Автор: Денис Аветисян
Новая библиотека `softdtw-cuda-torch` позволяет эффективно работать с Soft-DTW, преодолевая ограничения по памяти и длине последовательностей.
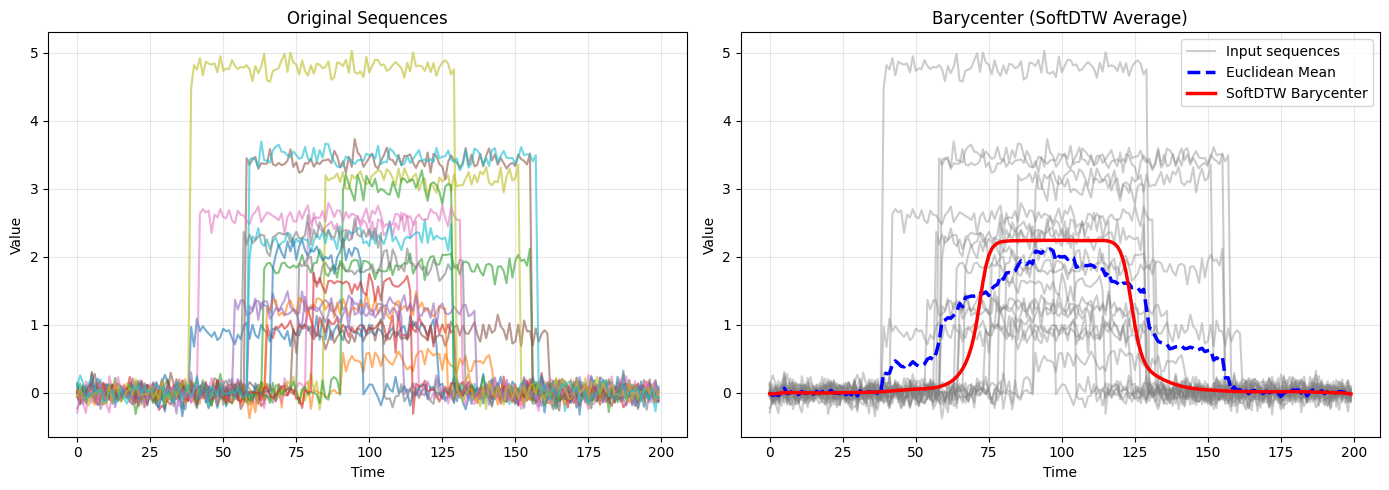
Реализация обеспечивает масштабируемое и дифференцируемое вычисление Soft-DTW с использованием CUDA и PyTorch.
Несмотря на растущую популярность динамического выравнивания временных рядов (DTW) в задачах анализа последовательностей, стандартные реализации Soft-DTW часто сталкиваются с ограничениями по объему памяти и вычислительной эффективности. В данной работе представлена библиотека ‘SoftDTW-CUDA-Torch: Memory-Efficient GPU-Accelerated Soft Dynamic Time Warping for PyTorch’, предназначенная для ускорения вычислений Soft-DTW на графических процессорах (GPU) и преодоления существующих ограничений, таких как фиксированная длина последовательности и нестабильность при малых значениях сглаживания. Предложенные оптимизации, включающие параллельное выполнение операций и слияние вычислений, позволяют снизить потребление памяти до 98% и обеспечить поддержку произвольной длины последовательностей. Каковы перспективы применения разработанной библиотеки в задачах обработки звука, анализа биосигналов и других областях, требующих эффективного выравнивания временных рядов?
За пределами классического выравнивания: Представляем Soft-DTW
Традиционный алгоритм динамического выравнивания во времени (DTW) зарекомендовал себя как эффективный инструмент для сопоставления последовательностей различной длины, находя оптимальное соответствие между элементами. Однако, ключевым ограничением DTW является его недифференцируемость. Это означает, что нельзя вычислить градиент функции потерь относительно входных данных, что делает невозможным использование DTW непосредственно в современных нейронных сетях, требующих градиентного спуска для обучения. В то время как нейронные сети преуспевают в задачах, требующих дифференцируемых операций, DTW, основанный на дискретных операциях выбора минимального значения, не позволяет эффективно обновлять параметры модели на основе ошибки. Эта проблема существенно ограничивает применение DTW в контексте глубокого обучения и стимулирует поиск альтернативных, дифференцируемых подходов к выравниванию последовательностей.
Для преодоления ограничений классического динамического выравнивания по времени (DTW), связанного с отсутствием дифференцируемости, предложен метод Soft-DTW. Он представляет собой дифференцируемую релаксацию рекуррентного алгоритма DTW, что позволяет использовать градиентный спуск для оптимизации. В отличие от традиционного DTW, который оперирует с жесткими минимумами при вычислении матрицы расстояний, Soft-DTW заменяет их на «мягкие» минимумы, позволяя градиентам распространяться через процесс выравнивания. Это достигается путем введения параметра температуры γ, который контролирует степень «сглаживания» матрицы расстояний и, следовательно, влияет на плавность процесса выравнивания последовательностей. Благодаря этому, Soft-DTW обеспечивает возможность обучения моделей, использующих выравнивание последовательностей, в рамках современных нейронных сетей, что ранее было недоступно из-за недифференцируемости стандартного DTW.
Для преодоления недифференцируемости классического динамического выравнивания по времени (DTW) предложен метод Soft-DTW, использующий релаксацию рекуррентного процесса. Ключевым элементом данной релаксации является замена операции взятия минимума на «мягкий минимум», регулируемый параметром температуры γ. Этот параметр позволяет контролировать степень «размытости» выравнивания: при малых значениях γ Soft-DTW приближается к жесткому DTW, точно определяя соответствия между элементами последовательностей, в то время как при больших значениях достигается более плавное и устойчивое к шуму выравнивание. Таким образом, параметр температуры выступает в роли регулятора, позволяющего адаптировать Soft-DTW к различным характеристикам данных и задачам оптимизации, делая его пригодным для использования в современных нейронных сетях.
Ускорение Soft-DTW: GPU-реализация
Практическое применение алгоритма Soft-DTW требует значительных вычислительных ресурсов, особенно при работе с большими наборами данных. Для обеспечения приемлемой производительности необходимо использование аппаратного ускорения, которое достигается посредством реализации на графических процессорах (GPU). В данной работе используется фреймворк PyTorch в сочетании с CUDA для реализации Soft-DTW на GPU. Это позволяет эффективно распараллеливать вычисления и значительно сократить время обработки по сравнению с CPU-реализациями. Использование CUDA обеспечивает низкоуровневый доступ к возможностям GPU, что критически важно для оптимизации производительности и снижения задержек.
Для повышения производительности Soft-DTW на GPU реализованы две ключевые оптимизации. Первая — “Fused Distance Computation”, объединяющая вычисление расстояния и экспоненциальную функцию в единую операцию, что значительно снижает количество операций чтения/записи из глобальной памяти. Вторая — “Anti-Diagonal Parallelization”, использующая особенности структуры матрицы расстояний для распараллеливания вычислений по антидиагоналям. Этот подход позволяет эффективно использовать потоковую архитектуру GPU, максимизируя пропускную способность и уменьшая время вычислений D(x, y), где D — матрица расстояний, а x и y — входные последовательности.
Для обеспечения численной устойчивости при вычислении градиентов в Soft-DTW используется механизм “Log-Space Backward Pass”, заключающийся в выполнении операций в логарифмической области во время обратного распространения ошибки. Это позволяет избежать проблем, связанных с переполнением или исчезновением значений при экспоненцировании малых или больших расстояний, возникающих в процессе вычисления Soft-DTW. Вместо непосредственного вычисления exp(-distance), вычисляется log(exp(-distance)) = -distance, что упрощает вычисления и повышает точность градиентов, особенно при работе с длинными временными рядами и большими значениями расстояний. Использование логарифмической области позволяет сохранить числовую стабильность и избежать потери информации при вычислении градиентов.
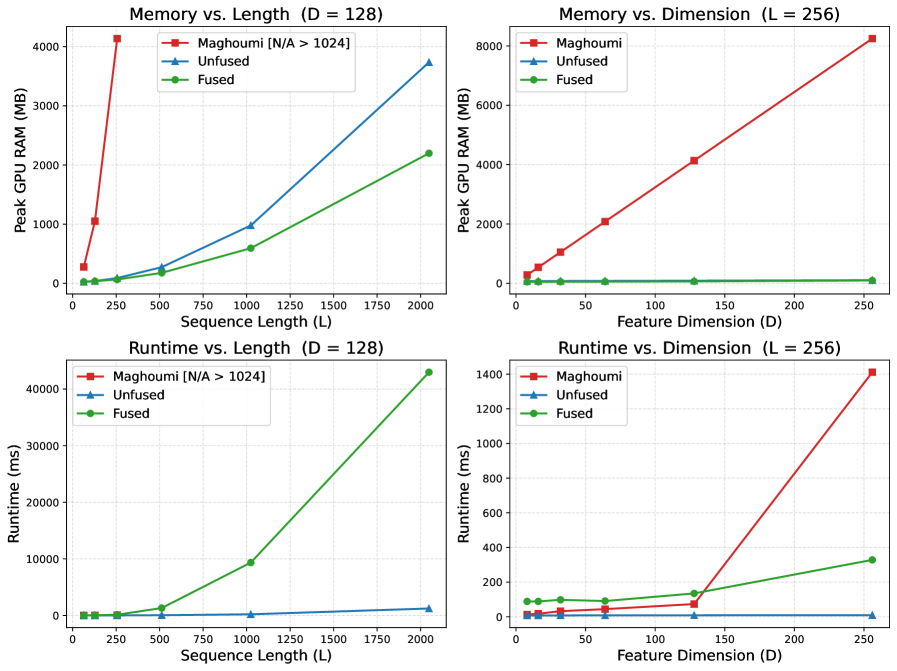
Доказательство эффективности: Производительность и масштабируемость
Внедрение GPU-ускорения значительно сокращает фактическое время выполнения (Wall-Clock Runtime) по сравнению с CPU-реализациями, особенно при обработке длинных последовательностей и данных с высокой размерностью признаков (Feature Dimension). Наблюдаемое ускорение обусловлено параллельной обработкой данных на GPU, что позволяет эффективно использовать вычислительные ресурсы для операций, требующих больших объемов вычислений. В частности, при увеличении длины последовательности и размерности признаков, выигрыш от использования GPU становится более существенным, так как CPU-реализации испытывают значительные задержки из-за последовательной обработки данных.
Предыдущая реализация накладывала ограничение на длину последовательности в 1024 элемента. Новая реализация устраняет данное ограничение, позволяя обрабатывать последовательности длиной более 1024 элементов. Это достигнуто путем изменения архитектуры обработки данных и оптимизации алгоритмов, что позволяет эффективно использовать память и вычислительные ресурсы для обработки последовательностей произвольной длины. Отсутствие ограничения на длину последовательности расширяет область применения алгоритма для анализа данных, требующих обработки длинных временных рядов или других последовательностей.
Режим «fused» позволяет снизить потребление памяти GPU до 98% по сравнению с предыдущей реализацией. Это достигается за счет объединения нескольких операций в одну, что уменьшает необходимость хранения промежуточных результатов. Однако, данная оптимизация влечет за собой увеличение времени выполнения в 10-15 раз. Причина заключается в том, что объединенные операции требуют больше вычислительных ресурсов для выполнения за один проход, несмотря на снижение объема используемой памяти. Таким образом, выбор между режимами работы зависит от приоритетов: снижение потребления памяти или минимальное время выполнения.
Эффективность работы реализации напрямую зависит от таких параметров, как размер пакета (Batch Size), длина последовательности (Sequence Length) и объем доступной памяти GPU. Увеличение размера пакета может повысить пропускную способность, но требует больше памяти GPU. Более длинные последовательности увеличивают вычислительную нагрузку и также требуют больше памяти. Ограниченный объем памяти GPU может стать узким местом, приводящим к ошибкам нехватки памяти или снижению производительности. Для достижения оптимальных результатов необходима тщательная настройка этих параметров с учетом конкретных аппаратных ресурсов и характеристик обрабатываемых данных. Неправильная конфигурация может привести к значительному снижению производительности или невозможности обработки данных.
Реализация поддерживает эффективное вычисление барицентров, позволяя находить средние значения коллекций временных рядов в пространстве DTW (Dynamic Time Warping). Данная функциональность реализуется путем вычисления взвешенного среднего DTW-представлений отдельных временных рядов, где веса могут быть заданы пользователем или вычислены автоматически. Это позволяет получить репрезентативный временной ряд, характеризующий всю коллекцию, и упрощает анализ больших объемов данных. Вычисление барицентров оптимизировано для работы с большими коллекциями временных рядов и обеспечивает высокую производительность благодаря использованию GPU-ускорений.
Расширяя горизонты: Приложения и будущие направления
Оптимизированная реализация значительно расширяет возможности применения алгоритма Soft-DTW в рамках ‘Diffeomorphic Temporal Alignment Networks’ (DTAN). DTAN, предназначенные для моделирования сложных временных зависимостей, часто сталкиваются с вычислительными ограничениями при работе с длинными последовательностями. Благодаря ускоренной обработке Soft-DTW, DTAN способны более эффективно выравнивать и анализировать временные ряды, даже при наличии значительных искажений и нелинейных деформаций. Это позволяет значительно повысить точность моделирования в задачах, требующих понимания динамических изменений во времени, таких как распознавание речи, анализ биомедицинских сигналов и прогнозирование временных рядов, где критически важна способность сети улавливать тонкие взаимосвязи и деформации во временных данных.
Разработанная платформа обеспечивает поддержку расширений, в частности, алгоритма ‘Нормализованного Мягкого Динамического Временного Выравнивания’ (Normalized Soft-DTW). Данное расширение существенно повышает устойчивость и обобщающую способность системы при работе с данными, подверженными шумам или изменениям масштаба. В отличие от стандартного Soft-DTW, нормализованная версия учитывает различную длительность и интенсивность сигналов, что позволяет более эффективно сравнивать временные ряды с отличающимися характеристиками. Благодаря этому, система демонстрирует улучшенные результаты при анализе разнородных данных и адаптации к новым, ранее не встречавшимся условиям, что делает ее более надежной и универсальной в различных применениях.
Реализация с использованием ‘Numba CUDA’ открывает широкие возможности для дальнейшей оптимизации и кастомизации алгоритма. Данный подход позволяет значительно ускорить вычисления за счет параллельной обработки на графических процессорах, что особенно важно при работе с большими объемами временных рядов. Более того, ‘Numba CUDA’ предоставляет гибкий инструмент для адаптации алгоритма к специфическим требованиям различных аппаратных платформ и задач, позволяя исследователям и разработчикам точно настроить производительность и эффективность вычислений. Такая возможность тонкой настройки делает решение применимым в широком спектре областей, от биоинформатики и анализа медицинских данных до обработки сигналов и машинного обучения.
Разработка библиотеки `softdtw-cuda-torch` демонстрирует стремление к элегантности в решении сложной задачи выравнивания временных рядов. Авторы не просто оптимизировали существующий алгоритм, но и переосмыслили его, чтобы преодолеть ограничения памяти и обеспечить стабильность вычислений. Если система держится на костылях, значит, мы переусложнили её — и данная работа является ярким примером отказа от подобных решений в пользу более изящного подхода. Как заметил Г.Х. Харди: «Математика — это наука о том, что можно доказать». Подобно этому, надежная и масштабируемая реализация Soft-DTW требует строгого обоснования каждого шага и тщательной проработки деталей, чтобы гарантировать корректность и эффективность алгоритма.
Что Дальше?
Представленная работа, безусловно, снимает ряд насущных проблем, связанных с масштабируемостью и эффективностью алгоритма Soft-DTW в контексте современных вычислительных систем. Однако, стоит помнить старую истину: любая оптимизация — это лишь перенос узкого места. Уменьшение требований к памяти и повышение скорости вычислений — это хорошо, но это не отменяет фундаментальных ограничений, присущих самому принципу динамического выравнивания. Все ломается по границам ответственности — если их не видно, скоро будет больно. В данном случае, граница ответственности — это сложность вычислений, растущая нелинейно с длиной последовательностей.
Будущие исследования, вероятно, будут сосредоточены на разработке более адаптивных и приближенных алгоритмов, способных эффективно работать с действительно большими объемами данных. Интересным направлением представляется исследование возможности комбинирования Soft-DTW с другими методами понижения размерности и аппроксимации, что позволит снизить вычислительную сложность без существенной потери точности. Важно помнить, что структура определяет поведение — и необходимо разработать архитектуры, которые будут эффективно использовать преимущества параллельных вычислений и специализированного оборудования.
Наконец, не стоит забывать о вопросах интерпретируемости. Динамическое выравнивание позволяет находить соответствия между различными частями последовательностей, но часто эти соответствия остаются “черным ящиком”. Разработка методов визуализации и анализа этих соответствий позволит лучше понять лежащие в основе данные и принимать более обоснованные решения. Иначе, все усилия по оптимизации окажутся бессмысленными — ведь даже самая быстрая машина не сможет компенсировать отсутствие понимания.
Оригинал статьи: https://arxiv.org/pdf/2602.17206.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сверхпроводящая логика: управление магнитным полем
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Распознавание смыслов: новый подход к классификации документов
- Квантовый скачок в многомасштабном моделировании
- От миллиметровых волн к кубитному управлению: единый подход
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Коллективный разум нейросети: новый подход к решению сложных задач
- Нейронные сети: Архитектура как ключ к масштабируемости
- Квантовые смеси: от капель жидкости до сверхтекучих кристаллов
2026-02-23 05:27