Автор: Денис Аветисян
Новая разработка позволяет мобильным роботам самостоятельно переставлять предметы, ориентируясь исключительно на изображение с камеры, установленной на корпусе.
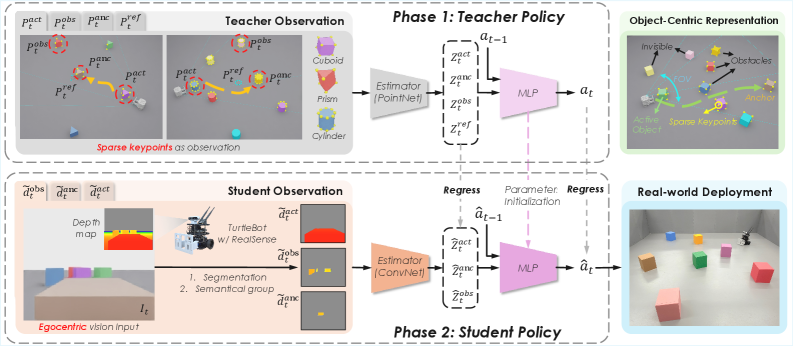
Предложен фреймворк EgoPush, использующий обучение с подкреплением, дистилляцию и объектно-центрированное представление для решения задач долгосрочного планирования и манипулирования объектами в условиях частичной наблюдаемости.
Несмотря на способность человека к манипулированию объектами в загроможденных пространствах, основанную на эгоцентричном восприятии, задача долгосрочной перестановки объектов для мобильных роботов остается сложной. В данной работе, представленной в статье ‘EgoPush: Learning End-to-End Egocentric Multi-Object Rearrangement for Mobile Robots’, предлагается фреймворк EgoPush, позволяющий мобильным роботам выполнять многоэтапную перестановку объектов, используя только эгоцентричное зрение. EgoPush сочетает в себе обучение с подкреплением, дистилляцию знаний и объектно-центрированное представление, что позволяет преодолеть проблемы частичной наблюдаемости и долгосрочного назначения вознаграждения. Сможет ли предложенный подход значительно улучшить автономность роботов в реальных условиях и открыть новые возможности для взаимодействия человека и робота?
Вызов Долгосрочного Планирования в Робототехнике
Традиционные подходы к управлению роботами зачастую опираются на заранее определенные планы или ограниченный горизонт планирования, что существенно затрудняет выполнение сложных, многоэтапных задач. Роботы, действующие по жесткому алгоритму, испытывают трудности при столкновении с непредвиденными обстоятельствами или в ситуациях, требующих адаптации к изменяющейся среде. В отличие от человеческой способности к импровизации и долгосрочному планированию, многие существующие системы робототехники не способны эффективно учитывать последствия своих действий на протяжении длительного времени, что ограничивает их возможности в реальных, неструктурированных условиях. Это особенно заметно при выполнении задач, требующих последовательного взаимодействия с несколькими объектами или решения проблем, возникающих в процессе выполнения.
Для успешного выполнения задач, связанных с перестановкой объектов в загроможденных пространствах, роботам необходима способность к рассуждению на протяжении длительных временных промежутков и адаптации к неожиданным изменениям обстановки. В отличие от традиционных подходов, ориентированных на краткосрочное планирование, подобный вид манипулирования требует от робота не просто следования заданному алгоритму, а предвидения возможных последствий своих действий и корректировки стратегии в реальном времени. Это подразумевает создание систем, способных учитывать не только текущее состояние окружения, но и вероятные изменения, вызванные взаимодействием с объектами, а также наличие непредсказуемых помех и препятствий. Таким образом, способность к долгосрочному планированию и адаптивности является ключевым фактором для создания действительно автономных и эффективных роботов-манипуляторов, способных решать сложные задачи в динамичных и непредсказуемых условиях.
Существующие методы манипулирования, такие как основанные на картах пространственных намерений, зачастую демонстрируют ограниченную эффективность в динамичных средах. Эти подходы полагаются на предварительно вычисленные планы, которые становятся неактуальными при малейших изменениях в окружении или появлении неожиданных препятствий. Предварительное планирование, хотя и эффективно в статичных условиях, не позволяет роботу гибко реагировать на непредвиденные обстоятельства, приводя к ошибкам и неудачам при выполнении задач. Неспособность адаптироваться к динамике окружающей среды ограничивает применимость этих методов в реальных сценариях, где изменения неизбежны, и требует разработки более робастных и адаптивных стратегий управления.

EgoPush: Система Визуальной Перестановки Объектов
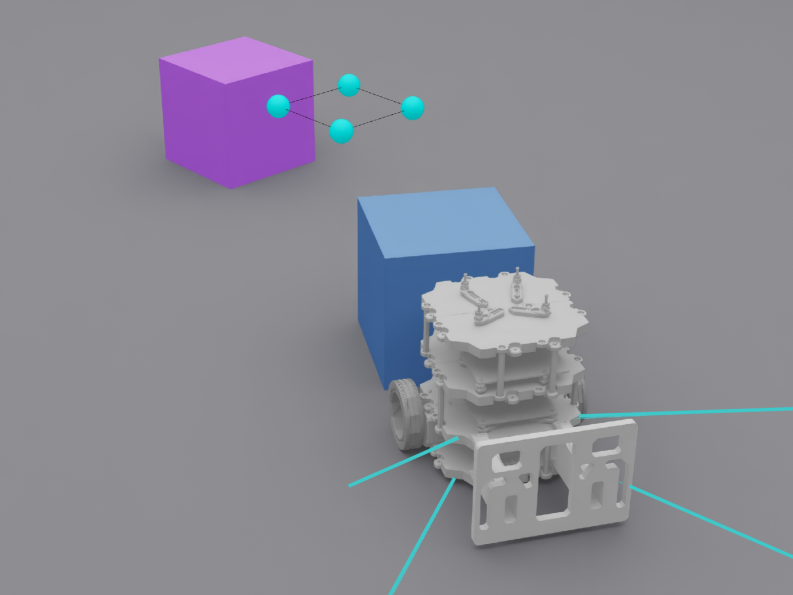
В системе EgoPush основным входным сигналом является визуальная информация, полученная с помощью `Эгоцентрического зрения`. Этот подход предполагает, что задача воспринимается и обрабатывается с точки зрения самого робота, что позволяет осуществлять обучение непосредственно на основе визуальных наблюдений. Вместо использования глобальной перспективы или карт окружения, EgoPush фокусируется на том, что робот «видит» непосредственно перед собой, что упрощает процесс обучения и повышает его эффективность за счет непосредственной связи между визуальным входом и действиями робота. Это позволяет роботу учиться взаимодействовать с объектами в окружающей среде, основываясь исключительно на информации, доступной в его поле зрения.
В основе EgoPush лежит архитектура «учитель-ученик», где «учитель» обучается стратегии (policy) при ограниченном наборе входных данных, имитирующих восприятие робота. «Ученик» в процессе обучения стремится воспроизвести поведение «учителя», что позволяет перенести навыки манипулирования объектами без необходимости прямого обучения «ученика» в сложной среде. Такой подход позволяет эффективно решать задачи визуальной перестановки объектов, используя знания, полученные «учителем» в контролируемых условиях, для обучения «ученика» более гибкому и адаптивному поведению.
Обучение политики учителя в EgoPush осуществляется посредством алгоритма обучения с подкреплением с ограничениями (Constrained Teacher RL). Данный подход предполагает ограничение входных данных учителя виртуальным эгоцентричным полем зрения, имитирующим перспективу робота. Для обеспечения пространственной осведомленности и снижения вычислительной сложности, в качестве входных признаков используются разреженные ключевые точки (Sparse Keypoints), выделяемые из визуального потока. Ограничение поля зрения и использование разреженных признаков позволяет учителю эффективно обучаться манипулированию объектами в условиях ограниченной информации, что, в свою очередь, способствует более эффективной передаче знаний студенческой политике.
Поэтапное Обучение и Проектирование Наград
Для повышения стабильности и эффективности обучения при решении задач с горизонтом планирования, мы используем поэтапное обучение (Stage-Wise Training). Этот подход заключается в декомпозиции сложной задачи на последовательность более простых, управляемых этапов. Разбиение на этапы позволяет агенту последовательно осваивать навыки, необходимые для достижения конечной цели, избегая проблем, связанных с разреженными наградами и сложностью долгосрочного планирования, характерными для задач с большим горизонтом. Обучение на каждом этапе фокусируется на локальной задаче, что упрощает процесс обучения и повышает скорость сходимости.
В процессе обучения используется механизм временного затухания (Temporal Decay), который предполагает снижение веса наград, получаемых на более поздних этапах обучения. Это позволяет сконцентрировать усилия агента на освоении начальных стадий задачи, обеспечивая более стабильное и эффективное обучение. Постепенное уменьшение значимости наград за поздние этапы способствует предотвращению преждевременной оптимизации и гарантирует, что агент сначала научится базовым навыкам, необходимым для успешного завершения всей последовательности действий. Эффективность данного подхода заключается в направленной оптимизации, где приоритет отдается последовательному освоению этапов, что в конечном итоге улучшает общую производительность и стабильность обучения.
Для повышения эффективности обучения и ускорения сходимости алгоритма используется система локальных наград за завершение этапов. Данная система предусматривает немедленное вознаграждение агента за успешное выполнение каждого отдельного этапа задачи, в отличие от отложенной награды за полное завершение всей последовательности действий. Такой подход позволяет агенту быстрее устанавливать связь между своими действиями и получаемым результатом на каждом шаге, что способствует более быстрому освоению требуемого поведения и улучшает стабильность процесса обучения.

Реляционная Дистилляция для Надежных Стратегий
Политика обучения, обозначенная как “EgoPush Student”, осваивает навыки посредством имитационного обучения, используя подход, основанный на “Relational Distillation Loss”. Данный механизм позволяет выстроить соответствие между реляционными структурами, используемыми учителем и студентом. Вместо простого копирования действий, студент учится понимать взаимосвязи между различными элементами окружающей среды и тем, как эти взаимосвязи влияют на эффективность действий. Это достигается путем анализа не только того, что делает учитель, но и почему он это делает в конкретных ситуациях, что позволяет студенту формировать более глубокое и обобщенное понимание задачи.
Обучение посредством имитации часто фокусируется на воспроизведении действий, однако данный подход демонстрирует, что понимание причин, лежащих в основе этих действий, критически важно для создания действительно надежной системы. Вместо простого копирования действий учителя, разработанный метод обеспечивает согласование реляционных структур между учителем и учеником. Это означает, что ученик не просто запоминает, что делать в конкретной ситуации, но и усваивает, почему это действие является эффективным, учитывая взаимосвязи между различными элементами окружающей среды. Такой подход позволяет ученику успешно адаптироваться к новым, ранее не встречавшимся сценариям и эффективно реагировать на изменения в окружении, значительно превосходя по своим возможностям системы, ориентированные исключительно на копирование действий.
Разработанная методика позволила создать устойчивую к изменениям политику управления, демонстрирующую впечатляющую способность к обобщению и адаптации к новым условиям. В ходе симуляций достигнута абсолютная эффективность — 100% успешных прохождений, а в реальных экспериментах зафиксирован значительный результат в 80%. Эти показатели существенно превосходят эффективность традиционных методов, не использующих реляционную дистилляцию, что особенно ярко проявилось при решении задачи Line-Shape, где новая политика продемонстрировала значительное улучшение производительности и надежности в различных, непредсказуемых ситуациях.
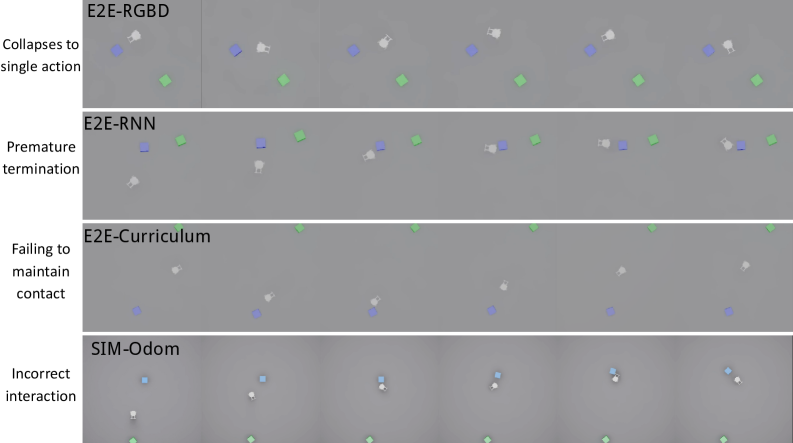
Исследование демонстрирует стремление к созданию систем, способных к долгосрочному планированию и манипулированию объектами исключительно на основе собственной перспективы. Этот подход, как и любое усложнение системы, требует предельной ясности в структуре и понимания взаимосвязей между элементами. Как однажды заметил Дональд Дэвис: «Простота — это высшая степень утонченности». В данном случае, стремление к созданию объектно-центрированных представлений и использование дистилляции знаний — это попытка избежать создания «костылей», поддерживающих сложную систему, и вместо этого выстроить элегантную и понятную структуру, где каждый элемент играет свою роль в достижении общей цели. Успех EgoPush зависит от четкого понимания контекста и модульности, а не от слепого добавления новых компонентов.
Что Дальше?
Представленная работа, безусловно, демонстрирует прогресс в обучении роботов манипулированию объектами в условиях ограниченной видимости. Однако, следует помнить: элегантный дизайн не терпит компромиссов с фундаментальными принципами. Успех EgoPush опирается на тщательно подобранные ограничения и объектно-ориентированное представление, что, по сути, является смещением сложности, а не её полным решением. Границы ответственности здесь чётко очерчены — система знает, что и где находится, но что произойдет, когда эти границы размоются, остается вопросом.
Наиболее вероятным направлением развития является преодоление зависимости от предопределенных объектов и сцен. Роботу необходимо научиться не просто перемещать известные предметы, но и понимать, что можно переместить, и зачем. Иными словами, требуется переход от пассивного распознавания к активному исследованию и построению моделей окружающего мира, что неизбежно потребует интеграции с более сложными системами планирования и принятия решений.
В конечном счете, долгосрочный успех в этой области будет зависеть не от улучшения алгоритмов обучения, а от способности создавать системы, устойчивые к неопределенности и способные адаптироваться к новым, непредвиденным ситуациям. Иначе, рано или поздно, что-то сломается — и произойдет это именно там, где не было предусмотрено запасного плана.
Оригинал статьи: https://arxiv.org/pdf/2602.18071.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сверхпроводящая логика: управление магнитным полем
- Распознавание смыслов: новый подход к классификации документов
- Квантовый скачок в многомасштабном моделировании
- От миллиметровых волн к кубитному управлению: единый подход
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Квантовые сети связи: оптимизация расписания для спутниковой передачи
- Батарея под контролем: Искусственный интеллект на страже долговечности
- Интеллектуальные агенты: как воплотить опыт экспертов в искусственный интеллект
2026-02-23 07:21