Автор: Денис Аветисян
Новая модель AudioChat объединяет возможности больших языковых моделей и генеративных сетей для создания, редактирования и понимания сложных аудио-повествований.

Представлена мультимодальная основа, использующая диффузионные модели и логические цепочки для обработки и генерации аудиоконтента.
Несмотря на значительный прогресс в области обработки звука, современные модели испытывают трудности при работе со сложными многокомпонентными аудиосценами. В данной работе, представленной под названием ‘AudioChat: Unified Audio Storytelling, Editing, and Understanding with Transfusion Forcing’, предлагается новый фреймворк для создания фундаментальных моделей, способных генерировать, редактировать и понимать аудиоистории. Ключевым нововведением является использование LLM-агентов, моделирующих взаимодействие пользователя с системой, и оригинальный метод обучения — Audio Transfusion Forcing, позволяющий одновременно выполнять декомпозицию высокоуровневых инструкций и интерактивное многооборотное понимание/генерацию звука. Сможет ли предложенный подход открыть новые возможности для создания более естественных и интерактивных аудиосистем?
За гранью речи: Понимание аудио в целом
Традиционные методы обработки звука зачастую концентрируются на изолированном анализе отдельных компонентов — речи, музыки, шумов — упуская из виду целостность звуковой картины и контекст, в котором эти элементы взаимодействуют. Такой подход не позволяет полностью понять смысл и эмоциональную окраску аудиозаписи, поскольку игнорируется взаимосвязь между звуками, их последовательность и влияние на общее восприятие. В результате, анализ отдельных фрагментов не дает возможности воссоздать полное представление о происходящем в звуковой сцене, лишая слушателя возможности ощутить всю глубину и нюансы повествуемого, что особенно критично для сложных аудиорассказов и реалистичных звуковых ландшафтов.
Существующие методы обработки звука часто оказываются неэффективными при анализе сложных звуковых сцен, где одновременно взаимодействуют несколько источников. Проблема заключается в том, что традиционные алгоритмы, как правило, фокусируются на выделении отдельных звуковых событий, игнорируя контекст и взаимосвязи между ними. Например, при анализе записи городского шума, сложно отделить речь одного конкретного человека от общего гула транспорта и разговоров, особенно если речь зашумлена или перекрывается другими звуками. Это затрудняет понимание не только содержания речи, но и общей картины происходящего, лишая возможность распознать эмоциональную окраску, намерения говорящего или даже определить, является ли звук частью сложного повествования. Подобные ограничения существенно снижают эффективность систем распознавания речи, анализа звуковых событий и, в конечном итоге, препятствуют созданию действительно интеллектуальных аудиосистем.
Необходимость создания единой модели для обработки звука обусловлена сложностью полного восприятия аудиоопыта. Традиционные методы, как правило, анализируют отдельные звуковые элементы, упуская контекст и взаимосвязи, которые формируют целостную звуковую картину. Разработка такой модели позволит не просто понимать содержание аудиозаписи, но и генерировать новые звуковые последовательности, а также редактировать существующие с сохранением их смысловой нагрузки и эмоционального окраса. Это откроет возможности для создания более реалистичных и захватывающих звуковых ландшафтов, а также для разработки интеллектуальных систем, способных к творческой обработке звука и адаптации к потребностям пользователя. Подобный подход позволит преодолеть разрыв между анализом, синтезом и модификацией звука, создавая единую платформу для работы со звуковыми данными.
AudioChat: Основа для повествования в аудио
AudioChat представляет собой мультимодальную модель, способную к генерации, редактированию и пониманию сложных аудио-историй. Это достигается за счет интеграции различных типов данных, включая аудиосигналы и текстовые описания, что позволяет модели не только создавать новые аудиоматериалы, но и модифицировать существующие, а также анализировать их содержание и структуру. Функциональность модели охватывает широкий спектр задач, включая создание повествований, добавление звуковых эффектов, изменение голосов и адаптацию аудиоконтента к различным сценариям и потребностям пользователей.
Ключевым компонентом системы является Self-Cascaded Transformer, архитектура, предназначенная для последовательной обработки аудиоинформации. В отличие от традиционных трансформеров, обрабатывающих весь аудиосигнал одновременно, Self-Cascaded Transformer разбивает аудиопоток на последовательные сегменты и обрабатывает их итеративно. На каждом этапе обработки модель использует информацию, полученную на предыдущих этапах, для построения более полного и контекстуально-обогащенного представления аудиоданных. Этот каскадный подход позволяет модели эффективно учитывать временные зависимости в аудиосигнале и формировать комплексное понимание его содержания, необходимое для задач генерации, редактирования и анализа аудиоисторий.
В системе AudioChat для преобразования необработанных аудиосигналов в формат, пригодный для глубокого обучения, используется непрерывный аудио-токенизатор. Этот токенизатор осуществляет дискретизацию аудиосигнала, представляя его в виде последовательности дискретных токенов, что позволяет модели эффективно обрабатывать и анализировать аудиоданные. В отличие от традиционных методов, основанных на фиксированных кадрах, непрерывный токенизатор обеспечивает более плавное и точное представление аудио, сохраняя важные временные характеристики и улучшая качество последующей обработки и генерации звука. Такой подход позволяет модели работать с аудиоданными как с последовательностью символов, аналогично обработке текста в задачах обработки естественного языка.
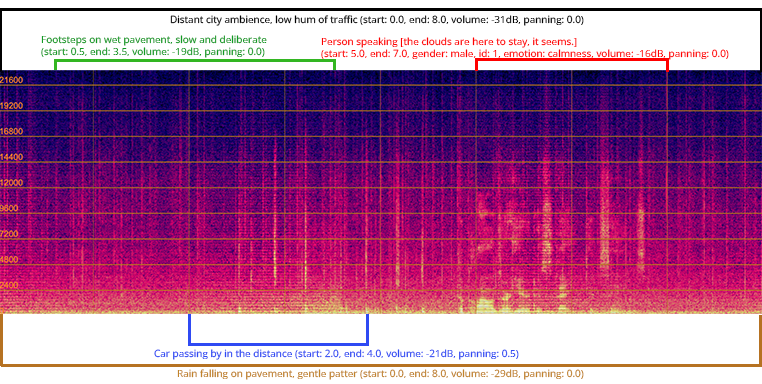
Сила принудительной диффузии аудио
Метод Audio Transfusion Forcing использует комбинацию большой языковой модели (Large Language Model) и диффузионной модели (Diffusion Model) для повышения качества генерируемого звука. Большая языковая модель отвечает за планирование и структурирование звукового контента, определяя последовательность событий и характеристики звуков. Диффузионная модель, в свою очередь, преобразует эти абстрактные представления в фактические звуковые волны, обеспечивая реалистичность и детализацию. Совместное использование этих двух типов моделей позволяет преодолеть ограничения, присущие каждому из них при отдельном использовании, и генерировать более связный и качественный аудиоматериал.
Метод использует структурированное цепочечное рассуждение (Structured Chain-of-Thought Reasoning), которое позволяет декомпозировать сложные задачи генерации аудио на более простые, последовательно решаемые компоненты. Этот подход предполагает разделение исходной задачи на ряд промежуточных шагов, каждый из которых обрабатывается отдельно. В контексте генерации аудио это может включать, например, определение общей структуры повествования, создание отдельных звуковых сцен, генерацию конкретных звуковых эффектов и, наконец, их объединение в единый аудиопоток. Разбиение сложной задачи на управляемые компоненты значительно повышает качество и когерентность генерируемого аудиоматериала, упрощая процесс обучения и контроля.
Комбинирование методов Audio Transfusion Forcing позволяет создавать более связные и реалистичные аудио-повествования. Используя возможности больших языковых моделей (LLM) и диффузионных моделей в сочетании со структурированным логическим мышлением (Structured Chain-of-Thought Reasoning), система разбивает сложные задачи генерации звука на последовательность управляемых этапов. Это обеспечивает последовательность и логическую связь между отдельными звуковыми элементами, что приводит к более правдоподобному и естественному звучанию генерируемых аудио-историй. Подобный подход повышает когерентность и качество звукового контента по сравнению с традиционными методами генерации.
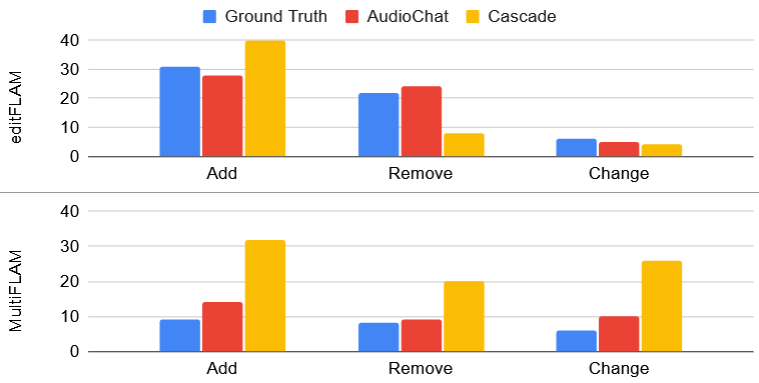
Количественная оценка качества аудио: Метрики успеха
Многомерная метрика MultiFLAM призвана оценить, насколько сгенерированный звук соответствует заданным семантическим элементам и смысловому содержанию. Исследования показали, что MultiFLAM достигает показателя 0.88, что свидетельствует о высокой степени соответствия между сгенерированным аудио и желаемыми характеристиками. Этот результат сопоставим с показателем, полученным для модели Whisper-Story (0.86), что подтверждает эффективность MultiFLAM в оценке семантической согласованности и ее потенциал для улучшения качества генерируемого звука. Подобная количественная оценка позволяет более точно оценивать и совершенствовать алгоритмы синтеза речи и создания звуковых эффектов.
Метод DeltaMultiFLAM разработан для оценки сохранения целостности аудиозаписи после редактирования. Он позволяет количественно измерить, насколько сильно отредактированный фрагмент отличается от исходного, выявляя возможные искажения или потери качества. В отличие от простых сравнений сигналов, DeltaMultiFLAM анализирует семантическое соответствие, то есть, насколько сохранен смысл и содержание аудио после внесения изменений. Высокие показатели DeltaMultiFLAM свидетельствуют о том, что редактирование было выполнено аккуратно и не привело к существенным отклонениям от первоначального звучания, что критически важно для сохранения качества и достоверности аудиоматериалов.
EditFLAM представляет собой метрику, разработанную для точной оценки успешности операций редактирования аудио. В отличие от общих показателей качества звука, EditFLAM фокусируется непосредственно на проверке соответствия между внесенными изменениями и исходными инструкциями. Этот подход позволяет количественно оценить, насколько точно выполнены запрошенные правки — например, удаление определенных фрагментов, изменение громкости или добавление новых звуковых элементов. Высокий показатель EditFLAM свидетельствует о том, что система редактирования аудио эффективно интерпретирует и реализует указанные требования, обеспечивая желаемый результат и минимизируя ошибки при обработке звука.
Исследования показали значительное превосходство системы AudioChat в понимании аудио-историй по сравнению с WhisperX. В ходе тестирования AudioChat продемонстрировал показатель tcpWER (текстовой ошибки распознавания речи) всего 9.7, что свидетельствует о высокой точности транскрипции и интерпретации аудио-контента. Для сравнения, WhisperX показал значительно худший результат — 55.9. Такое существенное различие указывает на более эффективные алгоритмы обработки звука и понимания контекста, реализованные в AudioChat, что делает ее перспективным инструментом для задач, связанных с анализом и обработкой аудио-информации.
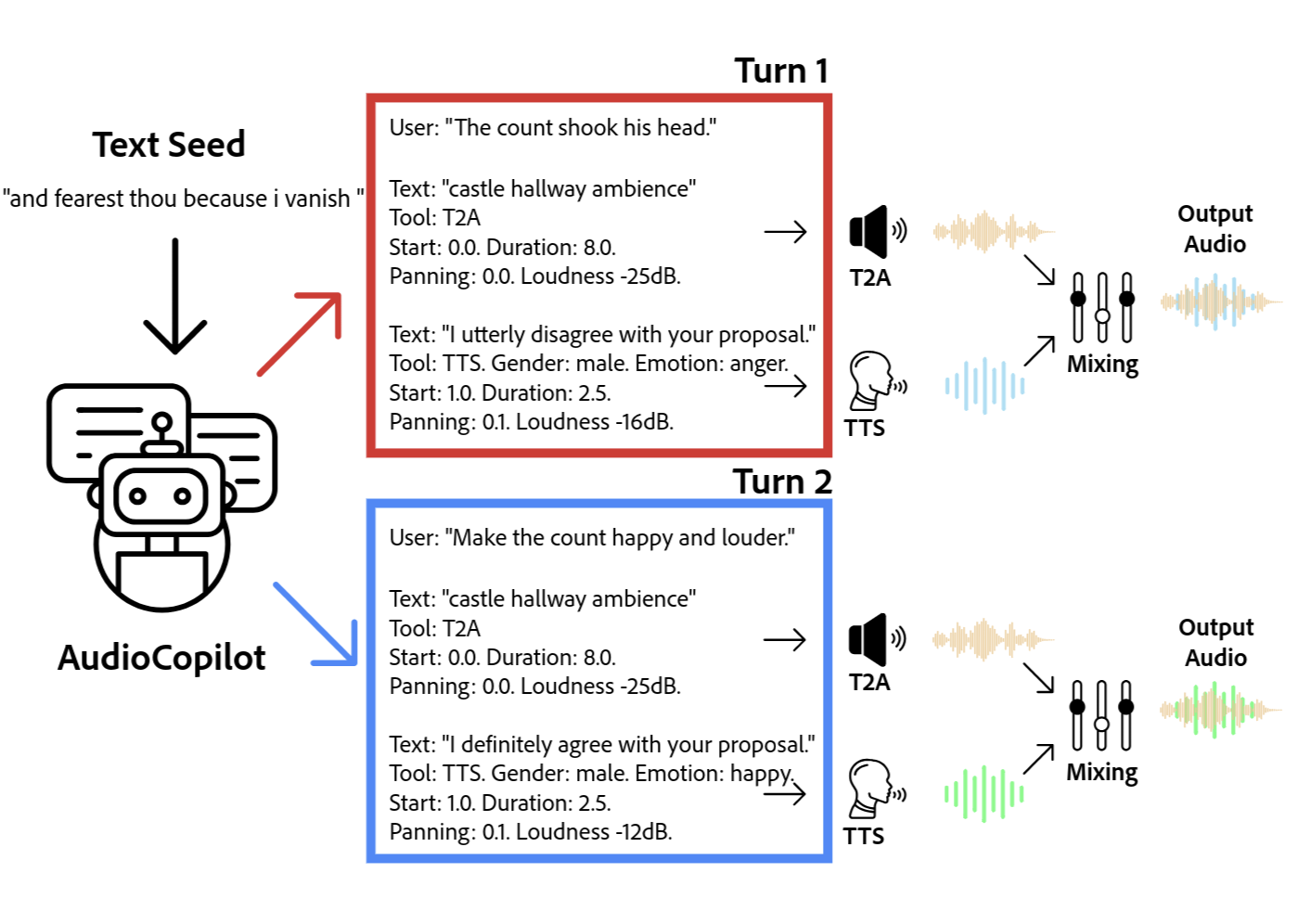
Масштабирование креативности: К интеллектуальным аудиоинструментам
Система AudioCopilot, работающая на базе AudioChat, представляет собой значительный прорыв в области создания аудио-контента, позволяя масштабировать процесс синтеза данных для повествовательных аудио-историй. Вместо трудоемкого ручного подбора и редактирования звуковых элементов, AudioCopilot автоматизирует значительную часть работы, существенно снижая временные и ресурсные затраты. Это достигается благодаря способности AudioChat генерировать и адаптировать аудиоматериалы на основе текстовых инструкций, что позволяет создавать сложные и детализированные звуковые ландшафты с минимальным вмешательством человека. В результате, создатели аудио-контента получают инструмент, который не только ускоряет процесс производства, но и открывает новые возможности для экспериментов и творческой реализации.
Интегрированная система, лежащая в основе AudioCopilot, обладает широкими возможностями благодаря поддержке как синтеза звука из текста (text-to-audio), так и преобразования текста в речь (text-to-speech). Это позволяет значительно расширить область применения разработки, охватывая не только создание звуковых эффектов и музыкального сопровождения, но и озвучивание повествований, автоматизированное чтение книг или создание голосовых помощников. Сочетание этих двух функций открывает путь к разработке интеллектуальных аудиоинструментов, способных адаптироваться к различным творческим задачам и предоставлять пользователям гибкий контроль над звуковым контентом, упрощая и ускоряя процесс создания иммерсивных аудиоопытов.
Исследования показали, что система AudioChat демонстрирует значительное превосходство в скорости создания аудиоповествований по сравнению с существующими решениями, такими как WavJourney. В частности, AudioChat способен генерировать аудиоматериал в 20 раз быстрее, что открывает новые возможности для автоматизации и масштабирования процесса создания звукового контента. Эта повышенная скорость позволяет значительно сократить время, необходимое для разработки аудиоисторий, и предоставляет создателям больше возможностей для экспериментов и итераций, что в конечном итоге приводит к более качественным и увлекательным звуковым произведениям. Подобная эффективность может кардинально изменить подход к созданию аудиоконтента, делая его более доступным и экономичным.
Разработанная платформа открывает новые горизонты для создания интеллектуальных инструментов, способных оказать существенную поддержку авторам в процессе разработки захватывающих и реалистичных аудио-проектов. Данный подход позволяет не просто генерировать аудио-контент, но и активно участвовать в формировании повествования, адаптируясь к творческим задачам и предлагая решения для достижения максимального эффекта погружения. В перспективе, подобные системы способны значительно ускорить и упростить процесс создания аудиокниг, подкастов, интерактивных аудио-игр и других мультимедийных продуктов, предоставляя авторам возможность сосредоточиться на художественной составляющей, а не на технических сложностях.
В очередной раз наблюдается стремление к созданию универсальных моделей, способных охватить сразу несколько задач. AudioChat, с его объединением генерации, редактирования и понимания аудио, — закономерный шаг в этом направлении. Однако, как показывает практика, попытки создать «швейцарский нож» часто приводят к громоздким и сложным системам. Удивительно, но несмотря на всю мощь и элегантность предлагаемого подхода с использованием diffusion models и chain-of-thought reasoning, вероятность появления новых проблем в процессе эксплуатации остаётся высокой. Как однажды заметил Винтон Серф: «Интернет — это не только технологии, но и люди». И именно человеческий фактор, склонность к упрощениям и непредсказуемым сценариям использования, в конечном итоге определяет судьбу любой, даже самой перспективной разработки.
Что Дальше?
Представленная работа, безусловно, демонстрирует очередную ступень в бесконечном стремлении научить машину рассказывать истории. Или, точнее, генерировать последовательности звуков, которые люди интерпретируют как истории. Однако, за элегантностью архитектуры AudioChat скрывается неизбежный факт: любые «революционные» модели рано или поздно столкнутся с жестокой реальностью продакшена. Качество сгенерированных историй, несомненно, будет оцениваться не алгоритмами, а уставшими менеджерами, которым нужно «запустить уже хоть что-нибудь» к концу квартала.
Следующим этапом, вероятно, станет борьба с неизбежными артефактами и галлюцинациями. Не стоит забывать, что даже самые сложные модели склонны к креативным выдумкам, которые в контексте повествования могут оказаться…неуместными. И вопрос не в улучшении алгоритмов диффузии или увеличении размера языковой модели, а в разработке способов автоматического обнаружения и исправления этих неточностей — задачи, которая, скорее всего, потребует участия живых редакторов, что, конечно, противоречит самой идее полной автоматизации.
В конечном счете, AudioChat — это ещё один шаг к созданию цифрового рассказчика. Но не стоит забывать, что настоящая магия историй заключается не в техническом совершенстве, а в способности вызывать эмоции и резонировать с человеческим опытом. И эту способность, боится, никакая модель пока не в состоянии воспроизвести. Тесты, как известно, — это форма надежды, а не уверенности.
Оригинал статьи: https://arxiv.org/pdf/2602.17097.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Распознавание смыслов: новый подход к классификации документов
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сверхпроводящая логика: управление магнитным полем
- Квантовый скачок в многомасштабном моделировании
- От миллиметровых волн к кубитному управлению: единый подход
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Звук как помощник зрения: Новые горизонты генерации видео
- Тонкости настройки: как научить нейросети понимать сложные предпочтения
- Ожившие Истории: Искусственный Интеллект, Создающий и Редактирующий Аудио
2026-02-23 05:21