Автор: Денис Аветисян
Исследователи представили комплексный бенчмарк для оценки способности моделей с искусственным интеллектом активно рассуждать с использованием изображений.
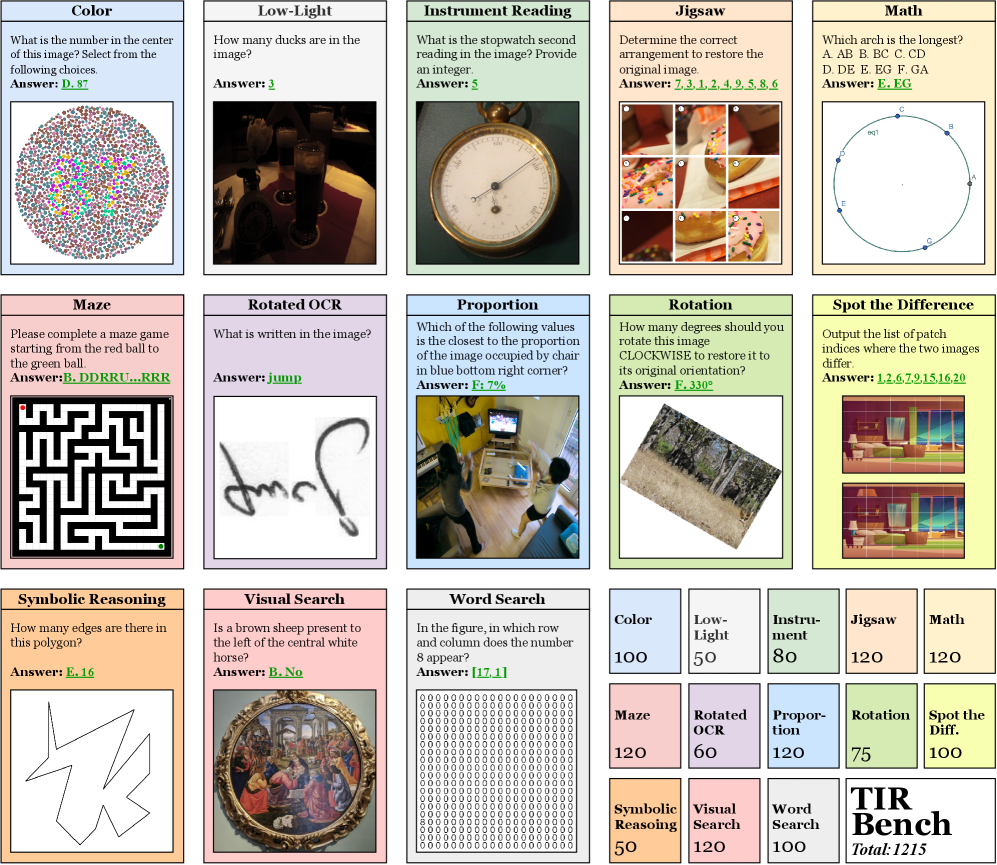
Представлен TIR-Bench – эталонный набор данных для оценки возможностей мультимодальных моделей в решении задач, требующих манипулирования визуальной информацией и использования инструментов.
Существующие бенчмарки для оценки визуального мышления недостаточно полно отражают возможности современных моделей, способных активно использовать инструменты для обработки изображений. В данной работе представлена новая комплексная методика оценки – TIR-Bench: A Comprehensive Benchmark for Agentic Thinking-with-Images Reasoning – предназначенная для измерения способности мультимодальных больших языковых моделей к решению задач путем манипулирования изображениями с использованием инструментов в рамках логической цепочки рассуждений. Результаты тестирования 22 моделей показали, что TIR-Bench является универсально сложным, и высокая производительность требует именно способности к активному “мышлению с изображениями”. Смогут ли новые подходы к обучению моделей преодолеть выявленные ограничения и приблизить нас к созданию действительно разумных систем визуального мышления?
За гранью восприятия: Эволюция визуального мышления
Традиционные системы компьютерного зрения демонстрируют эффективность в распознавании объектов, но испытывают трудности в комплексном анализе и логических выводах, основанных на визуальной информации. Современные мультимодальные большие языковые модели (MLLM) также ограничены в задачах, требующих итеративной обработки изображений. Существующие подходы часто не способны эффективно использовать инструменты для извлечения и обработки визуальных данных в сложных сценариях.

Необходима разработка моделей, способных к активному использованию инструментов для извлечения, обработки и интерпретации визуальной информации, позволяющих выполнять сложные задачи, требующие не только распознавания объектов, но и логического анализа и планирования действий. Каждая новая архитектура – лишь отсрочка неизбежного технического долга.
Агентское использование инструментов: От восприятия к действию
Агентное использование инструментов позволяет мультимодальным большим языковым моделям (MLLM) использовать внешние инструменты, такие как интерпретаторы кода, для сложных манипуляций и анализа изображений. Этот подход расширяет возможности моделей, позволяя им выходить за рамки пассивного восприятия и активно взаимодействовать с визуальными данными.
Методы, такие как обучение с подкреплением на основе предпочтений (Agentic SFT), позволяют обучать модели проактивному использованию инструментов, значительно улучшая их способность решать задачи. Агентные модели способны динамически адаптироваться к новым ситуациям, используя инструменты для преодоления ограничений и повышения точности.

Этот подход меняет парадигму обработки визуальной информации, переходя от пассивного восприятия к активному исследованию и манипулированию визуальными данными. Такой сдвиг открывает новые возможности для решения сложных задач, требующих понимания взаимосвязей и контекста.
TIR-Bench: Строгий тест для визуального мышления
Для оценки способности агентов, основанных на больших мультимодальных моделях (MLLM), к «мышлению с использованием изображений» разработан комплексный бенчмарк TIR-Bench. Этот бенчмарк включает в себя разнообразный набор задач, требующих итеративной обработки визуальной информации.
В состав TIR-Bench входят такие задачи, как сборка пазлов, поиск отличий и решение лабиринтов, а также распознавание текста на повернутых изображениях (Rotated Image OCR) и считывание показаний приборов, что проверяет способность модели использовать функциональные вызовы для сложных манипуляций с изображениями.

Дополнительные задачи, такие как Proportion VQA, Color VQA и Low-Light VQA, позволяют оценить способность модели к детальному визуальному анализу и интерпретации. На текущий момент лучшая агентурная модель, использующая инструменты (o3-TU), достигает общей точности 46% на TIR-Bench, что на 17% выше, чем у лучшей неагентной модели (Gemini-2.5-pro).
За пределами бенчмарков: Будущее визуального интеллекта
Успешное прохождение тестов на платформе TIR-Bench демонстрирует прогресс в создании интеллектуальных систем, способных к сложному визуальному рассуждению. Данный результат указывает на повышение эффективности алгоритмов обработки изображений и их способности к обобщению знаний.
Задачи, связанные с символьным рассуждением, указывают на потенциал моделей к абстрактному мышлению, открывая возможности для решения более сложных визуальных проблем. Способность к логическим выводам и манипулированию символами является ключевым элементом для достижения общего искусственного интеллекта.

Данные достижения имеют применение в широком спектре областей, включая робототехнику, автономную навигацию и анализ медицинских изображений. Дальнейшие исследования, вероятно, будут сосредоточены на повышении эффективности и надёжности использования инструментов агентами, а также на разработке новых методов представления и рассуждения о визуальных знаниях. Каждая «революционная» технология завтра станет техдолгом.
Исследование TIR-Bench наглядно демонстрирует, что современные мультимодальные модели, несмотря на кажущуюся продвинутость, часто терпят неудачу, когда дело доходит до активного взаимодействия с изображениями и использования инструментов для их анализа. Этот бенчмарк выявляет недостаток подлинного ‘мышления с изображениями’ – способности не просто распознавать объекты, но и манипулировать визуальной информацией для достижения цели. Как метко заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть полезен людям, а не просто впечатляющим». В данном контексте, впечатляющая способность генерировать описания изображений мало что значит, если модель не может использовать эти знания для решения практических задач, что и подтверждается результатами TIR-Bench. Этот бенчмарк – ещё одно напоминание о том, что ‘революционные’ технологии быстро обрастают техническим долгом, а реальная ценность заключается в надежности и применимости.
Что дальше?
Представленный бенчмарк, TIR-Bench, неизбежно выявит, что текущие мультимодальные модели далеки от подлинного «мышления с изображениями». Неудивительно. Каждая «революционная» возможность – лишь новый вектор для возникновения ошибок. Способность использовать инструменты для манипуляции визуальным входом – это, конечно, прогресс, но и ещё один слой абстракции, который рано или поздно потребует поддержки. Продакшен всегда найдёт способ сломать элегантную теорию.
В будущем, вероятно, возникнет потребность в более сложных бенчмарках, оценивающих не просто способность использовать инструменты, а способность к адаптации и самокоррекции. Текущая CI – это храм, в котором мы молимся, чтобы ничего не сломалось, но реальный мир не прощает ошибок. Документация – это миф, созданный менеджерами, и модели, которые полагаются на неё, обречены на провал.
В конечном итоге, истинный прогресс заключается не в создании более сложных моделей, а в признании их фундаментальных ограничений. Каждая новая возможность – это не шаг к искусственному интеллекту, а лишь увеличение технического долга, который когда-нибудь придётся выплачивать. И, вероятнее всего, это будет сделано в спешке и с ошибками.
Оригинал статьи: https://arxiv.org/pdf/2511.01833.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Динамика в кадре: Как научить ИИ понимать физику видео
- Сердце музыки: открытые модели для создания композиций
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Автономные агенты для анализа материалов: новый уровень автоматизации
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Оживляя текст: новый подход к генерации видео
- Самообучающиеся нейросети: новый подход к работе с инструментами
- Вопросы и ответы на ваших документах: Интеллект без облака
- Квантовые Загадки: От Материалов до Топологии
- Мультимодальные модели: новый подход к пониманию и генерации
2025-11-04 21:03