачи визуально-математического рассуждения поддаются машинному обучению, если правильно подобрана «приманка» в виде верифицируемых наград. Однако, стоит помнить: каждый эксплойт начинается с вопроса, а не с намерения. Возникает закономерный вопрос: достаточно ли одной лишь масштабируемости датасета для достижения истинного «понимания»? Или же, за пределами текущего подхода скрывается необходимость в принципиально новых архитектурах, способных к абстрактному мышлению, а не просто к статистическому сопоставлению паттернов?
Очевидным направлением дальнейших исследований является разработка более устойчивых к «шуму» и неполноте данных моделей. Настоящая проверка ждет датасет в условиях намеренных искажений, попыток обмануть систему, заставить её выдавать ложные решения. Иными словами, датасет необходимо «взломать» изнутри, прежде чем утверждать о его надежности. Кроме того, представляется перспективным изучение возможности переноса полученных навыков на другие, несвязанные области знаний. Иначе говоря, способен ли «обученный» алгоритм применить полученные навыки к решению проблем, не связанных с визуально-математическим рассуждением?
В конечном счете, успех этого направления исследований будет зависеть не от количества собранных данных, а от глубины поставленных вопросов и готовности к принятию неожиданных ответов. Задача не в том, чтобы создать идеальную систему, а в том, чтобы понять её пределы. И в этом, пожалуй, и заключается истинная ценность представленной работы.
Оригинал статьи: https://arxiv.org/pdf/2602.16742.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сверхпроводящая логика: управление магнитным полем
- Распознавание смыслов: новый подход к классификации документов
- Квантовый скачок в многомасштабном моделировании
- От миллиметровых волн к кубитному управлению: единый подход
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Разреженность как ключ к скорости: Новая архитектура для мультимодальных моделей
- Квантовые вычисления: Честность и Прогресс
- Звук как помощник зрения: Новые горизонты генерации видео
2026-02-22 19:20