Автор: Денис Аветисян
Исследователи предлагают алгоритм, позволяющий стабилизировать процесс обучения больших языковых моделей с использованием методов обучения с подкреплением.
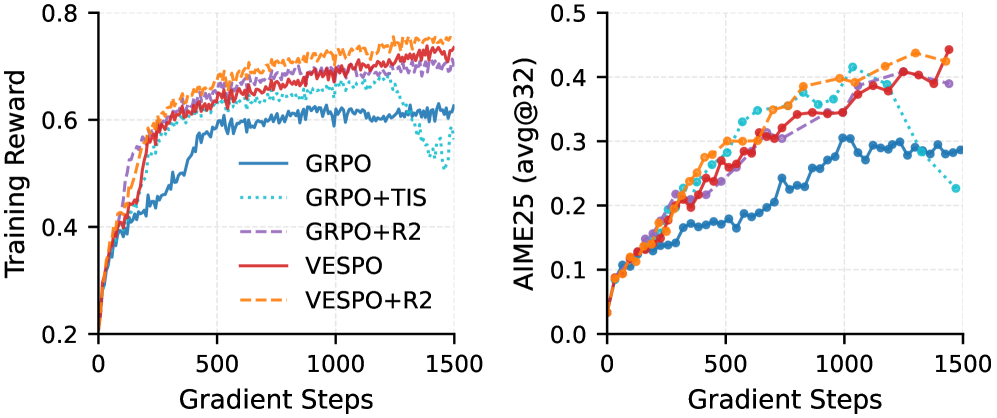
Алгоритм VESPO использует вариационную оптимизацию и коррекцию важности для снижения дисперсии при обучении в режиме off-policy.
Обеспечение стабильности обучения остается сложной задачей при использовании обучения с подкреплением для больших языковых моделей. В данной работе, представленной под названием ‘VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training’, предлагается новый алгоритм VESPO, который стабилизирует обучение в условиях расхождения между политикой сбора данных и текущей политикой, используя вариационный подход к уменьшению дисперсии весов важности. Эксперименты на математических задачах показали, что VESPO поддерживает стабильное обучение даже при значительной устарелости данных и асинхронном выполнении, обеспечивая прирост производительности для моделей различной архитектуры. Сможет ли VESPO стать ключевым элементом в создании более надежных и эффективных языковых моделей, обучаемых с использованием обучения с подкреплением?
Обучение с подкреплением: Когда теория разбивается о практику
Обучение с подкреплением (RL) представляет собой перспективный подход к оптимизации больших языковых моделей (LLM), однако его применение сопряжено с рядом существенных трудностей. В отличие от традиционных методов, где модель обучается непосредственно на данных, полученных в результате её текущих действий, RL позволяет модели исследовать различные стратегии и учиться на полученном опыте. Несмотря на теоретическую привлекательность, практическая реализация RL для LLM сталкивается с проблемами, связанными с нестабильностью обучения, высокой вычислительной сложностью и необходимостью тщательно продуманной функции вознаграждения. Преодоление этих сложностей является ключевым шагом к созданию более интеллектуальных и эффективных языковых моделей, способных решать сложные задачи и адаптироваться к меняющимся условиям.
В процессе обучения больших языковых моделей с использованием методов обучения с подкреплением, существенную сложность представляет применение так называемых “внеполисных обновлений”. Суть данной проблемы заключается в использовании данных, собранных при действии предыдущих версий модели (политик), для обучения текущей версии. Этот подход, хотя и эффективен с точки зрения использования накопленного опыта, часто приводит к нестабильности процесса обучения. Несоответствие между данными, полученными в результате действий старой политики, и текущей политикой, порождает смещение и повышенную дисперсию, что затрудняет сходимость модели к оптимальному решению. По сути, модель пытается учиться на данных, которые не совсем релевантны ее текущему поведению, что аналогично попытке построить дорогу, используя карту другой местности.
Несоответствие между средами сбора данных и обучения представляет собой серьезную проблему для эффективного обучения больших языковых моделей с использованием методов обучения с подкреплением. Когда модель обучается на данных, полученных в результате действий более старых версий своей политики, возникает смещение, поскольку эти данные не отражают оптимальное поведение текущей политики. Это приводит к увеличению дисперсии в оценках градиентов и, как следствие, к нестабильности процесса обучения. Более того, использование устаревших данных может привести к тому, что модель будет оптимизироваться для действий, которые больше не являются оптимальными в текущей среде, что замедляет сходимость и снижает общую производительность. В результате, необходимо разрабатывать специальные методы, позволяющие уменьшить влияние этого несоответствия и обеспечить стабильное и эффективное обучение.
Взвешивание важности: Первый рубеж защиты от смещения
Преобразование весов важности (Importance Weight Transformation) является базовым методом смягчения проблем, возникающих при обучении с использованием данных, собранных по другой стратегии (off-policy обучение). Суть метода заключается в перевзвешивании каждого образца данных, чтобы скорректировать расхождение между стратегией сбора данных (behavior policy) и целевой стратегией (target policy), используемой для обучения модели. Каждый вес рассчитывается как отношение вероятности действия, выбранного целевой политикой, к вероятности того же действия, выбранного политикой сбора данных, что позволяет придать большее значение тем образцам, которые соответствуют целевой политике, и уменьшить влияние образцов, собранных по другой стратегии. Данный подход позволяет эффективно использовать ранее собранные данные для обучения новой модели, даже если стратегии сбора и обучения отличаются.
Метод взвешивания по важности (Importance Weighting) корректирует расхождение между политикой поведения (используемой при сборе данных) и целевой политикой (используемой при обучении) посредством использования так называемого ‘Proposal Distribution’ — вероятностного распределения, представляющего политику поведения. Этот подход заключается в перевзвешивании каждого образца данных, полученного с использованием политики поведения, с целью отразить вероятность получения этого образца, если бы использовалась целевая политика. Вес каждого образца рассчитывается как отношение вероятности этого образца под целевой политикой к вероятности этого образца под политикой поведения. Таким образом, данные, полученные при политике поведения, адаптируются для эффективного обучения целевой политики, минимизируя смещение, вызванное различием между этими политиками.
Стандартные реализации взвешивания по важности часто демонстрируют высокую дисперсию, особенно при работе с длинными последовательностями данных. Это связано с тем, что небольшие различия в вероятностях между поведенческой и целевой политиками могут экспоненциально усиливаться при вычислении весов по длинным траекториям. Для смягчения данной проблемы и уменьшения влияния выбросов, применяются методы, такие как усеченное взвешивание по важности (Truncated Importance Sampling). Данный подход ограничивает максимальное значение веса каждого образца, предотвращая доминирование единичных, но сильно взвешенных, примеров, и стабилизируя процесс обучения при наличии несоответствия между обучением и выводом (Train-Inference Mismatch).
Уточнения на уровне токенов и последовательностей: Детали имеют значение
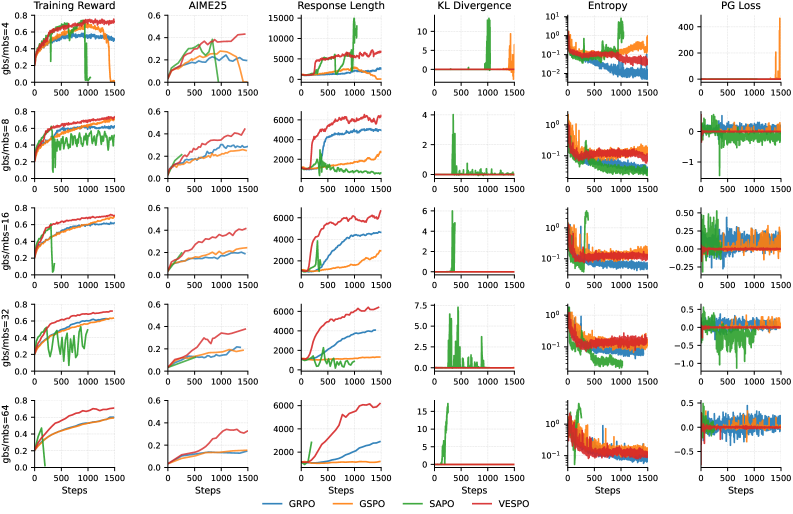
Недавние исследования в области обучения с подкреплением с использованием больших языковых моделей демонстрируют применение взвешивания важности на различных уровнях детализации. Подходы, известные как ‘Трансформация на уровне токенов’ и ‘Трансформация на уровне последовательностей’, направлены на коррекцию смещения, возникающего при использовании данных, собранных с использованием другой политики. ‘Трансформация на уровне токенов’ применяет веса к каждому отдельному токену в последовательности, в то время как ‘Трансформация на уровне последовательностей’ назначает веса целым последовательностям. Такой подход позволяет более эффективно использовать данные для обучения, особенно в сценариях, где данные собираются асинхронно или с использованием различных политик.
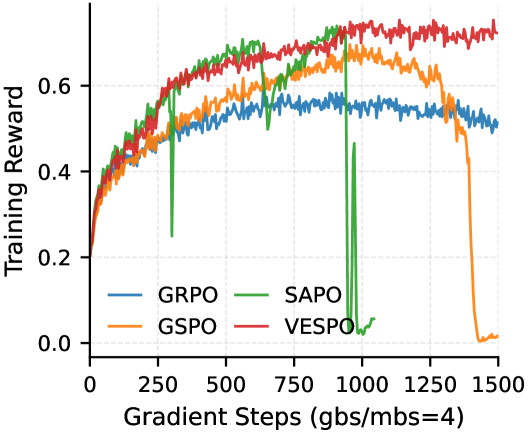
Алгоритмы, такие как SAPO и GRPO, применяют взвешивание важности на уровне отдельных токенов входной последовательности, что позволяет более детально регулировать вклад каждого токена в процесс обучения. В отличие от них, GSPO осуществляет корректировки на уровне всей последовательности, рассматривая ее как единое целое. Некоторые реализации GSPO дополнительно используют нормализацию по длине (Length Normalization), компенсируя влияние разной длины последовательностей на процесс обучения и обеспечивая более стабильную оценку важности.
Методы взвешивания важности, применяемые на уровне токенов и последовательностей, направлены на снижение дисперсии и повышение стабильности обучения моделей. Однако, в асинхронных средах обучения, эти методы могут сталкиваться с проблемой “устаревания политики” (policy staleness). Это происходит из-за того, что обновления политики, основанные на устаревших данных, могут приводить к снижению эффективности обучения и нестабильности процесса. Несмотря на усилия по оптимизации, поддержание актуальности политики в условиях асинхронного обучения остается сложной задачей, требующей дополнительных механизмов синхронизации или адаптации.

VESPO: Вариационный подход к стабилизации обучения
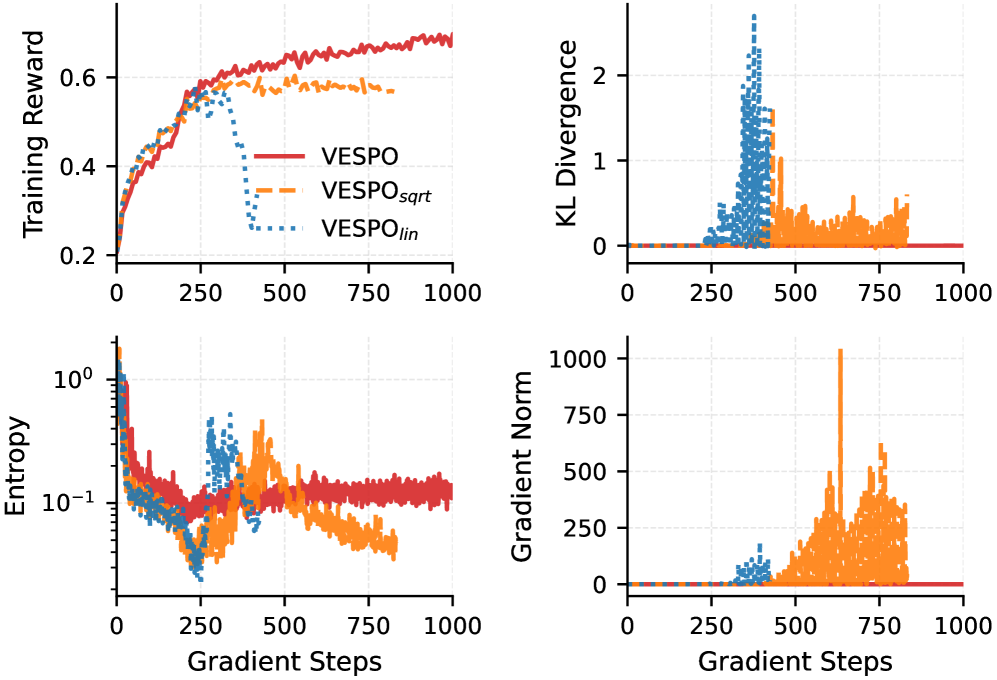
Метод VESPO (Variational Sequence-level Soft Policy Optimization) представляет собой новый подход к стабилизации обучения с подкреплением (RL) в больших языковых моделях (LLM). Он сочетает в себе преобразования на уровне последовательностей с вариационными техниками, что позволяет более эффективно управлять процессом обновления политики. Ключевым элементом является применение вариационного подхода, который обеспечивает контроль над изменениями политики и предотвращает её резкие колебания, часто наблюдаемые при обучении RL. Преобразования на уровне последовательностей позволяют моделировать более сложные зависимости в данных и улучшать обобщающую способность, что способствует повышению стабильности обучения и достижению лучших результатов.
Метод VESPO использует расхождение Кульбака-Лейблера (KL Divergence) в качестве регуляризующего члена для ограничения изменений в политике обучения. Это достигается путем добавления KL Divergence к функции потерь, что препятствует слишком сильным отклонениям новой политики от предыдущей. Для точного контроля над этими ограничениями, VESPO применяет множитель Лагранжа (Lagrange Multiplier). Этот множитель позволяет настраивать вес регуляризации KL Divergence, обеспечивая баланс между улучшением политики и поддержанием её стабильности. Использование множителя Лагранжа позволяет эффективно решать задачу оптимизации с ограничениями, гарантируя, что обновления политики остаются в пределах заданных ограничений, что критически важно для стабилизации обучения больших языковых моделей.
Метод VESPO демонстрирует передовые результаты благодаря использованию алгоритма градиентного спуска и приоритету снижения дисперсии. На модели Qwen3-30B-A3B-Base достигнуто среднее улучшение точности на 2.3%, при этом стабильность обучения сохраняется даже при коэффициенте устаревания политики 64x. В ходе тестирования на различных математических бенчмарках были получены следующие результаты: 68.2% на Qwen3-30B-A3B-Base, 58.2% на AIME 2024, 55.1% на AIME 2025, 62.4% на AMC 2023 и 43.1% на MATH-500, что подтверждает его эффективность в задачах математического рассуждения.
Эта работа с VESPO, конечно, элегантна. Вариационное переосмысление важности весов — звучит как что-то из учебника по математике. Но давайте будем честны: стабильное обучение LLM в off-policy условиях — это всегда борьба с техническим долгом. Авторы пытаются приручить хаос важности весов, а на деле просто создают ещё один уровень абстракции, который рано или поздно потребует тонкой настройки. Как говорил Роберт Тарьян: «Хороший алгоритм — это просто способ отложить проблему на будущее». И здесь, судя по всему, всё именно так. VESPO пытается обуздать неконтролируемый рост дисперсии, но в конечном итоге, это лишь попытка оптимизировать неизбежное усложнение системы. Не удивлюсь, если через полгода появится VESPO++, который будет решать проблемы, возникшие из-за внедрения VESPO.
Что Дальше?
Представленный алгоритм VESPO, безусловно, добавляет ещё один уровень сложности в и без того запутанную область обучения больших языковых моделей с подкреплением. Уменьшение дисперсии важно, это факт, но история показывает, что каждая «оптимизация» рано или поздно превращается в новый вид техдолга. Вероятно, в ближайшем будущем последуют работы, направленные на адаптацию VESPO к ещё более сложным сценариям, таким как обучение на неполных данных или в условиях меняющейся среды. Однако, стоит помнить, что даже самые элегантные решения в конечном итоге столкнутся с неизбежной реальностью: продакшен всегда найдёт способ сломать любую, даже самую тщательно спроектированную архитектуру.
Более фундаментальный вопрос заключается в том, действительно ли последовательное обучение с подкреплением является оптимальным подходом к управлению языковыми моделями. Возможно, будущее за другими парадигмами, которые позволят избежать проблем, связанных с оценкой важности и коррекцией смещения. Не исключено, что нам не нужно больше микросервисов для обучения LLM — нам нужно меньше иллюзий о том, что мы можем полностью контролировать их поведение.
В конечном счёте, успех VESPO, как и любой другой инновации в этой области, будет зависеть не от теоретической элегантности, а от способности выдержать проверку временем и суровую реальность практического применения. А это значит, что самое интересное ещё впереди — наблюдать, как неизбежные ошибки и ограничения алгоритма будут выявлены и преодолены.
Оригинал статьи: https://arxiv.org/pdf/2602.10693.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Квантовые схемы: универсальность и сложность
- Искусственный интеллект на службе материалов: от открытий до инноваций
- Кто несет ответственность за ИИ: новый взгляд на причинно-следственные связи
- Квантовый транспорт в сложных системах: новый подход к моделированию
- Искусственный интеллект в науке: на пути к прозрачности
- Знания в графах: как улучшить ответы больших языковых моделей
2026-02-23 16:02