Автор: Денис Аветисян
В статье представлена архитектура Avey-B, позволяющая эффективно обрабатывать длинные контексты без использования механизма внимания.
Avey-B — это двунаправленный энкодер, сочетающий в себе декомпозицию слоев на статические и динамические компоненты, нейронную компрессию и инновационный подход к контекстуализации для повышения эффективности и масштабируемости.
В условиях растущих требований к вычислительным ресурсам и памяти, традиционные двунаправленные кодировщики, основанные на механизмах внимания, сталкиваются с ограничениями при обработке длинных последовательностей. В данной работе представлена архитектура ‘Avey-B’ — альтернативный подход, использующий авторегрессионную модель без внимания, адаптированную для двунаправленного кодирования. Предложенная реализация, включающая разделение статических и динамических параметров, нормализацию, ориентированную на стабильность, и нейронную компрессию, демонстрирует превосходство над широко используемыми Transformer-based кодировщиками в задачах классификации токенов и поиска информации, при этом обеспечивая более эффективное масштабирование для длинных контекстов. Способна ли эта архитектура стать основой для нового поколения эффективных и масштабируемых моделей обработки естественного языка?
Преодолевая Границы: Вызовы Длинных Контекстов в Современной NLP
Традиционные архитектуры Transformer, несмотря на свою мощь, сталкиваются с серьезными трудностями при обработке очень длинных последовательностей текста. Эта сложность обусловлена квадратичной вычислительной сложностью — с увеличением длины входной последовательности, требуемые вычислительные ресурсы и время обработки растут экспоненциально. В частности, механизм внимания, ключевой компонент Transformer, требует вычисления взаимодействия между каждой парой токенов во входной последовательности, что приводит к O(n^2) сложности, где n — длина последовательности. Это существенно ограничивает возможности обработки длинных документов, книг или расширенных диалогов, требуя огромных вычислительных мощностей и делая применение Transformer в подобных задачах экономически нецелесообразным. В результате, производительность моделей снижается, а возможность извлечения значимой информации из длинных текстов существенно затрудняется.
Ограничение способности современных языковых моделей к обработке длинных текстов серьезно препятствует их применению в задачах, требующих анализа и логических выводов на основе развернутых повествований или объемных документов. Существующие архитектуры часто демонстрируют неудовлетворительные результаты при попытке экстраполировать информацию за пределы своего обученного контекстного окна, что создает узкое место в развитии передовых NLP-приложений. Модели испытывают трудности с удержанием важных деталей и установлением связей между отдаленными частями текста, что приводит к неточным ответам и снижению общей производительности при работе с длинными последовательностями. Это особенно заметно в задачах, требующих понимания сложных сюжетов, анализа юридических документов или обобщения научных статей, где критически важно учитывать весь объем информации.
Avey: Новый Взгляд на Эффективную Обработку Длинных Последовательностей
Архитектура Avey представляет собой альтернативу трансформерам, разработанную специально для эффективной обработки длинных последовательностей данных. В отличие от трансформеров, использующих механизм внимания, Avey использует иные подходы, направленные на снижение вычислительной сложности, возникающей при работе с большими объемами данных. Это достигается за счет отказа от квадратичной зависимости вычислительных затрат от длины последовательности, свойственной механизму внимания, и, как следствие, позволяет масштабировать модели для работы с более длинными последовательностями при сохранении приемлемой производительности и снижении потребления ресурсов. Avey позиционируется как потенциальное решение проблем масштабируемости, ограничивающих применение трансформеров в задачах, требующих обработки больших объемов данных, таких как анализ длинных текстов или обработка видеопотоков.
Архитектура Avey применяет методы статической и динамической параметризации для снижения вычислительной нагрузки при обработке длинных последовательностей. Статическая параметризация предполагает использование предобученных, фиксированных параметров, в то время как динамическая параметризация позволяет модели адаптировать параметры в зависимости от входных данных. Дополнительно, Avey использует методы нейронной компрессии, такие как квантизация и прунинг, для уменьшения размера модели и количества операций, при этом минимизируя потери в производительности. Комбинация этих техник позволяет Avey достигать высокой эффективности и масштабируемости при работе с большими объемами данных, сохраняя при этом сопоставимую или превосходящую точность по сравнению с традиционными моделями, основанными на механизмах внимания.
Архитектура Avey использует нормализованную по строкам меру схожести (row-normalized similarity) для оценки релевантности различных частей входной последовательности. Вместо обработки всей последовательности, Avey применяет метод отбора top-k, выбирая только k наиболее релевантных элементов для формирования контекста. Это позволяет значительно снизить вычислительные затраты при работе с длинными последовательностями, поскольку модель фокусируется на наиболее важных элементах, отбрасывая менее значимую информацию и повышая эффективность обработки.
AveyB: Подтверждение Эффективности на Практике
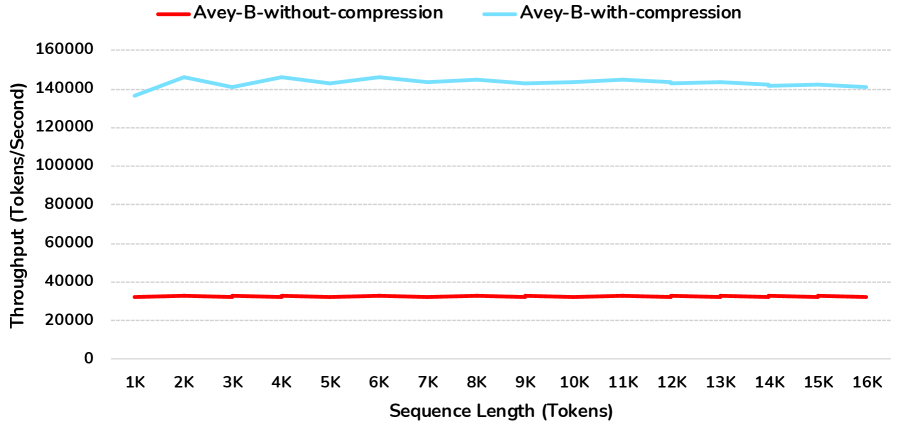
AveyB, двунаправленный кодировщик, разработанный на основе архитектуры Avey, демонстрирует передовые результаты в решении различных задач, а также превосходит стандартные энкодеры на основе Transformer в обработке длинных последовательностей. В частности, AveyB поддерживает стабильную точность при обработке контекста длиной до 96 000 токенов, что недостижимо для традиционных Transformer-моделей. Данный результат достигается благодаря сочетанию принципов Avey и двунаправленной архитектуры, обеспечивающей эффективное масштабирование и высокую производительность при работе с длинными последовательностями данных.
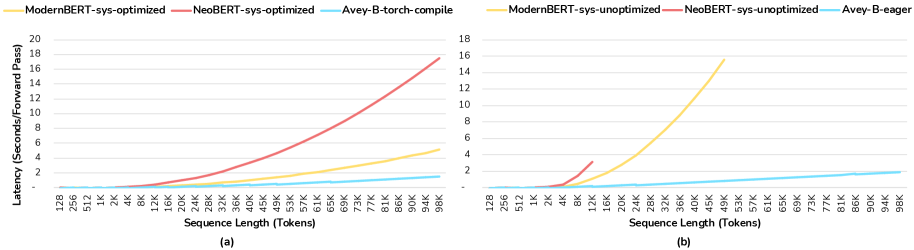
Увеличение производительности AveyB достигается за счет эффективной комбинации основных принципов Avey с двунаправленной архитектурой, оптимизированной как для скорости, так и для точности. При обработке последовательностей длиной 96 тысяч токенов, AveyB демонстрирует увеличение пропускной способности в диапазоне от 3.2 до 10 раз по сравнению с моделями ModernBERT и NeoBERT. Оптимизация архитектуры позволяет обрабатывать более длинные последовательности с существенно меньшими временными затратами, сохраняя при этом высокую точность обработки данных.
Сравнительный анализ AveyB с устоявшимися Transformer-моделями, такими как BERT и RoBERTa, демонстрирует его потенциал в достижении сопоставимых или превосходящих результатов при снижении вычислительных затрат. В частности, на бенчмарке NIAH-1 AveyB показывает снижение точности всего на 3-4 процентных пункта при 96-кратном увеличении длины последовательности. Это указывает на эффективное масштабирование модели и сохранение производительности при обработке значительно более длинных текстов, что делает AveyB перспективным решением для задач, требующих анализа больших объемов данных.

Расширяя Горизонты: NeoBERT и Линейное Внимание
Продолжая развитие архитектуры Transformer, модель NeoBERT представляет собой значительный шаг вперед в достижении повышенной масштабируемости и эффективности обработки данных. В отличие от традиционных Transformer, NeoBERT использует инновационные методы оптимизации, направленные на снижение вычислительных затрат и ускорение обучения. Это достигается за счет более эффективного использования памяти и параллелизации вычислений, что позволяет модели обрабатывать более длинные последовательности текста и работать с большими объемами данных. Благодаря этим улучшениям, NeoBERT демонстрирует превосходные результаты в различных задачах обработки естественного языка, включая машинный перевод, анализ тональности и генерацию текста, открывая новые возможности для создания интеллектуальных систем и приложений.
Механизмы внимания, являющиеся основой современных нейронных сетей, традиционно требуют значительных вычислительных ресурсов, особенно при обработке длинных последовательностей данных. Однако, разрабатываемые техники линейного внимания предлагают принципиально новый подход к снижению этой вычислительной сложности. Вместо вычисления внимания между всеми парами элементов последовательности, линейное внимание использует приближенные методы, позволяющие сократить количество операций с O(n^2) до O(n), где n — длина последовательности. Такое снижение сложности делает обработку очень длинных текстов, видео или других последовательных данных не только возможной, но и практичной для широкого спектра приложений, открывая путь к созданию более эффективных и масштабируемых моделей искусственного интеллекта.
Исследования в области архитектур, вдохновленных рекуррентными нейронными сетями (RNN), отражают растущую тенденцию к комбинированию сильных сторон различных подходов для решения проблемы моделирования длинного контекста. В то время как трансформеры демонстрируют превосходство в параллелизации и захвате глобальных зависимостей, RNN сохраняют преимущества в эффективной обработке последовательных данных и поддержании информации о прошлых состояниях. Попытки интегрировать принципы RNN, такие как механизмы памяти и рекуррентные связи, в новые архитектуры, нацелены на создание моделей, способных эффективно обрабатывать очень длинные последовательности, избегая ограничений вычислительной сложности, свойственных стандартным механизмам внимания. Такой гибридный подход позволяет преодолеть недостатки отдельных архитектур и раскрыть потенциал для создания более мощных и эффективных моделей обработки естественного языка, способных к более глубокому пониманию и генерации текста.
Исследование архитектуры Avey-B демонстрирует глубокую связь между структурой и поведением системы. Разделение статических и динамических слоёв, подобно тщательно продуманной иерархии, позволяет эффективно масштабировать модель для работы с длинными контекстами. Это подчеркивает, что целостность системы зависит от понимания взаимодействия её частей. Как заметил Анри Пуанкаре: «Наука не состоит из целого ряда отдельных фактов, а из связей между ними». Подобно тому, как Avey-B использует нейронную компрессию для оптимизации производительности, Пуанкаре подчеркивал важность выявления закономерностей и упрощения сложных систем для лучшего понимания и управления ими. В данном случае, эффективное масштабирование модели становится возможным благодаря продуманной архитектуре, где каждый элемент играет свою роль в общей картине.
Куда Дальше?
Представленная работа, хотя и демонстрирует впечатляющие результаты в области моделирования длинных контекстов, лишь слегка приоткрывает дверь в сложный лабиринт. Эффективность архитектуры Avey-B, основанной на разделении статических и динамических слоёв, заставляет задуматься: не является ли кажущаяся сложность существующих систем признаком их внутренней хрупкости? Если структура определяет поведение, то упрощение, а не усложнение, может стать ключом к настоящему масштабированию.
Очевидным направлением для дальнейших исследований представляется углубленное изучение принципов нейронной компрессии. Способность эффективно уменьшать размер представления данных, не теряя при этом существенной информации, — это не просто техническая задача, а философский вопрос о природе информации и её репрезентации. Архитектура, вынужденная выбирать, что отбросить, неизбежно демонстрирует свои приоритеты.
В конечном итоге, истинный прогресс, вероятно, потребует отказа от устаревших метафор. Моделирование контекста — это не просто расширение окна внимания, а создание внутренней репрезентации мира, способной к адаптации и обобщению. И если Avey-B является шагом в этом направлении, то будущее, несомненно, будет принадлежать тем, кто осмелится переосмыслить само понятие «внимания».
Оригинал статьи: https://arxiv.org/pdf/2602.15814.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- От миллиметровых волн к кубитному управлению: единый подход
- Квантовые схемы: универсальность и сложность
- Автоматический анализ алгоритмов: новый подход к оптимизации
- Визуальная навигация по множеству изображений: новый подход с использованием больших языковых моделей
- Автоматизация интеллекта: как оптимизировать сложные задачи
- Квантовые точки и литий танталат: новый путь к фотонным микросхемам
2026-02-24 00:14