Автор: Денис Аветисян
Новая статья предлагает комплексный подход к обеспечению конфиденциальности при использовании больших языковых моделей в приложениях, разработанных для детей.
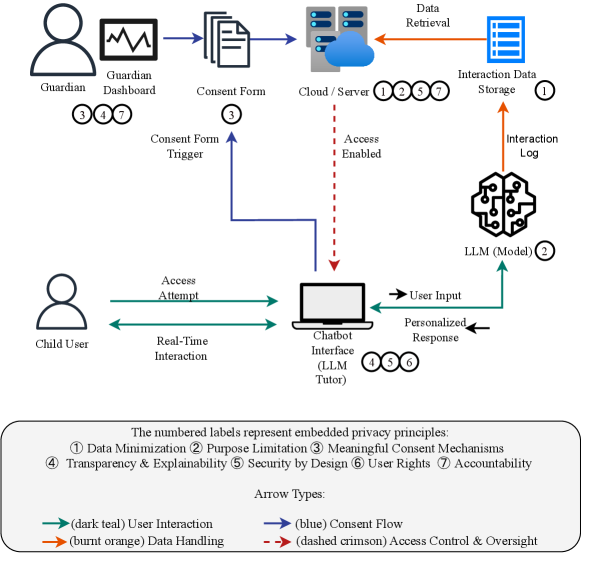
Разработана структура принципов Privacy by Design, адаптированная к жизненному циклу больших языковых моделей, для соответствия нормативным требованиям и защиты данных несовершеннолетних.
Растущее использование технологий искусственного интеллекта (ИИ) в приложениях для детей создает парадокс между инновациями и необходимостью защиты персональных данных. В статье ‘A Privacy by Design Framework for Large Language Model-Based Applications for Children’ предложен комплексный подход, основанный на принципах Privacy-by-Design, для разработки приложений с использованием больших языковых моделей (LLM). Данный фреймворк сопоставляет регуляторные требования, включая GDPR, COPPA и UNCRC, с различными этапами жизненного цикла LLM, обеспечивая соблюдение правовых норм и защиту конфиденциальности детей. Возможно ли, используя предложенные принципы, создать действительно безопасные и этичные ИИ-приложения для юных пользователей, сочетающие в себе образовательный потенциал и надежную защиту данных?
Растущая необходимость защиты приватности в больших языковых моделях
В настоящее время большие языковые модели (БЯМ) всё активнее внедряются в приложения, работающие с конфиденциальными данными, что вызывает растущую обеспокоенность по поводу сохранения приватности. От обработки персональной информации в сфере здравоохранения и финансов до анализа личных переписок и документов — БЯМ становятся ключевым элементом многих чувствительных процессов. Этот повсеместный рост использования поднимает вопросы о том, как обеспечить надёжную защиту личных данных от несанкционированного доступа, утечек и злоупотреблений. Сложность заключается в том, что БЯМ способны не просто хранить данные, но и извлекать из них скрытые закономерности и делать прогнозы, что значительно увеличивает риски для приватности пользователей. Поэтому разработка и внедрение эффективных механизмов защиты данных становятся критически важной задачей для разработчиков и регуляторов.
Традиционные методы обеспечения конфиденциальности, такие как анонимизация и маскировка данных, зачастую оказываются неэффективными применительно к большим языковым моделям (LLM). Уникальная способность LLM к запоминанию и воспроизведению информации, а также их способность к обобщению и выводу новых знаний из обработанных данных, позволяет им восстанавливать идентифицирующую информацию даже из, казалось бы, обезличенных наборов данных. В отличие от традиционных систем, где конфиденциальность обеспечивается контролем доступа и шифрованием, LLM оперируют с семантическим содержанием данных, что делает уязвимыми подходы, основанные на удалении или изменении конкретных атрибутов. Необходимость защиты от атак, направленных на извлечение конфиденциальной информации из параметров модели или генерируемых ею текстов, требует разработки принципиально новых методов обеспечения приватности, учитывающих специфику обработки данных в LLM.
Разработчики больших языковых моделей (LLM) сталкиваются со сложной задачей соответствия многочисленным нормативным актам, таким как GDPR, COPPA и PIPEDA. Эти законы, изначально не предназначенные для обработки данных столь сложными алгоритмами, требуют от компаний тщательного анализа и адаптации подходов к защите персональных данных. Соблюдение этих нормативных требований подразумевает не только технические решения, но и юридическую экспертизу, а также постоянный мониторинг изменений в законодательстве. Отсутствие четких инструкций и разнообразие интерпретаций этих законов создают значительные трудности для разработчиков, вынуждая их инвестировать в создание комплексных систем управления данными и обеспечения конфиденциальности, чтобы избежать потенциальных штрафов и репутационных рисков.
Учитывая растущую вероятность утечек данных и неправомерного использования информации, становится очевидной необходимость в упреждающих подходах к конфиденциальности, интегрированных в саму структуру больших языковых моделей. Данная работа подчеркивает важность принципа “конфиденциальность по умолчанию”, предлагая комплексную систему защиты, которая охватывает все этапы жизненного цикла модели — от сбора и обработки данных до обучения и развертывания. Предложенная структура предусматривает многоуровневую защиту, включающую анонимизацию данных, дифференциальную конфиденциальность и механизмы контроля доступа, что позволяет минимизировать риски, связанные с потенциальными нарушениями конфиденциальности и злоупотреблениями личной информацией. Такой проактивный подход, в отличие от реактивного исправления уязвимостей, позволяет разработчикам создавать более безопасные и надежные языковые модели, отвечающие современным требованиям регуляторов и ожиданиям пользователей.
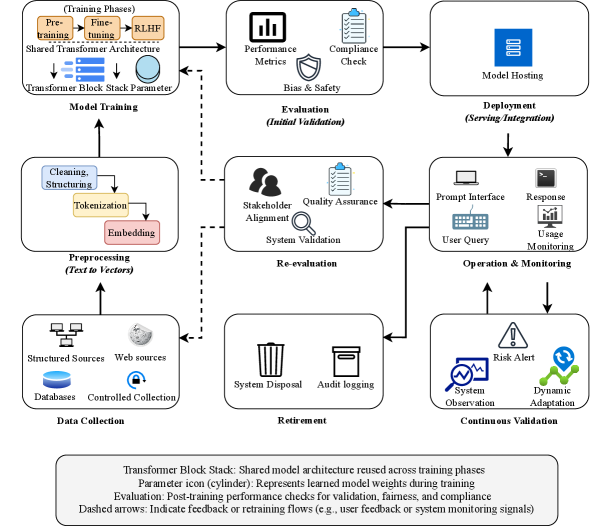
Жизненный цикл LLM и лучшие практики обработки данных
Жизненный цикл большой языковой модели (LLM) включает в себя этапы сбора данных, обучения модели, эксплуатации и мониторинга, а также непрерывную валидацию. На каждом из этих этапов необходимо учитывать специфические требования к конфиденциальности данных. Сбор данных требует соблюдения принципов минимизации и целевого использования. Обучение модели может потребовать применения методов дифференциальной приватности для защиты отдельных данных. Эксплуатация и мониторинг должны включать фильтрацию входных данных для предотвращения обработки конфиденциальной информации. Непрерывная валидация необходима для выявления и устранения потенциальных уязвимостей, связанных с конфиденциальностью, на протяжении всего жизненного цикла LLM.
Принципы минимизации данных и ограничения целей обработки являются основополагающими при сборе данных для обучения и функционирования больших языковых моделей (LLM). Минимизация данных предполагает сбор только той информации, которая строго необходима для достижения конкретной, заранее определенной цели. Ограничение целей обработки требует четкого определения и документирования целей сбора данных, а также недопущения использования собранной информации для иных, не оговоренных целей. Соблюдение этих принципов не только снижает риски, связанные с утечкой или неправомерным использованием персональных данных, но и упрощает соблюдение нормативных требований, таких как GDPR и другие законы о защите данных. Реализация этих принципов предполагает тщательный анализ потребностей в данных на каждом этапе жизненного цикла LLM и постоянный контроль за соответствием собираемой информации заявленным целям.
Фильтрация входных данных является критически важной процедурой для удаления конфиденциальной информации перед ее обработкой языковой моделью. Данные, поступающие на вход, могут содержать персональные идентификаторы (PII), финансовые данные, медицинскую информацию или другие чувствительные сведения. Для реализации фильтрации используются различные методы, включая регулярные выражения, словари запрещенных слов, алгоритмы распознавания именованных сущностей (NER) и маскирование данных. Эффективная фильтрация требует постоянного обновления правил и алгоритмов в соответствии с изменяющимися типами конфиденциальной информации и форматами данных, а также проведения регулярных проверок для обеспечения точности и полноты удаления чувствительных данных.
Дифференциальная конфиденциальность (Differential Privacy, DP) представляет собой набор методов, позволяющих обучать модели машинного обучения, включая большие языковые модели (LLM), без раскрытия информации об отдельных записях в обучающем наборе данных. Реализация DP достигается путем добавления контролируемого шума к данным или процессу обучения, что гарантирует, что вклад каждого отдельного пользователя или записи в результат обучения ограничен. Технически, DP измеряется параметром ε (эпсилон), определяющим уровень защиты конфиденциальности: чем меньше ε, тем выше уровень защиты, но и тем ниже точность модели. Организационные меры включают в себя определение бюджета конфиденциальности для всего жизненного цикла модели, мониторинг использования бюджета, а также внедрение политик, регламентирующих сбор, обработку и использование данных для обучения LLM. Интеграция DP требует применения специализированных алгоритмов и инструментов, а также тщательной оценки компромисса между конфиденциальностью и полезностью модели.
Защита LLM в работе: мониторинг и безопасность
Эффективная эксплуатация и мониторинг больших языковых моделей (LLM) требует применения состязательного обучения (Adversarial Training) для повышения их устойчивости к злонамеренным входным данным. Данный метод предполагает намеренное создание и использование модифицированных входных данных, разработанных для обхода защитных механизмов LLM. В процессе обучения модель подвергается воздействию этих “состязательных примеров”, что позволяет ей научиться распознавать и нейтрализовывать подобные атаки. Состязательное обучение повышает робастность модели к различным типам атак, включая инъекции подсказок (prompt injection) и обход фильтров безопасности, что критически важно для обеспечения надежной и безопасной работы LLM в реальных условиях эксплуатации. Регулярное применение состязательного обучения в процессе мониторинга позволяет своевременно выявлять и устранять уязвимости, связанные с манипуляциями входными данными.
Использование временной памяти сессии (Ephemeral Session Memory) существенно снижает риски, связанные с хранением и потенциальной утечкой данных в системах, основанных на больших языковых моделях (LLM). Вместо сохранения данных пользовательских взаимодействий на постоянных носителях, информация обрабатывается и используется исключительно в рамках текущей сессии. После завершения сессии данные не сохраняются, что исключает возможность их компрометации в случае взлома системы или несанкционированного доступа. Такой подход минимизирует поверхность атаки и соответствует принципам конфиденциальности данных, особенно в контексте обработки персональной информации и соответствия требованиям регуляторов.
Панели управления для родителей и опекунов предоставляют инструменты для мониторинга и контроля взаимодействия детей с приложениями на основе больших языковых моделей (LLM). Эти панели обеспечивают доступ к истории запросов и ответов, позволяя родителям оценивать содержание и выявлять потенциально нежелательный контент или поведение. Функционал часто включает в себя фильтрацию контента, установку ограничений на темы обсуждения, а также возможность блокировки или сообщения о неприемлемых взаимодействиях. Реализация таких панелей позволяет родителям активно участвовать в цифровом опыте своих детей и обеспечивать соответствие контента возрастным ограничениям и семейным ценностям.
Механизмы проверки возраста имеют решающее значение для ограничения доступа к контенту, не соответствующему возрасту пользователя, и обеспечения соответствия нормативным требованиям, таким как COPPA (Children’s Online Privacy Protection Act). Предлагаемая в рамках исследования комплексная структура сопоставляет принципы конфиденциальности по умолчанию (privacy-by-design) с жизненным циклом приложений на основе больших языковых моделей (LLM). Данная структура охватывает все этапы — от разработки и внедрения до эксплуатации и вывода из эксплуатации — и определяет конкретные меры по защите данных несовершеннолетних, включая методы верификации возраста, управление согласием на обработку данных и обеспечение прозрачности в отношении использования информации. Реализация предложенного подхода позволяет разработчикам создавать LLM-приложения, соответствующие законодательным требованиям и обеспечивающие безопасность детей в цифровой среде.
Влияние на ответственное развитие LLM
Соблюдение принципов конфиденциальности на протяжении всего жизненного цикла больших языковых моделей (LLM) является фундаментальным фактором для формирования доверия со стороны пользователей и содействия ответственному внедрению искусственного интеллекта. Уделение внимания защите персональных данных на этапах сбора, обработки и использования информации не только снижает риски нарушения прав граждан, но и создает позитивный имидж разработчиков и операторов LLM. Когда пользователи уверены в безопасности своих данных, они более охотно используют инновационные сервисы, основанные на этих моделях, что способствует более широкому и эффективному применению технологий искусственного интеллекта в различных сферах жизни. Игнорирование принципов конфиденциальности, напротив, может привести к потере доверия, юридическим последствиям и замедлению темпов развития этой перспективной области.
Соблюдение нормативных актов, таких как GDPR, COPPA и PIPEDA, представляется не просто формальным требованием закона, а фундаментальным этическим принципом в контексте разработки и применения больших языковых моделей. Эти законы, направленные на защиту персональных данных, отражают общественное признание ценности личной информации и необходимости её бережного обращения. Игнорирование этих норм подрывает доверие пользователей, создаёт риски для их приватности и может привести к серьёзным последствиям, как юридическим, так и репутационным. Таким образом, приверженность этим стандартам является неотъемлемой частью ответственной разработки искусственного интеллекта и демонстрирует уважение к правам и свободам каждого человека.
Подход “конфиденциальность по замыслу” является ключевым для снижения рисков и защиты конфиденциальных данных в приложениях, использующих большие языковые модели (LLM). Вместо того, чтобы рассматривать защиту данных как последующую меру, данный подход интегрирует принципы конфиденциальности на всех этапах разработки — от проектирования архитектуры модели и выбора обучающих данных до внедрения и постоянного мониторинга. Это включает в себя минимизацию собираемых данных, использование методов дифференциальной конфиденциальности для защиты персональной информации, а также разработку строгих протоколов доступа и шифрования. Реализация принципов “конфиденциальность по замыслу” позволяет не только соблюдать нормативные требования, но и укреплять доверие пользователей к технологиям искусственного интеллекта, создавая более безопасную и этичную цифровую среду.
Приоритет конфиденциальности и безопасности открывает путь к полному раскрытию потенциала больших языковых моделей, одновременно защищая права личности. Данная работа представляет собой комплексную структуру для достижения этой цели, предлагая действенные механизмы контроля, направленные на усиление защиты данных и обеспечение соответствия нормативным требованиям. Реализация предложенного подхода позволяет не только минимизировать риски, связанные с обработкой чувствительной информации, но и создать доверие пользователей к системам искусственного интеллекта, что является ключевым фактором для широкого и ответственного внедрения подобных технологий в различных сферах жизни.
Статья предлагает рассматривать разработку больших языковых моделей для детей не как последовательность технических задач, а как создание сложной экосистемы, где каждый компонент влияет на целостность и безопасность данных. Принципы Privacy by Design, интегрированные в жизненный цикл LLM, — это не просто соответствие нормативным требованиям, а попытка предвидеть и смягчить потенциальные риски, возникающие в процессе взаимодействия с уязвимой аудиторией. Как однажды заметил Роберт Таржан: «Программы должны быть достаточно просты, чтобы их можно было понять, достаточно мощными, чтобы их можно было использовать, и достаточно гибкими, чтобы их можно было изменить». Эта фраза отражает суть подхода, предложенного в статье: создание адаптивной системы, способной эволюционировать вместе с меняющимися потребностями и угрозами в сфере защиты данных детей.
Что дальше?
Предложенная структура, конечно, выглядит аккуратно на бумаге. Но каждый деплой — маленький апокалипсис, и иллюзия контроля над жизненным циклом большой языковой модели тает быстрее, чем надежды на исчерпывающую документацию. Защита данных детей — это не просто соответствие регуляторным требованиям, это признание принципиальной непредсказуемости систем, которые мы пытаемся обуздать. Каждое архитектурное решение — это пророчество о будущей уязвимости, и данная работа лишь формализует этот процесс.
Следующим шагом видится не столько усовершенствование фреймворков, сколько признание их временности. Необходимо сместить фокус с проектирования «безопасности» на создание механизмов быстрой адаптации к неизбежным сбоям. Адаптивное управление рисками, основанное на постоянном мониторинге и прогнозировании, представляется более реалистичным подходом, чем попытки построить непробиваемую крепость.
В конечном итоге, вопрос не в том, как спроектировать идеальную систему защиты данных, а в том, как научиться жить с её несовершенством. Никто не пишет пророчества после их исполнения, и данная работа, как и любая другая, — лишь временная зарисовка на пути к неизбежному хаосу.
Оригинал статьи: https://arxiv.org/pdf/2602.17418.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сверхпроводящая логика: управление магнитным полем
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Квантовые смеси: от капель жидкости до сверхтекучих кристаллов
- Квантовый взрыв: Разговор о голосах и перспективах
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Квантовый скачок через SPAC: Анализ рынка и физика надежды
- Волшебство по запросу: ИИ создает заклинания в игре
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
2026-02-22 22:46