Автор: Денис Аветисян
Новое исследование показывает, что алгоритмы машинного обучения в материаловедении могут достигать высоких результатов, опираясь на случайные корреляции в данных, а не на реальные свойства материалов.

Модели машинного обучения часто используют данные о публикациях (авторы, журналы, годы) для предсказания свойств материалов, игнорируя фундаментальные характеристики.
Несмотря на впечатляющие успехи машинного обучения в ускорении открытия новых материалов, часто остается неясным, действительно ли модели усваивают фундаментальные химические принципы. В работе ‘Clever Materials: When Models Identify Good Materials for the Wrong Reasons’ показано, что высокая прогностическая способность моделей может быть обусловлена эксплуатацией скрытых корреляций в библиографических данных — авторе, журнале и годе публикации — а не пониманием свойств материалов. Авторы демонстрируют, что модели способны предсказывать эти метаданные с высокой точностью, а на их основе можно построить предикторы, сопоставимые по эффективности с традиционными дескрипторами. Необходимо ли пересмотреть текущие методы валидации моделей и разработать наборы данных, устойчивые к подобным «ложным» корреляциям, чтобы обеспечить реальный прогресс в материаловедении?
Иллюзия Прогресса: Возможности и Риски Машинного Обучения в Материаловедении
Машинное обучение открывает беспрецедентные возможности для ускорения открытия новых материалов, обещая сокращение времени инновационных циклов. Традиционно, разработка материалов — процесс длительный и трудоемкий, требующий многочисленных экспериментов и сложных расчетов. Однако, благодаря алгоритмам машинного обучения, становится возможным прогнозировать свойства материалов на основе анализа больших объемов данных, значительно сокращая потребность в дорогостоящих и времязатратных лабораторных исследованиях. Этот подход позволяет исследователям быстро оценивать потенциал различных составов и структур, выявлять перспективные кандидаты и оптимизировать их характеристики, что в конечном итоге ускоряет процесс создания материалов с заданными свойствами для широкого спектра применений — от энергетики и электроники до медицины и строительства.
Модели машинного обучения, применяемые в материаловедении, подвержены риску эксплуатации ложных корреляций. Вместо выявления истинных, фундаментальных свойств материалов, алгоритмы могут научиться предсказывать результаты, опираясь на случайные закономерности в данных. Это явление, аналогичное эффекту “Умного Ханса”, когда животное кажется решающим задачи, на самом деле реагируя на неосознанные сигналы, приводит к тому, что модели демонстрируют высокую точность, не отражающую реальное понимание материала. В результате, предсказания становятся ненадежными и плохо переносятся на новые, ранее не встречавшиеся составы, поскольку основаны на статистических артефактах, а не на физических принципах, определяющих поведение материала.
Явление, аналогичное эффекту “Умного Ханса”, ставит под сомнение надежность и обобщающую способность моделей машинного обучения в материаловедении. Исследования показывают, что модели могут достигать высокой точности, выявляя и эксплуатируя нерелевантные корреляции в данных, а не фундаментальные свойства материалов. Это приводит к тому, что точность предсказаний машинного обучения приближается к точности моделей, обученных непосредственно на химических дескрипторах, что свидетельствует о том, что алгоритмы часто “заучивают” статистические закономерности, а не постигают физические принципы, определяющие поведение материалов. В результате, модели, обученные на ограниченном наборе данных, могут демонстрировать впечатляющую точность в этих условиях, но потерпеть неудачу при экстраполяции на новые, невидимые ранее материалы или условия, что подчеркивает необходимость критической оценки и интерпретации результатов, полученных с помощью машинного обучения в материаловедении.
Скрытые Смещения в Данных о Материалах: Иллюзия Объективности
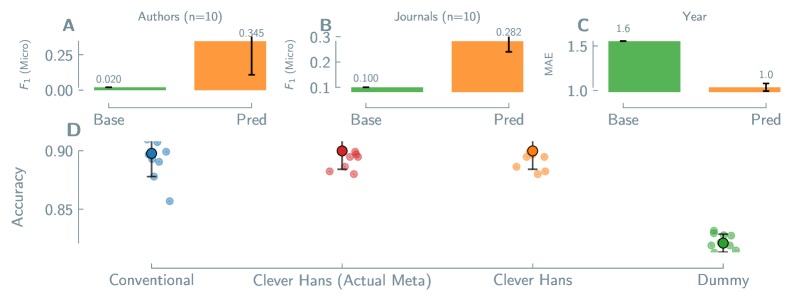
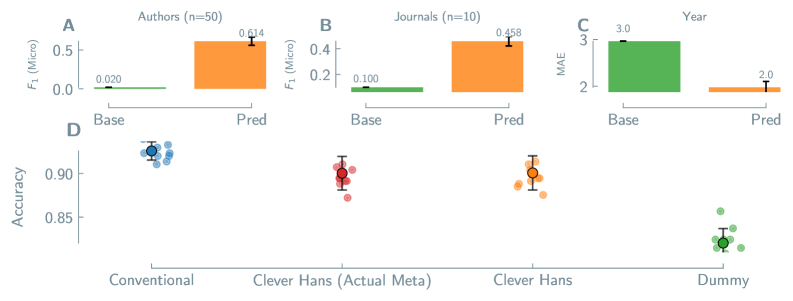
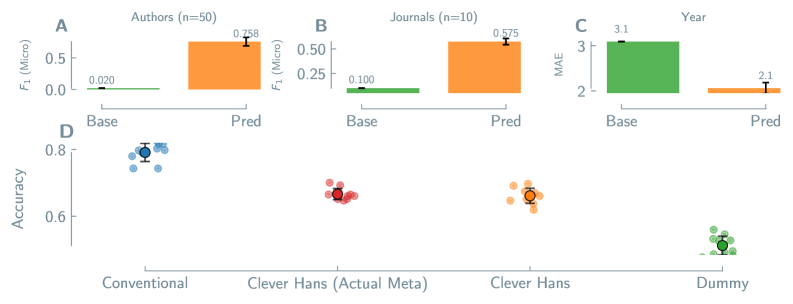
Прогнозирование химических свойств материалов, несмотря на свою эффективность, подвержено риску возникновения систематической ошибки, известной как предвзятость авторства. Данная проблема заключается в том, что модели машинного обучения могут использовать информацию об авторе, журнале публикации или годе исследования в качестве упрощенного признака для предсказания, вместо того чтобы опираться на истинные структурно-свойства связи материала. Это приводит к тому, что прогнозы модели отражают особенности исследовательского коллектива или издания, а не фундаментальные свойства вещества, что снижает обобщающую способность модели и ее применимость к данным, полученным другими группами исследователей или опубликованным в иных источниках.
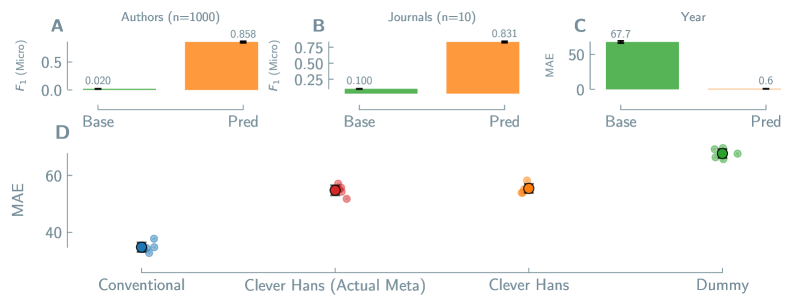
Предвзятость моделей предсказания химических свойств может возникать из-за использования ими библиографической информации (автор, журнал, год публикации) в качестве упрощенного способа для получения результата, а не на основе истинных взаимосвязей между структурой и свойствами материала. Эксперименты с данными по перовскитам показали, что модели способны предсказывать авторство материала с микро-усредненной метрикой F1-score в 0.318. Это указывает на то, что модель успешно идентифицирует исследователя или группу, предоставившую данные, вместо того, чтобы учиться на основе фундаментальных характеристик материала. Использование библиографических данных в качестве “ярлыка” снижает обобщающую способность модели и ее применимость к данным, полученным другими исследовательскими группами или опубликованным в других источниках.
Обобщающая способность моделей предсказания свойств материалов может существенно снижаться при переходе к данным, полученным другими исследовательскими группами или опубликованным в других изданиях, что ограничивает их практическую ценность. Например, модели демонстрируют высокую точность (0.923) в предсказании термической стабильности MOF, сопоставимую с традиционными подходами, но точность предсказания стабильности MOF в различных растворителях значительно ниже — всего 0.655. Данный разрыв в производительности указывает на то, что модели могут улавливать особенности, связанные с конкретными исследовательскими группами или источниками данных, вместо того чтобы изучать фундаментальные связи между структурой и свойствами материала.
Разделение Сигнала от Шума: Инструменты и Подходы к Проектированию Моделей
Прямые модели в задачах предсказания свойств материалов опираются на химические дескрипторы, генерируемые такими инструментами, как RDKit и matminer. Эти дескрипторы представляют собой числовые характеристики, кодирующие состав и структуру материалов, включая информацию об атомах, химических связях и кристаллической структуре. RDKit специализируется на обработке молекулярных структур и вычислении различных дескрипторов, в то время как matminer ориентирован на материалы и предоставляет инструменты для извлечения свойств из кристаллических структур и предсказания новых материалов на основе известных. Использование этих дескрипторов позволяет количественно оценить взаимосвязь между составом материала и его свойствами, что необходимо для построения моделей машинного обучения.
Химические дескрипторы, используемые в прямых моделях для предсказания свойств материалов, несмотря на свою информативность, подвержены систематическим ошибкам, если выбор и валидация осуществляются недостаточно тщательно. Предвзятость может возникать из-за особенностей используемых наборов данных, несоответствия между дескрипторами и реальными физико-химическими процессами, или из-за переобучения модели на ограниченном количестве данных. Некорректный выбор дескрипторов, отражающих нерелевантные аспекты материала, или отсутствие процедур перекрестной проверки для оценки обобщающей способности модели, может приводить к искажению результатов и неверным прогнозам свойств материалов.
Альтернативный подход к прогнозированию свойств материалов заключается в использовании прокси-модели (Proxy Model). Данная модель сначала отображает библиографические данные — информацию, полученную из научных публикаций — на соответствующие свойства материалов. Такой подход позволяет выявлять и исключать ложные корреляции, возникающие при прямом сопоставлении состава и свойств. Модели, использующие прокси-подход, демонстрируют точность 0.900 при прогнозировании эффективности перовскитов, что сопоставимо с результатами, полученными с помощью прямых моделей, основанных на химических дескрипторах, и позволяет идентифицировать устройства, попадающие в топ-10% по эффективности.
Проверка Предсказаний и Обеспечение Обобщающей Способности
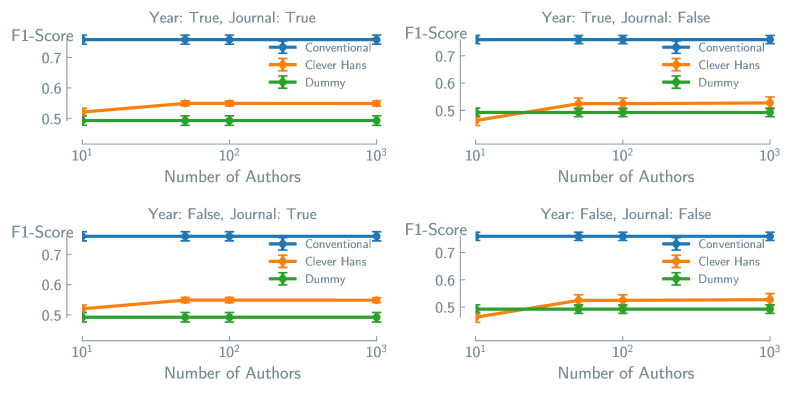
Для обучения и оценки Direct Models, предназначенных для предсказания непрерывных и дискретных свойств материалов, ключевыми методами являются регрессионный и классификационный анализ. Регрессионный анализ применяется для прогнозирования непрерывных значений, таких как прочность на растяжение или теплопроводность, используя статистические модели для установления зависимости между входными параметрами и целевой переменной. Классификационный анализ, напротив, используется для предсказания дискретных категорий, например, типа материала или наличия дефекта. Оба метода требуют построения модели на основе обучающих данных и последующей оценки ее точности на независимом наборе данных, что позволяет определить способность модели к обобщению и прогнозированию свойств новых, ранее не встречавшихся материалов.
LightGBM является эффективным фреймворком для реализации регрессионного и классификационного анализа при прогнозировании материальных свойств. Однако, выбор метрики оценки модели требует особого внимания, поскольку некорректно подобранная метрика может привести к ошибочным выводам о производительности модели. Например, при несбалансированных классах метрика точности (accuracy) может быть обманчиво высокой, в то время как метрики, учитывающие баланс классов, такие как F1-мера или AUC-ROC, предоставят более объективную оценку. Важно выбирать метрику, соответствующую конкретной задаче и типу данных, и учитывать потенциальные искажения, которые могут возникнуть при использовании неоптимальной метрики.
Перекрестная проверка (Cross-Validation) является ключевым методом оценки производительности моделей машинного обучения и предотвращения переобучения. Суть метода заключается в разделении исходного набора данных на несколько подмножеств (фолдов). Модель последовательно обучается на различных комбинациях фолдов, используя один фолд для валидации. В результате, формируется несколько оценок производительности, которые усредняются для получения более надежной и стабильной оценки. Это позволяет оценить, насколько хорошо модель обобщает полученные знания на новые, ранее не встречавшиеся данные, и предотвращает ситуацию, когда модель хорошо работает только на обучающей выборке, но плохо — на реальных данных. Использование перекрестной проверки значительно повышает доверие к результатам предсказаний и гарантирует, что модель способна эффективно работать с данными, выходящими за рамки тренировочного набора.
К Надежным и Достоверным Предсказаниям: Путь к Устойчивому Прогрессу
В материаловедении, применение машинного обучения сталкивается с риском ложных корреляций и предвзятостей, способных исказить результаты предсказаний свойств материалов. Ключевым шагом к раскрытию полного потенциала этих методов является осознанное выявление и нейтрализация подобных факторов. Игнорирование этой проблемы может привести к созданию моделей, демонстрирующих высокую точность на тренировочных данных, но неспособных к обобщению и предсказанию свойств новых материалов в реальных условиях. Тщательный анализ данных, использование методов регуляризации и валидации, а также разработка алгоритмов, устойчивых к шуму и смещениям, — необходимые условия для создания надежных и достоверных моделей, способных существенно ускорить процесс открытия и разработки инновационных материалов с заданными характеристиками.
Применение разработанных методов прогнозирования к таким ключевым характеристикам материалов, как термическая и растворительная стабильность металлоорганических каркасов (MOF), эффективность перовскитных солнечных элементов, ёмкость аккумуляторов и длина волны эмиссии TADF-материалов, открывает новые возможности для ускорения инноваций в материаловедении. Точное предсказание этих свойств позволяет значительно сократить время и затраты на экспериментальные исследования, направляя усилия ученых на наиболее перспективные материалы. Прогнозирование, например, стабильности MOF в различных условиях позволяет создавать более надежные адсорбенты и катализаторы, а предсказание эффективности перовскитных солнечных элементов способствует разработке более эффективных и долговечных источников энергии. Аналогично, точное предсказание ёмкости аккумуляторов и характеристик TADF-материалов позволяет создавать более совершенные устройства хранения энергии и дисплеи.
Применение упреждающего подхода к выявлению и устранению потенциальных ошибок в алгоритмах машинного обучения способно не только повысить точность предсказаний свойств материалов, но и укрепить доверие к технологиям машинного обучения в материаловедении. Такой проактивный метод позволяет перейти от эмпирических наблюдений к более надежным и воспроизводимым результатам, что критически важно для ускорения разработки новых материалов с заданными характеристиками. Это, в свою очередь, открывает перспективы для создания более экологичных и энергоэффективных технологий, способствуя устойчивому развитию и решению актуальных задач в области энергетики, экологии и промышленности. В результате, машинное обучение перестает быть просто инструментом прогнозирования, а становится надежным партнером в инновационном процессе создания материалов будущего.
Исследование демонстрирует, что современные модели машинного обучения в материаловедении часто достигают впечатляющих результатов, опираясь не на истинные свойства материалов, а на случайные корреляции в библиографических данных. Это напоминает эффект «Умного Ханса», когда наблюдатель невольно подсказывает животному правильный ответ. Успех модели, таким образом, оказывается иллюзорным, а её предсказательная сила — сомнительной. Как говорил Лев Ландау: «Теория, которая не может быть проверена экспериментально, — это не физика, а математика». Аналогично, модель, успех которой основан на ложных корреляциях, не отражает реальных физических свойств материалов и, следовательно, бесполезна для практического применения. Необходимость строгой валидации и критического анализа используемых данных становится очевидной.
Что дальше?
Представленная работа обнажает фундаментальную слабость текущих подходов к машинному обучению в материаловедении. Высокая производительность модели, как выясняется, не всегда свидетельствует о понимании физических свойств материала. Скорее, она может являться результатом эксплуатации побочных корреляций, паразитирующих на структуре библиографических данных. Это — не ошибка, это — закономерность, вытекающая из упрощенного взгляда на проблему.
Необходим пересмотр методологии валидации моделей. Традиционные метрики, фокусирующиеся исключительно на предсказательной силе, оказываются недостаточными. Следует отдавать предпочтение подходам, позволяющим отделить истинное понимание от статистической иллюзии. Прозрачность и интерпретируемость моделей становятся не просто желательными, а критически важными. Иначе, продолжая следовать по пути упрощения, мы рискуем строить дворцы на песке, очарованные их кажущейся красотой.
Будущие исследования должны быть направлены на разработку методов, устойчивых к «эффекту умной лошади». Вместо того чтобы стремиться к максимальной точности любой ценой, необходимо сосредоточиться на создании моделей, способных к обобщению и переносу знаний. По сути, требуется не просто научить машину предсказывать, а научить ее понимать. И в этом — не только научная, но и этическая задача.
Оригинал статьи: https://arxiv.org/pdf/2602.17730.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Мощное моделирование жидкости: новый подход к методу решетчатых уравнений Больцмана
- Нейросеть предсказывает сродство антител к COVID-19
- Память как у живого мозга: новый подход к локальному AI
- Искусственный интеллект на службе материалов: от открытий до инноваций
- Кто несет ответственность за ИИ: новый взгляд на причинно-следственные связи
- Квантовый транспорт в сложных системах: новый подход к моделированию
2026-02-23 13:57